2025年10月03日·1 分钟
为什么 Docker 对在云上可靠运行应用很重要
了解为什么 Docker 能让团队从笔记本到云端以相同方式运行应用、简化部署、提升可移植性并减少环境问题。
了解为什么 Docker 能让团队从笔记本到云端以相同方式运行应用、简化部署、提升可移植性并减少环境问题。
大多数云端部署的痛点都源自一个熟悉的惊讶:应用在笔记本上能跑,但部署到云服务器后就失败了。也许服务器上的 Python 或 Node 版本不同、缺少系统库、配置文件有轻微差异,或某个后台服务没有运行。这些小差异累积起来,团队最终在调试环境而不是改进产品。
Docker 的做法是把你的应用连同它需要的运行时和依赖一起打包。你不用再发布一长串步骤像“安装 X 版本,然后加上 Y 库,然后设置这个配置”,而是发布一个已经包含这些内容的容器镜像。
一个有用的心智模型是:
当你在云上运行与本地测试时用同一个镜像,诸如“但是我的服务器不一样”的问题会大大减少。
Docker 对不同角色分别有不同的好处:
Docker 极其有用,但它不是你需要的唯一工具。你仍需管理配置、密钥、数据存储、网络、监控与扩容。对许多团队来说,Docker 是一个构建块,会与 Docker Compose(用于本地工作流)和生产环境的编排平台一起工作。
把 Docker 想像成你应用的集装箱:它让交付更可预测。码头(即云端的设置与运行时)仍然重要——但当每次发货都按照相同方式打包时,事情会容易得多。
Docker 的词汇看起来很多,但核心思想很直接:把你的应用打包,使其在任何地方以相同方式运行。
虚拟机 打包了完整的来宾操作系统加上你的应用。这很灵活,但运行更重且启动慢。
容器 打包了你的应用和依赖,但共享宿主机的操作系统内核而不是携带整个操作系统。因此容器通常更轻量、几秒内启动,并且可以在同一台服务器上运行更多副本。
镜像(Image):应用的只读模板。把它想像成包含代码、运行时、系统库和默认设置的打包制品。
容器(Container):镜像的一个运行实例。如果镜像是蓝图,容器就是你当前居住的房子。
Dockerfile:Docker 用来构建镜像的逐步说明(安装依赖、复制文件、设置启动命令)。
注册表(Registry):用于存储和分发镜像的服务。你把镜像“推送”到注册表,之后在服务器上“拉取”(可以是公共注册表或公司内部的私有注册表)。
一旦你的应用被定义为由 Dockerfile 构建的镜像,你就获得了一个标准化的交付单元。标准化使发布可复现:你测试过的就是你部署的镜像。
它也简化了交接。你不再说“在我机器上能跑”,而是指向注册表中的某个具体镜像版本,说:用这个镜像,带这些环境变量,在这个端口上运行。那是实现开发与生产环境一致性的基础。
Docker 在云端部署中的最大作用就是一致性。你不必依赖笔记本、CI 运行器或云虚拟机上随意安装的软件,而是一次在 Dockerfile 中定义环境并在各阶段复用它。
在实践中,一致性体现在:
这种一致性很快就能体现价值。出现在生产中的 bug 可以通过运行相同的镜像标签在本地复现。因缺少库而导致的部署失败也不太可能发生——因为测试容器中也会缺少该库。
团队经常尝试用安装文档或脚本来标准化服务器配置。问题在于漂移:随着补丁与包更新,机器会随时间改变,差异慢慢累积。
使用 Docker,环境被视为一个工件。如果需要更新它,你重建一个新的镜像并部署——让变更变得显式且可审查。如果更新引入问题,回滚通常只需部署之前的已知良好标签即可。
Docker 的另一个主要收获是可移植性。容器镜像把你的应用变成一个可移植的工件:构建一次,然后在任何兼容的容器运行时上运行。
Docker 镜像把应用代码和运行时依赖打包(例如 Node.js、Python 包、系统库)。这意味着你在笔记本上运行的镜像也可以运行在:
这在应用运行时层面减少了供应商锁定。你仍然可以使用云原生服务(数据库、队列、存储),但核心应用不必因为更换主机而重建。
当镜像被存储并在注册表中版本化时,可移植性最佳。典型工作流如下:
myapp:1.4.2)。注册表也让复现与审计部署更容易:如果生产运行 1.4.2,你可以稍后拉取相同工件并得到完全相同的内容。
迁移主机: 如果你从一个 VM 提供商迁移到另一个,不需要重新安装堆栈。你只需让新服务器指向注册表,拉取镜像,并用相同配置启动容器。
横向扩展: 需要更多容量?在更多服务器上启动来自同一镜像的额外容器。因为每个实例都是相同的,扩容变成可复现的操作而不是手动设置。
一个好的 Docker 镜像不只是“能运行的东西”。它是一个可版本化、可重建并仍可信赖的封装工件。这正是让云端部署可预测的原因。
Dockerfile 描述了如何逐步组装应用镜像——就像一份精确配方。每一行创建一层,共同定义:
保持该文件清晰和有意图有助于镜像更容易调试、审查与维护。
小镜像拉取更快、启动更快,且包含更少可能出问题或含有漏洞的“东西”。
alpine 或 slim 变体),在与应用兼容时优先使用。许多应用需要编译器和构建工具来编译,但运行时不需要。多阶段构建允许你在一个阶段完成构建,在第二个精简的阶段生成用于生产的镜像。
# build stage
FROM node:20 AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# runtime stage
FROM nginx:1.27-alpine
COPY --from=build /app/dist /usr/share/nginx/html
结果是更小的生产镜像,依赖更少,需修补的面也更小。
标签是你识别精确部署内容的方式。
latest:它含糊不清。1.4.2)用于发布。1.4.2-<sha> 或仅 <sha>),以便总能追溯镜像对应的代码。这支持干净的回滚与变更审计。
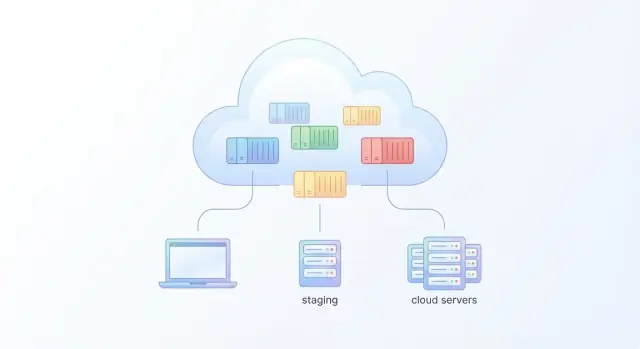
一个“真实”的云应用通常不是单一进程。它是一个小系统:一个网页前端、一个 API,也许还有后台 worker,以及数据库或缓存。Docker 支持简单和多服务设置——你只需要理解容器之间如何通信、配置在哪里,以及数据如何在重启后存活。
单容器应用可能是静态站点或不依赖其他服务的单个 API。你暴露一个端口(例如 8080)并运行它。
多服务应用更常见:web 依赖 api,api 依赖 db,还有 worker 从队列消费任务。容器通常通过共享网络按服务名互相通信(例如 db:5432),而不是硬编码 IP 地址。
Docker Compose 是本地开发与预发布的实用之选,因为它让你用一条命令启动整个栈,同时文件也记录了应用的“形态”(服务、端口、依赖),团队成员可以共享该文件。
一个典型进阶路径是:
镜像应可复用且安全共享。把环境特定的设置放到镜像之外:
通过环境变量、.env 文件(注意不要提交)或云端的密钥管理器传入这些配置。
容器是可丢弃的;你的数据不应该是。对需要在重启后保留的内容使用卷:
在云端部署中,等价的是托管存储(托管数据库、网络磁盘、对象存储)。关键思想不变:容器运行应用;持久存储保存状态。
健康的 Docker 部署工作流是有意简化的:构建一次镜像,然后在各处运行相同的镜像。不再把文件拷贝到服务器或重新运行安装脚本,而是把部署变成可复现的例行操作:拉取镜像,运行容器。
大多数团队遵循如下流水线:
myapp:1.8.3)。最后一步让 Docker 给人的感觉是“平淡无奇”的,这正是好事:
# build locally or in CI
docker build -t registry.example.com/myapp:1.8.3 .
docker push registry.example.com/myapp:1.8.3
# on the server / cloud runner
docker pull registry.example.com/myapp:1.8.3
docker run -d --name myapp -p 80:8080 registry.example.com/myapp:1.8.3
运行 Docker 化应用在云端常见两种方式:
为了在发布时减少中断,生产部署通常会加入三块基石:
注册表不仅是存储——它是你保持环境一致的方式。常见做法是把相同镜像在 dev → staging → prod 间提升(promote)(通常通过重新打标签),而不是每次重建。这样生产运行的就是你已经测试过的确切工件,减少了“在预发布能跑”的惊讶。
CI/CD(持续集成与持续交付)本质上是软件交付的装配线。Docker 让这条装配线更可预测,因为每个步骤都在已知的环境中运行。
一个适配 Docker 的流水线通常有三阶段:
myapp:1.8.3)。这个流程也便于向非技术干系人解释:"我们构建一个封闭的盒子,测试盒子,然后把同一个盒子发到每个环境。"
测试在本地通过但在生产失败,常因运行时不一致、缺少系统库或环境变量不同。把测试放在容器内能减少这些差距。CI 运行器不再需要精心调校的机器——只要有 Docker。
Docker 支持“提升,而不是重建”。流程是:
myapp:1.8.3 一次。各环境之间只变更配置(如 URL 或凭证),而不是应用工件。这减少了发布日的不确定性,并使回滚变得简单:重新部署先前的镜像标签即可。
如果你节奏很快并想在不花数天搭建脚手架的情况下获得 Docker 的好处,Koder.ai 可以通过聊天驱动的工作流帮助你生成面向生产的应用并把它整洁地容器化。
例如,团队常用 Koder.ai 来:
docker-compose.yml(让开发与生产行为保持一致),关键优势是 Docker 仍然是部署的基本单元,而 Koder.ai 加速了从想法到容器就绪代码库的路径。
Docker 让把服务打包并在一台机器上运行变得容易。但当你有多服务、多副本与多台服务器时,需要一个系统来协调这一切。编排就是用来决定容器运行位置、保证它们健康并随需求变化调整容量的软件。
只有少量容器时,你可以手动启动并在出问题时重启。但当规模增大,这种方式迅速失效:
Kubernetes(常简称为 K8s)是最常见的编排器。一个简单的心智模型:
Kubernetes 不负责构建容器;它运行容器。你仍然构建 Docker 镜像,把它推到注册表,随后 Kubernetes 在节点上拉取该镜像并启动容器。你的镜像仍是贯穿各处的可移植、可版本化的应用工件。
如果你只在一台服务器上运行少量服务,Docker Compose 可能已经足够。只有在你需要高可用、频繁部署、自动伸缩或多机容量与弹性时,编排才真正体现价值。
容器并不会自动让应用变得安全——它们主要使你更容易标准化与自动化应做的安全工作。好处是 Docker 提供了明确、可复现的点来加入审计与安全团队关心的控制措施。
容器镜像是你的应用加其依赖的捆绑体,因此漏洞往往来自基础镜像或你未直接编写的系统包。镜像扫描能在部署前检查已知 CVE。
把扫描作为流水线的门禁:发现重大漏洞就失败构建,并用修补后的基础镜像重建。保留扫描结果作为工件,以便合规审查时展示你发布的内容。
尽量以非 root 用户运行容器。许多攻击依赖容器内的 root 权限来突破或篡改文件系统。
还可考虑把容器文件系统设为只读,并仅挂载特定的可写路径(用于日志或上传)。这能减少攻击者入侵后可修改的范围。
不要把 API 密钥、密码或私钥复制进镜像或提交到 Git。镜像会被缓存与分享,机密可能广泛泄露。
应当在运行时通过平台的密钥存储(比如 Kubernetes Secrets 或云提供商的 Secrets Manager)注入机密,并限制只有需要的服务可访问它们。
与传统服务器不同,容器在运行时不会自我打补丁。标准做法是:用更新后的依赖重建镜像,然后重新部署。
设定重建节奏(每周或每月),即便应用代码未变也要重建;当高危 CVE 影响基础镜像时立即重建。这一习惯能让部署更易审计且风险更低。
即便团队“在用 Docker”,如果一些习惯潜入,仍会交付不可靠的云部署。以下是最常导致痛苦的错误及实用预防措施。
一个常见的反模式是“SSH 到服务器修一下配置”或 exec 进运行中的容器做热修复。它可能暂时生效,但之后没人能复现确切状态。
相反,把容器当作“牲畜(cattle)”:可丢弃、可替换。所有变更都要通过镜像构建与部署管道完成。若需调试,在临时环境排查,然后把修复固化到 Dockerfile、配置或基础设施设置中。
超大的镜像会拖慢 CI/CD、增加存储成本并扩大安全暴露面。
避免方法:
.dockerignore,不要把 node_modules、构建产物或本地密钥一并发上镜像。目标是构建在干净机器上也能快速且可复现。
容器并不能替你理解应用在做什么。没有日志、指标与追踪,你只能在用户抱怨时察觉问题。
至少确保应用将日志写到 stdout/stderr(而不是本地文件)、有基本健康端点并导出若干关键指标(错误率、延迟、队列深度)。然后把这些信号接入你云栈的监控系统。
无状态容器易于替换,有状态的数据则不是。团队常在太晚才发现:把数据库放在容器内“看起来可行”,但一次重启就把数据抹掉了。
提前决定状态在哪里:
Docker 非常适合打包应用——但可靠性来自于你对容器如何构建、如何被观测以及如何连接到持久化数据的刻意设计。
如果你刚接触 Docker,最快的价值路径是把一个真实服务端到端容器化:构建、在本地运行、推送到注册表并部署。用下面的清单把范围保持小且结果可用。
先挑一个无状态的服务(API、worker 或简单网页应用)。定义它启动所需的内容:监听端口、必要的环境变量以及任何外部依赖(比如你可以单独运行的数据库)。
目标很明确:“我能用同一个镜像在本地和云端运行该应用”。
写一个最小的 Dockerfile,能稳定构建并运行你的应用。优先考虑:
然后添加 docker-compose.yml 供本地开发使用,把环境变量与依赖(如数据库)接起来,而无需在笔记本上再安装额外软件。
如果日后需要更复杂的本地环境,可以逐步扩展——先保持简单。
决定镜像存放位置(Docker Hub、GHCR、ECR、GCR 等)。采用可以让部署可预测的标签约定:
:dev 用于本地测试(可选):<git-sha>(不可变,最适合部署):v1.2.3 用于发布在生产中避免依赖 :latest。
配置 CI:每次主分支合并时自动构建镜像并推送到注册表。你的流水线应当:
一旦这个流程稳定,你就能把发布步骤连接到云端部署并持续迭代。
Docker 通过将应用程序与其运行时和依赖项打包到镜像中,减少“在我机器上能跑”的问题。你可以在本地、CI 和云端运行同一个镜像,避免因操作系统包、语言版本或已安装库的差异而导致行为不同。
通常你只构建一次镜像(例如 myapp:1.8.3),然后在不同环境中运行多个容器实例。
虚拟机(VM)包含完整的来宾操作系统,因此通常更重、启动更慢。容器共享宿主机的内核,只打包应用运行所需的运行时和库,因此通常:
注册表是存放和版本化镜像的地方,其他机器可以从那里拉取镜像。
常见流程:
docker build -t myapp:1.8.3 .docker push <registry>/myapp:1.8.3这也使得回滚更容易:重新部署之前的标签即可。
使用不可变、可追溯的标签,这样你总能识别当前运行的内容。
实用方式:
:1.8.3:<git-sha>(或 : <sha>):latest(含糊不清)把环境特定的配置放在镜像之外。不要把 API 密钥、密码或私钥写进 Dockerfile 或提交到仓库。
替代方案:
.env 文件不被提交到 Git这样镜像可复用,避免意外泄露。
容器是可替换的,文件系统可在重启或重建时变化。使用:
经验法则:把程序运行在容器中,把状态放在专门的存储中。
当你想在本地或单机上用一致方式定义多服务栈时,Compose 很合适:
db:5432)当需要多机、多可用性、自动伸缩时,通常会使用编排器(如 Kubernetes)。
一个实用的流水线是:构建 → 测试 → 发布 → 部署:
优先采用“提升而不是重建”(promote, don’t rebuild),这样工件在各环境保持一致。
常见原因包括:
-p 80:8080)。调试步骤:先在本地运行与生产相同的镜像标签,比较配置差异。
这有助于回滚和审计。