2025年11月03日·1 分钟
多租户 SaaS 模式:隔离、扩展与 AI 设计
了解常见的多租户 SaaS 模式、租户隔离的权衡与扩展策略。查看 AI 生成的架构如何加速设计与评审。
什么是多租户(用通俗的话说)
多租户意味着一套软件产品从同一个运行系统为多个客户(租户)提供服务。每个租户感觉像拥有“自己的应用”,但在幕后他们共享基础设施的某些部分——比如相同的 Web 服务器、相同的代码库,通常也会共享数据库。
一个有帮助的类比是公寓楼。每个人都有自己的带锁单元(他们的数据和设置),但你们共享电梯、管道和维护团队(应用的计算、存储与运维)。
团队为什么选择多租户
大多数团队并不是因为多租户流行才选择它——而是因为它高效:
- 每位客户的成本更低: 共享基础设施通常比为每个客户单独部署整套系统便宜。
- 运维更简单: 只需监控、修补和加固一个平台(而不是成百上千个小部署)。
- 交付更快: 改进一次即可让所有客户受益,避免客户间出现“版本漂移”。
可能出问题的地方
两类经典失败模式是安全和性能。
在安全方面:如果租户边界没有在每个层面强制执行,漏洞可能导致客户之间的数据泄露。这些泄露很少是戏剧性的“入侵”——更多的是常见失误,比如缺失的过滤器、配置错误的权限检查,或在没有租户上下文的情况下运行的后台任务。
在性能方面:共享资源意味着一个繁忙的租户会拖慢其他租户。所谓“噪声邻居”效应可能表现为慢查询、突发性负载,或单个客户消耗不成比例的 API 容量。
本文涵盖模式的速览
本文介绍团队用来管理这些风险的构建模块:数据隔离(数据库、schema 或行级)、租户感知的身份与权限、噪声邻居控制,以及用于扩展和变更管理的运维模式。
核心权衡:隔离 vs 效率
多租户是一个关于你在“共享多少”与“为每个租户专属多少”之间选择的问题。下面的每种架构模式只是该谱系上的不同点。
共享资源 vs 专属资源:核心谱系
一端,租户几乎共享一切:相同的应用实例、相同的数据库、相同的队列、相同的缓存——通过租户 ID 和访问规则在逻辑上区分。这通常是运行成本最低且最容易管理的方式,因为你可以池化容量。
另一端,租户获得系统的“独立切片”:独立数据库、独立计算,有时甚至是独立部署。这增加了安全性和控制力,但也提高了运维开销和成本。
为什么隔离和成本会牵扯相反方向
隔离降低了一个租户访问另一个租户数据、消耗其他租户的性能预算或受异常使用模式影响的概率。它也让某些审计与合规要求更容易满足。
效率来自于把空闲容量在多个租户间摊销。共享基础设施让你运行更少的服务器,保持更简单的部署流水线,并基于总体需求而非单租户的最坏情况来扩展。
常见的决策驱动因素
你在谱系上的“正确位置”很少是哲学性的——更多由约束决定:
- SLA 与客户期望: 严格的可用性或延迟目标会让你倾向于更多隔离。
- 合规与数据驻留: 要求可能强制指定专用存储或专用环境。
- 增长阶段: 早期产品通常为更快速发展而倾向共享;后期可能为大客户引入专属选项。
- 运维成熟度: 更多隔离通常意味着更多需要监控、修补和迁移的对象。
一个简单的思考模型来选择模式
问两个问题:
-
如果一个租户行为异常或被攻破,可能的影响范围(blast radius)有多大?
-
缩小该影响范围的商业成本是多少?
如果影响范围必须极小,就选择更多专属组件;如果成本与速度最重要,则更多共享——并在共享时投入强有力的访问控制、速率限制和按租户的监控以确保安全。
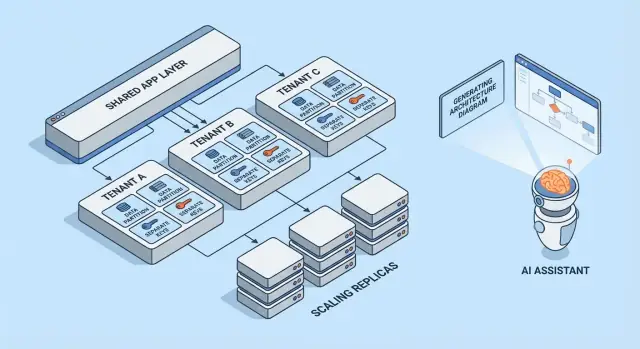
多租户模型一览
多租户不是单一架构——而是一组在客户之间共享(或不共享)基础设施的方式。最佳模型取决于你需要的隔离程度、预期租户数量以及团队能承担的运维开销。
1) 单租户(专属)——基线
每个客户获得自己的应用堆栈(或至少独立运行时与数据库)。这在安全与性能上最容易推理,但通常每位租户成本最高,也可能放慢你扩展运营的速度。
2) 共享应用 + 共享数据库 —— 成本最低,但需最高谨慎
所有租户运行在相同的应用和数据库上。成本通常最低因为你最大化复用,但你必须在各处严格维护租户上下文(查询、缓存、后台任务、分析导出)。一个失误就可能导致跨租户的数据泄露。
3) 共享应用 + 独立数据库 —— 更强的隔离,但运维更多
应用共享,而每个租户拥有自己的数据库(或数据库实例)。这增强了事故时的影响范围控制,便于租户级别的备份/恢复,并能简化合规讨论。代价是运维:更多数据库要配置、监控、迁移与加固。
4) 面向“大客户”的混合模型
许多 SaaS 产品混合使用上述方法:大多数客户在共享基础设施下运行,而大型或受监管的客户获得专属数据库或专属计算。混合往往是更实际的终态,但需要明确规则:谁有资格、费用如何、升级如何推进。
如果你想更深入了解每种模型内部的隔离技术,参见 /blog/data-isolation-patterns。
数据隔离模式(数据库、Schema、行)
数据隔离回答一个简单问题:“一个客户能否查看或影响另一个客户的数据?”常见三种模式,各自有不同的安全与运维影响。
行级隔离(共享表 + tenant_id)
所有租户共享同一套表,每行包含 tenant_id 列。这对于小到中等规模的租户最为高效,因为它最小化基础设施并让报表与分析保持简单。
风险也很明显:如果某个查询忘记按 tenant_id 过滤,就会泄露数据。即便是一个“管理员”端点或后台任务也可能成为薄弱环节。缓解方法包括:
- 在共享的数据访问层强制租户过滤(避免开发者手工写过滤器)
- 在可用的数据库上使用行级安全(RLS)等功能
- 添加自动化测试,有意尝试跨租户访问
- 为常用访问路径建立索引(通常是
(tenant_id, created_at)或(tenant_id, id)),以保证租户范围内查询高效
每租户 Schema(同一数据库,独立 schema)
每个租户有自己的 schema(命名空间,如 tenant_123.users、tenant_456.users)。相比行级共享这能提高隔离,并使租户导出或租户级别调优更容易。
代价是运维开销。迁移需要在大量 schema 上运行,失败会更复杂:你可能成功迁移 9900 个租户,却卡在 100 个上。监控和工具很重要——你的迁移流程需要明确的重试与报告行为。
每租户数据库(独立数据库)
每个租户拥有独立数据库。隔离性强:访问边界更清晰,单个租户的噪声查询不太可能影响其他租户,单个租户的恢复也更干净。
成本和扩展是主要缺点:更多数据库需要管理,更多连接池,以及潜在的升级/迁移工作。许多团队把该模型保留给高价值或受监管的客户,而小客户留在共享基础设施上。
随着租户增长的分片与放置策略
真实系统常把这些模式混合使用。常见路径是早期用行级隔离,然后将较大租户“升级”到独立 schema 或数据库。
分片(sharding)增加了一个放置层:决定某个租户在哪个数据库集群(按地域、规模等级或哈希)上。关键是让租户放置变得明确且可变——以便在不重写应用的情况下移动租户,并通过新增分片而非重设计整个系统来扩展。
身份、访问与租户上下文
多租户系统会以出人意料的普通方式失败:缺失过滤器、跨租户共享的缓存对象,或忘记请求属于哪个租户的管理员功能。解决之道不是某一个大安全功能——而是在请求的第一个字节到最后一个数据库查询之间,始终保持一致的租户上下文。
租户识别(如何知道“是谁”)
大多数 SaaS 产品选一个主要标识,并把其他作为便捷手段:
- 子域名:
acme.yourapp.com对用户友好,且适合租户品牌化体验。 - Header: 对 API 客户端和内部服务有用(但必须认证)。
- Token 声明: 签名的 JWT(或 session)包含
tenant_id,不易被篡改。
选择一个单一可信来源并在日志中记录。如果支持多个信号(子域名 + token),要定义优先级并拒绝模糊不清的请求。
请求作用域(如何让每个查询保持在租户内)
一个好的规则是:一旦解析出 tenant_id,下游所有代码都应从单一位置读取它(请求上下文),而不是重新推导。
常见的防护措施包括:
- 将
tenant_id附加到请求上下文的中间件 - 要求
tenant_id作为参数的数据访问辅助函数 - 数据库层的强制(如行级策略)使错误“失败关闭”
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
授权基础(租户内的角色)
将 认证(用户是谁)与 授权(能做什么)分开。
典型 SaaS 的角色是 Owner / Admin / Member / 只读,但关键是范围:某用户在租户 A 可能是 Admin,在租户 B 仅是 Member。权限应按租户存储,而不是全局存储。
防止跨租户泄露(测试与防护)
把跨租户访问当作高优先级事故并主动预防:
- 添加自动化测试,尝试以租户 A 的身份读取租户 B 的数据
- 让缺失租户过滤的错误更难被发布(linter、查询构建器、强制租户参数)
- 对可疑模式(如 token 与子域名的租户不匹配)进行日志记录与告警
如果你想要更深入的运维检查表,可将这些规则链接到你的工程运行手册(runbooks),位置如 /security,并与代码一起版本化。
超越数据库的隔离
用代码验证隔离
将隔离取舍转为可度量的可运行基线。
数据库隔离仅是故事的一半。许多实际的多租户事故发生在应用共享的管道周边:缓存、队列与存储。这些层快速、方便,也容易意外变成全局的。
共享缓存:防止键冲突与数据泄露
如果多个租户共享 Redis 或 Memcached,主要规则很简单:绝不存储无租户前缀的键。
一个实用模式是用稳定的租户标识作为前缀(而非电子邮件域名或显示名)。例如:t:{tenant_id}:user:{user_id}。这样做有两个好处:
- 防止不同租户使用相同内部 ID 导致冲突
- 在支持事件或迁移时,能通过前缀进行批量失效操作
同时明确哪些数据可以全局共享(例如公共特性开关、静态元数据)并记录——意外的全局项是跨租户暴露的常见来源。
租户感知的速率限制与配额
即便数据隔离,租户仍能通过共享计算影响其他租户。应在边缘加入按租户的限制:
- 每租户的 API 速率限制(通常也按租户内用户区分)
- 对昂贵操作(导出、报表生成、AI 调用)的配额
将限制公开(HTTP 头、UI 提示),让客户明白限流是策略而非系统不稳定。
后台任务:按租户分区队列
单一共享队列可能让某个繁忙租户主导工作线程。
常见修复:
- 按等级/方案分开队列(如
free、pro、enterprise) - 按租户桶分区队列(将 tenant_id 哈希到 N 个队列)
- 租户感知的调度,保证每个租户得到公平的片段
始终在任务负载与日志中传递租户上下文,避免错用租户造成副作用。
文件/对象存储:独立路径、策略与密钥
对于 S3/GCS 式存储,隔离通常基于路径和策略:
- 按租户单独 Bucket(严格隔离,但运维开销更大)
- 共享 Bucket + 租户前缀(更简单,但需仔细配置 IAM 与签名 URL)
无论选择哪种方式,都要在每个上传/下载请求上校验租户归属,而不仅仅在 UI 层。
处理噪声邻居与公平资源使用
多租户系统共享基础设施,这意味着一个租户可能意外(或故意)消耗超额资源。噪声邻居问题就是:一个响亮的工作负载会降低所有人的性能。
噪声邻居的表现
想象一个导出功能导出一整年的数据为 CSV。租户 A 在 9:00 安排了 20 个导出任务。这些导出饱和了 CPU 与数据库 I/O,导致租户 B 的正常页面开始超时——尽管 B 没有异常行为。
资源控制:限制、配额与工作负载整形
预防始于明确的资源边界:
- 速率限制:按租户与端点限制请求数,防止昂贵的 API 被刷。
- 配额:对导出、邮件、AI 调用或后台任务等设定日/月配额。
- 工作量整形:把重型任务(导出、导入、重建索引)放到带有按租户并发上限和优先级规则的队列里。
一个实用模式是把交互式流量与批处理工作分开:把用户请求放在快速通道,把其他全部推到受控队列。
每租户断路器与隔离舱(bulkheads)
增加当租户越界时触发的安全阀:
- 断路器(Circuit breakers): 当某租户的错误率、延迟或队列深度超限时,临时拒绝或延后昂贵操作。
- 隔离舱(Bulkheads): 将共享池(DB 连接、工作线程、缓存)隔离,使单个租户不能耗尽全局容量。
做得好时,租户 A 可能只影响自己的导出速度,而不会拖垮租户 B。
何时将租户迁移到专属容量
当租户持续超出共享假设时,应把其迁移到专属资源:持续高吞吐、不定期的突发与业务关键事件、严格合规需求,或需要定制调优的负载。一个简单规则是:如果为了保护其他租户必须持续限速某付费客户,就该考虑为其提供专属容量(或更高等级)而不是一直 firefight。
适用于多租户 SaaS 的扩展模式
控制噪声邻居
为每个租户构建速率限制和排队任务,防止噪声邻居影响系统。
多租户扩展不只是“更多服务器”,而是让某个租户的增长不会让所有人措手不及。最佳模式让扩展可预测、可衡量且可逆。
无状态服务的横向扩展
首先把你的 Web/API 层做成无状态:把会话存到共享缓存(或使用基于 Token 的认证)、把上传放到对象存储、把长时任务推到后台。只要请求不依赖本地内存或磁盘,就可以在负载均衡器后加实例并快速横向扩展。
实用提示:在边缘保持租户上下文(由子域或 Header 推导),并把它传递到每个请求处理器。无状态不等于无租户感知——意思是要在不依赖黏性服务器的情况下意识到租户。
每租户热点:识别并平滑它们
大多数扩展问题是“某个租户不同”。注意以下热点:
- 单个租户产生过高流量
- 少数租户拥有非常大的数据集
- 批处理式使用(如月末报表、夜间导入)
平滑策略包括按租户速率限制、基于队列的摄取、缓存租户特定的读路径、并把大租户分片到独立的工作池。
读副本、分区与异步工作负载
对读密集型工作(仪表盘、搜索、分析)使用读副本,并把写保持在主库。分区(按租户、按时间或两者)有助于保持索引小且查询快。对于昂贵任务——导出、ML 打分、Webhook——优先使用异步任务并保证幂等,以免重试放大负载。
容量规划信号与简单阈值
保持信号简单且具租户感知性:p95 延迟、错误率、队列深度、数据库 CPU、按租户请求率。设定简单阈值(例如“队列深度 > N 持续 10 分钟”或“p95 > X ms”),在影响其他租户之前触发自动扩缩或临时租户限额。
面向租户的可观测性与运维
多租户系统不会先整体失败——它通常先在某个租户、某个套餐或某个噪声负载上失败。如果你的日志与仪表板不能在几秒内回答“哪个租户受影响?”,值班就会变成猜测。
租户感知的日志、指标与跟踪
从一致的租户上下文开始贯穿遥测:
- 日志: 在每个请求与后台任务中包含
tenant_id、request_id与稳定的actor_id(用户/服务)。 - 指标: 输出按租户等级(至少是
tier=basic|premium)和按高层端点细分的计数器与延迟直方图(不要用原始 URL)。 - 追踪: 把租户上下文作为追踪属性传播,这样你可以把慢追踪过滤到特定租户并查看时间消耗点(DB、缓存、第三方调用)。
控制基数很重要:对所有租户的逐一度量可能成本高昂。常见折衷是默认按等级的指标,并支持按需的租户级钻取(例如对“流量前 20 的租户”或“当前违背 SLO 的租户”抽样追踪)。
避免在遥测中泄露敏感数据
遥测是一个数据导出通道。把它当作生产数据处理。
优先使用ID 而非内容:记录 customer_id=123,而不是名字、邮箱、Token 或查询负载。在日志/SDK 层做脱敏,并屏蔽常见机密(Authorization 头、API Key)。支持工单时把调试负载存到受控的单独系统——不要放在共享日志里。
按租户等级的 SLO(不要过度承诺)
定义与能力匹配的 SLO。高级租户可能享有更严格的延迟/错误预算,但前提是你有控制手段(速率限制、工作负载隔离、优先队列)。把等级 SLO 作为目标发布,并对等级与一组精选高价值租户进行追踪。
值班运行手册:多租户常见事故
你的运行手册应以“识别受影响租户”开头,然后列出最快的隔离动作:
- 噪声邻居: 限速该租户、暂停重负载任务或把它们移到低优先级队列。
- 数据库热点/失控查询: 启用查询超时,检查按租户排序的 top queries,应用索引或限制端点。
- 租户上下文错误(数据混淆): 立即禁用相关功能标志或端点,并验证访问检查的租户范围。
- 后台任务积压: 清空按租户分区的队列、限制并发并带着幂等保障重放。
运营目标很简单:按租户检测、按租户隔离、并在不影响所有人的前提下恢复。
部署、迁移与按租户发布
多租户改变了交付节奏。你不是在部署“一个应用”;你是在同时为许多客户维护共享运行时与共享数据通路。目标是在不强制全体租户同步大升级的情况下交付新特性。
滚动部署与低宕机迁移
偏好能容忍短时间混合版本的部署模式(蓝绿部署、金丝雀、滚动)。这只有在数据库变更也能分阶段进行时才可行。
一个实用规则是 扩展 → 迁移 → 收缩:
- 扩展(Expand): 添加新列/表/索引而不破坏现有代码。
- 迁移(Migrate): 分批回填数据(通常按租户)并验证。
- 收缩(Contract): 在所有应用实例不再依赖旧字段后再移除它们。
对于热点表,分批回填并做节流,否则迁移本身会在系统中制造噪声邻居事件。
面向租户的特性开关以便更安全的发布
租户级的特性开关让你全局发布代码,同时有选择地开启行为。
这支持:
- 为少数租户提供抢先体验
- 仅为受影响租户禁用特性以实现快速回滚
- 在不分叉部署的前提下做 A/B 实验
保持开关系统可审计:谁在何时为哪个租户启用了什么。
版本与向后兼容预期
假设某些租户在配置、集成或使用模式上可能滞后。设计 API 与事件时要有明确的版本机制,以免新生产者破坏旧消费者。
常见内部预期:
- 在迁移窗口内,新旧数据结构需要同时被读取。
- 弃用需有发布时间表(即便只是内部注记和面向客户的邮件模板)。
租户特定配置管理
把租户配置视为产品表面:它需要验证、默认值与变更历史。
把配置与代码分离(理想上也与运行时密钥分离),并支持配置无效时的安全模式回退。像 /settings/tenants 这样的小型内部页能在事故响应与分阶段发布中节省大量时间。
AI 生成架构的帮助(及其局限)
设置租户路由
在不重建现有栈的情况下测试子域或自定义域的租户路由。
AI 能加速多租户 SaaS 的早期架构思考,但不能替代工程判断、测试或安全评审。把它当作高质量的头脑风暴伙伴,产出草案——然后验证每个假设。
AI 生成架构应该做什么(和不应做什么)
AI 在生成选项和强调典型失败模式上很有用(例如哪里可能丢失租户上下文,或共享资源会产生意外)。但它不应决定你的模型、保证合规或验证性能。它看不到你的真实流量、团队能力或遗留集成中的边缘情况。
重要输入:需求、约束、风险、增长
输出质量依赖于输入。有用的输入包括:
- 当前与未来 12–24 个月的租户数量及每租户数据量预期
- 隔离需求(合同、监管、客户期望)
- 预算与运维能力(值班成熟度、SRE 支持、工具链)
- 延迟目标、峰值使用模式与租户突发性
- 风险容忍度:若某租户影响另一个,后果如何?
使用 AI 提出带权衡的模式选择
要求 AI 提供 2–4 个候选设计(例如:每租户数据库 vs 每租户 schema vs 行级隔离),并生成清晰的权衡表:成本、运维复杂度、影响范围、迁移工作量与扩展上限。AI 很擅长列出可转化为团队设计问题的注意点。
如果你想把“草案架构”更快验证成可运行的原型,像 Koder.ai 这样的 vibe-coding 平台可以通过聊天把这些选择变成真实的应用骨架——通常是 React 前端与 Go + PostgreSQL 后端——以便更早验证租户上下文传播、速率限制与迁移工作流。规划模式与快照/回滚等功能在迭代多租户数据模型时尤其有用。
使用 AI 生成威胁模型与检查清单
AI 可以起草简单的威胁模型:入口点、信任边界、租户上下文传播与常见错误(如后台任务缺失授权检查)。用它来生成 PR 与运行手册的审查清单——但要用真实的安全专业知识和你的事故历史来验证这些结果。
一个实用的团队选择清单
选择多租户方法更多是关于“匹配度”而非“最佳实践”:考量你的数据敏感度、增长速度以及能承担的运维复杂度。
分步清单(在 30 分钟的研讨中使用)
-
数据: 哪些数据会在租户间共享(如果有的话)?哪些数据绝对不能共置?
-
身份: 租户身份在哪里存放(邀请链接、域、SSO 声明)?如何在每次请求上建立租户上下文?
-
隔离: 决定默认隔离级别(行/Schema/数据库)并识别例外(例如需要更强隔离的企业客户)。
-
扩展: 识别你预期的首个扩展压力点(存储、读流量、后台任务、分析),并选取最简单能解决它的模式。
与工程与安全评审验证的问题
- 如果开发者忘记过滤器,我们如何防止跨租户访问?
- 我们每个租户的审计链(谁在何时做了什么)是什么样?
- 我们如何处理每租户的数据删除与保留?
- 一个错误迁移或失控查询的影响范围有多大?
- 我们能否为每个租户进行限速、配额与资源预算?
需要更深入设计工作的红旗
- “我们以后再加租户检查。”
- 共享管理工具在没有严格控制下可以看到所有数据。
- 没有每租户备份/恢复或事故响应计划。
- 单一队列/工作池没有按租户的公平性保障。
示例“推荐的下一步”摘要
推荐: 从行级隔离 + 严格的租户上下文强制开始,加入每租户限流,并为高风险租户定义升级到 schema/数据库隔离的路径。
下一步(2 周): 对租户边界做威胁建模,在一个端点上原型化强制措施,并在一个 staging 副本上进行迁移演练。有关发布指南,见 /blog/tenant-release-strategies。