2025年4月29日·2 分钟
如何构建用于定价实验的 Web 应用
规划、设计并交付一个管理定价实验的 Web 应用:变体、流量拆分、分配、指标、仪表盘与安全推出护栏。
规划、设计并交付一个管理定价实验的 Web 应用:变体、流量拆分、分配、指标、仪表盘与安全推出护栏。
定价实验是有结构的测试:向不同客户群展示不同价格(或打包方案),并衡量发生了什么——转化、升级、流失、每访客收入等。它类似于价格层面的 A/B 测试,但风险更高:错误可能会混淆客户、产生支持工单,甚至违反内部政策。
定价实验管理器是让这些测试可控、可观察且可回滚的系统。
可控性: 团队需要一个集中位置来定义在测试什么、在哪里针对谁。"我们改了价格" 不是计划——实验需要明确的假设、日期、定向规则和终止开关。
追踪: 若没有一致的标识(实验 key、变体 key、分配时间戳),分析将变成猜测。管理器应确保每次曝光和购买都能归因到正确的测试。
一致性: 客户不应该在价格页看到一个价格,在结账看到另一个。管理器应协调变体如何在各个界面应用,以保证体验一致。
安全性: 定价错误代价高昂。你需要诸如流量限制、资格规则(比如仅限新客户)、审批步骤和可审计性的护栏。
本文聚焦于一个 内部 Web 应用:管理实验的创建、变体分配、事件收集与结果报告。
它 不是 一个完整的定价引擎(税务计算、开票、多货币目录、按期折算等)。相反,它是让定价测试能定期、安全运行的控制面板与跟踪层。
定价实验管理器只有在明确知道它会做什么与不会做什么时才有用。收窄范围有助于产品易于操作并能安全发布,尤其当真实收入受到影响时。
至少,你的 Web 应用应允许非技术操作者端到端运行一个实验:
如果只做一件事,就把这些做好——使用清晰的默认值与护栏。
尽早决定你将支持哪些实验格式,以便 UI、数据模型与分配逻辑保持一致:
防止“范围膨胀”使实验工具变成脆弱的业务关键系统,请明确不做的项:
用可操作的术语定义成功,而不仅仅是统计学上的:
定价实验应用的成败取决于其数据模型。如果你无法可靠回答“这个客户什么时候看到了哪个价格?”,你的指标就会很嘈杂,团队会失去信任。
从一小套核心对象开始,它们应映射到产品中实际的定价方式:
在系统间使用稳定的标识符(product_id、plan_id、customer_id)。避免用“好看”的名字做键——它们会变。
时间字段同样重要:
还应考虑在 Price 记录上使用 effective_from / effective_to,以便你能重建任意时间点的定价。
明确地定义关系:
实际上,这意味着一个 Event 应携带(或可联接到)customer_id、experiment_id 与 variant_id。如果你只存 customer_id 并“稍后查分配”,当分配变更时会有错误的关联风险。
定价实验需要审计友好的历史。让关键记录不可变:
这种做法能保持报告一致,并使后续的治理功能(比如审计日志)更容易实现。
定价实验管理器需要清晰的生命周期,让每个人都明白哪些可编辑、哪些被锁定,以及实验状态变化时客户会怎样被处理。
Draft → Scheduled → Running → Stopped → Analyzed → Archived
为减少高风险上线,在实验推进过程中强制要求必要字段:
对定价而言,为 财务 与 法务/合规 添加可选门控。只有审批者可以把实验从 Scheduled → Running。若支持覆盖(如紧急回滚),在审计日志中记录谁覆盖、为何覆盖与何时覆盖。
当实验 Stopped(停止) 时,定义两个明确行为:
在停止时把这作为必选项,以免团队在停止实验时不声明客户影响。
分配是否正确,是值得信任的定价测试与噪声混乱的分水岭。你的应用应便于定义“谁”会看到某个价格,并确保他们持续看到相同的价格。
客户应在会话与设备之间保持相同变体(在可能的情况下)。这意味着分配必须是确定性的:给定相同的分配键与实验,结果始终相同。
常见方法:
(experiment_id + assignment_key) 做哈希并映射到变体。很多团队默认使用基于哈希的分配,并仅在需要时存储分配以便支持或治理。
你的应用应支持多种键,因为定价可能以用户级或账户级计算:
这个升级路径很重要:若某人匿名浏览后注册,你应决定是保留其原始变体(保持连续性)还是重新分配(身份更干净)。把它作为一个明确设置。
支持灵活分配:
在放量时保持分配的粘性:增加流量应是 新增 用户进入实验,而不是重新洗牌已有用户。
并发实验可能冲突。为此建立护栏:
一个清晰的“分配预览”页面(给定示例用户/账户)能帮助非技术团队在上线前验证规则。
定价实验最常在集成层失败——不是实验逻辑错,而是产品在某处显示了一个价格却在结账时收取了另一个。你的 Web 应用应让“价格是什么”与“产品如何使用它”非常明确。
把 价格定义 视为事实来源(变体的价格规则、生效日期、货币、税处理等)。把 价格交付 视为一个简单的机制,通过 API 或 SDK 获取被选中变体的价格。
这种分离让实验管理工具保持清晰:非技术团队编辑定义,而工程师集成稳定的交付契约,例如 GET /pricing?sku=...。
常见模式有两种:
实际做法通常是“客户端展示,服务器校验并计算”,并使用相同的实验分配。
变体必须遵循相同规则:
将这些规则与价格一起存储,以便每个变体可比且财务友好。
若实验服务变慢或宕机,产品应返回安全默认价格(通常为当前基线)。定义超时、缓存与明确的“失败关闭(fail closed)”策略,以免结账中断,并记录所有回退以量化影响。
定价实验的生死取决于测量。你的 Web 应用应在上线前强制要求清晰的决策指标、干净的事件和一致的归因方法,避免“上线后盲测”。
从一到两个用于决定胜负的指标开始。常见的定价指标:
一个实用规则:如果团队在测试后仍对结果争论不休,说明你可能没有明确定义决策指标。
护栏用于捕捉尽管短期营收看起来不错但可能造成损害的情况:
你的应用可以通过强制阈值(例如 “退款率不得增加超过 0.3%”)来执行护栏,并在实验页面上突出显示违规情况。
至少你的跟踪应在每个相关事件上包含稳定的实验与变体标识:
{
"event": "purchase_completed",
"timestamp": "2025-01-15T12:34:56Z",
"user_id": "u_123",
"experiment_id": "exp_earlybird_2025_01",
"variant_id": "v_price_29",
"currency": "USD",
"amount": 29.00
}
在摄取时把这些属性设为必需,而不是“尽力而为”。如果事件缺少 experiment_id/variant_id,把它路由到“未归因”桶并标记数据质量问题。
定价结果常常有延迟(续订、升级、流失)。定义:
这能让团队对何时结果可信达成共识,避免仓促结论。
只有当产品经理、市场和财务能在无需工程大幅参与的情况下运行工具时,定价实验工具才会生效。UI 应快速回答三个问题:当前有什么在运行?客户会发生什么变化?发生了什么和为什么?
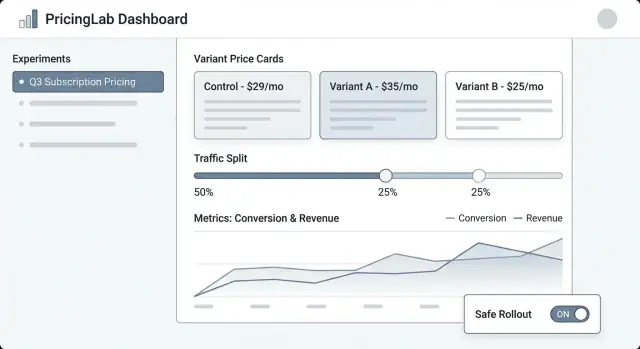
实验列表(Experiment list) 应像运维仪表盘:显示名称、状态(Draft/Scheduled/Running/Paused/Ended)、开始/结束日期、流量分配、主要指标与负责人。加上明显的“最后更新者”与时间戳,增强信任感。
实验详情(Experiment detail) 是主页面。顶部放紧凑摘要(状态、日期、受众、分配、主指标)。下方用标签页划分 Variants, Targeting, Metrics, Change log 与 Results。
变体编辑器(Variant editor) 要直观且有意见性。每行变体应包含价格(或价格规则)、货币、计费周期与一句易懂的描述(例如 “年付:$120 → $108”)。对在运行变体的误编辑要设置确认步骤。
结果视图(Results view) 应以决策为首要信息,而不仅仅是图表:“变体 B 将结账转化率提高了 2.1%(95% CI …)。”然后提供支撑的下钻与筛选。
使用一致的状态徽章并展示关键日期时间线。把流量分配既用百分比也用迷你条形图呈现。包含“谁改了什么”面板(或标签页),列出对变体、定向与指标的修改。
在允许 Start 前要求:至少选择一个主指标、至少两个有有效价格的变体、定义放量计划(可选但推荐)与回滚/回退价格。如果缺项,展示可操作的错误提示(例如 “添加主指标以启用结果展示”)。
提供安全且显眼的操作按钮:Pause(暂停)、Stop(停止)、Ramp up(放量)(例如 10% → 25% → 50%)与 Duplicate(复制为新草案)。对高风险操作使用确认框并总结影响(“暂停会冻结分配并停止曝光”)。
若想在投入完整构建前验证工作流(Draft → Scheduled → Running),可以用类似 Koder.ai 的 vibe-coding 平台快速搭出内部 Web 应用原型——然后用角色化页面、审计日志与简单仪表盘快速迭代。对早期原型尤其有用,能立刻产出可运行的 React UI 与 Go/PostgreSQL 后端并在后续导出与加固。
定价实验仪表盘应快速回答:"我们应保留此价格、回退,还是继续学习?" 最好的报告不是最花哨的,而是最容易信任与解释的。
从少量自动更新的趋势图开始:
图下放一个 变体对照表:变体名、流量占比、访客数、购买数、转化率、每访客收入与相对控制组的差值。
对置信度指标避免学术化用语。使用通俗标签:
短提示可解释置信度随样本量与时间增加而上升。
定价常常总体表现良好但关键群体失败。让细分切换变得简单:
在所有视图中保持一致的指标,以便比较直观。
在仪表盘上添加轻量级告警:
告警出现时展示疑似窗口与指向原始事件状态的链接。
使报告可搬运:当前视图的 CSV 下载(含分段)、可分享的内部报告链接。如果需要,链接一篇简短说明页 /blog/metric-guide,让干系人在不另开会的情况下理解他们看到的内容。
定价实验触及收入、客户信任与常被监管的报表。简单的权限模型与清晰的审计轨迹能降低意外上线、静默的“谁改了它?”争议,并让你更快、更安全地发布。
把角色设计得既容易解释又难以误用:
若有多个产品或区域,按工作区做权限作用域(例如 “EU Pricing”),以免一个区域的 Editor 影响另一区域。
你的应用应记录每次变更并注明 谁、做了什么、何时,最好包含“前/后”差异。至少要记录:
使日志可搜索并可导出(CSV/JSON),并直接从实验页面链接,便于审阅。提供一个专门的 /audit-log 视图供合规模块查看。
把客户标识与营收信息默认视为敏感:
在每个实验上添加轻量注释:假设、预期影响、审批理由与“为何停止”摘要。六个月后,这些备注会防止重复失败的想法并使报告更可信。
定价实验失败的方式往往很微妙:50/50 的分配漂移到 62/38、一个 cohort 看到错的货币或事件从未进入报表。在让真实客户看到新价格前,把实验系统当作支付特性来验证其行为、数据与失败模式。
从确定性测试用例开始,以证明分配逻辑在服务与发布间稳定。使用固定输入(customer IDs、experiment keys、salt)并断言每次都返回相同变体。
customer_id=123, experiment=pro_annual_price_v2 -> variant=B
customer_id=124, experiment=pro_annual_price_v2 -> variant=A
然后在大规模下测试分布:生成例如 1M 的合成 customer IDs 并检查观测到的分配是否在紧密容差内(例如 50% ± 0.5%)。同时验证边界情况,如流量上限(仅 10% 入组)与“保留组”。
不要仅停留在“事件触发了”。增加自动化流程:创建测试分配、触发一次购买/结账事件,并验证:
在预发布环境以及生产中针对仅限内部用户的测试实验运行这些检查。
给 QA 与 PM 一个简单的“预览”工具:输入一个 customer ID(或 session ID),查看会被分配到的变体与将展示的确切价格。这能在上线前捕获四舍五入、货币、税务展示或“错套餐”问题。
考虑提供一个不会改变真实分配的安全内部路由如 /experiments/preview。
演练最糟糕的场景:
如果你无法自信地回答“当 X 发生时会怎样?”,说明你还没准备好上线。
发布定价实验管理器不仅是“交付一个页面”,更在于确保能控制冲击半径、快速观察行为并安全恢复。
采用与信心与产品约束相匹配的上线路径:
把监控当作发布必需而非“可选”。设置告警用于:
为运维与 on-call 编写运行手册:
核心工作流稳定后,优先开发能提升决策质量的功能:更多定向规则(地域、套餐、客户类型)、更强的统计与护栏,以及集成(数据仓、计费、CRM)。若你有多个套餐或打包策略,考虑在 /pricing 上暴露实验能力说明以便团队理解支持范围。
它是一个内部控制面板与跟踪层,用于定价测试。它帮助团队定义实验(假设、受众、变体)、在各个界面展示一致的价格、收集可归因的事件,并在启动/暂停/停止时保留审计记录。
它有意不是完整的计费或税务引擎;它在现有定价/计费栈之上编排实验流程,使测试能够安全地反复运行。
一个实用的 MVP 应至少包含:
如果这些功能可靠,就可以在此基础上迭代更丰富的定向与报告功能。
建模能让你回答“这个客户在什么时候看到了什么价格?”通常需包含:
避免在关键历史上做可变性修改:对价格做版本控制,若需修正分配则追加新记录而不要覆盖已有记录。
建议使用类似 Draft → Scheduled → Running → Stopped → Analyzed → Archived 的生命周期。
在 Running 状态时锁定风险字段(变体、定向、分流),并要求在状态推进前进行校验(选择指标、确认跟踪、回滚计划)。这样可以防止“测试中途修改”造成结果不可信或客户体验不一致。
使用 粘性分配(sticky assignment),确保同一客户在不同会话/设备上尽量看到相同变体。
常见实现:
(experiment_id + assignment_key) 做哈希并映射到变体桶很多团队默认先用哈希,只有在需要治理或支持时才写入真实分配记录。
选择与客户定价体验匹配的分配键:
若先使用匿名键,需明确定义“身份升级”规则(在 signup/login 时保留原始变体以保持连续性,或重新分配以保持身份整洁)。
把 “停止(Stop)” 分为两个明确决策:
在停止实验时必须选择展示策略,确保团队在停止操作时明确客户影响。
保证展示价格与实际收费一致的要点:
还要定义当实验服务慢或不可用时的安全回退(通常回退至基线价格)并记录每次回退以便可视化影响。
要求一个小且一致的事件模式,所有相关事件都应包含 experiment_id 与 variant_id。
通常需要定义:
若事件到达时缺少 experiment/variant 字段,应将其归入“未归因”桶并标记数据质量问题。
使用简单明了的角色模型与完整的审计轨迹:
这能减少误发并方便财务/合规模块的审查与事后回顾。