2025年11月26日·2 分钟
如何构建用于跟踪运营瓶颈的 Web 应用
逐步指南:规划、设计并交付一个 Web 应用,用于采集工作流数据、发现瓶颈并帮助团队修复延迟。
从问题和决策开始
一个流程跟踪的 Web 应用只有在它能回答一个具体问题时才有用:“我们在哪里陷住了,应该怎么做?”在画界面或选架构之前,先定义在你的运营中“瓶颈”是什么意思。
定义什么算作瓶颈
瓶颈可以是一个步骤(例如“质检复核”)、一个团队(例如“配送”)、一个系统(例如“支付网关”),甚至是一个供应商(例如“承运方取件”)。选择那些你会实际管理的定义。例如:
- 当某个步骤的平均队列时间超过 24 小时时,该步骤即为瓶颈。
- 当在制品(WIP)在某个团队处持续高于阈值超过 3 天时,该团队为瓶颈。
- 当系统故障使得周期时间超出商定范围时,该系统为瓶颈。
列出应用必须支持的决策
你的运营仪表板应该推动行动,而不仅仅是报告。写下你希望更快、更有把握地做出的决策,例如:
- 人员配置:“本周我们是否把一个人从 A 团队调到 B 团队?”
- 优先级调整:“哪些订单/工单应该插队以保障 SLA?”
- 自动化:“哪个步骤既稳定又昂贵,应优先自动化?”
确定主要用户及他们的需求
不同用户需要不同的视图:
- 运营经理 需要一个明确的“今天该在哪里干预”的视图。
- 团队负责人 需要可下钻到单个队列、阻塞和交接的信息。
- 分析师 需要一致的定义和导出以做工作流分析。
为应用本身设定成功指标
决定如何判断应用是否有效。好的衡量标准包括采用率(每周活跃用户)、报告节省的时间,以及更快的解决速度(更短的检测时间和修复时间)。这些指标让你聚焦在结果而不是功能。
选择工作流并绘制简单流程图
在设计表结构、仪表板或告警之前,选一个你能用一句话描述的工作流。目标是跟踪工作在哪里等待——因此从小处着手,选择一到两个流程,它们重要且产生稳定量,例如订单履行、支持工单或员工入职。
范围紧凑能保持完成定义清晰,并防止项目因不同团队对流程“应该”如何工作的分歧而停滞。
从 1–2 个高信号流程开始
选择满足以下条件的工作流:
- 发生频繁(有足够的数据来发现模式)
- 至少包含一次交接(队列容易在此处形成)
- 有明确的客户影响(时间、成本、满意度)
例如,“支持工单”通常比“客户成功”更合适,因为它有明显的工作单位和时间戳化的操作。
用通俗语言绘制步骤和交接
用团队已在使用的词汇把工作流写成简单的步骤列表。你不是在记录政策——而是在识别工作项经过的状态。
一个轻量的流程图可能像这样:
- Ticket created → triaged → assigned → agent working → waiting on customer → resolved
在这个阶段,明确交接点(triage → assigned、agent → specialist 等)。交接是队列时间常常隐藏的地方,也是日后你要测量的关键时刻。
定义每个步骤的开始/结束事件以及“完成”的含义
对每个步骤写两件事:
- 开始事件(有什么能证明步骤开始了?)
- 结束事件(有什么能证明步骤完成了?)
保持可观测。“坐手开始调查”主观且难以跟踪;“状态变为 In Progress”或“添加了第一条内部备注”是可追踪的。
还要定义“完成”的含义,这样应用不会将部分完成误判为完成。例如,“resolved” 可能意味着“已发送解决消息且工单标记为 Resolved”,而不仅仅是“内部工作已完成”。
记录你稍后要跟踪的常见异常
真实的运营包含混乱路径:返工、升级、缺少信息和重新打开的工单。不要在第一天把所有东西都建模——只要写下异常,以便日后有意地添加它们。
像“10–15% 的工单会升级到二线支持”这样的简单备注就足够了。你会用这些备注来决定异常是否应该成为独立步骤、标签或单独流程,当你扩展系统时再处理。
定义能真正揭示瓶颈的指标
瓶颈不是一种感觉——它是在特定步骤上的可测慢速。在你建图表之前,决定哪些数字能证明工作在哪里堆积以及为什么堆积。
选择一小套核心指标
从四个适用于大多数工作流的指标开始:
- 周期时间(Cycle time):一个项从开始到完成花了多长时间。
- 等待/队列时间(Wait/queue time):一个项在步骤之间闲置了多长时间。
- 吞吐量(Throughput):单位时间内完成了多少项。
- 在制品(WIP):当前“系统内”有多少项。
这些指标覆盖速度(周期)、空闲(队列)、产出(吞吐)和负载(WIP)。大多数“神秘延迟”表现为某一特定步骤的队列时间和 WIP 增长。
定义计算方法(包括边界情况)
写出你的团队都能达成一致的定义,然后严格实现它们。
- Cycle time =
done_timestamp − start_timestamp。- 边界情况:工单被重新打开(当作新周期还是延长原周期)、从未开始的项(从周期时间中排除但计入 WIP)、缺失时间戳(标记为数据质量问题)。
- Queue time = 在状态为“等待”的步骤间隙时间之和。
- 边界情况:夜间/周末(使用日历时间还是营业时间)、阻塞状态(如需更清晰原因可与普通等待分开计数)。
- Throughput = 窗口内
done_timestamp在该窗口的项的计数。- 边界情况:取消(排除或单独跟踪)、部分完成。
- WIP = 在某一时点未处于终态的项的计数。
- 边界情况:挂起(仍属 WIP,但你可能想单独列出“被阻塞的 WIP”)。
选择能驱动决策的拆分维度
选择管理者实际会用到的切片:团队、渠道、产品线、区域 和 优先级。目标是回答“哪里慢、对谁慢、在什么条件下慢?”
设定时间窗口和目标值
决定你的报告节奏(常见的是每日和每周)并定义目标,例如 SLA/SLO 阈值(例如“80% 的高优先级项在 2 天内完成”)。有目标值会让仪表板可操作而非仅供装饰。
规划数据来源和采集方式
假设数据会“自己存在”是让瓶颈跟踪应用停滞的最快方式。在你设计表或图之前,写下每个事件和时间戳的来源——以及如何长期保持一致。
清点现有的数据源
大多数运营团队已经在少数地方跟踪工作。常见起点包括:
- 用于交接、日常记录或产量计数的电子表格
- ERP/CRM 系统(订单、客户、履行步骤)
- 工单系统(支持队列、变更请求、维护任务)
- 内部数据库(仓库扫描、作业调度表、制造执行数据)
对每个来源,记录它能提供什么:稳定的记录 ID、状态历史(而非仅当前状态)以及至少两个时间戳(进入步骤、退出步骤)。没有这些,队列时间监控和周期时间跟踪就是猜测。
为不同来源选择合适的采集方法
通常有三种选项,很多应用会混合使用:
- API 拉取:定期从 ERP/CRM/工单系统同步。易于推理,但需处理分页、速率限制和增量更新。
- Webhooks 推送:工作变化时推送更新。适合近实时瓶颈告警,但需设计重试和乱序事件处理。
- 手动录入 / CSV 导入:适合从电子表格起步或边缘场景。用模板、校验和清晰的错误信息保证安全性。
为数据质量做计划(因为问题肯定会出现)
预料到缺失时间戳、重复和不一致的状态(“In Progress” 与 “Working”)。及早建立规则:
- 优先使用不可变的事件日志而不是覆盖记录
- 通过 source ID + event time + status 去重
- 将状态标准化为应用的规范步骤
- 标记无法产生可靠周期时间跟踪的记录
决定刷新频率
不是所有流程都需要实时更新。根据决策类型选择:
- 实时:调度、支持分诊、SLA 风险
- 每小时:仓库吞吐、队列时间监测
- 每日:周报、持续改进评审
现在把这些写下来;它会驱动你的同步策略、成本和对运营仪表板的期望。
设计以时间分析为核心的数据模型
一个瓶颈跟踪应用的成败取决于它回答时间问题的能力:“这花了多久?”,“在哪儿等待?”,以及“在变慢之前发生了什么变化?”从第一天起围绕事件和时间戳建模,是支持这些问题的最简单方式。
从核心实体开始
保持模型精简且直观:
- Process:总体工作流(例如“订单履行”)。
- Step:流程内的阶段(例如“拣货”、“打包”、“发运”)。
- Work item:在步骤间移动的单位(工单、订单、索赔)。
- Event:记录状态变更(进入步骤、分配、被阻塞、完成)。
- User/Team 与 Assignment:在某一时刻谁负责该工作。
这种结构让你能测量每步的周期时间、步骤间的队列时间,以及整个流程的吞吐量,而无需发明大量特例。
优先使用事件日志而非“当前状态”字段
把每次状态变更视为一个不可变的事件记录。不要覆盖 current_step 并丢失历史,而是追加一条事件,例如:
- work_item_id
- from_step → to_step(或“entered_step”)
- event_type(assigned、started、blocked、completed)
- event_time
你仍可为性能存储“当前状态”快照,但分析应依赖事件日志。
把时间和可追溯性作为底线要求
统一以 UTC 存储时间戳。同时在工作项和事件上保留原始来源标识(例如 Jira issue key、ERP 订单 ID),这样每张图表都能追溯到真实记录。
捕获异常信息但别制造繁琐流程
为能解释延迟的瞬间设计轻量字段:
- reason_code(标准选项如 “Waiting on customer”)
- comment(可选文本)
- blocked_flag 或 severity
保持它们可选且容易填写,这样你能从异常中学习而不会把应用变成填写表单的工具。
选择适合团队的架构
快速部署试点
使用 Koder.ai 托管来试点你的内部工具,并与真实用户迭代。
“最佳”架构是团队能构建、理解并长期运维的那个。先选与招聘和现有技能匹配的技术栈——常见且成熟的选择有 React + Node.js、Django 或 Rails。可维护性比新奇更重要,尤其当这是大家每天都依赖的运营仪表板时。
分离关注点以保持系统可编辑
瓶颈跟踪应用通常在清晰分层时更易维护:
- 摄取层(Ingestion):接收事件(状态变化、时间戳、交接)来自表单、集成或导入。
- 存储层(Storage):用于可靠写入和审计历史的事务型数据库。
- 分析查询层(Analytics queries):用于计算周期时间、队列时间和吞吐量的读优化查询或视图。
- UI/API:保持仪表板快速且可预测的端点和界面。
这种分离让你在添加新数据源时无需重写全部内容。
决定计算放在哪一端
有些指标可在数据库查询中直接计算(例如“过去 7 天按步骤的平均队列时间”)。另一些则计算昂贵或需预处理(例如百分位、异常检测、每周队列)。实用规则:
- 在数据库做实时过滤和拆分。
- 使用后台作业预计算沉重的聚合,并存储以便仪表板快速加载。
- 只有在团队有信心维护时才加入专门的分析层。
提前考虑性能
当仪表板感觉慢时就会失败。在时间戳、工作流程步骤 ID 和 tenant/team ID 上做索引。对事件日志使用分页。缓存常见的仪表板视图(如“今天”和“最近 7 天”),并在新事件到来时使缓存失效。
如果需要更深入的权衡讨论,在代码仓库里保留一份决策记录,以免未来改动漂移。
想要快速上线的团队的快捷路径
如果目标是在承诺完整构建前验证工作流分析和告警,一个像 Koder.ai 的 vibe-coding 平台可以帮助你更快搭建首个版本:你在对话中描述工作流、实体和仪表板,然后迭代生成的 React UI 和 Go + PostgreSQL 后端,随之精炼 KPI 指标化。
对瓶颈跟踪应用的实际好处是反馈速度:你可以试点摄取(API 拉取、Webhooks 或 CSV 导入)、添加下钻屏幕,并在不需数周脚手架工作的情况下调整指标定义。当准备好时,Koder.ai 也支持源代码导出与部署/托管,便于从原型过渡到可维护的内部工具。
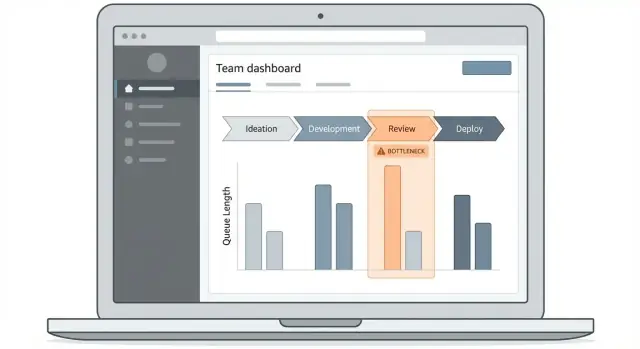
设计仪表板与下钻体验
瓶颈跟踪应用的成败在于人们能否快速回答一个问题:“现在工作在哪里被卡住了,哪些项导致了问题?”你的仪表板应让这条路径显而易见,即使是只来一周一次的人也能看懂。
从 2–3 个核心屏幕开始
把首个版本做紧凑:
- 概览仪表板:周期时间、队列时间和最堵塞步骤的“状态板”。
- 工作项列表:可搜索、可筛选的受延迟影响的项表格。
- 工作流详情:逐步视图,展示每步的停留时间和交接点。
这些屏幕形成自然的下钻流程,不会强迫用户学习复杂 UI。
使用能说明时间与流动性的可视化
选择能回答运营问题的图表类型:
- 阶段漏斗:显示体量在哪儿累积(便于发现队列)。
- 阶段停留时间柱状图:按中位数和百分位比较步骤,而不仅仅是平均值。
- 趋势线:回答“是否变好或变差?”(按周为单位)。
- 热力图:揭示诸如“周一在复核环节”或“夜班交接”之类的模式。
标签要通俗:“等待时间”而不是“队列延迟”。
让筛选器一致且显眼
在各屏幕使用同一个共享的筛选栏(相同位置,相同默认值):日期范围、团队、优先级 和 步骤。把生效的筛选以标签呈现,让人不会误读数据。
设计明确的下钻路径
每个 KPI 模块都应可点击并导向有用的页面:
KPI → 步骤 → 受影响的项列表
例如:点击“最长队列时间”打开步骤详情,再点一次显示当前在此等待的具体项——按年龄、优先级和负责人排序。这样把好奇心转化为具体待办,这正是让仪表板被使用而不是被忽视的关键。
添加告警与早期预警信号
可靠地捕获事件
设置 API 拉取、Webhook 或 CSV 导入,保留不可变事件日志。
仪表板适合会议回顾,但瓶颈最常在会议之间造成损失。告警把应用变成早期预警系统:在问题形成时你能发现,而不是等到一周都白干了。
从明确、平凡的规则开始
先从团队已认同为“坏”的少量告警类型开始:
- 阈值触发:周期时间或队列时间超过已知限制(例如 “Review step > 24 hours”)。
- 异常上升:今天的中位数周期时间较上周上升 30%。
- 卡滞项:N 小时/天内无状态变更,或超过最大存活时间的项。
把第一版做简单。少数确定性规则能捕获大部分问题,而且比复杂模型更容易被信任。
添加轻量的异常检测
当阈值稳定后,添加基本的“这不寻常吗?”信号:
- 与上周的百分比变化(按相同工作日比较可减少误报)。
- 移动平均漂移(例如 7 天均值稳步上升)。
- 量级不匹配(输入增长速度超过某步骤的输出)。
把异常标记为建议而非紧急:标注为“注意”直到用户确认它们有用。
在人员工作的场所推送告警
支持多渠道,让团队选择适合自己的方式:
- 邮件用于经理和每日摘要
- Slack / Microsoft Teams 用于实时分诊
- 应用内通知用于工具内的负责人
让每个告警都可执行
一个告警应回答“是什么、在哪儿、下一步怎么办”:
- 哪个步骤受影响,以及时间窗口
- 主要驱动因素(例如团队、分类、优先级)
- 到调查页面的直接链接,如:
/dashboard?step=review&range=7d&filter=stuck
如果告警不能引导到具体下一步,人们会屏蔽它们——把告警质量视为产品特性而非附属功能。
处理权限、安全与可审计性
瓶颈跟踪应用很快会成为“事实来源”。这很好——直到错误的人修改定义、导出敏感数据或将仪表板分享给不该看的对象。权限和审计轨迹不是繁文缛节;它们保护对数据的信任。
定义角色与访问规则
先从小而清晰的角色模型开始,仅在需要时扩展:
- Viewer(查看者):只读访问仪表板和报告。
- Manager(经理):能按团队筛选、创建保存视图、确认告警并添加备注(但不能修改全局设置)。
- Admin(管理员):管理流程定义、KPI 公式、集成和用户访问。
明确每个角色能做什么:查看原始事件 vs 聚合指标、导出数据、编辑阈值、管理集成等。
按团队或业务单元划分数据
如果多个团队使用该应用,应在数据层而非仅在 UI 强制隔离。常见方案:
- 多租户:每条记录有
tenant_id,每次查询都按此范围过滤。 - 分区/项目:为每个业务单元单独的“工作区”,有独立设置和仪表板。
及早决定管理者是否能查看其他团队的数据。把跨团队可见性作为有意的权限,而非默认行为。
安全认证(支持 SSO 或准备好 MFA)
如果组织有 SSO(SAML/OIDC),使用它以便离职和权限集中管理。如果没有,实现一个支持 MFA(TOTP 或 passkeys) 的登录,支持安全的密码重置并强制会话超时。
使变更可审计
记录会改变结果或暴露数据的操作:导出、阈值变更、流程编辑、权限更新和集成设置。捕获谁做了、何时做的、变更前后内容以及发生在哪个工作区。提供“审计日志”视图以便快速调查问题。
把洞察转化为行动与流程改进
只有当它改变人们接下来的行为时,瓶颈仪表板才有意义。本节目标是把“有趣的图表”变成可复用的运营节奏:决定、行动、衡量、保留有效方法。
创建轻量的瓶颈复盘机制
设定简单的每周节奏(30–45 分钟)并明确责任人。从按影响排序的 1–3 个瓶颈开始(例如最高队列时间或最大吞吐下降),然后为每个瓶颈达成一个行动。
保持流程精简:
- 负责人:每个行动一名责任人
- 到期日:默认下次复盘时
- 完成定义:一个可衡量的改变(而不是“继续调查”)
把决策直接记录在应用中,这样仪表板和行动日志保持连接。
把改进当作实验来跟踪
把修复当作实验,这样你能快速学习并避免“随机优化”。对每次变更记录:
- 假设(什么在拖慢,为什么)
- 变更(你将做什么)
- 预期影响(哪个指标会移动,幅度如何)
- 结果(实际发生了什么)
随着时间推移,这会成为减少周期时间、减少返工以及无效优化的玩法手册。
用注释增加上下文
没有上下文的图表会误导。在线时间轴上添加简单注释(例如新员工入职、系统宕机、策略更新),以便查看者正确解释队列时间或吞吐的变化。
简化分享方式
提供导出选项用于分析和报告——CSV 下载和定期报告——这样团队能把结果纳入运营更新和领导汇报。如果你已有报告页,从仪表板链接到它(例如 /reports)。
部署、监控并保持数据新鲜
先规划指标
在生成界面和表格之前,先锁定实体、指标和边界情况。
瓶颈跟踪应用只有在持续可用且数字可信时才有用。把部署和数据新鲜度当作产品的一部分,而不是事后补充。
使用独立环境与可重复的部署流程
尽早设置 dev / staging / prod。Staging 应镜像生产(相同数据库引擎、相似数据量、相同后台作业),以便在用户发现之前捕捉慢查询和失败的迁移。
用单一流水线自动化部署:运行测试、应用迁移、部署,然后做快速冒烟检查(登录、加载仪表板、验证摄取运行)。保持小且频繁的部署;这样能降低风险并便于回滚。
监控应用与数据流水线
需要两方面的监控:
- 应用健康:错误率、延迟、慢端点和慢查询。
- 数据健康:摄取失败、积压大小和“自上次事件以来的时间”。
对用户感知到的问题(仪表板超时)和早期信号(某一队列 30 分钟增长)都设告警。还要跟踪指标计算失败——缺失的周期时间看起来像“改善”。
保持数据新鲜:迟到事件、更正与回填
运营数据会迟到、乱序到达或被更正。要计划:
- 幂等摄取(重复处理同一事件不会重复计数)。
- 回填 某个数据源停机期间的日期范围。
- 重算 当参考数据发生变化时(例如更新的班次日历)。
定义什么是“新鲜”(例如 95% 的事件在 5 分钟内到达),并在 UI 显示新鲜度。
编写运行手册,让修复不再靠猜测
记录逐步运行手册:如何重启失败的同步、验证昨天的关键指标、确认回填没有意外改变历史数字。把它们存放在项目内并从 /docs 链接,以便团队能快速响应。
与用户迭代并扩展覆盖范围
当人们信任并真正使用它时,瓶颈跟踪应用才算成功。这只有在你观察实际用户尝试回答真实问题(“本周审批为什么慢?”)并据此围绕这些工作流打磨产品后才会发生。
从试点开始并观察哪里会出问题
从一个试点团队和少量工作流开始。保持范围足够窄,这样你能观察使用情况并快速响应。
在前一两周,关注哪些地方让人困惑或崩溃:
- 哪些图表被用户读错?
- 在下钻时他们在哪儿卡住?
- 他们期望看到但找不到哪些数据?
- 哪些运营瓶颈对他们而言“显而易见”但未在应用中反映?
在工具内捕获反馈(关键页面上的一个简单“这有用吗?”提示就很有效),这样你不必依赖会议记忆。
校验指标以避免“仪表板争论”
在向更多团队推广之前,与那些将被问责的人一起锁定定义。许多推广失败是因为团队对指标含义存在分歧。
对每个 KPI(周期时间、队列时间、返工率、SLA 违约),记录:
- 精确的开始和结束事件
- 暂停、周末与缺失时间戳的处理方式
- 异常如何计数(取消、升级、重新打开)
然后与用户复核这些定义,并在 UI 中添加简短的提示(tooltip)。如果调整了定义,显示清晰的变更日志以便人们理解数字为何变化。
在不把应用变成乱七八糟的情况下扩展覆盖范围
仅在试点团队的工作流分析稳定时才谨慎添加功能。常见的后续扩展包括自定义步骤(不同团队对阶段命名不同)、更多数据源(工单 + CRM + 表格)和高级分段(按产品线、区域、优先级、客户等级)。
一个有用的规则:一次添加一个新维度,并验证它是否改善了决策而非仅仅增加报告量。
让入门变得简单且可复用
当你向更多团队推广时,需要保持一致性。创建一份简短的入门指南:如何连接数据、如何解读运营仪表板、以及如何根据瓶颈告警采取行动。
在产品内链接相关页面和内容,例如 /pricing 和 /blog,这样新用户可以自助查找答案,而不是等培训。