2025年11月24日·1 分钟
如何为技术对比矩阵构建网站
学习如何规划、设计并构建一个承载技术决策对比矩阵的网站,包含清晰的评估标准、评分、过滤功能和对搜索引擎友好的页面设计。
学习如何规划、设计并构建一个承载技术决策对比矩阵的网站,包含清晰的评估标准、评分、过滤功能和对搜索引擎友好的页面设计。
对比矩阵的价值取决于它能帮人做出怎样的决策。设计表格、过滤器或评分之前,先明确谁会使用站点以及他们要决定的是什么。这样可以避免一个常见失败模式:做出漂亮的表格,但回答的是没人问的问题。
不同受众对同样的“功能对比”有不同解读:
为首个版本选定一个主要受众。可以继续支持次要用户,但站点的默认视图、术语和优先级应反映主要用户组的需求。
把矩阵必须支持的具体决策写下来。例如:
这些决策会影响哪些标准需要成为顶级过滤条件、哪些作为“详情”展示、哪些可以省略。
避免模糊目标如“提高参与度”。选择反映决策进程的指标:
“技术评估”可以包含多个维度。与团队对齐哪些最重要,例如:
用通俗语言记录这些优先项,这将成为后续所有选择的北极星:数据模型、评分规则、UX 与 SEO。
数据模型决定矩阵是否能保持一致、可搜索且易于更新。在画界面之前,先决定你要比较的“事物”、要衡量的内容,以及如何存储证据。
大多数技术对比站点需要以下构件:
把评估标准建模为可复用对象,并把每个供应商/产品的值存为单独记录(常称为“评估”或“标准结果”)。这样你新增供应商时无需复制标准列表。
不要把所有东西都强行塞成纯文本。选择与用户过滤和比较方式匹配的类型:
还要决定如何表示“未知”、“不适用”和“计划中”,避免空白被理解为“否”。
标准会演进。请存储:
为内部评论、谈判细节和审阅者信心设置字段(或单独表)。公开页面应展示值与证据;内部视图可以包含坦率的背景与后续任务。
当访客能预测内容在哪里以及如何到达时,对比矩阵网站才算成功。选择一个反映人们如何评估选项的信息架构。
从简单、稳定的分类法开始,不要每季度改动。以“问题域”而非供应商名来思考。
示例:
把树做浅层(通常两级就够)。若需更细的区分,用标签或过滤器(例如“开源”、“SOC 2”、“自托管”)而非深层嵌套,这有利于用户浏览并避免重复内容。
围绕少数可重复的页面模板设计:
再加上能减少混淆并建立可信度的配套页面:方法论、术语表、联系(更正、合作、数据来源)。
尽早决定 URL 规则,避免日后大量重定向。常见模式:
/compare/a-vs-b(或 /compare/a-vs-b-vs-c 用于多方)\n- 分类:/category/ci-cd保持 URL 简短、小写且一致。使用产品的规范名(或稳定的 slug),避免出现同一工具既有 /product/okta 又有 /product/okta-iam 的情况。
最后,决定过滤与排序如何影响 URL。如果希望过滤结果可分享,请规划干净的查询字符串(例如 ?deployment=saas&compliance=soc2),并保证基础页面在无参数时也可用。
矩阵只有在规则一致时才有助于决策。在加入更多供应商或标准之前,锁定“数学规则”与每个字段的含义,避免日后无休止争论(“我们说 SSO 支持是什么意思?”)并让结果具备可辩护性。
从规范标准列表开始,把它当作产品规格对待。每个标准应包含:
避免近似重复(例如“合规性”与“证书”)除非能明确区分。若需要变体(如“静态加密”和“传输中加密”),把它们拆成独立标准并分别定义。
只有在大家使用相同刻度时,分数才可比较。为每个标准写出评分量表:
定义每个刻度点的含义。例如,“3” 可能是“满足需求但有局限”,而“5” 是“全面满足且有成熟部署”。还要说明何时允许“不可用/不适用”。
权重会改变矩阵讲述的结论,请有意为之:
若支持自定义权重,设定护栏(如权重和为 100,或提供低/中/高预设)。
数据缺失不可避免。制定规则并始终如一地应用:
这些政策能保持矩阵公平、可重复并在增长时值得信赖。
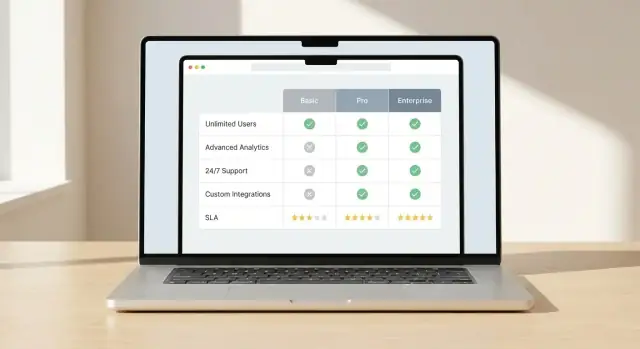
对比 UI 的成败取决于一件事:读者能否迅速看出有意义的差异。确定主要对比视图和一套视觉提示,让差异一目了然。
选一个主要模式并围绕它设计:
一致性很重要。用户在某处学会了如何看差异,其他地方应遵循相同规则。
避免迫使用户逐个扫描每个单元格。用刻意的高亮手法:
保持颜色含义简单且可访问:一色表示“更好”,一色表示“更差”,中性为背景。不要仅依赖颜色——加图标或简短标签。
长矩阵在技术评估中很常见,让它们可用:
移动用户不会容忍微小网格。提供:
当差异易于发现时,读者会信任矩阵并持续使用它。
当用户能在几分钟内缩小列表并看到有意义差异时,矩阵才显得“快速”。过滤、排序与并排视图是让体验顺畅的核心交互工具。
从反映真实评估问题的少量过滤器开始,而不是只根据易于存储的字段来设计。常用过滤器示例:
允许用户组合过滤条件。过滤时显示匹配数量,并明确如何清除过滤器。若某些过滤互斥,应阻止无效组合而非只显示“0 条结果”且无解释。
排序应反映客观与受众优先级。提供几种清晰选项:
若显示“最佳得分”,请说明该分数代表什么(整体得分或分类得分)并允许用户切换评分视图。避免隐蔽的默认项。
允许用户选择小集合(通常 2–5 个)并在固定列布局中比较。把最重要的标准置顶并对其余标准进行分组折叠以减少认知负担。
使对比可分享,链接应保留选择、过滤与排序信息,便于团队共用同一份候选名单而不重复构建。
导出对内部评审、采购与离线讨论有价值。若受众需要,提供 CSV(用于分析)和 PDF(用于分享)。导出文件应聚焦:包含所选项、所选标准、时间戳和评分备注,避免导出内容在后续查看时产生误导。
用户只有在信任你的矩阵时才会据此做决策。若页面在没有展示数据来源或核验时间的情况下做出强断言,读者会认为其有偏或过时。
把每个单元格当作一条需要证据的陈述。对于事实性内容(定价层限制、API 可用性、合规证书)在值旁存储“来源”字段:
在 UI 中以不凌乱的方式展示来源:小型“来源”标签在提示中或可展开行的方式均可。
提供能回答两个问题的元数据:“这有多新?”和“谁负责?”
为每个产品(或可选地为每个标准)显示“最后核验”日期,并指明负责复核的团队或个人。对于变化快的项(功能开关、集成、SLA 条款)尤其重要。
并非所有项都是二元的。对于主观标准(如上手难度、支持质量)或不完整项(供应商未公开细节)显示置信度等级,例如:
这可避免假精确,并鼓励读者查看备注。
在每个产品页上包含简要变更日志,记录关键字段的变更(定价、重大功能、安全态势)。读者能迅速了解有什么新变化,回访的利益相关者也可相信自己不是在对比过时信息。
对比矩阵只有在保持最新时才有用。在发布第一版之前,决定谁可以修改数据、这些变更如何复核,以及如何在大量行中保持评分一致性。
先选好矩阵数据的“事实来源”:
关键不是技术本身,而是你的团队能否可靠地更新而不破坏矩阵。
把变更当作产品发布来处理,而非随意编辑。
一个实用工作流示例:
若预期频繁更新,添加轻量约定:变更请求、标准的“更新理由”字段和定期复核周期(月度/季度)。
验证能防止矩阵隐性漂移:
手工编辑无法扩展。若有大量供应商或频繁数据源,规划:
当工作流明确并被执行,你的矩阵将保持可信,而可信才会驱动用户行动。
表面看起来简单的对比矩阵,体验依赖于如何高效获取、渲染并更新大量结构化数据。目标是在页面保持快速的同时让团队容易发布更改。
根据数据变化频率与交互需求选模型:
矩阵表格很快变重,务必提前考虑性能:
搜索应覆盖供应商名称、别名和关键标准标签。为相关性建立索引:
返回能直接跳到供应商行或标准段落的结果,而非仅仅展示通用的结果页。
跟踪能反映意图与摩擦的事件:
在事件负载中捕获活跃过滤器与被比较的供应商 ID,以便学习哪些标准真正驱动决策。
如果想快速上线对比站点——免去为 CRUD 管理界面、基础表格 UX 等花费数周时间——像 Koder.ai 这样的 vibe-coding 平台可以是实用捷径。你可以在聊天中描述实体(产品、标准、证据)、所需工作流(复核/审批)和关键页面(分类中心、产品页、对比页),然后迭代生成的应用。
如果目标技术栈与其默认匹配,Koder.ai 特别相关:网页端使用 React,后端为 Go,数据库为 PostgreSQL,并可选提供 Flutter 以便日后构建“已保存对比”的移动伴侣。你还可以导出源码,使用快照/回滚来调整评分逻辑,并在准备好时用自定义域名部署。
对比页面通常是高意图访问者的第一接触点(“X vs Y”、“最佳工具用于…”、“功能对比”)。SEO 最佳实践是在每页都有明确目的、稳定 URL 和真正不同的内容。
为每个对比页写独特的页面标题和 H1,匹配用户意图:
以简短摘要开篇,回答:本次对比适合谁、比较了什么、以及关键差异是什么。然后包含简要结论段(例如“适合 X 的为 A,适合 Y 的为 B”),避免页面仅仅是通用表格。
结构化数据在反映可见内容时能改善搜索结果展示:
避免在每页塞入大量你无法用证据支持的 schema 字段。准确性与一致性比数量更重要。
过滤与排序会生成许多相似 URL。决定哪些应被索引、哪些不应:
帮助搜索引擎和用户按相同路径导航:
使用描述性锚文本(“比较定价模型”、“安全特性”)而非重复性的“点击这里”。
对于大型矩阵,SEO 成功依赖于你有选择地不让某些页面被索引。把高价值页面加入站点地图(中心页、核心产品、策划对比)。把薄弱或自动生成的组合排除在索引之外,并监控爬取统计,确保爬虫把时间花在真正有助于决策的页面上。
矩阵能否长期发挥作用取决于它是否保持准确、易用且值得信赖。把上线当作开始,持续进行:测试、发布、学习与更新。
做可用性测试时关注真实结果:用户是否能更快且更有信心地做出决定?给参与者真实场景(例如“为 50 人团队且有严格安全要求选择最佳方案”)并衡量:
对比 UI 常常在基本无障碍上失败。上线前验证:
先抽查流量最高的供应商/产品与最重要的标准,然后测试边界情形:
在内部与外部设置期望:数据会变更。\n
定义用户如何报错或建议更新。提供简易表单并分门别类(数据错误、缺失功能、UX 问题),并承诺响应时限(例如 2 个工作日内确认)。随着时间推移,这将成为你最有价值的“下一步修复”来源。
从定义主要受众和他们要做出的具体决策开始(缩短候选名单、替换系统、RFP、验证需求)。然后选择与该受众约束匹配的评估标准和默认 UX。
一个好的内部自检:用户能否从落地页快速得到一个可辩护的候选名单,而不需要完整学会你的评分体系?
把每个单元格当作需要证据支持的声明。把证据与值一起存储(文档章节、发行说明、内部测试),并在 UI 中通过提示或可展开的备注展示出来。
同时展示:
使用能保持对比一致性的核心实体:
把标准建模为可复用对象,并分别存储每个产品的值,这样新增供应商时无需复制整套标准列表。
选择与用户筛选和比较方式相匹配的数据类型:
为 未知、不适用 和 计划中 定义明确状态,避免空白被误读为“否”。
使用一组可复用的页面模板:
用方法论、术语表和联系/纠错页面来增强可信度与清晰度。
制定可扩展且一致的 URL 规则:
/compare/a-vs-b(多项时 /compare/a-vs-b-vs-c)/category/ci-cd如果支持可分享的过滤视图,请让基础页面保持稳定并使用查询字符串(例如 ?deployment=saas&compliance=soc2)。同时规划规范化 URL,避免过滤和排序产生重复的 SEO 页面。
为每个评估标准写清晰的评分规则并选定合适的评分方式:
记录未知项如何影响总分(计为 0、视为中性或从总分中排除),并在全站一致应用该规则。
权重会改变矩阵讲述的故事,所以要有意为之:
如果允许自定义权重,设定护栏(例如权重和为 100,或提供低/中/高预设)。
围绕“快速生成候选名单”来设计:
如果受众需要采购或离线评审,提供 CSV/PDF 导出,并在导出中包含时间戳和评分说明,避免误导接收者。
大型矩阵常用的性能手段:
一个实用方案是混合渲染:预构建稳定页面,同时通过 API 加载交互式矩阵数据,这样页面既快又便于更新。