2025年9月14日·2 分钟
如何构建用于数据质量检查与告警的 Web 应用
学习如何规划并构建一个 Web 应用来运行数据质量检查、跟踪结果并发送及时告警,同时具备清晰归属、审计日志和可视化仪表盘。
学习如何规划并构建一个 Web 应用来运行数据质量检查、跟踪结果并发送及时告警,同时具备清晰归属、审计日志和可视化仪表盘。
在动手开发之前,先统一团队对“数据质量”的定义。一个用于数据质量监控的 Web 应用只有在所有人就其应保护的结果和所要支持的决策达成一致时才有用。
大多数团队会混合多种维度。挑出重要的维度,用通俗语言定义,并把这些定义作为产品需求:
这些定义成为你的数据校验规则的基础,帮助确定应用必须支持的数据质量检查类型。
列出坏数据的风险以及受影响方。例如:
这样可以避免只追踪“有趣”的指标而忽视真正伤害业务的问题,并且有助于设计Web 应用告警:正确的信息要到达正确的负责人。
明确是否需要:
明确延迟期望(分钟级 vs 小时级)。该决定会影响调度、存储和告警紧急程度。
定义上线后如何衡量“更好”:
这些指标让你的数据可观测性工作更有焦点,并帮助你在异常检测基础与简单规则校验之间优先取舍。
在编写检查前,先弄清你拥有什么数据、数据在哪里、以及出问题时谁能修复。现在做一个轻量的清单,可以避免后面数周的混乱。
列出所有数据产生或被转换的地方:
为每个来源记录一个 负责人(人或团队)、Slack/邮箱联系人和预期刷新频率。如果没有明确的负责人,告警也会无从路由。
挑选关键表/字段并记录依赖关系:
像“orders.status → revenue dashboard” 这样的简单依赖注记就足够开始。
根据影响与发生概率排序:
这些将成为你初始的监控范围和首批成功指标。
把已经遇到的具体失败写下来:静默的管道失败、缓慢的检测、告警缺乏上下文、责任不明。把这些转成后面章节的具体需求(告警路由、审计日志、调查视图)。如果你维护一页内部文档(例如 /docs/data-owners),在应用中链接它,以便响应者快速采取行动。
在设计界面或写代码之前,决定产品将执行哪些检查。这个选择决定了规则编辑器、调度、性能以及告警的可操作性。
大多数团队可从一组核心检查类型立即获益:
email 空值率不超过 2%”。order_total 必须在 0 到 10,000 之间”。order.customer_id 必须在 customers.id 中存在”。user_id 在单日内保持唯一”。让初始目录有明确意见性。以后可以添加小众检查而不让 UI 变得混乱。
通常有三种选项:
实际做法是“先 UI,再逃生舱”:提供模板和 UI 规则覆盖 80%,并允许自定义 SQL 解决其余场景。
让严重性有意义且一致:
明确触发条件:单次失败触发 vs “连续 N 次失败”、基于百分比的阈值、以及可选的抑制窗口。
如果支持 SQL/脚本,提前决定:允许连接范围、超时、只读权限、参数化查询,以及如何把结果规范化为通过/失败 + 指标。这能在保留灵活性的同时保护你的数据和平台。
数据质量应用能否成功取决于用户能多快回答三个问题:什么失败了、为什么重要、以及谁负责。如果用户必须翻日志或解读晦涩的规则名,他们会忽视告警并失去对工具的信任。
从一小套屏幕开始,支持从创建到解决的生命周期:
让主流程显而易见且可复用:
create check → schedule/run → view result → investigate → resolve → learn
“调查”应是一级动作。从一次失败运行中,用户应能跳转到数据集、查看失败指标/值、与历史运行比较,并记录原因说明。“学习”是鼓励改进的地方:建议调整阈值、添加配套检查或将失败关联到已知事故。
初期保持最小角色集:
每个失败结果页应展示:
当你把“控制平面”(配置与决策)与“数据平面”(执行检查与记录结果)分开时,数据质量应用更易于扩展和调试。
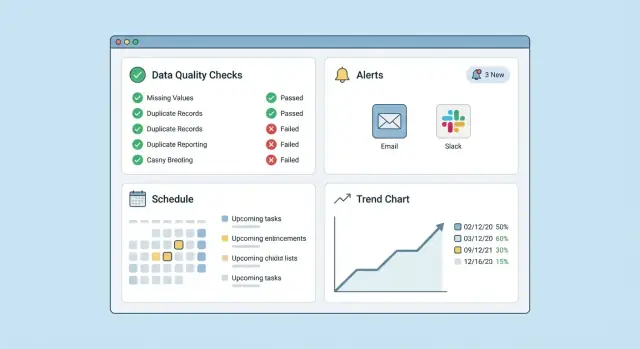
从一个回答“什么坏了,谁负责?”的屏幕开始。一个带过滤器的简单仪表盘能解决大部分问题:
从每一行用户应能进入运行详情页:检查定义、失败样本与最近一次成功运行。
围绕应用管理的对象设计 API:
保持写入小且有校验;返回 ID 与时间戳以便 UI 轮询并保持响应性。
检查应在 web 服务之外运行。使用调度器将任务入队(类似 cron),并允许 UI 发起按需触发。Workers 的职责:
该设计允许你对每个数据集设置并发限制并安全重试。
为不同需求使用独立存储:
这种分离能让仪表盘快速响应,同时在失败时保留详细证据。
如果想快速交付 MVP,像 Koder.ai 这样的代码生成平台可以根据书面规范(checks、runs、alerts、RBAC)快速引导出 React 仪表盘、Go API 和 PostgreSQL 模式。它适合快速生成核心 CRUD 流程和屏幕,然后对检查引擎与集成进行迭代。因为 Koder.ai 支持源码导出,你可以把生成的代码纳入自己的仓库并进一步强化。
好的数据质量应用表面看起来简单,是因为底层数据模型有纪律。目标是让每个结果都可解释:是什么运行了、针对哪个数据集、使用了哪些参数、以及随时间如何变化。
从一组小而清晰的一等对象开始:
为调查保留原始结果细节(失败行样本、出错列、查询输出片段),同时持久化汇总指标用于仪表盘与趋势。这种拆分让图表快速且不丢失调试上下文。
不要覆盖 CheckRun。追加式历史让你可以审计(“我们在周二知道了什么?”)并调试(“是规则变了还是数据变了?”)。在每次运行中记录检查版本/配置哈希。
为 Dataset 与 Check 添加标签,如 team、domain 与 PII 标记。标签可驱动仪表盘过滤,也支持权限规则(例如只有特定角色能查看带 PII 标记的数据集的原始失败行样本)。
执行引擎是数据质量监控应用的运行时:决定检查何时运行、如何安全运行、以及记录哪些信息以保证结果可信且可复现。
用调度器按周期触发检查(类似 cron)。调度器不应直接运行耗时任务——它的工作是入队。
队列(用数据库或消息代理支撑)能让你:
检查常常会针对生产数据库或仓库执行查询。设置护栏以避免错误配置的检查拖垮数据源:
同时记录“进行中”状态,并确保 worker 崩溃后任务能被安全拾取。
没有上下文的通过/失败难以信任。每次结果都应保存运行上下文:
这样你数周之后也能回答:“到底跑了什么?”
在激活检查前,提供:
这些功能能降低意外并在第一天就保持告警可信度。
告警是数据质量监控要么赢得信任、要么被忽视的地方。目标不是“把所有错误都通知我”,而是“告诉我接下来该做什么,以及有多紧急”。让每个告警回答三个问题:什么坏了、多严重、谁负责。
不同检查需要不同触发条件。支持几种覆盖大多数场景的模式:
让这些条件可在每个检查级别配置,并提供预览(“上月这设置会触发 5 次”)以便调优灵敏度。
同一事故反复告警会训练人们静音通知。加入:
同时追踪状态转换:对新失败告警,并可选在恢复时通知。
路由应基于数据驱动:按 数据集负责人、团队、严重性 或 标签(例如 finance、customer-facing)路由。该路由逻辑应配置化,而不是写死在代码里。
邮件和 Slack 覆盖大多数工作流且易于采用。设计告警负载以便未来容易拓展 webhook。为更深入的排查,在告警中直接链接到调查视图(例如:/checks/{id}/runs/{runId})。
仪表盘是让数据质量监控可用的地方。目标不是好看的图表,而是让人快速回答两个问题:“有什么坏了?”与“我接下来做什么?”
从一个紧凑且加载迅速的健康视图开始:
展示:
这个首屏应该像运维控制台:状态清晰、点击最少、标签一致。
从任何失败检查进入详细视图,支持在应用内调查而不是强制跳出:
包括:
如果可能,添加一键“打开调查”面板并链接(相对路径)到 runbook 与调试查询,例如 /runbooks/customer-freshness 与 /queries/customer_freshness_debug。
失败很明显;缓慢退化不明显。为每个数据集与每个检查增加趋势页:
这些图表让异常检测基础变得实用:团队能判断这是一次性问题还是持续模式。
每个图表和表格都应能追溯到底层运行历史与审计日志。为每个点提供“查看运行”链接,以便团队比较输入、阈值与告警路由决策。这种可追溯性建立了对数据可观测性与 ETL 数据质量工作流仪表盘的信任。
早期做出的安全决策要么让应用易于运维,要么带来持续风险与返工。数据质量工具会触及生产系统、凭据,有时还会触及受监管数据,因此应把它当作内部管理员产品来对待。
如果组织已有 SSO,尽快支持 OAuth/SAML。在此之前,邮件/密码对 MVP 可接受,但必须做好基础防护:加盐密码哈希、速率限制、账户锁定与 MFA 支持。
即便有 SSO,也要保留应急的“break-glass”管理员帐户,安全存放并限制使用。
把“查看结果”与“改变行为”分开。常见角色:
在 API 层强制权限,而非仅依赖 UI。考虑按工作区/项目做隔离,防止团队误改他人的检查。
尽量避免存储可能含 PII 的原始行样本。优先存汇总与摘要(计数、空值率、最小/最大、直方桶、失败行数)。如果确实需要样本做调试,应显式 opt-in、短期保留、掩码/脱敏并强制严格访问控制。
记录审计日志:登录事件、检查编辑、告警路由变更与密钥更新。审计轨迹能在配置变更时减少猜测并有助合规。
数据库凭据与 API key 不应以明文存储在数据库中。使用 vault 或运行时注入,并为轮换设计(允许多个活跃版本、记录上次轮换时间、并提供测试连接流程)。限制只有管理员能查看凭据,并在日志中记录访问但不记录密钥值本身。
在把系统交付用于抓取数据问题之前,证明它能可靠地检测失败、避免误报并能平滑恢复。把测试当成产品功能:保护用户免受嘈杂告警,也保护你免受监控盲区。
为支持的每种检查(新鲜度、行数、模式、空值率、自定义 SQL 等)创建样例数据集与金丝雀测试用例:一个应通过、若干应以特定方式失败。保持小、可版本化且可重复。
一个好的金丝雀回答:期望结果是什么?UI 应展示哪些证据?审计日志应记录什么?
告警逻辑的 bug 往往比检查本身更具破坏性。测试告警阈值、冷却与路由逻辑:
监控自身以便发现监控器失效:
编写清晰的故障排查页面,覆盖常见问题(作业卡住、凭据缺失、调度延迟、告警被抑制),并内部链接,例如 /docs/troubleshooting。包含“先检查什么”的步骤以及在哪里查找日志、运行 ID 与 UI 中的最近事故。
交付数据质量应用更像是小步快跑地建立信任而非一次性大投放。首个版本应证明闭环:运行检查、展示结果、发送告警并帮助某人修复真实问题。
从一组窄而可靠的能力开始:
MVP 应以清晰度优先而非灵活性。如果用户不明白为什么检查失败,就不会对告警采取行动。
如果你想快速验证 UX,可以用 Koder.ai 把 CRUD 密集的部分(检查目录、运行历史、告警设置、RBAC)先原型化,再决定是否完整实现。在内部工具场景下,快照与回滚功能在调优告警噪音与权限时特别有用。
把监控应用当作生产基础设施处理:
一个简单的“杀开关”能在早期采用阶段节省大量时间。
让前 30 分钟成功。提供模板,如“每日管道新鲜度”或“主键唯一性”,并在 /docs/quickstart 提供短小的设置指南。
同时定义轻量的归属模型:谁接收告警、谁能编辑检查、以及故障后“完成”的定义(例如:确认 → 修复 → 重跑 → 关闭)。
当 MVP 稳定后,根据真实事故扩展:
迭代目标是缩短诊断时间并降低告警噪音。当用户感受到该应用持续为他们节省时间时,采用会自发增长。
先把“数据质量”对你们团队意味着什么写清楚——通常包括 准确性、完整性、时效性和唯一性。然后把每个维度翻译成具体的结果(例如“orders 在早上 6 点前加载完成”,“email 空值率 < 2%”),并挑选成功指标,例如减少事故、更快的检测与修复、以及更低的误报率。
多数团队的最佳做法是同时支持 批处理 和 实时:
明确延迟期望(分钟 vs 小时),因为这会影响调度、存储和告警的紧急程度。
按优先级选出第一个 5–10 个绝对不能出错的数据集:
同时为每个数据集记录负责人和预期刷新频率,这样告警才能路由到能采取行动的人。
一个实用的 MVP 检查目录包括:
这些涵盖大多数高影响故障,而不用一开始就引入复杂的异常检测。
采用“先 UI,后逃生舱”的策略:
如果允许自定义 SQL,要施加护栏(只读连接、超时、参数化,以及把结果规范为通过/失败 + 指标)。
首个版本保持精简但完整:
每个失败视图应清楚展示 发生了什么、为何重要、以及谁负责。
把系统分成四部分:
这种分离能让控制平面稳定,而执行引擎按需扩展。
采用追加式(append-only)模型:
把可执行性和噪音控制放在第一位:
在告警中包含直接跳转到调查页面的相对链接(例如 /checks/{id}/runs/{runId}),并可选地在恢复时通知。
像对待内部管理类产品一样:
为每种支持的检查类型准备“金丝雀”数据集和测试用例:一个应通过的样例和多个应失败的样例,且这些用例要小、可版本化、可重复。每个金丝雀应回答:期望结果是什么?UI 应展示什么证据?审计日志应写入什么?
既要存汇总指标,也要保留足够的原始证据(在保证安全的前提下),并在每次运行时记录配置版本/哈希以区分“规则改了”还是“数据变了”。