2025年10月07日·2 分钟
如何构建物流追踪 Web 应用:司机与路线
规划并构建一个物流 Web 应用以追踪配送、司机与路线。了解核心功能、数据流、地图、通知、安全与上线步骤。
规划并构建一个物流 Web 应用以追踪配送、司机与路线。了解核心功能、数据流、地图、通知、安全与上线步骤。
在开始画界面草图或选择技术栈之前,先决定你的物流 Web 应用的成功标准。“追踪”可以有很多含义,而模糊的目标通常会导致一个杂乱、无人喜欢的产品。
选择一个主要业务目标和一两个支持目标。示例:
一个好的目标要足够具体以指导决策。例如,“减少晚点交付”会促使你优先考虑准确的 ETA(预计到达时间)和异常处理——而不是仅仅做一个更好看的地图。
大多数配送追踪软件有多个受众。尽早定义他们,避免只为某一角色构建所有功能。
限制在三个,这样你的 MVP 才能保持聚焦。常见指标:
把系统将捕获的确切信号写下来:
这个定义会成为产品决策和团队期望的共享契约。
在设计界面或选工具之前,就要就配送在你系统中的单一“真实流程”达成一致。清晰的工作流能防止“这个停靠点还在吗?”或“为什么我无法重分配这项工作?”之类的混淆——同时也让报表更可靠。
大多数物流团队可以在简单骨架上达成一致:
Create jobs → assign driver → navigate → deliver → close out(创建任务 → 分配司机 → 导航 → 交付 → 结项)。
即便你的业务有特殊情况(退货、多点投递、货到付款),也把骨架保持一致,并把变体作为“例外”处理,而不是为每个客户发明一套新的流程。
用简单明了的语言定义状态,并保证它们互斥。一个实用的集合是:
就每个状态变更的触发条件达成一致。例如,“En route(行驶中)”可在司机点击“开始导航”时自动触发,而“Delivered(已交付)”应始终由司机显式确认。
需要支持的司机操作:
需要支持的调度员操作:
为了减少后续争议,要记录每次变更的谁、何时、为什么(尤其是针对 Failed(失败) 与重新分配)。
清晰的数据模型能把“带点的地图”变成可靠的配送追踪软件。如果核心对象定义合理,调度看板更容易构建,报表更准确,运营也不需要临时变通。
将每次配送建模为一个会在状态间流转的任务(planned、assigned、en route、delivered、failed 等)。包含支持实际调度决策的字段,而不仅仅是地址:
提示:把取货与送达都视为“停靠点(stops)”,这样任务未来可以扩展为多停靠点而无需重设计。
司机不只是路线上的一个名字。捕获操作约束以使路线优化与调度更现实:
路线应保存有序停靠点列表,以及系统预期与实际发生情况的对比信息:
添加不可篡改的事件日志:记录谁在何时做了什么(状态更新、编辑、重新分配)。这支持客户争议、合规以及“为什么晚点?”的分析——尤其当它与交付证明和异常配合使用时。
优秀的物流追踪软件本质上是个 UX 问题:在正确的时间把正确的信息以最少的点击呈现出来。在构建功能之前,先草绘核心界面并决定每类用户能否在 10 秒内完成关键操作。
这是分配工作与处理问题的地方。让它“易读且以行动为先”:
保持列表视图速度快、可搜索并优化键盘操作。
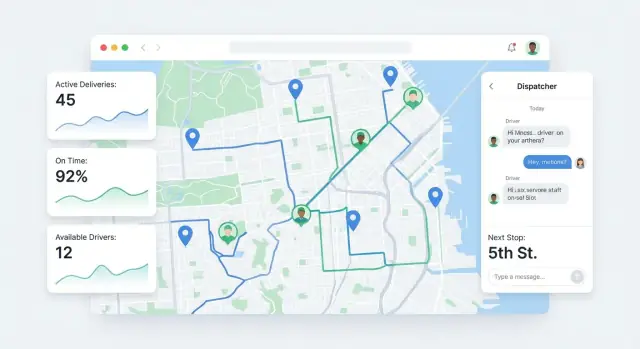
调度员需要一张能解释当天情况的地图,而不仅仅是一些点。
显示实时司机位置、停靠点图标与颜色编码的状态(Planned、En route、Arrived、Delivered、Failed)。添加简单切换:“仅显示晚点风险”、“仅显示未分配”和“跟随司机”。点击图标应弹出紧凑的停靠卡片,显示 ETA、备注与下一步操作。
司机屏幕应聚焦于下一个停靠点,而非整条计划。
包含:下一个停靠地址、指示(门禁码、放置说明)、联系按钮(呼叫/短信调度或客户),以及快速状态更新,最小化输入。如果支持交付证明,保持签名/拍照流程在同一操作链路内。
经理需要的是趋势而非原始事件:准时率、各区域交付时间、主要失败原因。让报表易于导出并便于做环比对比。
设计提示:在每个界面定义一致的状态词汇与配色系统——这能减少培训时间并避免代价高昂的误解。
地图是把“停靠列表”变成交付可执行信息的地方。目标不是华丽的制图——而是更少走错路、更清晰的 ETA、以及更快的决策。
大多数物流 Web 应用需要一套相同的地图功能:
尽早决定是依赖单一服务提供商(实现更简单)还是在内部抽象出一个提供层(现在工作量更大,但后续更灵活)。
错误地址是配送失败的主要原因之一。构建护栏:
分别存储原始文本地址与解析坐标,以便审计和修复重复问题。
先从手动排序(拖拽停靠点)加上实用助手功能开始:比如“聚合附近停靠点”、“把失败的投递移到末尾”或“优先处理紧急停靠”。随着对真实调度行为的了解再加入基础优化规则(最近下一个、最小化行驶时间、避免折返)。
即便是 MVP 的路线规划也应理解如下约束:
如果你在界面上清晰记录这些约束,调度员会信任系统生成的计划并知道何时需要人工覆盖。
实时司机追踪只有在可靠、易理解且节省电量的前提下才有用。在写代码前先决定“实时”对你的运营意味着什么:调度员需要逐秒更新,还是 30–60 秒一次就足够用来回答客户问题并应对延误?
更高的更新频率会让调度看板上运动更平滑,但会消耗更多电量和移动数据。
一个实用的起点:
你也可以在有意义事件(到达停靠点、离开停靠点)触发更新,而不是持续心跳式上报。
在调度界面上常见两种模式:
许多团队先用定期刷新,随着调度量增长再引入 WebSockets。
别只保存最新坐标。保留轨迹点(时间戳 + 纬度/经度 + 可选速度/精度),这样你可以:
移动网络会掉线。司机端应用应在信号丢失时本地排队位置事件,并在恢复时自动同步。在调度看板上,把司机显示为“上次更新:7 分钟前”而不是假装点位是实时的。
做好了的实时 GPS 追踪能建立信任:调度看到真实发生的事,司机不会因为不稳定的连接被误判。
通知与异常处理是把基础追踪变成可靠交付工具的关键。它们能帮助团队提前行动,减少客户来电。
从一小套对运营和客户都重要的事件开始:已派发、即将到达、已交付、交付失败。让用户选择渠道——推送、短信或邮件——以及谁接收哪些通知(仅调度员、仅客户或两者)。
实用规则:仅当状态发生变化才发送面向客户的消息,运营消息可以更详尽(停靠原因、联系尝试、备注)。
异常应由明确条件触发,而非主观判断。末端配送中常见异常:
当异常触发时,在调度看板展示建议的下一步操作:比如“致电收件人”、“重新分配”或“标记为延迟”。这能让车队管理决策更一致。
交付证明应对司机来说简单、对争议来说可验证。典型选项:
把 POD 存为配送记录的一部分,并使其可下载以供客服使用。
不同客户希望看到不同措辞。增加消息模板与按客户配置(时间窗、升级规则、静默时段)的能力。这样你的应用能在无需改代码的情况下适配不同客户的需求,随着交付量增长变得更灵活。
在第一次争议、第一次新增网点或第一个客户问“是谁改了这个配送?”时,账号与访问控制的问题才会显现。清晰的权限模型能防止误操作、保护敏感数据并提升调度团队效率。
从简单的邮箱/密码流程开始,但要做到可投入生产:
如果客户或大型客户使用身份提供方(Google Workspace、Microsoft Entra ID/AD),把 SSO 作为升级路径。即便 MVP 不立刻实现,也要设计用户记录以便后续链接 SSO 身份而不产生重复账户。
初期避免创建几十个微权限。定义少量与真实岗位对应的角色,然后根据反馈调整。
物流 Web 应用常见角色:
然后决定谁能执行敏感操作:
如果你有多个仓或网点,尽早实现类似租户的隔离:
这样能让团队聚焦,减少误操作其它网点的数据。
为争议、退款与“为什么改了路线?”的问题建立追加式事件日志,记录关键动作:
使审计条目不可变并支持按配送 ID 与用户查询。在配送详情页展示可读的“活动”时间线(参考 /blog/proof-of-delivery-basics)也很有帮助,让运营在不翻原始数据的情况下解决问题。
集成能把一个追踪工具变成日常运营中心。在写代码之前,列出现有系统并决定哪一个是订单、客户数据与计费的“真实来源”。
大多数物流团队会接触多个平台:订单管理系统(OMS)、仓储管理(WMS)、运输管理(TMS)、CRM 与会计系统。决定哪些数据你要拉入(订单、地址、时间窗、物品数量)以及哪些数据要推回(状态更新、交付证明、异常、费用)。
简单规则:避免重复录入。如果调度员在 OMS 中创建任务,就不要强制他们在你的物流应用里重新创建。
让 API 围绕团队熟悉的对象:
大多数情况用 REST 接口足够,而 webhooks 用于向外部系统推送实时更新(例如 “delivered”、“failed delivery”、“ETA changed”)。对状态更新要求幂等性以便重试不会重复事件。
即使有 API,运营团队仍会要求 CSV 功能:
增加定时同步(每小时/夜间)以及清晰的错误报告:哪些失败、为何失败以及如何修复。
如果工作流使用条码扫描器或标签打印机,定义它们如何与应用交互(扫描确认停靠、扫描确认包裹、在仓库打印标签)。先支持小范围常用设备,记录并扩展支持列表。
追踪配送与司机意味着处理高度敏感的运营数据:客户地址、电话号码、签名与实时 GPS。几项前期决策可以避免后续昂贵的事故。
至少在传输中用 HTTPS/TLS 加密。在静态数据上启用主机提供的加密(数据库、对象存储的照片、备份)。把 API 密钥与访问令牌放入安全的密钥管理,不要写在源码或共享表格里。
实时 GPS 有很强的功能,但不应过度精确。很多团队只需:
定义明确的保留期。例如:高频位置点保留 7–30 天,然后降采样为小时/日点用于分析。
对登录、追踪与公共 POD 链接添加速率限制以减少滥用。集中化日志(应用事件、管理员操作、API 请求)以便快速回答“是谁改了这个状态?”。
同时从第一天就规划备份与恢复:自动每日备份、已测试的恢复步骤以及一套应急检查清单,供团队在事故时按部就班执行。
只收集必要数据并记录用途。为司机追踪提供同意与告知,明确如何处理数据访问或删除请求。一份简短、通俗的内部与对外政策能很好地对齐预期,减少未来的惊讶。
物流追踪应用在真实世界成败:混乱的地址、晚点司机、糟糕的网络与高压下的调度员。扎实的测试计划、谨慎的试点和实用的培训能把“软件可用”变成“人们愿意用的软件”。
超越理想流程测试,重现日常的混乱:
包含 Web(调度)和移动(司机)流程,以及异常流程,如配送失败、回仓或客户不在场。
在崩溃前地图与追踪可能先变慢。测试:
测量加载时间与响应性,并设定团队可以监控的性能目标。
从一个仓或一个区域开始,而不是全公司推广。事先定义成功标准(例如:具有 POD 的配送占比、减少“我的司机在哪儿?”的电话、准时率提升)。每周收集反馈,快速修复问题后再扩展。
制作简短的快速入门指南、增加首用提示并设定明确的支持流程:司机在路上联系谁,调度如何上报 bug。人们知道在出错时该做什么会显著提高采纳率。
首次构建物流 Web 应用时,最快的交付方式是定义一个狭窄的 MVP 来验证调度与司机端的价值,再在工作流稳定后加入自动化与分析功能。
首版必须要有的 通常包括:创建配送并分配司机的调度看板、对司机友好的移动 Web 视图(或简易 App)用于查看停靠列表、基础状态更新(例如 Picked up、Arrived、Delivered),以及用于路线可见性的地图视图。
可选但常拖慢进度的功能: 复杂的路线优化规则、多网点规划、自动客户 ETA、自定义报表与大量集成。除非你已经确定这些会直接带来收入,否则把它们排除在 MVP 之外。
一个实用的技术栈示例:
如果你优先考虑快速上线、验证工作流,可以采用低代码 / 生成式工具先验证。比如文中提到的 Koder.ai,团队可在对话中描述调度看板、司机流程、状态与数据模型,生成一个可运行的 Web 应用(React 前端、Go + PostgreSQL 后端)。
这在试点阶段尤其有用:
当 MVP 证明了价值,你可以导出源码并继续用传统工程流水线开发,或继续通过该平台部署托管。
交付追踪软件的最大成本往往基于使用量:
如果需要估算这些项,建议访问 /pricing 获取快速报价或在 /contact 讨论你的具体工作流。
当 MVP 稳定后,常见的升级包括:客户追踪链接、更强的路线优化、交付分析(准时率、停留时间)、以及关键客户的 SLA 报表。
从一个主要目标开始(例如:减少延迟交付或减少“我的司机在哪儿?”的电话),然后定义3 个可衡量的结果,例如准时率、失败停靠率和空闲时间。这些指标能让 MVP 保持聚焦,避免“追踪”变成一个面面俱到但无重点的地图式产品。
为你的系统写出一份明确的、共享的定义,说明它会捕获哪些信号:
这会成为产品决策的契约,避免团队之间期望不一致。
保持状态互斥并明确触发条件。一个实用的基础集为:
决定哪些转换是自动的(例如司机点击“开始导航”时转为“行驶中”),哪些必须由人显式操作(例如“已交付”)。
把配送视为一个会包含多个停靠点(stops)的任务(job),这样未来扩展到多停靠点路由时无需重构。核心实体包括:
一份追加式事件日志是处理争议与分析的真实来源,应记录:
并包含谁、何时、为何,这样客服与运营能在不猜测的情况下回答“发生了什么?”
把能在 10 秒内完成动作的屏幕放到首位:
在地址输入环节加护栏:
同时分别保存原始文本地址和解析后的坐标,以便审计和修正上游数据问题。
采用在实用性与电量/流量之间平衡的更新策略:
结合事件触发的更新(到达/离开停靠点),并在界面显示“上次更新:X 分钟前”。
为不可靠的网络做好准备:
把角色数量保持精简并映射到真实工作:
如果有多个网点(仓/分部),尽早实现网点范围(branch/depot)划分,并对导出或派发后编辑等敏感操作施加更严格权限与审计记录。