如何构建用于集中通知控制的 Web 应用
学习如何设计并构建一个将多渠道通知集中管理的 Web 应用,包含路由规则、模板、用户偏好和投递跟踪。
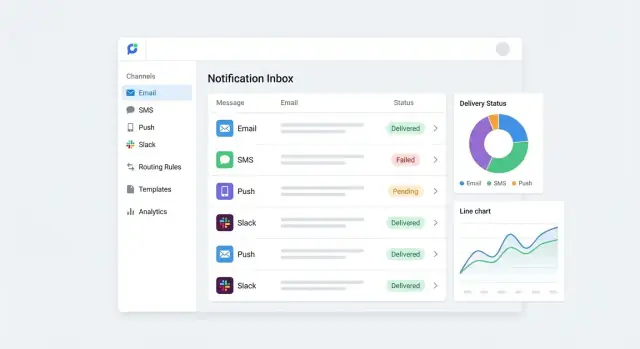
集中通知管理解决的问题
集中通知管理意味着将产品发送的每一条消息——邮件、短信、推送、应用内横幅、Slack/Teams、Webhook 回调——作为一个协调体系来对待。
与其让每个功能团队各自实现“发送消息”的逻辑,不如创建一个统一入口:事件进入、规则决定处理方式、投递端到端跟踪。
它消除了哪些痛点
当通知分散在各个服务和代码库时,相同的问题会反复出现:
- 逻辑重复:多个团队重新实现重试、限流、退订与格式化。
- 消息不一致:同样的“密码重置”或“发票已就绪”在不同渠道或产品区域表现不同,导致用户和支持困惑。
- 缺少审计轨迹:当客户说“我没收到”,很难回答到底发送了什么、发给谁、何时、为什么。
集中化用一个一致的工作流替代零散的发送:创建事件、应用偏好和规则、选模板、通过渠道投递,并记录结果。
谁会受益
通知集线器通常服务于:
- 管理员:无需发布部署即可配置渠道、模板、路由和合规规则。
- 支持团队:搜索并验证投递尝试、排查失败、并自信地回复用户。
- 产品团队:通过发出事件而不是构建新的通知流水线来更快上线功能。
- 终端用户:可控制偏好(选择/取消、静默时段、渠道),且结果可预测。
成功的样子
当如下情况出现时,说明方法奏效:
- 事故量下降,因为重试、限流和后备渠道被标准化。
- 更改(文案修改、路由调整、新收件人)耗时几分钟,而不是一个发布周期。
- 报告清晰:按渠道的投递率、投递耗时、失败原因,以及是谁做了哪些变更。
要求与范围:渠道、用例、约束
在草拟架构前,先明确“集中通知控制”对你组织意味着什么。清晰的需求能让首个版本有聚焦,避免集线器变成半成品的 CRM。
定义通知类型(以及它们为何不同)
先列出将支持的类别,因为它们决定规则、模板与合规:
- 事务型:密码重置、收据、账户变更。通常是必须且时间敏感的。
- 营销型:促销、简报、产品公告。始终需要按渠道处理加入/退订。
- 告警型:安全警告、故障、可疑活动。通常紧急,可能绕过部分偏好。
- 提醒型:预约、续费、未完成任务提醒。计时窗口与限频很重要。
明确每条消息属于哪个类别——这可防止“伪装成事务型的营销”。
选择渠道:现在支持 vs 以后支持
从一小撮可可靠运营的渠道开始,并记录“稍后”的渠道以免数据模型阻塞扩展。
现在支持(典型 MVP): 电子邮件 + 一个实时渠道(推送或应用内)或在产品依赖时选择 SMS。
以后支持: 聊天工具(Slack/Teams)、WhatsApp、语音、邮寄、合作方 Webhook。
同时记录渠道约束:速率限制、可达性要求、发送身份(域名、电话号码)以及单次发送成本。
设定非目标以保护范围
集中通知管理不是“所有与客户相关事务”的同义词。常见的非目标:
- 不做完整的联系人数据库富化(保持用户/收件人信息最小化)。
- 不提供带分群、A/B 测试或分析仪表的营销活动构建器。
- 不实现工单/升级工作流(与现有工具集成即可)。
合规与保留要求
提前收集规则以免后期返工:
- 按渠道与通知类型的同意/加入(尤其是营销消息)。
- 退订处理(必要时一键退订)与抑制名单。
- 保留策略:消息内容与元数据分别保留多长时间(例如 30/90/365 天)。
- 可审计性:是谁在何时修改了模板、路由或偏好。
若已有策略,请在内部链接到它们(例如 /security、/privacy),并将其作为 MVP 的验收标准。
通知集线器的高层架构
把通知集线器理解为一条流水线最容易:事件进入,消息发出,每一步都可观测。职责分离能让以后添加渠道(SMS、WhatsApp、推送)时不必重写全部代码。
核心组件
1) 事件摄取(API + 连接器)。 应用、服务或外部合作方将“发生了某事”事件发送到单一入口。常见摄取路径包括 REST 接口、Webhook 或直接 SDK 调用。
2) 路由引擎。 集线器决定应通知谁、通过哪个(些)渠道以及何时。该层读取收件人数据与偏好,评估规则并输出投递计划。
3) 模板与个性化。 根据投递计划,集线器渲染渠道特定消息(邮件 HTML、短信文本、推送负载),替换模板变量。
4) 投递 Worker。 与提供商(SendGrid、Twilio、Slack 等)集成,处理重试并遵守速率限制。
5) 跟踪与报告。 每次尝试都要记录:已接受、已发送、已投递、失败、已打开/点击(如可用)。这些数据支持管理员仪表盘与审计轨迹。
同步 vs 异步处理
仅在轻量摄取(例如校验并返回 202 Accepted)时使用同步处理。对于大多数真实系统,应采用异步:
- 摄取后入队,以保护应用免受提供商故障与流量冲击影响。
- 按渠道或优先级分队列(事务型 vs 营销),避免某一类流量饥饿其它流量。
环境与配置
尽早规划 dev/staging/prod。将提供商凭证、速率限制和功能开关存放在环境特有的配置中(不要把它们写入模板)。模板要版本化,以便在 staging 中测试更改再推到生产。
谁拥有规则与内容?
一个实用的划分:
- 工程师 负责事件 schema、集成与防护(超时、重试、幂等)。
- 管理员或运维 负责路由规则与模板文案,并为高风险渠道设置审批流程。
这种划分能在保持稳定骨干的同时,把日常消息改动从部署周期中剥离出来。
事件模型与数据契约
集中通知管理系统的成败取决于事件质量。如果产品的不同部分以不同方式描述“相同”的事,集线器将不得不不停翻译、猜测并出错。
定义清晰的事件 schema
先从一个小而明确的契约开始,供每个生产者遵循。实用的基线包括:
- event_name: 稳定标识(例如
invoice.paid、comment.mentioned) - actor: 谁触发(用户 ID、服务名)
- recipient: 接收者(用户 ID、团队 ID 或列表)
- payload: 生成消息所需的业务字段(金额、invoice_id、comment_excerpt)
- metadata: 路由与运营的上下文(租户/工作区 ID、时间戳、来源、语言提示)
这种结构使事件驱动的通知可理解,并支持路由规则、模板与投递跟踪。
为契约版本化(不要畏惧变更)
事件会演进。用版本化避免破坏,例如通过 schema_version: 1。如需破坏性更改,发布新版本(或新事件名),在过渡期同时支持旧版。这在多个生产者(后端服务、Webhook、定时任务)向同一集线器发送事件时尤为重要。
验证、清洗与幂等
把入站事件当作不可信输入,即便来自你自己的系统:
- 验证 必需字段与类型;拒绝或隔离格式错误的事件。
- 清洗 payload 字符串,防止在渲染模板时发生注入或格式问题(HTML 邮件、Slack/Teams markdown、短信)。
- 添加 幂等键(例如
idempotency_key: invoice_123_paid),使重试不会在多渠道通知中产生重复发送。
强健的数据契约能减少支持工单,加快集成,并让报告与审计日志更可靠。
用户、收件人与通知偏好
集线器要知道“谁”、如何联系他们,以及他们同意接收什么,才能工作。把身份、联系方式与偏好视为一等对象,而不是用户记录上的附属字段。
收件人 vs 用户
把 User(登录账户)与 Recipient(可接收消息的实体)分开:
- 一个用户可以有多个收件人(工作邮箱、个人邮箱、短信号、Slack 标识)。
- 一个收件人可以是共享目的地,如团队邮箱或值班轮值,而非单人。
对每个联系点存储:value(如 email)、channel 类型、标签、所属者与验证状态(未验证/已验证/被阻止)。还要保留元数据如上次验证时间与验证方式(链接、验证码、OAuth)。
偏好:按渠道、主题与时间
偏好应既有表达力又可预测:
- 按主题(例如 计费、 安全、 部署)
- 按渠道(电子邮件、SMS、推送、Slack)
- 静默时段(收件人本地时区),并对关键告警保留例外
用分层默认建模:组织 → 团队 → 用户 → 收件人,下层覆盖上层。这样管理员可设合理基线,个人可控制私人投递。
同意、退订与证明
同意不只是一个复选框。要存储:
- 按渠道与主题的加入/退订时间戳
- 同意来源(UI、API、导入)及执行者(用户/管理员/系统)
- 退订原因(自由文本或枚举)与临时抑制的过期时间
- 必要时的证据(双重加入令牌、Webhook 回调、签名记录)
使同意变更可审计并能从单一位置导出(例如 /settings/notifications),因为支持团队在用户询问“为什么收到/没收到?”时会用到它。
路由规则:谁在何时以何种方式收到通知
路由规则是集线器的“大脑”:决定哪些收件人应被通知、通过哪些渠道、在何种条件下发送。良好的路由能减少噪音同时不漏掉关键告警。
规则输入(“何时”和“谁”)
定义规则可评估的输入。首个版本保持精简但要有表达力:
- 事件类型(例如
invoice.overdue、deployment.failed、comment.mentioned) - 用户分群(角色、套餐、团队、地区、所有权——谁有资格收到)
- 严重度/优先级(info、warning、critical)
- 时间窗口(工作时间 vs 非工作时间;静默时段)
- 语言/区域(用于选择正确的模板与格式)
这些输入应从事件契约中派生,而不是由管理员在每条通知上手动输入。
规则动作(“如何”)
动作指定投递行为:
- 选择渠道:邮件、SMS、推送、Slack/Teams、Webhook、应用内收件箱
- 限频/汇总:限制重复(例如“每 30 分钟最多 1 条”)或对非紧急消息批量处理
- 升级:若在 X 分钟内未确认,则路由到值班人员
- 路由到值班:集成排班以便非工作时间将事件发给正确的人
优先级、后备与故障处理
为每条规则定义明确的优先级与后备顺序。示例:先尝试推送,若推送失败则用 SMS,再最后用邮件。
将后备策略与真实投递信号(退回、提供商错误、设备不可达)关联,并用明确上限阻止重试循环。
安全编辑与审核工作流
规则应能通过引导式 UI(下拉、预览与警告)编辑,具备:
- 草稿 vs 已发布 状态
- 高影响更改的 同行评审/审批
- 模拟模式(在示例事件上显示“谁会收到”)
- 将每次更改与管理员与时间戳关联的 审计轨迹
模板与本地化以保持一致的消息体验
模板是把“散乱的消息”变成一致产品体验的地方。良好的模板系统能保持语调在各团队间一致、减少错误,并让多渠道投递(邮件、短信、推送、应用内)显得经过设计而非即兴。
模板结构:可预期、关注渠道差异
把模板视为结构化资产而非一段文本。至少应保存:
- 主题/标题(邮件主题、推送标题、应用内头部)
- 正文(邮件 HTML + 文本;推送/短信的短/长版本)
- 变量(类型化占位符,如
{{first_name}}、{{order_id}}、{{amount}}) - 格式规则(每个渠道允许的标记、最大长度、链接策略)
让变量带有显式 schema,以便系统能校验事件 payload 是否提供了所有必需字段,防止发送“Hi {{name}}”这种半渲染的消息。
本地化:语言选择与缺失翻译处理
定义收件人语言选择策略:优先用户偏好,再到账户/组织设置,最后使用默认(通常为 en)。为每个模板存储每种 locale 的翻译并制定清晰回退策略:
- 若缺少
fr-CA,回退到fr。 - 若缺少
fr,回退到模板的默认语言。 - 若某 locale 的必需翻译缺失,阻止该 locale 的发送或切换到默认语言,并在投递元数据中记录回退。
这样可以让缺失翻译在报告中可见,而不是默默退化。
预览与测试发送流(管理员 + QA)
提供模板预览,允许管理员选择:
- 渠道(邮件/SMS/推送)
- 语言
- 示例事件 payload(真实采集的事件或模拟 JSON)
渲染最终消息,完全等同于管道将要发送的内容,包括链接重写与截断规则。添加一个测试发送,目标为安全的“沙箱收件人列表”,避免误发给客户。
版本与审批以防事故
模板应像代码一样版本化:每次更改创建一个不可变版本。使用状态流如 Draft → In review → Approved → Active,并可设置基于角色的审批。可一键回滚。
为审计记录谁在什么时候为何修改,并将其与投递结果关联,以便能把失败激增与模板编辑关联起来(另见 /blog/audit-logs-for-notifications)。
渠道集成与投递流水线
集线器的可靠性取决于最后一公里:实际负责发送邮件、短信和推送的渠道提供商。目标是让每个提供商看起来像“可插拔”的组件,同时保持跨渠道的一致投递行为。
每个渠道先集成一个提供商(从一开始)
从每个渠道选择一个支持良好的提供商开始,例如 SMTP 或邮件 API、一个 SMS 网关、一个推送服务(通过供应商使用 APNs/FCM)。将集成封装在统一接口后面,以便将来可切换或新增提供商而无需重写业务逻辑。
每个集成都应处理:
- 认证与请求签名
- 负载映射(你的消息 → 提供商格式)
- 提供商特定约束(附件限制、发送者 ID、退订头)
构建投递流水线,而不仅仅是 API 调用
把“发送通知”当作一条有明确阶段的流水线:enqueue → prepare → send → record。即便应用规模不大,基于队列的 worker 模型能防止慢速提供商调用阻塞 Web 应用,并为安全实现重试提供场所。
实用做法:
- Web 应用写入“投递任务”到队列
- Worker 拉取任务、调用提供商,然后存储结果
- 可选的 webhook 异步更新状态(有些提供商会稍后确认)
标准化状态与错误处理
提供商返回的响应差异巨大。把它们规范化为单一内部状态模型,例如:queued、sent、delivered、failed、bounced、suppressed、throttled。
为调试保留原始提供商载荷,但仪表盘与告警基于规范化状态。
重试、退避、速率限制与批量
实现带指数退避和最大尝试次数的重试。仅对短暂性失败(超时、5xx、限流)重试,不对永久性错误(无效号码、硬退回)重试。
通过为每个提供商加上速率限制来尊重提供商限制。对于高并发事件,在提供商支持的情况下进行批量(例如批量邮件 API),以降低成本并提高吞吐。
跟踪、状态与报告仪表盘
集线器的可信度建立在可见性上。当客户说“我没收到那封邮件”时,你需要快速回答:发了什么,走了哪个渠道,之后发生了什么。
定义清晰的投递状态
在渠道间标准化一小组投递状态以保持报告一致。实用基线为:
- queued(已接受,等待发送)
- sent(已交付给提供商)
- delivered(渠道确认已投递时)
- bounced(永久投递失败,通常是邮件)
- failed(因错误或提供商拒绝无法发送)
- opened(若可用,如部分邮件提供商;短信/推送通常不可用)
把这些状态视为时间线,而非单一值——每次消息尝试可能发出多条状态更新。
构建可搜索的消息日志
为支持与运营创建一个易用的消息日志。至少应支持按以下项搜索:
- 收件人(用户 ID、邮箱、电话)
- 事件(例如
invoice.paid、password.reset) - 时间范围(今天、最近 7 天)
包含关键细节:渠道、模板名/版本、语言、提供商、错误代码与重试次数。默认安全:屏蔽敏感字段(部分隐藏邮箱/电话)并通过角色限制访问。
将消息与上游事件关联
添加 trace ID 来把每条通知与触发动作(结账、管理员更新、Webhook)关联。使用相同 trace ID 写入:
- 原始事件记录
- 通知请求
- 所有投递尝试与状态更新
这能把“发生了什么?”变成一个单一过滤视图,而不是跨多个系统去追查。
真正有用的仪表盘
把仪表盘聚焦在可决策的信息上,而非展示性指标:
- 按渠道和事件的 发送量(发现峰值)
- 按提供商、模板和原因的 失败(发现故障与坏数据)
- 按发送次数与失败率的 热门模板(优先改进)
从图表允许下钻到消息日志,确保每个指标都可解释。
安全、访问控制与可审计性
集线器触及客户数据、提供商凭证与消息内容——因此必须将安全设计内置而非后置。目标很简单:只有合适的人能改动行为,秘密保持安全,且每次更改可追溯。
基于角色的访问控制(RBAC)
从少量角色开始并将其映射到关键操作:
- Admin: 管理组织设置、用户与保留策略。
- Notification Manager: 编辑路由规则、模板与本地化字符串。
- Integration Manager: 添加/更新渠道提供商密钥(邮件/SMS/推送)、Webhook 与回调 URL。
- Viewer/Auditor: 仅读取仪表盘与审计轨迹权限。
采用“最小权限”默认:新用户默认不得编辑规则或凭证,需显式授予权限。
秘密处理与凭证轮换
提供商密钥、Webhook 签名密钥与 API 令牌必须端到端作为秘密处理:
- 在静态存储加密(KMS/托管密钥库),并限制解密权限到投递服务。
- 支持无停机轮换(存储多个活动密钥、版本化并允许分阶段切换)。
- 在日志与错误追踪中脱敏敏感字段;若消息体可能包含 PII,尽量避免记录。
值得信赖的审计日志
每次配置变更都应写入不可变审计事件:谁、何时、何处(IP/设备),以及变更前后值(对秘密字段做掩码)。追踪对 路由规则、模板、提供商密钥 与 权限分配 的改动。提供简单导出(CSV/JSON)以便合规审查。
保留与删除请求
为每类数据(事件、投递尝试、内容、审计日志)定义保留期并在 UI 中说明。对删除请求,支持删除或匿名化收件人标识,同时保留汇总投递指标与掩码过的审计记录(如适用)。
管理与终端用户的 UX
集中通知集线器的成败取决于可用性。大多数团队并不每天管理通知——直到出现故障或事故。为快速浏览、安全改动与清晰结果而设计 UI。
管理控制台:关键页面
规则 应该像策略一样可读,而不是代码。使用“IF 事件… THEN 发送…”的表格表示法,并用渠道(Email/SMS/Push/Slack)标签显示。包含一个模拟器:选一个事件,精确展示谁会在何时以何种方式收到消息。
模板 适合左右并排的编辑与预览。允许管理员切换语言、渠道与示例数据。提供模板版本控制、发布步骤与一键回滚。
收件人 支持个人与组(团队、角色、分群)。显示成员关系(“为什么 Alex 在值班?”)并展示收件人在规则中被引用的位置。
提供商健康 应一目了然:投递延迟、错误率、队列深度与最近事故。把每个问题链接到可读的解释与下一步操作建议(例如“Twilio 认证失败——检查 API key 权限”)。
终端用户设置:简单明了的控制
保持偏好轻量:渠道选择、静默时段和主题/类别切换(如“计费”、“安全”、“产品更新”)。在顶部显示一段通俗的摘要(“您会通过 SMS 接收安全告警,任何时间”)。
包含合规的退订流程:营销消息一键退订,并在关键告警无法关闭时给予清晰说明(“为保障账户安全,关键告警无法关闭”)。当用户禁用某渠道时,确认变更的影响(“已停用 SMS;邮件仍然启用”)。
面向运维的实用工具
运维在高压环境下需要安全工具:
- 重发(带护栏:速率限制、确认、默认仅发原始接收人)
- 取消 计划中的通知并留审计轨迹
- 抑制 噪声来源(有时间限制)
- 事故模式:覆盖路由(例如升级到值班)并暂停非关键消息
指导性的空状态与可执行的错误信息
空状态应指导下一步(“还没有规则——创建第一条路由规则”)并链接到下一步(例如 /rules/new)。错误信息应说明发生了什么、影响范围和可采取的下一步——避免内部行话。尽可能提供快速修复(“重新连接提供商”)和“复制详情”按钮以便工单使用。
MVP 计划、测试与上线策略
集中通知集线器可以扩展成大平台,但应从小处开始。MVP 目标是在最少要素下验证端到端流(事件 → 路由 → 模板 → 发送 → 跟踪),然后安全扩展。
如果要加速首个可用版本,像 Koder.ai 这样的 vibe-coding 平台可以帮助快速搭建管理员控制台与核心 API:构建 React 前端、Go 后端与 PostgreSQL,在聊天驱动的工作流中迭代——并使用规划模式、快照与回滚功能在精细调整规则、模板与审计日志时保持变更安全。
一个仍能证明概念的最小 MVP
将首版刻意做窄:
- 一个事件类型(例如“请求密码重置”或“发票已支付”)。
- 一个渠道(通常是电子邮件)且仅一个提供商集成。
- 基础模板,带简单变量(姓名、日期、金额)与文本回退。
- 一个简易管理员 UI,展示发送与状态(queued/sent/failed)。
该 MVP 要回答的问题是:“我们能否可靠地把正确的消息发送给正确的收件人,并看到发生了什么?”
保护投递与信任的测试策略
通知是面向用户且时间敏感的,自动化测试很快就能体现价值。关注三类测试:
- 路由测试: 给定事件与收件人偏好,断言选定的渠道与抑制规则。
- 模板测试: 使用示例数据渲染模板,校验必需变量并确保转义(避免损坏的 HTML 或错乱的短信文本)。
- 重试与故障测试: 模拟提供商超时与错误,确认重试策略、幂等性(无重复)与死信处理。
在 CI 中添加少量端到端测试,发送到沙箱提供商账号。
无惊喜上线的策略
采用分阶段部署:
- 影子模式: 处理事件并生成“将要发送”的记录,但不实际投递。
- 逐步放量: 先内部用户,再逐步放大到一小部分生产事件。
- 回退到遗留: 若集线器故障,自动路由回旧的发送路径直到问题解决。
MVP 之后的路线图
稳定后按明确步骤扩展:加入渠道(SMS、推送、应用内)、更丰富的路由、改进的模板工具与更深入的分析(投递率、投递时长、退订趋势)。
常见问题
在 Web 应用背景下,什么是集中通知管理?
集中通知管理是一个单一系统,它接收事件(例如 invoice.paid),应用用户偏好和路由规则,为不同渠道渲染模板,通过提供商(邮件/SMS/推送等)投递,并端到端记录结果。
它用一致的管道替代各处的“在这里发封邮件”式的临时实现,从而便于运维和审计。
如何判断我的产品是否需要一个通知集线器?
常见早期信号包括:
- 多个团队重复实现重试、限流、退订和格式化逻辑
- 用户在不同渠道/功能看到同一操作的措辞不一致
- 支持无法快速回答“是否发送了?”因为日志分散
- 当某个提供商降级时频繁出现事故(没有队列、没有后备、没有标准重试)
如果这些问题反复出现,构建一个通知集线器通常能很快收回成本。
我应该先支持哪些渠道(哪些可以稍后再加)?
先从可可靠运营的小集合开始:
- 电子邮件加一个实时渠道(推送或应用内),或者如果产品依赖则选择 SMS
记录“以后支持”的渠道(Slack/Teams、Webhook、WhatsApp 等),以便数据模型将来扩展不致破坏现有功能,但 MVP 阶段避免集成过多渠道。
MVP 应包含哪些内容以验证集中通知控制可行?
一个实用的 MVP 要证明端到端流程可行(事件 → 路由 → 模板 → 投递 → 跟踪),同时保持最小复杂度:
- 一个事件类型(例如 密码重置 或 发票已支付)
- 一个渠道(通常是电子邮件)和一个提供商集成
- 基本模板与必需变量校验
- 至少包含
queued/sent/failed的消息日志
目标是可靠性与可观测性,而不是功能广度。
我应该为通知标准化什么事件 schema?
使用小而明确的事件契约,这样路由和模板就不需要猜测:
event_name(稳定标识)actor(触发者)recipient(接收者)payload(用于生成消息的业务字段)metadata(租户、时间戳、来源、语言提示)
添加 schema_version 和 幂等键,以免重试导致重复发送。
如何防止在重试和多渠道场景下发生重复通知?
幂等性可以避免在生产者重试或集线器重试时产生重复发送。
实用方法:
- 要求每个事件包含
idempotency_key(例如invoice_123_paid) - 在接收或创建投递任务时去重
- 将决策(路由计划 + 模板版本)与该键关联并持久化
这对多渠道和重试密集的流程尤为重要。
我应该如何建模用户、收件人和通知偏好?
将身份与可接触点分离:
- User:登录账户
- Recipient:可接收消息的端点(邮件、电话、设备令牌、Slack 身份)或组(团队邮箱、值班轮值)
为每个联系人记录验证状态(未验证/已验证/被阻止),并采用分层默认偏好(组织 → 团队 → 用户 → 收件人)。
从第一天起应构建哪些合规与同意功能?
从一开始就把合规和同意建模好,并保证可审计:
- 每个渠道和通知类型的加入/退订时间戳、来源和执行者
- 退订处理(必要时的一键退订)
- 抑制名单与过期机制(临时抑制)
- 内容与元数据的保留策略
在一个可导出的视图中保留同意历史,便于支持团队回答“我为什么会收到/没收到?”的问题。
如何在不同提供商之间一致地跟踪投递状态?
将不同提供商的返回结果标准化为统一的内部状态机:
queued、sent、delivered、failed、bounced、suppressed、throttled
为调试保留原始提供商响应,但基于标准化状态驱动看板和告警。把状态视为时间线(一次消息尝试可以有多个状态更新),而不是单一最终值。
哪些管理工具和安全措施可以防止路由与模板出错?
使用安全操作模式与护栏:
- 规则/模板的草稿与发布流程,并对高风险更改要求审批
- 发布前仿真(“谁会收到?”)
- 通过版本化模板实现一键回滚
- 可控的重发(确认、速率限制,默认仅发给原始接收人)
- 临时抑制和“事故模式”以暂停非必要消息
所有更改都要有不可变的审计日志,记录是谁在什么时候做了什么。