2025年7月10日·1 分钟
用于邮件和 Webhook 的简单后台任务队列模式
学习如何用简单的后台任务队列发送邮件、生成报表并可靠投递 webhooks,包含重试、退避与死信处理,无需复杂工具。
学习如何用简单的后台任务队列发送邮件、生成报表并可靠投递 webhooks,包含重试、退避与死信处理,无需复杂工具。
任何可能超过一两秒的工作都不应该在用户请求中执行。发送邮件、生成报表和投递 webhooks 都依赖网络、第三方服务或缓慢的查询。有时它们会暂停、失败或比预期更慢。
如果在用户等待时直接执行这些工作,人会立刻注意到:页面卡住,“保存”按钮转圈,请求超时。重试也可能出现在错误的地方:用户刷新、负载均衡重试、前端重复提交,最终导致重复邮件、重复的 webhook 调用或两个报表同时竞争资源。
后台任务通过让请求保持简短和可预测来解决这个问题:接受动作,记录一条稍后执行的任务,快速响应。任务在请求之外运行,由你控制规则。
难点在于可靠性。一旦工作脱离请求路径,你仍需回答诸如:
许多团队的回应是引入“笨重”的基础设施:消息代理、独立的 worker 群、仪表盘、告警和操作手册。这些工具在确实需要时很有用,但它们也增加了新的移动部件和新的失败模式。
一个更好的起步目标是更简单:用已有组件实现可靠的任务。对大多数产品来说,这意味着基于数据库的队列加上一个小的 worker 进程。再加上明确的重试与退避策略,以及对持续失败任务的死信处理。这样你能在第一天就获得可预测的行为,而无需承诺复杂平台。
即便你用像 Koder.ai 这样的聊天驱动工具快速构建,这种请求与后台分离仍然很重要。用户现在应当得到快速响应,而系统应在后台安全地完成缓慢、易失败的工作。
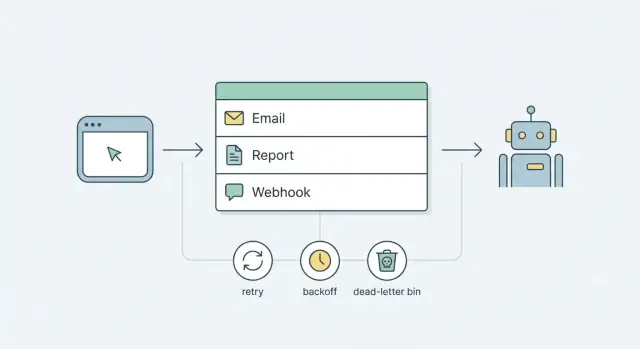
队列就是工作等待的队伍。不是在用户请求中执行慢或不稳定的任务(发送邮件、生成报表、调用 webhook),而是把一个小记录放入队列并快速返回。随后,独立进程取出该记录并执行工作。
常见术语:
最简单的流程如下:
入队(Enqueue):应用保存一条任务记录(类型、payload、运行时间)。
认领(Claim):worker 找到下一条可用任务并“锁定”它以确保只有一个 worker 执行。
执行(Run):worker 完成任务(发送、生成、投递)。
完成(Finish):标记为已完成,或记录失败并设置下次运行时间。
如果任务量适中且你已有数据库,基于数据库的队列通常足够。它易于理解、便于调试,并满足邮件任务处理与 webhook 投递可靠性的常见需求。
当你需要非常高的吞吐、许多独立消费者或在多个系统间重放大量事件时,流式平台才开始显得合适(比如 Kafka)。直到那时,一张数据库表加上一个 worker 循环已经覆盖了很多真实场景。
数据库队列只有在每条任务记录能快速回答三件事时才不会混乱:要做什么、下次什么时候重试、上次发生了什么。把这件事做好,运维就会变得无聊(这正是目标)。
存必要的最小输入,而不是整段渲染好的输出。好的 payload 是 ID 和少量参数,例如 { "user_id": 42, "template": "welcome" }。
避免存大块数据(完整 HTML 邮件、巨大的报表数据、庞大的 webhook 主体)。这会让数据库膨胀并使调试更难。如果任务需要大文档,存引用:report_id、export_id 或文件键。worker 在运行时再取回完整数据。
至少要包含:
job_type 用来选择处理器(send_email、generate_report、deliver_webhook)。payload 放小输入,如 ID 和选项。queued、running、succeeded、failed、dead)。attempt_count 和 max_attempts,以便在明显无法成功时停止重试。created_at 和 next_run_at(何时有资格运行)。如果想更好地观察慢任务,可加 started_at 和 finished_at。idempotency_key 用以防止重复副作用,last_error 用来查看失败原因而不用翻大量日志。幂等听起来高大上,实际上意思很简单:同一任务如果跑两次,第二次应能检测并避免危险操作。例如,webhook 投递任务可以用 webhook:order:123:event:paid 作为幂等键,这样在重试与超时重叠时不会重复投递相同事件。
还要尽早采集一些基本统计。你不需要复杂仪表盘,只要能跑出查询:当前排队的任务数、失败任务数、最老排队任务的时长。
如果你已经有数据库,就可以开始构建后台队列而无需新增基础设施。任务是行,worker 是不断取到期行并执行的进程。
保持表结构小而朴素。需要足够字段用于运行、重试和后续调试。
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
如果你用的是 Postgres(与 Go 后端常见的组合),jsonb 是保存任务数据的实用方式,比如 { "user_id":123,"template":"welcome" }。
当用户动作应触发任务(发送邮件、触发 webhook)时,尽量把写入任务行与主数据变更放在同一数据库事务内。这样可以避免“用户已创建但任务丢失”的情况。
例如用户注册时,在一个事务里插入用户记录和 send_welcome_email 任务。
worker 会重复同样的周期:找一条到期任务,原子认领,处理,然后标记完成或安排重试。
在实践中意味着:
status='queued' 且 next_run_at <= now() 的一条任务。SELECT ... FOR UPDATE SKIP LOCKED)。status='running'、locked_at=now()、locked_by='worker-1'。done/succeeded),或记录 last_error 并安排下一次尝试。多个 worker 可以同时运行。认领步骤防止重复处理。
关机时停止接收新任务,完成当前任务,然后退出。如果进程在执行中挂掉,用一条简单规则处理:对超时的 running 任务由周期性“清理器”重新入队。
如果你在 Koder.ai 上构建,这个基于数据库的队列模式是电子邮件、报表和 webhook 的一个稳妥默认方案,在引入专用队列服务前能满足大部分需求。
重试是队列在现实世界混乱时保持平静的方法。没有明确规则,重试会变成噪音循环,骚扰用户、猛击第三方 API,并掩盖真正的 bug。
先决定什么应当重试、什么应当快速失败。
临时问题重试:网络超时、502/503、速率限制或短暂的数据库连接抖动。
永久失败立即放弃:缺少邮箱地址、webhook 返回 400(负载无效)、针对已删除账户的报表请求。
退避是尝试之间的等待。线性退避(5s、10s、15s)简单,但仍会产生流量波动。指数退避(5s、10s、20s、40s)能更好地分散流量,通常对 webhook 与第三方提供方更安全。加入抖动(在延迟上加小随机值),避免成千上万的任务在故障恢复时恰好同时重试。
生产中表现良好的规则:
最大尝试次数是限制损害的手段。对多数团队来说,5 到 8 次足够。超过此次数,把任务停放到供人工查看的死信流程而不是无限循环。
超时能防止“僵尸”任务。邮件每次尝试可以设置为 10–20 秒超时;webhook 常需更短的限制,比如 5–10 秒,因为接收方可能宕机且你希望尽快转移到其他任务。报表生成可能允许几分钟,但也应有硬性截止。
在实现时把 should_retry、next_run_at 与幂等键作为第一类字段对待。这些小细节能在出现问题时让系统保持安静。
死信状态是当任务不再安全或不再有意义时的去处。它能把沉默的失败变成可见且可搜索、可操作的对象。
保存足够信息以便理解发生了什么并能在不猜测的情况下重放任务,但要注意不要泄露敏感数据。
保留:
如果 payload 包含令牌或个人数据,在存储前脱敏或加密。
任务进入死信后,做出快速决策:重试、修复或忽略。
重试:针对外部宕机和超时。修复:数据缺失(无邮箱、错误 webhook URL)或代码 bug。忽略应当少用,但当任务不再相关时可以接受(例如用户删除账号)。若忽略,应记录原因以免任务看起来“消失”了。
手动重新入队最安全的做法是创建一条新任务并保持原死信不可变。把死信标注上谁重试、何时重试与原因,然后入队一个新的副本(新 ID)。
在告警方面,关注那些通常意味着实际痛点的信号:死信数量快速上升、相同错误在大量任务中重复、以及长时间未被认领的老排队任务。
为供应商故障加安全阀:对每个提供商限制发送速率,并使用断路器。如果某个 webhook 端点严重失败,暂停该端点的一段时间,避免你自己与对方被刷垮。
当每个任务类型有明确规则时队列表现最佳:什么算成功、什么应重试、什么绝不允许重复发生。
邮件。 多数邮件失败是临时性的:提供商超时、速率限制或短暂宕机。把这些当作可重试,且使用退避策略。更大的风险是重复发送,因此要让邮件任务具备幂等性。存一个稳定的去重键,例如 user_id + template + event_id,如果该键已标记为已发送则拒绝再次发送。
还值得保存模板名与版本(或渲染后主题/正文的哈希)。如果需要重跑任务,你可以决定是重发完全相同的内容还是用最新模板重新生成。如果提供商返回消息 ID,保存它以便支持团队追踪。
报表。 报表失败的方式不同。它们可能运行数分钟、触及分页限制或在一次性处理时耗尽内存。把工作切分成更小的块。常见模式是:一个“报表请求”任务会创建许多“页面”(或“分片”)任务,每个处理一段数据。
把结果存为可下载的形式,而不是让用户等待。可以用数据库表以 report_run_id 为键,或用文件引用加元数据(状态、行数、创建时间)。加入进度字段,让 UI 能显示“处理中”与“已就绪”。
Webhooks。 Webhook 更关注投递可靠性而非速度。给每次请求签名(比如用共享密钥做 HMAC),并包含时间戳以防重放。仅在接收方有可能后来成功时才重试。
一个简单规则集:
顺序与优先级。 大多数任务不需要严格顺序。需要顺序时通常是按键分组(每个用户、每个发票、每个 webhook 端点)。加一个 group_key 并保证同一键只有一个并发任务即可。优先级上,把紧急工作与慢工作分开:大的报表积压不应阻塞密码重置邮件。
例如购买后,你入队(1)订单确认邮件、(2)合作方 webhook、(3)报表更新。邮件可快些重试,webhook 用更长的退避并最终停止在永久 4xx,报表延后在低优先级运行。
用户在你应用注册。三件事情应发生,但都不应该拖慢注册页:发送欢迎邮件、向 CRM 发 webhook、把用户纳入夜间活跃报表。
在创建用户记录后,写三条任务到数据库队列。每行有类型、payload(如 user_id)、状态、尝试计数和 next_run_at 时间戳。
典型生命周期:
queued:已创建,等待 workerrunning:被 worker 认领succeeded:完成,无需更多工作failed:失败,已排期或耗尽重试dead:失败次数过多,需要人工查看欢迎邮件任务包含幂等键例如 welcome_email:user:123。在发送前,worker 检查完成的幂等键表(或通过唯一约束强制)。如果任务因崩溃再次运行,第二次会看到键并跳过发送,从而避免重复欢迎邮件。
假设 CRM 的 webhook 端点宕机。webhook 任务超时失败。worker 按退避计划重试(例如:1 分钟、5 分钟、30 分钟、2 小时),并加一点抖动,避免大量任务在同一秒重试。
当最大尝试次数耗尽,任务变为 dead。用户仍然注册成功、收到了欢迎邮件,夜间报表任务也可以正常运行。只有 CRM 通知卡住,而且这个失败是可见的。
第二天早上,支持或值班人员可以在不翻大量日志的情况下处理:
webhook.crm)dead -> queued,重置尝试次数)或临时禁用该目标如果你在 Koder.ai 上构建,同样的模式适用:保持用户流程快速,把副作用推到任务中,并让失败容易检查与重跑。
最容易把队列搞坏的做法是把它当作可有可无。团队常常先在请求中“就这一次”直接发送邮件,因为看起来更简单。然后这种做法蔓延:密码重置、收据、webhook、报表导出。很快应用变得缓慢、超时增加、任何第三方的小波动都变成你的故障。
另一个陷阱是忽略幂等性。如果任务可能被执行两次,必须保证不会产生两个结果。没有幂等性,重试会导致重复邮件、重复事件或更糟。
第三个问题是可视性。如果你只从支持工单里得知失败,队列已经在伤害用户了。即便是一个能显示按状态统计任务数并能搜索 last_error 的基础内部视图也能节省大量时间。
退避能防止自我造成的故障。即便是基本的计划如 1 分钟、5 分钟、30 分钟、2 小时,也能让失败更安全。同时设置最大尝试次数,把出问题的任务展示出来而不是无限循环。
如果你在 Koder.ai 上构建,把这些基础与功能一起交付,而不是在几周后当作收尾项目再去修补。
在添加更多工具前,确保基础稳固。数据库队列在每条任务易于认领、易于重试且易于检查时效果很好。
一个快速可靠性清单:
接下来,挑出你的前三类任务并写下它们的规则。例如:密码重置邮件(快速重试、短最大尝试),夜间报表(少次重试、较长超时),webhook 投递(更多重试、更长退避,在永久性 4xx 时停止)。
如果不确定何时数据库队列不再够用,注意这些信号:从大量 worker 出现行级争用、严格的跨类型顺序需求、大规模扇出(一次事件触发数千任务),或跨服务消费场景(不同团队拥有不同 worker)。
如果想做快速原型,可以在 Koder.ai 中用规划模式草拟流程,生成 jobs 表与 worker 循环,并在部署前通过快照与回滚反复迭代。
如果一个任务可能比一两秒更耗时,或依赖网络调用(邮件提供商、webhook 接收方、慢查询),就应该把它移到后台任务。
让用户请求只负责校验输入、写入主要数据变更、入队任务并快速返回响应。
当满足下列条件时可以从数据库队列开始:
当需要非常高的吞吐、众多独立消费者或跨服务事件回放时,再考虑添加消息中介或流处理工具。
追踪能回答三个问题的基础字段:该干什么、下次什么时候重试、上次发生了什么。
实用的最小字段:
把输入存起来,而不是大的输出。
适合的 payload:
user_id、template、report_id)避免:
关键是原子性的“认领”步骤,保证两个 worker 不会处理同一条任务。
Postgres 常用做法:
FOR UPDATE SKIP LOCKED)running 并写入 locked_at/locked_by这样 worker 可以横向扩展而不会重复处理同一行。
假定任务有可能被执行两次(崩溃、超时、重试),因此把副作用设计为幂等。
简单做法:
idempotency_key,例如 welcome_email:user:123这对邮件和 webhook 特别重要以避免重复。
使用明确且保守的策略:
对永久性错误(缺少邮箱、无效负载、大多数 4xx webhook 响应)应快速失败,不重试。
死信表示“停止重试并让人可见”。当达到 max_attempts、错误显然是永久性的或继续重试有害时,就把任务标记为死信。
保存足够的上下文以便处理:
last_error 与最后的状态码(针对 webhook)重放时优先创建新任务并保持死信条目不可变。
用两条规则处理“卡在 running 的任务”:
running 任务并重新入队或标记为失败这样系统可以从 worker 崩溃中自动恢复,减少人工干预。
把慢工作与紧急工作分开,避免慢任务阻塞关键流程:
如果需要顺序性,通常按“键”来保证(每个用户、每个 webhook 端点)。加个 group_key 并确保同一组只有一个正在运行的任务以维持局部顺序,不必全局排队。
job_type、payloadstatus(queued、running、succeeded、failed、dead)attempts、max_attemptsnext_run_at,以及 created_atlocked_at、locked_bylast_erroridempotency_key(或其他去重机制)如果任务需要大数据,存一个引用(如 report_run_id 或文件键),worker 在运行时再获取真实内容。