2025年10月11日·1 分钟
Kafka 事件流:队列何时够用,何时该用日志
Kafka 事件流通过把事件当作有序日志改变了系统设计。了解何时简单队列就足够,何时基于日志的方式更有价值。
Kafka 事件流通过把事件当作有序日志改变了系统设计。了解何时简单队列就足够,何时基于日志的方式更有价值。
大多数产品一开始采用简单的点对点集成:系统 A 调用系统 B,或用一个小脚本把数据从一个地方复制到另一个地方。产品增长、团队拆分、连接数量增加后,这种做法就不够用了。很快,每次改动都需要跨多个服务协调,因为一个小字段或状态更新可能会在依赖链中产生连锁反应。
速度通常首先受影响。新增功能意味着要更新多个集成、重新部署若干服务,并祈祷没有其他系统依赖旧行为。
调试随后变得非常痛苦。当界面看起来不对时,很难回答基本问题:发生了什么、按什么顺序发生、你看到的值是哪个系统写入的?
缺失的往往是审计轨迹。如果数据直接从一个数据库推到另一个(或在传输过程中被转换),你就丢失了历史。你可能看到最终状态,但看不到导致最终状态的事件序列。事故复盘和客户支持都会受到影响,因为你无法重放过去来确认发生了什么以及为什么发生。
这也是“谁拥有真相”争论开始的地方。一个团队会说“计费服务是事实来源”,另一个会说“订单服务是”。事实上,每个系统都有部分视图,点对点集成把这种分歧变成日常摩擦。
举个简单例子:订单被创建、付款,然后退款。如果三个系统直接相互更新,在重试、超时或人工修复的情况下,每个系统可能会看到不同的“故事”。
这就引出了 Kafka 事件流背后的核心设计问题:你只是需要把工作从一个地方移动到另一个地方(队列),还是需要一个共享的、持久的、许多系统可以读取、回溯并信任的记录(日志)?答案会改变你构建、调试和演进系统的方式。
Jay Kreps 对 Kafka 的发展有重要影响,更重要的是他改变了很多团队对数据移动的思考方式。有用的转变在于心态:不要把消息当作一次性交付,而要把系统活动当作记录来对待。
核心思想很简单。把重要变化建模为一连串不可变的事实:
每个事件都是不该被事后改写的事实。如果后来发生变化,你发布新的事件来陈述新的真实情况。随着时间推移,这些事实就形成了一个日志:一个追加写入的系统历史。
这正是 Kafka 事件流与许多基础消息系统的不同之处。很多队列设计是“发送、处理、删除”。当工作仅仅是一次交接时,这没问题。日志视角则是“保留历史,以便许多消费者现在或将来都能使用它”。
重放历史是一个非常实用的超能力。
如果报告有误,你可以把相同的事件历史重新运行到修好的分析任务中,找出数字何时变化。如果 bug 导致了错误邮件,你可以把事件重放到测试环境,重现准确时间线。如果新功能需要过去的数据,你可以构建一个新消费者从头开始读取并按自己的速度赶上进度。
举个具体例子。假设你在处理了数月付款后才加入反欺诈检查。有了支付和账户事件的日志,你可以重放过去的数据来训练或校准规则,为旧交易计算风险分,并回填 fraud_review_requested 事件,而无需重写数据库。
注意这会迫使你做出一些改变。基于日志的方法会推动你明确事件命名、保持事件稳定,并接受多个团队和服务会依赖这些事件。它也会引出有用的问题:谁是事实来源?这个事件从长期来看意味着什么?当我们犯错时怎么处理?
价值不在于某个人的风格,而在于意识到共享日志可以成为系统的记忆,而记忆正是让系统在新增消费者时不会崩溃的关键。
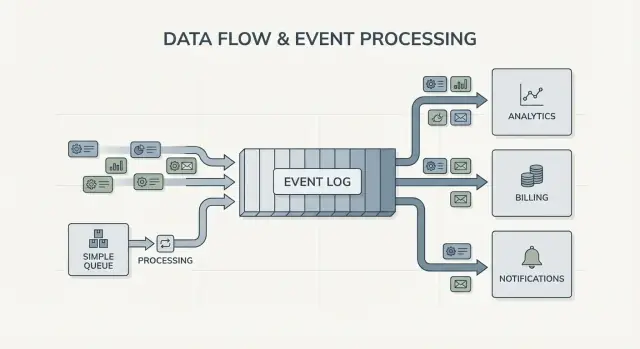
消息队列像是软件的待办队列。生产者把工作放入队列,消费者取下一个项并执行,执行完成后该项就消失。系统主要目标是尽快并且尽量只处理一次每个任务。
日志则不同。日志是按序保存的事实记录,事件以持久的顺序存储。消费者不会把事件“拿走”。他们按自己的速度读取日志,并且可以之后再读。在 Kafka 事件流中,这个日志是核心概念。
一个实用的记忆方式:
保留期会改变设计。有了队列,如果之后你需要依赖旧消息的新功能(分析、欺诈检查、在 bug 之后的重放),通常得另建数据库或把数据另外捕获一份。日志的重放是常态:你可以从头读取来重建派生视图(或从某个已知检查点开始)。
扇出(fan-out)也是一个大差别。想象结账服务发出 OrderPlaced。在队列里,你通常会选择一个工作组来处理它,或者把工作复制到多个队列。在日志里,计费、邮件、库存、搜索索引和分析都可以独立读取同一事件流。每个团队可以按自己的节奏前进,增加新消费者也不需要修改生产者。
因此心智模型很直接:当你只是移动任务时用队列;当你需要记录事件并让公司多个部分现在或将来读取时,用日志。
事件流把默认问题翻转了。你不再问“我应该把这条消息发给谁?”,而是先记录“刚刚发生了什么?”。听起来很小,但它会改变你建模系统的方式。
你发布像 OrderPlaced 或 PaymentFailed 这样的事实,系统的其他部分再决定是否、何时以及如何对其做出反应。
在 Kafka 事件流中,生产者不再需要维护一长串直接集成。结账服务可以只发布一个事件,而不必关心分析、邮件、风控或未来的推荐服务是否会使用它。新消费者可以后来加入,旧的可以暂停,生产者的行为不受影响。
这也改变了你从错误中恢复的方式。在纯消息世界里,一旦消费者错过了东西或存在 bug,数据往往“消失”了,除非你构建了定制备份。有了日志,你可以修复代码并重放历史来重建正确状态。这往往比人工修改数据库或不受信任的一次性脚本更可取。
在实践中,这种转变以几个可靠方式体现:把事件当作持久记录,通过订阅而不是修改生产者来新增功能,可以从头重建只读模型(搜索索引、仪表盘),并获得更清晰的跨服务时间线。
可观测性得到提升,因为事件日志成为共享参考。当出现问题时,你可以沿着业务序列追踪:订单创建、库存预留、支付重试、发货安排。与分散的应用日志相比,这条时间线通常更容易理解,因为它聚焦于业务事实。
举个具体例子:如果某个折扣 bug 在两个小时内错误定价,你可以发布修复并重放受影响的事件来重新计算总额、更新发票并刷新分析。你是通过重新派生结果来纠正输出,而不是猜测哪些表需要手工修补。
当你的目标是移动工作而不是建立长期记录时,简单队列是合适的工具。目标是把任务交给工作者、执行,然后忘记。如果无人需要重放过去、检查旧事件或以后增加新消费者,队列会更简单。
队列在后台任务场景下很出彩:发送注册邮件、图片上传后的裁剪、生成夜间报告、调用可能很慢的外部 API 等。在这些场景中,消息只是一个工作票据。工作者完成任务后,票据就完成了。
队列也符合常见的所有权模型:一个消费者组负责端到端完成工作,其他服务不需要独立读取同一条消息。
当下列条件多数成立时,队列通常够用:
举例:产品允许用户上传照片。应用写入一个“resize image”的队列任务。工作者 A 拿到任务,生成缩略图、存储,并标记任务完成。如果任务运行两次,输出相同(幂等),那么至少一次交付是可以接受的。没有其他服务需要以后读取该任务。
一旦你的需求开始向共享事实(多个消费者)、重放、审计或“系统上周认为是什么”的方向发展,Kafka 事件流和基于日志的方法就会开始体现价值。
当事件不再是一次性消息而是共享的历史时,基于日志的系统就会带来回报。你不再是“发送然后忘记”,而是保留一个有序记录,多个团队可以按自己的节奏读取并在以后重放。
最明显的信号是多个消费者。像 OrderPlaced 这样的事件可以同时供计费、邮件、风控、搜索索引和分析使用。使用日志,每个消费者独立读取同一条流。你无需构建定制的扇出管道或协调谁先接收消息。
另一个好处是能够回答“当时我们知道什么?”如果客户对收费有异议,或推荐结果看起来不对,追加写入的历史可以让你按事件到达的顺序重放事实。这个审计轨迹很难在后期加到简单队列上。
你还获得了一种实用方式来在不重写旧代码的情况下新增功能。如果你几个月后增加一个“发货状态”页面,一个新服务可以订阅并从既有历史回填以构建自己的状态,而不是去求其他系统导出数据。
当你识别出下列一种或多种需求时,基于日志的方法通常值得投入:
常见模式是产品从订单和邮件开始。后来,财务需要收入报告,产品需要漏斗分析,运维需要实时仪表盘。如果每个新需求都迫使你通过新管道复制数据,成本会快速上升。共享的事件日志让团队在相同的事实来源上构建,即使系统增长并且事件形状发生变化。
在队列和基于日志的方法之间做选择时,把它当作产品决策会更容易。以一年后的需求为起点,而不是只考虑本周能工作的方案。
绘制发布者和读取者。写下今天谁在创建事件、谁在读取,并列出可能的未来消费者(分析、搜索索引、风控、客户通知)。如果你预计许多团队会独立读取相同事件,日志开始变得有意义。
问自己是否需要重新读取历史。要具体说明原因:在 bug 后重放、回填或消费者以不同速度读取。队列适合一次性交接,日志适合你想重放的记录。
定义“完成”意味着什么。对某些工作流来说,完成就是“作业运行完毕”(发送邮件、裁剪图片)。对另一些来说,完成意味着“事件是持久事实”(订单已下达、支付已授权)。持久事实会把你推向日志。
确定交付期望并决定如何处理重复。常见的是至少一次交付,这意味着可能会有重复。如果重复会造成问题(重复扣款),就要规划幂等性:存储已处理事件 ID,使用唯一约束,或使更新对重复安全。
从一个薄切片开始。选择一个易于理解的事件流并从那里扩展。如果你选用 Kafka 事件流,保持第一个 topic 专注、事件命名清晰,并避免把不相关的事件混在一起。
举个具体例子:如果 OrderPlaced 将来会供发货、开票、支持和分析使用,日志让每个团队按自己的节奏读取并在出错后重放。如果你只需要后台工人发送收据邮件,简单队列通常就足够了。
想象一家小型网店。起初它只需要下单、扣款并创建发货请求。最简单的做法是结账后触发一个后台作业:“process order”。它调用支付 API、更新订单数据库行,然后调用发货。
当时队列式的做法很好:有明确工作流、只有一个消费者(工作者),重试和死信队列覆盖大多数失败场景。
随着商店成长,问题出现了。客服想要自动的“我的订单在哪儿?”更新。财务要日度收入数据。产品团队要客户邮件。发货前需要做风控检查。把所有逻辑都塞在一个“process order”工作者里,你会不断修改同一个工作者、添加分支,并把新 bug 引入核心流程。
采用基于日志的方法,结账会产出小粒度事实事件,各团队在此基础上构建。典型事件可能是:
关键变化在于所有权。结账服务负责发布 OrderPlaced。支付服务负责 PaymentConfirmed。发货负责 ItemShipped。以后新消费者可以出现而不改动生产者:风控服务读取 OrderPlaced 和 PaymentConfirmed 做评分,邮件服务发送收据,分析构建漏斗,支持工具维护事件时间线。
这正是 Kafka 事件流的价值所在:日志保留历史,新消费者可以从头回放并赶上进度(或从已知点开始),而不需要每个上游团队去新增 webhook。
日志并不能替代你的数据库。你仍需要数据库来表示当前状态:最新订单状态、客户记录、库存计数以及事务性规则(比如“支付确认前不发货”)。把日志看作是变更记录,把数据库当作查询“现在什么是真的”的地方。
事件流能让系统显得更清晰,但一些常见错误会迅速抹去这些好处。大多数问题来自把事件日志当成远程控制而不是记录。
一个常见陷阱是把事件写成命令,比如 “SendWelcomeEmail” 或 “ChargeCardNow”。这会让消费者与意图耦合过紧。事件更适合作为事实:UserSignedUp 或 PaymentAuthorized。事实更容易随时间复用。
重复和重试是另一个主要痛点。真实系统中生产者会重试、消费者会重处理。如果不提前规划,你会遇到重复扣款、重复邮件和愤怒的客户。解决办法并不复杂,但需要刻意实现:幂等处理器、稳定的事件 ID,以及检测“已应用”的业务规则。
常见陷阱包括:
模式和版本管理需要特别关注。即便你一开始用 JSON,也需要明确契约:必需字段、可选字段,以及如何发布变更。一个小的字段重命名可能会悄悄破坏分析、计费或更新较慢的移动应用。
另一个陷阱是过度拆分。团队有时为每个功能创建新的流。一个月后,无人能回答“订单的当前状态是什么?”,因为相关信息散落在太多地方。
事件流并不能取代良好的数据模型。你仍然需要一个代表当前真实状态的数据库。日志是历史,而不是你的全部应用。
如果你在队列和 Kafka 事件流之间犹豫,先做几个快速检查。这些问题能告诉你是否只需要在工作者间做简单交接,还是需要一个能被多年复用的日志。
如果你对“重放”为否、对“仅一个消费者”为否,以及对“消息短期有效”为否,基本队列通常够用。若你对重放、多个消费者或更长保留期回答“是”,基于日志的方法更可能带来回报,因为它把一条事实流变成其他系统可构建的共享来源。
把答案转换为一个小而可测试的计划。
如果你需要快速原型,可以在 Koder.ai 的规划模式中草绘事件流并迭代设计。在那里你可以在锁定事件名称和重试规则前测试单个生产者-消费者切片。由于 Koder.ai 支持源代码导出、快照和回滚,它也是测试单个生产者-消费者切片并在不把早期实验变成生产债务的情况下调整事件形状的实用工具。
队列适合作为工作票,处理后就可以忘记(发送邮件、裁剪图片、运行后台任务)。日志适合作为事实保留,让多个系统以后读取和重放(例如 order placed、payment authorized、refund issued)。
当每个新功能都需要改动多个集成,调试变成“谁写了这个值?”且没有清晰的时间线时,你会感觉到点对点集成成为问题。日志的好处是它成为一个共享的记录,你可以检查并重放,而不是从分散的数据库状态中猜测。
当你需要审计轨迹和重放时,Kafka 风格的日志式方法就很值:通过重处理历史来修复 bug、用旧数据回填新功能、回答“当时我们知道什么?”之类的调查,或在不改动生产者的情况下同时支持计费、分析、客服、风控等多个消费者。
因为系统会以混乱的方式失败:重试、超时、部分宕机和人工修复。如果每个服务直接相互更新,它们可能会对发生的事情产生不同的看法。追加写入的事件历史为你提供一个有序的序列,可以用于推理,即使有些消费者掉线后来再追上也没问题。
把事件建模为不可变的事实(过去时)来描述已经发生的事:
OrderPlaced,而不是 ProcessOrderPaymentAuthorized,而不是 ChargeCardNowUserEmailChanged,而不是 要假设会有重复(至少一次交付是常态)。让每个消费者可以安全重试:
默认规则:先保证正确性,再追求速度。
优先采用可追加的改动:保留旧字段、添加新可选字段,避免重命名或删除现有消费者依赖的字段。如果必须做破坏性变更,为事件或主题/流设版本,并有计划地迁移消费者,而不是直接改 JSON。
从一条薄切片开始:
OrderPlaced → 邮件回执)。orderId 或 userId)。在扩展到更多事件和团队之前,先验证这个闭环可行。
不替代。仍需数据库来存放当前状态和事务(“现在什么是真的”)。用事件日志保存历史,并用它来重建派生视图(分析表、搜索索引、时间线)。实际分工:数据库负责产品的读写,日志负责分发、重放和审计。
规划模式适合映射发布者/消费者、定义事件名称、以及决定幂等性和保留策略,先在设计上把事情说清楚再写生产代码。然后你可以实现一个小的生产者-消费者切片,拍快照并快速回滚以调整事件形状。稳定后导出源代码并像其他服务一样部署。
UpdateEmail如果后来发生变化,发布新的事件来陈述新的真实情况,而不是去修改旧的事件。