2025年11月15日·2 分钟
为库存预测与需求计划构建 Web 应用
规划并构建一款用于库存预测与需求计划的 Web 应用:数据准备、预测方法、用户体验、集成、测试与部署。
规划并构建一款用于库存预测与需求计划的 Web 应用:数据准备、预测方法、用户体验、集成、测试与部署。
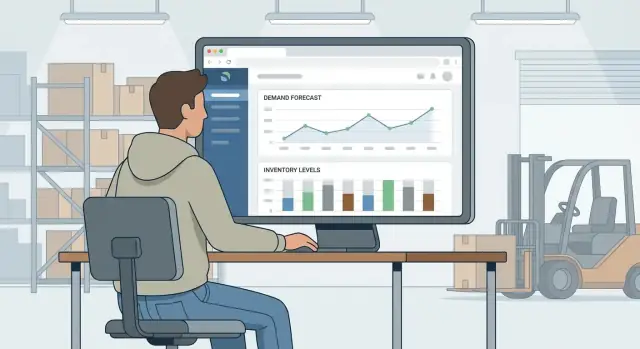
库存预测与需求计划 Web 应用帮助企业基于未来预期需求和当前库存位置决定“该买什么、什么时候买、买多少”。
库存预测是预测每个 SKU 随时间的销售或消耗。需求计划把这些预测转化为决策:再订货点、订货量和时机,以满足服务目标并兼顾现金约束。
没有可靠系统时,团队常依赖表格和直觉,通常带来两个代价高昂的结果:
设计良好的库存预测 Web 应用能建立对需求预期和推荐动作的共享事实来源——让各地点、渠道和团队的决策保持一致。
准确性和信任是时间堆积出来的。你的 MVP 需求计划应用可以从:
开始。一旦用户采纳了流程,可以逐步通过更好的数据、分群、促销处理和更智能的模型来提高准确性。目标不是“完美”预测,而是一个可重复的决策流程,使每次周期性地变得更好。
典型用户包括:
用业务结果来评判应用:更少的缺货、更低的过剩库存、更清晰的采购决策——这些都应在库存规划仪表板上可见,并让下一步行动一目了然。
库存预测 Web 应用的成败在于清晰性:它要支持哪些决策,为谁服务,以及支持到何种细节层级?在模型与图表之前,先定义 MVP 必须改进的最小决策集。
把问题写成动作,而不是功能:
如果某个界面无法绑定到上述问题之一,通常应推到后期阶段。
选择与提前期和采购节奏匹配的视野:
然后选择更新节奏:销售变化快时需每日,采购按固定周期时可每周。节奏还决定了应用运行作业和刷新建议的频率。
“正确”的层级是人们实际上可以下单与移动库存的层级:
把成功量化:服务水平/缺货率、库存周转率和预测误差(例如 MAPE 或 WAPE)。把指标与业务结果挂钩,如防止缺货和降低过剩。
MVP: 每个 SKU(或 SKU-地点)一个预测、一套再订货点计算、一个简单的审批/导出工作流。
后续: 多级库存优化、供应商约束、促销与情景规划等。
预测的价值取决于输入数据。在选择模型或构建界面前,先明确你拥有哪些数据、它们存放在哪里,以及对 MVP 来说“足够好”的质量标准是什么。
至少需要持续一致的视图:
大多数团队从多系统汇总:
决定应用刷新频率(每小时、每日)以及数据延迟或编辑时的处理方式。一个实用模式是保留不可变的事务历史并应用调整记录,而不是覆盖过去的数据。
为每个数据集分配负责人(例如库存:仓库运营;提前期:采购)。维护简短的数据字典:字段含义、单位、时区与允许值。
预计会遇到问题,如缺失的提前期、单位换算(each vs case)、退货与取消、重复 SKU、和不一致的地点编码。提前标记这些问题,以便在 MVP 中显式地修复、默认处理或排除它们。
预测应用能否赢得信任,关键在于数据模型是否让“发生了什么”(销售、收货、调拨)清晰无歧义,并使“现在的真实情况”(在手、在订)保持一致。
定义少量实体并在整个应用中保持一致:
选择 日 或 周 作为规范时间粒度,把所有输入对齐:订单可能带时间戳、库存盘点是日终快照、发票可能后发。明确对齐规则(例如“销售归属发货日,按日桶化”)。
如果你同时以 each/case/kg 销售,存储原始单位并提供用于预测的归一化单位(例如“each”)。如果要预测收入,保存原始货币并提供与汇率参考的统一报告货币。
按 SKU-地点-时间跟踪一系列事件:在手快照、在订量、收货、调拨、调整。这让缺货解释与审计轨迹更容易实现。
对于关键指标(单位销量、在手、提前期),决定一个权威来源并在模式中记录。当两个系统不一致时,模型应展示哪个来源胜出以及原因。
预测 UI 的价值取决于为其提供数据的质量。如果数字无故改变,用户会失去对库存规划仪表板的信任——即使模型本身没问题。ETL 应使数据可预测、可调试并可追溯。
先为每个字段写下“事实来源”(订单、出货、在手、提前期)。然后实现可重复流程:
保留两层:
当计划员问“为什么上周的需求变了?”,你应能定位到原始记录与触及它的转换逻辑。
至少校验:
让运行失败(或将受影响分区隔离),而不是默默发布错误数据。
若采购以周为单位,日批通常已足够。仅当操作决策需要(当天补货、电商骤变)时使用近实时,因为那会增加复杂度与告警噪声。
记录失败时的处理:哪些步骤自动重试、重试次数、谁会收到通知。对提取失败、行数急剧下降或校验失败发送告警,并保留运行日志以便审计每次预测输入。
没有哪种方法在抽象意义上“最好”——它们要适合你的数据、SKU 与计划节奏。优秀的 Web 应用让你容易从简单起步、衡量结果,然后在能带来收益的地方升级到更复杂的模型。
基线快、可解释且是极好的健全检查。至少包含:
始终将预测准确性与这些基线比较——若复杂模型无法优于基线,就不应投入生产。
当 MVP 稳定后,加入“进阶”模型:
用一个默认模型和少量参数能更快上线。但对于混合了稳定畅销、季节性商品与长尾商品的目录,按 SKU 选择模型(基于回测选择最佳模型家族)通常能取得更好效果。
若许多 SKU 经常为零销量,要把它当作一级情况处理。加入适合间歇性需求的方法(如 Croston 类方法),并用不会对零值不公平惩罚的指标来评估。
计划员需要对新品、促销与已知扰动做覆盖。构建带理由、到期日与审计轨迹的覆盖工作流,让手动编辑改善决策而不是掩盖发生了什么。
预测准确性常由特征决定:即除“上周销量”外你提供的上下文。目标不是加入成百上千个信号,而是加入少量反映业务行为且计划员能理解的特征。
需求通常有节奏。加入少量日历特征以捕捉节奏而不过拟合:
若促销数据混乱,先用简单的“促销中”标记,再逐步细化。
库存预测不仅是预测需求,也要考虑可得性。可解释且有用的信号包括价格变动、提前期更新以及供应商是否受限。可考虑:
缺货日零销量不等于零需求。若把这些零直接喂入模型,模型会学到需求消失。
常见做法:
新商品没有历史。规定清晰规则:
将特征集保持精简,并在应用中以业务术语命名特征(例如“节假日周”而不是“x_reg_17”),以便计划员信任并质疑模型行为。
预测只有在告诉某人下一步要做什么时才有价值。你的 Web 应用应把预测转为可审阅的具体采购动作:何时再订货、今天应下多少单、以及需要多大缓冲。
从每个 SKU(或 SKU-地点)输出三项:
实用结构为:
若可测量,请纳入提前期波动性(而不仅仅取平均提前期)。即便是每个供应商的简单标准差也能显著降低缺货。
并非每件商品都应给同样的保护。让用户按 ABC 分类、毛利或关键性设置服务水平目标:
建议必须可行。加入约束处理:
每条建议都应包含简短说明:提前期内的预测需求、当前库存位置、所选服务水平以及应用的约束调整。这能建立信任并便于审批例外。
把预测应用当成两件产品来维护最容易:面向人的 Web 体验,以及在后台运行的预测引擎。这样的分离能保持 UI 响应,避免超时,并使结果可复现。
从四大构件开始:
关键决策:预测运行绝不要在 UI 请求中执行。把它们放到队列(或定时任务),返回运行 ID,并在 UI 中流式展示进度。
如果你想加速 MVP 构建,像 Koder.ai 这样的编程即构建(vibe-coding)平台可能适合原型:你可以在一个聊天驱动的构建循环中快速原型 React UI、Go API 与 PostgreSQL 后端及后台作业工作流——准备好后再导出源代码以做加固或自托管。
把“事实系统”表(租户、SKU、地点、运行配置、运行状态、审批)放在主数据库。将大体量输出(按日预测、诊断、导出)放在适合分析的表或对象存储中,并以运行 ID 做引用。
若为多个业务单元或客户提供服务,在 API 层和数据库模式中强制租户边界。简单做法是在每张表上带 tenant_id,并在 UI 中做基于角色的访问控制。即便是单租户 MVP,这也能避免日后数据混淆。
目标是小而清晰的接口:
POST /data/upload(或连接器),GET /data/validationPOST /forecast-runs(启动),GET /forecast-runs/:id(状态)GET /forecasts?run_id=... 与 GET /recommendations?run_id=...POST /approvals(接受/覆盖),GET /audit-logs预测可能很昂贵。通过缓存特征、在配置不变时复用模型、安排完整重训练(例如每周)并运行轻量的每日更新来限制代价。这能保持 UI 响应和预算稳定。
再优秀的模型也只有在计划员能快速且自信地采取行动时才有价值。良好的 UX 把“表格里的数字”变成明确的决策:该买什么、何时买、现在需要关注什么。
从少量与日常规划任务契合的页面开始:
保持导航一致,使用户能从异常跳转到 SKU 详情并返回而不丢失上下文。
计划员频繁切分数据。使筛选响应快速且可预测(按日期范围、地点、供应商、品类)。使用合理默认(例如最近 13 周、主仓库)并记住用户的上次选择。
通过展示预测为何改变来建立信任:
在 UI 避免复杂数学,侧重以自然语言的提示与悬浮说明。
加入轻量协作:行内备注、高影响订单的审批步骤与变更历史(谁何时为何改了预测覆盖)。这支持可审计性而不拖慢常规决策。
即便是现代团队仍然共享文件。提供干净的 CSV 导出和打印友好的订单摘要(商品、数量、供应商、总额、要求交货日),让采购能直接执行而无需额外排版。
预测只有能更新操作系统并被人们信任时才有用。早期规划集成、访问控制与审计轨迹,以便应用能从“有趣”变成“可操作”。
从驱动库存决策的核心对象开始:
明确每个字段的事实来源。例如,SKU 状态与单位来自 ERP,而预测覆盖与覆盖理由来自你的应用。
多数团队需要“现在能用”和“未来可扩展”的路径:
无论哪种方式,都要存储导入日志(行数、错误、时间戳),以便用户在无工程师帮助下诊断缺失数据。
按业务操作定义权限,通常按地点或部门划分。常见角色有 Viewer、Planner、Approver 与 Admin。确保敏感操作(编辑参数、审批采购建议)由合适角色执行。
记录谁何时为何改了什么:预测覆盖、再订货点编辑、提前期调整与审批决定。保留差异、评论与受影响建议的链接。
若公布预测 KPI,在应用内链接定义(或参考 /blog/forecast-accuracy-metrics)。在推广计划中,分层访问模型可与 /pricing 对齐。
预测应用只有在你能证明其表现良好并能发现其何时失效时才有用。测试不仅是“代码能否运行”,更是“预测与建议是否改善了结果?”
从团队都能理解的少量指标开始:
按 SKU、品类、地点与预测视野(下周 vs 下月)分报这些指标。
回测应模拟生产中应用的运行方式:
增加当准确性骤降或输入异常(缺失销量、重复订单、异常峰值)时的告警。在 /admin 区保留小型监控面板可防止数周的糟糕采购决策。
在全面上线前,与小批计划员/采购员做试点。跟踪建议是否被采纳或拒绝,并记录原因。这些反馈成为规则调整、异常处理与更好默认值的训练数据。
预测应用常触及最敏感的业务部分:销售历史、供应商报价、库存位置与未来采购计划。把安全与运营当作产品特性来对待——一次泄露或一次夜间作业失败可能会破坏数月的信任。
以最小权限原则保护敏感业务数据。从 Viewer、Planner、Approver、Admin 开始,把操作而不仅仅是页面进行分权:查看成本、编辑参数、审批采购建议、导出数据等。
若集成身份提供者(SSO),把组映射到角色以实现自动离职管理。
尽可能在传输与静态时加密。全站使用 HTTPS、定期轮换 API 密钥,并将密钥存放在托管的密钥库中,而不是服务器环境文件。数据库开启静态加密并限制网络访问仅限应用与作业运行器。
记录访问与关键操作(导出、编辑、审批)。保留结构化日志以记录:
这不是繁文缛节,而是调试库存规划仪表板意外问题的方式。
定义上传与历史运行的保留规则。许多团队对原始上传短期保留(例如 30–90 天),而把汇总结果长期保存用于趋势分析。
准备事件响应与备份计划:值班人员、如何撤销访问、以及如何恢复数据库。定期测试恢复,并为 API、作业与存储记录恢复时间目标,确保你的需求计划软件在压力下也能可靠运行。
先定义它必须改进的决策:每件商品应订购多少、何时下单、以及为哪个地点/渠道下单。然后选择实用的计划视野(例如 4–12 周)和一个与采购/补货节奏匹配的时间粒度(每天或每周)。
一个稳健的 MVP 通常包括:
把促销、情景规划、多层级优化等放在后续版本中。
至少需要:
如果这些数据不可靠,要在界面上显式展示缺口(默认值、标记或排除),不要默默猜测。
建立数据字典并在以下方面强制一致性:
在数据管道中加入自动化校验:缺失键、负库存、重复、异常值等。对出问题的分区隔离而不是发布错误数据。
把库存建模为事件和快照:
这样可追溯“发生了什么”,并保持“当前真实状态”一致,便于解释缺货并对 ERP/WMS/POS 等来源的差异进行调和。
先用简单、可解释的基线并长期保留:
使用回测证明更复杂的模型确实能优于这些基线。只有在有足够干净历史和驱动因素时,才加入更复杂的方法。
不要直接把缺货日期的零销量作为训练目标。常见做法:
关键是不要教模型把缺货误认为需求消失。
为冷启动 SKU 制定明确规则,例如:
在 UI 中让这些规则可见,以便计划人员知道何时是基于代理而非数据驱动的预测。
把预测转化为三类可操作输出:
然后应用真实世界约束:MOQ 与整箱(向上取整)、预算上限(优先级排序)、容量限制(仓储/托盘)。并始终展示每项建议的“原因”。
将 UI 与预测引擎分离:
不要在 UI 请求内运行完整预测;使用队列或调度器,返回run ID,并在界面中显示进度/状态。把批量输出(按日预测、诊断)存放在适合分析的存储并用 run ID 引用。