2025年4月03日·2 分钟
在 AI 应用中跨前端与后端管理状态
了解在 AI 应用中 UI、会话和数据状态如何在前端与后端之间流动;提供同步、持久化、缓存及安全的实用模式。
在 AI 构建的应用中,“状态”是什么意思
“状态”是你的应用需要记住的一切,以便在随后时刻正确地表现。
如果用户在聊天界面点击 发送,应用不应该忘记他们输入的内容、助手已经回复了什么、请求是否仍在运行,或哪些设置(语气、模型、工具)处于启用状态。所有这些都是状态。
用更通俗的话说状态
一个有用的思路是:应用当前的真实情况 — 那些影响用户所见和系统下一步行为的值。这既包括明显的表单输入,也包括一些“看不见”的事实,例如:
- 用户所在的对话
- 最后一次响应是流式返回还是已完成
- 消息列表及其顺序
- 工具调用和工具结果(搜索结果、数据库查找、文件提取)
- 错误、重试和速率限制退避
为什么 AI 应用有更多活动部分
传统应用通常读取数据、显示并保存更新。AI 应用增加了额外步骤和中间产物:
- 单次用户操作可能触发多个后端操作(LLM 调用、工具调用、再次 LLM 调用)。
- 响应可能增量到达(流式 token),因此 UI 必须管理部分状态。
- 上下文重要:系统可能需要保持会话记忆、工具输出和模型设置在请求间一致。
这些额外的运动是为什么状态管理常常是 AI 应用隐含复杂性的原因。
本指南将覆盖的内容
在下文中,我们会把状态切分为实用的类别(UI 状态、会话状态、持久化数据、模型/运行时状态),并说明每类状态应放在何处(前端 vs 后端)。我们还将涵盖同步、缓存、长时任务、流式更新和安全性——因为状态只有在正确且受保护时才有用。
快速示例场景
想象一个聊天应用,用户问:“总结上个月的发票并标出异常项。”后端可能会 (1) 获取发票,(2) 运行分析工具,(3) 将摘要流回 UI,(4) 保存最终报告。
为了让这看起来无缝,应用必须跟踪消息、工具结果、进度和已保存的输出——同时不混淆对话或在用户间泄露数据。
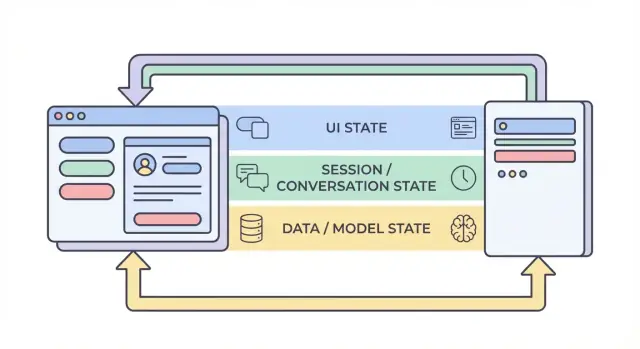
四层状态:UI、会话、数据和模型/运行时
当人们在谈论 AI 应用中的“状态”时,常常会把非常不同的东西混在一起。把状态分为四层——UI、会话、数据和模型/运行时——能更容易决定某项状态应放在哪里、谁可以更改它以及如何存储它。
1) UI 状态(用户当前正在做的事情)
UI 状态是浏览器或移动端的实时、瞬时状态:文本输入、切换项、已选项、哪个标签页打开、按钮是否禁用等。
AI 应用带来一些 UI 特有的细节:
- 加载指示和“思考中”状态
- 流式 tokens(生成时出现的部分文本)
- 本地草稿消息(发送前)
UI 状态应该容易重置且可以安全丢失。如果用户刷新页面,你可能会丢失它——通常这是可以接受的。
2) 会话 / 对话状态(用户流程的共享上下文)
会话状态将用户与正在进行的交互绑定:用户身份、对话 ID,以及消息历史的一致视图。
在 AI 应用中,这通常包括:
- 消息历史(或对其的引用)
- 工具追踪(调用了哪些函数/工具及其结果)
- “工作集”选择,如当前项目/文档、所选模型或工作区
这一层通常跨前端和后端:前端保存轻量的标识符,而后端是会话连续性和访问控制的权威。
3) 数据状态(存储中的持久记录)
数据状态是你有意存储在数据库中的内容:项目、文档、embeddings、偏好、审计日志、计费事件和保存的对话记录。
与 UI 和会话状态不同,数据状态应当:
- 持久(能在重启后存活)
- 可查询(你可以对其搜索/过滤)
- 可审计(你可以事后理解发生了什么)
4) 模型 / 运行时状态(AI 当前的配置)
模型/运行时状态是用于生成答案的运行设置:system prompt、启用的工具、temperature/max tokens、安全设置、速率限制和临时缓存。
其中有些是配置(稳定的默认值);有些是短暂的(短期缓存或每次请求的 token 预算)。大多数内容应放在后端,以便可以一致地控制并避免不必要地暴露。
为什么分离能减少 Bug
当这些层模糊时,会出现典型故障:UI 显示的文本没有被保存,后端使用的 prompt 设置与前端期望的不一致,或对话记忆在用户之间“泄露”。明确边界能创造更清晰的事实来源,并让你更容易判断什么必须持久化、什么可以重算、什么必须受保护。
什么应在前端,什么应在后端(以及原因)
在 AI 应用中,为每一块状态决定其所在位置:浏览器(前端)、服务器(后端)或两者都有,是减少 Bug 的可靠方式。这个选择影响可靠性、安全性,以及当用户刷新、打开新标签或丢失网络时应用的“意外性”。
前端状态:快速、临时、由用户驱动
前端状态适合那些变化快且不需要在刷新后存活的内容。本地保留能让 UI 响应迅速,避免不必要的 API 调用。
常见的仅前端示例:
- 用户正在输入的草稿消息文本
- 表格中的本地过滤和排序
- 模态框的开/关状态、已选标签、hover 状态
如果刷新丢失这些状态,通常可以接受(且常被预期)。
后端状态:权威、敏感、共享
凡是必须被信任、审计或一致强制的内容应放在后端。这包括其他设备/标签页需要查看的状态,或客户端被修改后仍需正确的状态。
常见的仅后端示例:
- 权限与角色(用户被允许做什么)
- 计费/订阅状态与使用限额
- 长时运行任务(文档索引、大规模导出、微调运行)及其状态
一个好的心态:如果错误的状态会花钱、泄露数据或破坏访问控制,那么它属于后端。
共享状态:需协调,但要有唯一的事实来源
有些状态本质上需要共享:
- 对话标题
- 聊天的已选知识源
- 跨设备使用的用户资料字段
即便需要共享,也要选一个“事实来源”。通常后端是权威,前端为速度缓存一份副本。
经验法则(以及常见反模式)
把状态放在最接近使用者的地方,但把必须在刷新、设备切换或中断后仍需存活的状态持久化。
避免把敏感或权威状态仅存放在浏览器中的反模式(例如把客户端的 isAdmin 标记、套餐等级或任务完成状态当作事实)。UI 可以展示这些值,但后端必须验证它们。
一个典型的 AI 请求生命周期:从点击到完成
一个 AI 功能看起来像“一个动作”,但它实际上是一串在浏览器与服务器间共享的状态转换。理解生命周期能帮助避免 UI 不匹配、缺失上下文和重复扣费。
1) 用户操作 → 前端准备意图
用户点击 发送。UI 立即更新本地状态:可能添加一个“挂起”消息气泡,禁用发送按钮,并捕获当前输入(文本、附件、已选工具)。
此时前端应生成或附加关联标识符:
- conversation_id:该消息所属于的线程
- message_id:客户端为新用户消息生成的 ID
- request_id:每次尝试唯一的 ID(对重试很有用)
这些 ID 让双方即便在响应延迟或重复到达时也能讨论同一事件。
2) API 调用 → 服务器验证并持久化
前端发送包含用户消息和 ID 的 API 请求。服务器验证权限、速率限制和载荷格式,然后持久化用户消息(或至少写一条不可变的日志记录),以 conversation_id 和 message_id 为键。
这一步的持久化可防止用户在请求中途刷新导致的“幻影历史”。
3) 服务器重建上下文
为了调用模型,服务器从其事实来源重建上下文:
- 拉取该 conversation_id 的最近消息
- 获取相关记录(文档、偏好、工具输出)
- 应用对话策略(system prompts、记忆规则、截断)
关键思路:不要依赖客户端提供完整历史。客户端可能是陈旧的。
4) 模型/工具执行 → 中间状态
服务器可能在或在模型生成期间调用工具(搜索、数据库查询)。每个工具调用都会产生中间状态,应按 request_id 跟踪,以便审计和安全重试。
5) 响应(流式或非流式)→ UI 完成
对于流式,服务器发送部分 tokens/事件。UI 逐步更新挂起的助手消息,但在收到最终事件标记完成前仍将其视为“进行中”。
6) 需要规划的失败点
重试、重复提交和乱序响应会发生。在服务端使用 request_id 去重,在 UI 使用 message_id 做协调(忽略不匹配当前请求的迟到片段)。始终展示明确的“失败”状态,并提供不会产生重复消息的安全重试方式。
会话与对话记忆:在不混乱的情况下保持上下文
把架构变成代码
描述你的状态模型,让 Koder.ai 生成 React、Go 和 PostgreSQL 的脚手架。
会话是将用户的动作连接起来的“线程”:他们在哪个工作区、上次搜索了什么、正在编辑哪个草稿、AI 回复应继续哪个对话。良好的会话状态让应用在页面间看起来是连续的——理想情况下在设备间也是如此——同时不把后端变成存放用户所有话语的垃圾场。
会话状态的目标
目标是:(1) 连续性(用户可以离开再返回),(2) 正确性(AI 在正确对话中使用正确上下文),以及 (3) 封闭性(一个会话不能漏到另一个会话)。如果你支持多设备,请将会话视为按用户范围加上设备范围:“同一账号”并不总是意味着“相同打开的工作区”。
Cookies、令牌与服务器会话
通常会从以下方式中选其一来标识会话:
- Cookies:对 web 应用最简单,因为浏览器会自动发送。适合传统会话,但必须设置安全标志(
HttpOnly、Secure、SameSite)并适当处理 CSRF。 - 令牌(例如 JWT):适合 API 和移动应用,客户端可以显式附加。扩展性好,但撤销与轮换需要额外设计(且不要把敏感状态塞进令牌里)。
- 服务器会话:服务器存储会话数据(常用 Redis),客户端只保存不透明的会话 ID。最易于撤销和更新,但需要运行和扩展会话存储。
对话记忆策略
“记忆”只是你选择再次传入模型的状态。
- 完整历史:最准确,但成本高且可能暴露旧的敏感内容。
- 摘要历史:保持运行摘要加上几个近期回合;更便宜且通常够用。
- 窗口上下文:只保留最近 N 条消息;最简单,但可能丢失重要的早期决定。
一个实用模式是摘要 + 窗口:可预测并有助于避免令人惊讶的模型行为。
工具调用:可重复且可审计
如果 AI 使用工具(搜索、数据库查询、文件读取),存储每次工具调用的输入、时间戳、工具版本和返回输出(或其引用)。这样可以解释“为什么 AI 那样说”,为调试重放运行,并检测工具或数据集变化导致的结果变化。
隐私保护措施
默认不要长期存储记忆。只保留连续性需要的内容(对话 ID、摘要、工具日志),设置保留期限,避免持久化原始用户文本,除非有明确的产品理由和用户同意。
安全同步状态:事实来源与冲突处理
当同一“事物”可以在多个地方被编辑时——你的 UI、第二个浏览器标签或后台任务更新对话——状态就会变得危险。解决方法不是花哨的代码,而是明确的所有权。
定义事实来源
为每项状态决定哪个系统是权威。大多数 AI 应用中,后端应掌管需正确的核心记录:对话设置、工具权限、消息历史、计费限额与任务状态。前端可缓存并派生状态以提高速度(已选标签、草稿提示文本、“正在输入”指示),但若有不一致,应相信后端。
一个实用规则:如果你失去它会很恼火,那它可能属于后端。
乐观 UI 更新(谨慎使用)
乐观更新能让应用感觉即时:切换设置时立刻更新 UI,再与服务器确认。这适用于低风险且可逆的操作(例如给对话加星)。
当服务器可能拒绝或变更该更改(权限检查、配额限制、验证或服务器端默认值)时,这会导致混淆。在那些场景下,显示“保存中…”并在确认后再更新 UI。
处理冲突(两个标签、一个对话)
当两个客户端基于不同的起始版本更新同一记录时会发生冲突。常见示例:标签 A 和标签 B 都更改了模型的 temperature。
使用轻量的版本控制,让后端检测陈旧写入:
updated_at时间戳(简单且便于人工调试)- ETags /
If-Match头(HTTP 原生) - 递增的修订号(显式冲突检测)
如果版本不匹配,返回冲突响应(通常 HTTP 409),并返回最新的服务器对象。
设计 API 以减少不匹配
任何写入后,API 应返回已持久化的保存对象(包含服务器生成的默认值、规范化字段和新版本)。这让前端能立即替换其缓存副本——一次性更新事实来源,而不是猜测哪些字段变了。
缓存与性能:在不产生陈旧状态的情况下加速
缓存是让 AI 应用感觉即时的快速方法之一,但它也会创建状态的第二份副本。如果你缓存了错误的内容或在错误的位置缓存,你会交付一个既快又令人困惑的 UI。
在客户端缓存什么
客户端缓存应关注体验而非权威。合适的候选项包括最近对话预览(标题、最后消息摘录)、UI 偏好(主题、所选模型、侧边栏状态)和乐观 UI 状态(“发送中”的消息)。
保持客户端缓存小且可丢弃:如果被清空,应用应仍能通过从服务器重新拉取而工作。
在服务器缓存什么
服务器缓存应关注昂贵或高频重复的工作:
- 可以安全复用的工具结果(例如同一城市 5 分钟内的天气查询)
- embeddings 查找和向量搜索结果(通常短 TTL)
- 速率限制状态和限流计数器(保护你的 API 与成本)
这也是缓存派生状态的好地方,例如 token 计数、审查决策或文档解析输出——任何确定性且昂贵的内容。
缓存失效基础(不用搞得太复杂)
三个实用规则:
- 使用清晰的缓存键来编码输入(
user_id、模型、工具参数、文档版本)。 - 根据底层数据变化速度设置 TTL。短 TTL 胜过复杂逻辑。
- 当正确性比速度更重要时绕过缓存:用户更新文档、更改权限或请求刷新时。
如果你无法解释缓存条目何时会出错,就不要缓存它。
不要在共享缓存中缓存秘密或个人数据
避免将 API 密钥、认证令牌、包含敏感文本的原始 prompts 或用户特定内容放入 CDN 等共享层。如果必须缓存用户数据,请按用户隔离并在静态时加密——或把它放在主数据库中。
衡量影响:速度 vs 陈旧 UI
缓存应被验证而非假定。跟踪 p95 延迟变化、缓存命中率以及用户可见错误(例如“渲染后消息被更新”)。一个快速但随后与 UI 冲突的响应往往比稍慢但一致的响应要糟糕。
持久化与长时任务:作业、队列与状态
保障状态安全
为状态写入生成服务器端授权检查和安全的验证模式。
有些 AI 功能在一秒内完成,另一些则需几分钟:上传并解析 PDF、对知识库做 embedding 索引、或运行多步工具工作流。对于这些,“状态”不仅仅是屏幕上显示的内容——它是能在刷新、重试和时间中存活的东西。
应该持久化什么(以及为什么)
只持久化能带来实际产品价值的内容。
对话历史 是显而易见的:消息、时间戳、用户身份,以及(通常)使用的模型/工具。这支持“稍后恢复”、审计追踪和更好的客服。
用户与工作区设置 应该存入数据库:首选模型、temperature 默认值、功能开关、system prompts 以及应跟随用户跨设备的 UI 偏好。
文件与产物(上传、提取文本、生成报告)通常存放在对象存储中,并在数据库中有记录指向它们。数据库保存元数据(所有者、大小、内容类型、处理状态),而 blob 存储保存字节。
针对长任务的后台作业
如果一个请求无法在常规 HTTP 超时内可靠完成,就把工作移到队列中。
典型模式:
- 前端调用
POST /jobs,传入输入(文件 id、conversation id、参数)。 - 后端排队一个作业(提取、索引、批量工具运行),并立即返回一个
job_id。 - 工作进程异步处理作业并把结果写回持久存储。
这让 UI 保持响应,并让重试更安全。
UI 可以信任的状态
使作业状态明确且可查询:queued → running → succeeded/failed(可选 canceled)。在服务器端存储这些状态转换及时间戳与错误详情。
在前端清晰反映状态:
- Queued/running: 显示加载动画并禁用重复操作。
- Failed: 显示简洁错误,并提供 重试 按钮。
- Succeeded: 加载产生的产物或更新对话。
暴露 GET /jobs/{id}(轮询)或推送更新(SSE/WebSocket),让 UI 不必猜测。
幂等键:在重试时避免重复写入
网络超时会发生。如果前端重试 POST /jobs,你并不希望产生两个相同的作业(以及两笔账单)。
对每个逻辑操作要求一个 Idempotency-Key。后端将该键与生成的 job_id/响应一起存储,并对重复请求返回相同结果。
清理与过期策略
长时运行的 AI 应用会快速累积数据。尽早定义保留规则:
- 在 N 天后过期旧对话(或让用户配置)。
- 在源被删除时删除派生产物。
- 定期清理失败的作业和中间文件。
把清理视为状态管理的一部分:它降低风险、成本和用户混淆。
流式响应与实时更新:管理部分状态
流式让状态更棘手,因为“答案”不再是单个完整块。你处理的是部分 tokens(逐字到达)以及有时分步完成的工具工作(搜索启动,后完成)。这意味着你的 UI 和后端必须就什么算临时、什么算最终达成一致。
后端:流式发送有类型的事件,而不仅仅是文本
一个清晰的模式是流式发送一系列小事件,每个事件带有类型与载荷。例如:
token:增量文本(或小片段)tool_start:工具调用开始(例如“搜索中…”,带一个 id)tool_result:工具输出就绪(相同 id)done:助手消息已完成error:发生错误(包含对用户友好的消息和调试 id)
这种事件流比原始文本流更易于版本化与调试,因为前端可以准确渲染进度(并显示工具状态)而无需猜测。
前端:追加式更新,然后最终提交
在客户端,把流式视为追加式操作:创建一个“草稿”助手消息,并在 token 事件到达时持续追加。当收到 done 时执行提交:将消息标记为最终、(如果本地存储)持久化它,并解锁诸如复制、评分或再生成等操作。
这避免了在流式过程中重写历史,使 UI 更可预测。
处理中断(取消、断连、超时)
流式增加了半完成工作的可能性:
- 用户取消: 发送取消信号;停止渲染 tokens;把草稿显式标记为已取消。
- 网络中断: 停止流;显示“重连中…”并不要假设完成。
- 服务器超时/错误: 把草稿最终标记为失败,并提供一个启动新请求的重试(不要在后台无缝拼接两个流)。
重新恢复:重建稳定状态
如果页面在流式中途重新加载,从最近的稳定状态重建:最后已提交的消息加上任何存储的草稿元数据(message id、累计文本、工具状态)。如果无法恢复流,显示草稿为中断状态并让用户重试,而不是假装它已完成。
安全与隐私:端到端保护状态
为 Web 和移动端做原型
创建共享相同后端状态的 Flutter 移动端和 React Web 客户端。
状态不仅是“你存储的数据”——它是用户的 prompts、上传内容、偏好、生成的输出以及将一切连接起来的元数据。在 AI 应用中,这些状态可能异常敏感(个人信息、专有文档、内部决策),因此需要在每一层设计安全性。
把秘密保存在服务器
任何能让客户端冒充你的应用的东西都必须留在后端:API keys、私有连接器(Slack/Drive/DB 凭据)、内部 system prompt 或路由逻辑。前端可以请求一个动作(“总结此文件”),但后端应决定如何执行以及使用哪些凭据。
授权每一次写入(以及大多数读取)
把每次状态变更当作特权操作。当客户端尝试创建消息、重命名对话或附加文件时,后端应验证:
- 用户已认证。
- 用户拥有该资源(对话、工作区、项目)。
- 用户被允许执行该操作(角色、套餐限制、组织策略)。
这能防止“ID 猜测”攻击(有人换用另一个 conversation_id 访问他人历史)。
永远不要信任浏览器:验证与消毒
把任何客户端提供的状态视为不可信输入。验证模式与约束(类型、长度、允许的枚举),并根据目标场景做消毒(SQL/NoSQL、日志、HTML 渲染)。如果接受“状态更新”(例如设置、工具参数),采用字段白名单而不是合并任意 JSON。
关键操作的审计轨迹
对于更改持久状态的操作——分享、导出、删除、连接器访问——记录是谁在什么时候做了什么。轻量的审计日志有助于事件响应、客户支持与合规。
数据最小化与加密
只存你交付功能所需的数据。如果不需要长期保存完整 prompts,考虑保留窗口或做脱敏。对敏感状态在静态时加密(令牌、连接器凭据、上传文档),并在传输时使用 TLS。把操作元数据和内容分离,这样可以更严格地限制访问。
实用参考架构与构建检查清单
一个有用的默认做法是简单的:后端是事实来源,前端是快速的、乐观的缓存。UI 可以感觉即时,但凡是你如果丢失会难受的东西(消息、作业状态、工具输出、计费相关事件)都应被确认并在服务器端存储。
如果你使用“vibe-coding”式的工作流——大量产品表面通过聊天快速生成——状态模型会更重要。像 Koder.ai 这样的平台可以帮助团队从聊天中快速交付完整的 web、后端和移动应用,但同样的规则依旧适用:快速迭代时,最好在一开始就设计好事实来源、IDs 和状态转变。
可交付的参考架构(可部署的)
前端(浏览器/移动)
- UI 状态:打开的面板、草稿提示文本、选定模型、临时“正在输入”指示。
- 缓存的服务器状态:最近对话、上次已知的作业状态、部分流缓冲。
- 一个始终附带
session_id、conversation_id和新的request_id的请求管道。
后端(API + workers)
- API 服务:验证输入、创建记录、发出流式响应。
- 耐久存储(SQL/NoSQL):对话、消息、工具调用、作业状态。
- 队列 + workers:长时任务(RAG 索引、文件解析、图像生成)。
- 缓存(可选):热读(对话摘要、embeddings 元数据),始终按版本/时间戳加键。
注:一种实用方法是尽早标准化你的后端栈。例如,Koder.ai 生成的后端常用 Go + PostgreSQL(前端用 React),这使得把“权威”状态集中在 SQL 中变得直观,同时保持客户端缓存可丢弃。
先设计状态模型
在构建界面之前,定义各层依赖的字段:
- ID 与所有权:
user_id,org_id,conversation_id,message_id,request_id。 - 时间戳与排序:
created_at,updated_at, 以及明确的消息sequence。 - 状态字段:
queued | running | streaming | succeeded | failed | canceled(用于作业和工具调用)。 - 版本控制:
etag或version以实现冲突安全更新。
这能避免 UI “看起来正确”但无法协调重试、刷新或并发编辑的经典问题。
使用一致的 API 形态
在各功能间保持端点可预测:
GET /conversations(列表)GET /conversations/{id}(获取)POST /conversations(创建)POST /conversations/{id}/messages(追加)PATCH /jobs/{id}(更新状态)GET /streams/{request_id}或POST .../stream(流式)
在所有响应中使用相同的包裹样式(包括错误),让前端能统一更新状态。
在状态可能出错的地方增加可观测性
对每次 AI 调用记录并返回 request_id。记录工具调用的输入/输出(脱敏)、延迟、重试和最终状态。让团队能轻易回答:“模型看到了什么、哪些工具运行了、我们持久化了哪些状态?”
构建检查清单(避免常见状态 Bug)
- 后端是事实来源;前端缓存有明确标签且可丢弃。
- 每次写入都是幂等的(可安全重试),使用
request_id(和/或 Idempotency-Key)。 - 状态转换明确且被验证(不允许从
queued无声跃到succeeded)。 - 流式更新按 ID/序列合并,而不是“最后一条消息生效”。
- 冲突通过
version/etag或服务器端合并规则处理。 - PII 与秘密绝不存于客户端状态;默认对日志进行脱敏。
- 提供一个用于调试的面板视图:请求、工具调用、作业状态与错误。
当你采用更快的构建周期(包括 AI 辅助生成)时,考虑添加能自动强制执行这些检查清单项的保护措施——模式验证、幂等性与事件化流式——这样“快速前进”不会导致状态漂移。在实践中,这正是像 Koder.ai 这样的端到端平台能发挥作用的地方:它加快交付,同时允许你导出源代码并在 web、后端与移动构建中保持一致的状态处理模式。