2025年10月03日·1 分钟
以快照为先的开发流程:让重大变更更安全
了解以快照为先的开发流程:在架构、认证和界面变更前创建安全保存点,并在不丢失进度的情况下回滚。
什么是“快照优先”,为什么有用
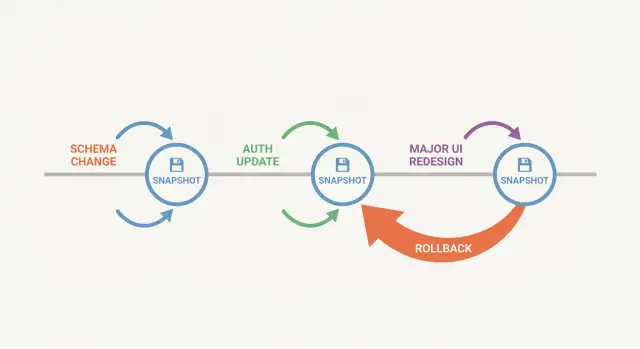
“快照优先”工作流的意思是:在做可能破坏应用的更改之前,先创建一个保存点。快照是项目在某一时刻的冻结副本。如果下一步出现问题,你可以回到那个确切状态,而不是手动去撤销一团糟。
大型变更很少只以一种明显的方式失败。架构更新可能会悄悄地破坏三屏之外的报告。认证微调可能会把你锁在外面。界面重写在示例数据下看起来没问题,但在真实账户和边缘用例下可能崩溃。没有明确的保存点时,你会去猜测是哪次更改导致的问题,或者不停修补一个已坏的版本,直到忘了什么是“工作状态”。
快照能帮你,因为它给了你一个已知良好的基线,让你更便宜地尝试大胆想法,并简化测试。当出现问题时,你可以回答:“在快照 X 之后它还正常吗?”
也要明确快照能保护什么和不能保护什么。快照会保留当时的代码和配置(在像 Koder.ai 这样的平台上,还可以保留你正在使用的完整应用状态)。但它修不正错误的假设。如果你的新功能期望生产环境缺失的数据库列,回滚代码并不会撤销已经运行的迁移。你仍然需要为数据更改、兼容性和部署顺序制定计划。
心态上的转变是把快照当成一种习惯,而不是救生钮。在做有风险的操作前立刻拍快照,而不是等出问题后再补拍。这样你会跑得更快、心也更定,因为你始终有一个干净的“最后已知良好”可回去。
哪些更改值得设置保存点
当某次更改可能同时破坏很多东西时,拍快照最划算。
架构工作是显而易见的:重命名一列可能悄悄破坏仍期望旧名称的 API、后台任务、导出和报表。认证更改也很危险:一个小规则改动可能把管理员锁住或不小心开放了权限。界面重写很狡猾,因为它常把视觉变化和行为变化混在一起,回归往往藏在边缘状态里。
简单规则:在任何会改变数据结构、身份与访问,或一次影响多个屏幕的更改前拍快照。
低风险的编辑通常不需要专门停下来拍快照。文案改动、微调间距、小的校验规则或一个小的辅助函数清理的影响面通常很小。你仍然可以拍快照来帮助自己专注,但不必为每次小改动中断工作流程。
高风险的更改则不同。它们常在“快乐路径”测试中通过,但会在旧行的 null 值、具有不寻常角色组合的用户,或你手动不会触及的界面状态下失败。
如何命名快照以便在紧急时有用
只有当你能在压力下快速识别快照,这个快照才有用。名称和备注能把回滚变成冷静、快速的决定。
一个好的标签回答三个问题:
- 改了什么?
- 为什么改?
- 下一步要做什么?
保持简短但具体。避免模糊的名字,比如“before update”或“try again”。
一种易读的命名模式
选一个模式并坚持使用。例如:
[WIP] 认证:添加 magic link(为 OAuth 做准备)[GOLD] 数据库:users 表 v2(通过基本冒烟测试)[WIP] 界面:仪表盘布局重构(下一步:图表)[GOLD] 发布:计费修复(已部署)Hotfix:登录重定向循环(已记录根因)
先写状态,然后写领域,再写动作,最后写简短的“下一步”。这一小部分在一周后尤其有用。
光有名字还不够。用备注记录你未来会忘记的东西:你做出的假设、你测试了什么、还有什么没修好、你有意忽略了什么。
好的备注通常包含假设、2–3 个快速测试步骤、已知问题,以及任何高风险细节(模式调整、权限更改、路由修改)。
“GOLD” 与 “WIP” 的区别
只有当快照可以在没有惊喜的情况下返回并继续工作时,才把它标记为 GOLD:基本流程可用、错误已被理解、接着可以从那里继续。其他一律标为 WIP。这个小习惯能防止你回滚到一个看似稳定但实际上留着一个大漏洞的点。
分步:一个简单的快照优先循环
一个可靠的循环很简单:只从已知良好的点往前走。
1) 从“能运行”开始
在拍快照之前,确保应用确实能运行且关键流程正常。保持范围小:能否打开主界面、登录(如果你的应用有登录)、并完成一个核心操作而不报错?如果某些东西已经不稳定,先修好它,否则你的快照会保存一个问题。
2) 创建快照并写下意图
创建快照,然后写一句话说明它存在的目的。描述即将存在的风险,而不是当前状态。
示例:“在更改 users 表并添加 organization_id 之前”或“在为 SSO 支持重构认证中间件之前”。
3) 做一项聚焦的改动
避免在一次迭代里叠加多个大改动(模式加认证加界面)。选择一个切片,完成它,然后停止。
一个好的“单一改动”是“添加一个新列并保持旧代码可工作”,而不是“替换整个数据模型并更新每个屏幕”。
4) 每次改动后运行一组小而可重复的检查
每步后都运行相同的快速检查,这样结果才有可比性。保持简短以确保你会去做。
- 应用能启动且无错误
- 一个关键流程端到端可用
- 在该流程中没有出现新的控制台/服务器错误
- 覆盖了你引入的任何新边缘情况(例如空状态)
5) 在新的稳定点再拍一次快照
当改动可用并且你有了干净的基线后,再拍一个快照。那会成为下一步的安全点。
在模式变更前:在哪放保存点
以更安全的方式进行模式变更
通过明确的添加、回填和切换保存点逐步执行迁移。
数据库更改看起来“很小”,直到它们破坏注册、报表或你忘了存在的后台任务时才暴露为大问题。把模式工作当成一系列安全检查点,而不是一次大跳跃。
在动任何东西之前先拍一个快照。然后写一份白话基线:涉及了哪些表、哪些屏幕或 API 调用了它们,以及什么叫“正确”(必填字段、唯一规则、预期行数)。这几分钟的工作能在你需要比较行为时节省数小时。
大多数模式工作的一组实用保存点大致如下:
- 快照 1(基线): 在第一次迁移之前。记录关键表、重要查询以及你用来验证的用户流程。
- 快照 2(添加性变更): 添加新表/列之后(尚未删除旧的)。旧行为仍应可用。
- 快照 3(回填): 在把数据复制/计算到新列后,做少量抽查。
- 快照 4(代码切换): 应用开始从新结构读写之后。
- 快照 5(清理): 只有在真实使用检查后再移除旧列或收紧约束。
避免一次性做巨量迁移把所有东西重命名。把它拆成更小的步骤,这样你可以测试并回滚。
每个检查点之后,验证的不应仅有快乐路径。依赖被改动表的 CRUD 流程很重要,但导出(CSV 下载、发票、管理员报表)同样重要,因为它们常用旧查询。
在开始之前规划回滚路径。如果你添加了新列并开始写入,决定如果你回退会发生什么:旧代码会安全地忽略该列吗,还是需要反向迁移?如果可能出现部分迁移的数据,决定如何检测并完成它,或如何干净放弃它。
在认证变更前:如何避免被锁
认证变更是最快让你(和你的用户)被锁掉的方式之一。保存点之所以有用,是因为你可以尝试有风险的改动、测试它,然后在需要时快速回滚。
在动认证之前拍一个快照。然后写下你当前的状态,即便看起来显而易见也要写。这能避免“我以为管理员还能登录”的惊讶。
记录基础信息:
- 当前登录方式(邮箱/密码、magic link、SSO/OAuth 等)
- 角色与权限(“用户”与“管理员”能做什么)
- 特殊规则(仅受邀、必须 2FA、IP 白名单)
- 测试账号(一个普通用户、一个管理员)
- 与认证相关的密钥与环境设置(key、回调 URL、token 过期等)
开始改动时,一次只动一条规则。如果你同时改了角色检测、令牌逻辑和登录界面,你将无法判断是哪一项导致失败。
一个好的节奏是:改一部分,运行相同的小检查,然后如果干净就拍快照。例如,在添加“编辑者”角色时,先实现创建和分配并确认登录仍可用,然后再加一条权限门并重新测试。
改动后从三个角度验证访问控制。普通用户不应看到管理员专用操作;管理员应能进入设置和用户管理。然后覆盖边缘用例:会话过期、重置密码、被禁用的账户,以及使用你测试中未用到的登录方式的用户。
人们常忽略的一点:密钥通常不在代码里。如果你回滚代码但保留了新密钥和回调设置,认证可能会以令人困惑的方式失效。清楚记录你所做或需要回退的任何环境更改。
在界面重写前:在不混乱的情况下保留进度
通过导出源码保持掌控
在达到干净、可运行的基线时导出源代码。
界面重写风险高,因为它把视觉工作和行为改动混在一起。在界面稳定且可预测时拍一个保存点,即便它不漂亮。这个快照就是你的工作基线:如果必须发布,你会选择回到的最后版本。
将重写拆成片段
界面重写之所以失败,是因为把它当成一次大切换。把工作拆成可独立存在的切片:一个屏幕、一个路由或一个组件。
如果你在重写结账流程,把它拆成购物车、地址、支付和确认。每个切片先匹配旧行为,然后再改进布局、文案和小交互。该切片“足够完成”并且能保留时就拍快照。
重新测试那些常常出问题的部分
每个切片后,做一些针对重写常见失败点的快速回测:
- 导航:能否从主要路径到达该屏幕?
- 表单:校验、必填字段、提交动作
- 加载与空状态
- 错误状态(请求失败、权限错误、重试)
- 移动端行为(小屏、滚动、触控目标)
一个常见失败例子:新的资料页布局更好看,但因为某个组件改变了 payload 形状,某个字段不再保存。若有好的检查点,你可以回滚、对比并重新应用视觉改进,而不丢失几天的工作。
如何安全回滚而不丢失有价值的工作
回滚应当是可控的,而不是惊慌的动作。首先判断是需要完全回滚到已知良好点,还是只回退某一部分改动。
当应用在很多地方都坏了(测试失败、服务器无法启动、登录被锁)时,完全回滚是合适的。若只是单个部分出错(某次迁移、一个路由保护、或某个导致崩溃的组件),则适合部分撤销。
一套安全的回滚流程
把最近的稳定快照当作你的“家”点:
- 回滚到最近的稳定快照。
- 确认关键流程再次可用(启动应用、登录、到达主屏、执行一项关键动作)。
- 立即新建一个快照,命名类似 “stable-after-rollback”。
- 以更小的步骤重新应用那次好的迭代(一个迁移、一条认证规则、一个界面块)。
- 在每个干净的步骤后拍快照,这样你可以在下一个风险点前停下。
然后花五分钟做基础检查。回滚很容易执行,但仍可能错过安静的中断,比如某个后台任务不再运行。
快速检查能捕捉大多数问题:
- 新用户能否注册并登录?
- 主页是否能加载且无错误?
- 创建与保存动作是否有效(“钱的路径”)?
- 数据是否仍然存在且可读?
例子:你做了大规模认证重构,结果把你的管理员账号挡掉了。回滚到那次改动前的快照,验证你能登录,然后以更小的步骤重做改动:先角色,再中间件,最后界面门控。如果再次出问题,你就能精确定位是哪一步引起的。
最后,留一段简短备注:什么坏了、你如何发现、是什么修复了它、下次你会怎么做不同。这会把回滚变成学习而不是时间损失。
让回滚痛苦的常见错误
逐片迭代界面
分片重写 React 页面,并在进行中保存稳定点。
回滚痛苦通常来自不清楚的保存点、混合改动和跳过检查。
太少保存是经典错误。有人匆忙做了一个“快速”的模式调整、一个小认证规则改动和一个界面改动,结果发现应用坏掉却没有干净的返回点。
相反的问题是不断保存但没有备注。十个都叫“test”或“wip”的快照基本上相当于一个快照,因为你无法判断哪个是安全的。
把多个高风险改动混在一次迭代里也是陷阱。如果把模式、权限和界面改动一起上线,回滚就成了猜谜游戏。你也会失去保留好部分(比如界面改进)同时回退危险部分(比如迁移)的选项。
还有一个问题:回滚时不检查数据假设和权限。回滚后数据库可能仍包含新列、意外的 null 或部分迁移的行。或者你可能恢复了旧的认证逻辑,但用户角色是在新规则下创建的。这种不匹配会让人觉得“回滚没生效”,其实回滚是生效了。
如果你想避免大部分问题,简单做法是:
- 在决策点拍快照(在一次有风险的改动之前和之后),而不是仅在一天结束时拍。
- 写一句话的备注:改了什么、你测试了什么、什么算“好”。
- 把大工作拆成不同类型的块:先模式、然后认证、再界面。
- 回滚后验证数据库状态和真实的权限路径。
- 重现触发回滚的那个故障,然后确认它已不存在。
检查清单、一个现实例子和下一步建议
快照与快速检查配合使用效果最佳。这些检查不是完整测试计划,而是一组能快速告诉你是否可以继续或应当回退的动作。
有风险改动前的快速检查
在拍快照前运行这些。你要证明当前版本值得保存。
- 应用能启动且加载无错误。
- 至少一个真实用户(或测试用户)能登录。
- 一个核心流程端到端可用(创建、保存、再查看)。
- 数据库可达并能做基本读取。
- 你能用一句话说明接下来要改的内容。
如果某些东西已经坏了,先修复它。除非你是故意为调试保存该问题,否则不要拍快照保存一个问题。
有风险改动后的快速检查
目标是覆盖一条快乐路径、一条错误路径和一个权限检查。
- 快乐路径:完成你触及的主要操作。
- 错误路径:触发一个已知失败并确认提示合理。
- 权限:验证一个应有权限的用户能访问,而一个不应有权限的用户不能。
- 刷新并重访:重载页面并确认状态未丢失。
- 若有迁移:检查一个旧记录和一个新记录。
示例:新增用户角色并重设计设置界面
想象你在添加一个叫“Manager”的新角色并重设计设置页面。
-
从稳定版本开始。运行改动前检查,然后用清晰名字拍快照,例如:“pre-manager-role + pre-settings-redesign”。
-
先做后端的角色工作(表、权限、API)。当角色和访问规则表现正确时,再拍一个快照:“roles-working”。
-
然后开始 Settings 界面的重写。在重大布局改动前拍快照:“pre-settings-ui-rewrite”。如果界面变糟,回滚到该点并尝试更干净的做法,而不会丢失已经完成的角色工作。
-
当新的 Settings 界面可用时,拍快照:“settings-ui-clean”。只有在那之后再做打磨。
下一步
本周在一个小特性上试试这个流程。选一个有风险的改动,在它前后各放两个快照,并练习一次有目的的回滚。
如果你在 Koder.ai (koder.ai) 上构建,它内建的快照和回滚功能会让这个工作流在迭代时更容易坚持。目标很简单:让重大变更变得可逆,这样你就可以快速推进而不把最佳工作版本当做赌注。
常见问题
What does “snapshot-first” actually mean?
A snapshot is a frozen save point of your project at a specific moment. The default habit is: take a snapshot right before a risky change, so you can return to a known-good state if something breaks.
It’s most helpful when failures are indirect (a schema change breaking a report, an auth tweak locking you out, a UI rewrite failing with real data).
When should I create a snapshot (and when is it overkill)?
Snapshot before changes with a big blast radius:
- Database/schema changes (new columns, renames, constraints, migrations)
- Auth and permissions (roles, middleware, session/token rules, SSO settings)
- Multi-screen UI rewrites (routing, forms, shared components)
For small edits (copy tweaks, minor spacing, tiny refactors), you usually don’t need to stop and snapshot every time.
How should I name snapshots so they’re easy to use later?
Use a consistent pattern that answers:
- What changed
- Why
- What’s next
A practical format is: STATUS + Area + Action (+ next step).
Examples:
What’s the difference between a GOLD snapshot and a WIP snapshot?
Mark a snapshot GOLD only when you’d be happy to return to it and continue work without surprises.
A good GOLD snapshot usually means:
- App starts cleanly
- One core flow works end-to-end
- Any known issues are understood and documented
Everything else is . This prevents rolling back to something that stable but had a major unresolved bug.
What should I test before and after a risky change?
Keep checks short and repeatable so you’ll actually do them:
- App starts without errors
- Login works (if applicable)
- One core flow works end-to-end (create/save/view)
- No new console/server errors during that flow
- One relevant edge state works (empty state, validation error, permission gate)
The goal isn’t full testing—just proving you still have a safe baseline.
What’s a safe snapshot plan for database schema changes?
A practical sequence of save points is:
- Baseline snapshot: before the first migration
- Additive snapshot: after adding new columns/tables (old behavior still works)
- Backfill snapshot: after copying/computing data, with spot checks
How do I avoid lockouts when changing auth or permissions?
Take a snapshot before touching auth, then write down what exists today:
- Login methods
- Roles/permissions
- Test accounts (at least one normal user + one admin)
- Any auth-related environment settings (keys, callbacks, token expiry)
Then change one rule at a time, retest, and snapshot again if it’s clean. Also note any environment changes—rolling back code won’t automatically revert secrets or external settings.
How can I do a UI rewrite without it turning into chaos?
Break the rewrite into slices you can keep independently:
- One screen/route/component at a time
- Match old behavior first (forms, payloads, navigation)
- Then improve layout and interactions
After each slice, retest what usually breaks: navigation paths, form submit/validation, loading/empty/error states, and mobile behavior. Snapshot when a slice is “done enough” to keep.
What’s the safest way to roll back without losing good work?
Use a controlled rollback sequence:
- Roll back to the last stable snapshot.
- Confirm key flows work again (start app, login, core action).
- Create a new snapshot like
stable-after-rollback. - Reapply changes in smaller steps, snapshotting after each clean step.
This turns a rollback into a reset to “home base,” instead of a panic undo.
What are the most common snapshot and rollback mistakes?
Common mistakes:
- Saving too rarely: you can’t find a clean point to return to.
- Saving constantly without notes: you can’t tell what’s safe.
- Mixing big changes: schema + auth + UI in one batch makes failures hard to isolate.
- Ignoring data/env mismatches: rolling back code doesn’t undo a migration that already ran or auth secrets that changed.
Best default: snapshot at decision points (before/after one risky change), add one sentence of notes, and keep risky work separated by type.
What quick checks should I run before a risky change?
Run these right before you take the snapshot. You’re proving the current version is worth saving.
- The app starts and loads without errors.
- Login works with at least one real user (or a test user).
- One core flow works end-to-end (create something, save it, see it again).
- The database is reachable and basic reads work.
- You can state what you’ll change next in one sentence.
If something is already broken, fix that first. Don’t snapshot a problem unless you’re intentionally preserving it for debugging.