2025年9月21日·2 分钟
在你的应用中使用 Meilisearch 实现即时服务端搜索
了解如何在后端添加 Meilisearch 以实现快速、容错拼写的搜索:安装、索引、排名、筛选、安全与扩展基础。
了解如何在后端添加 Meilisearch 以实现快速、容错拼写的搜索:安装、索引、排名、筛选、安全与扩展基础。
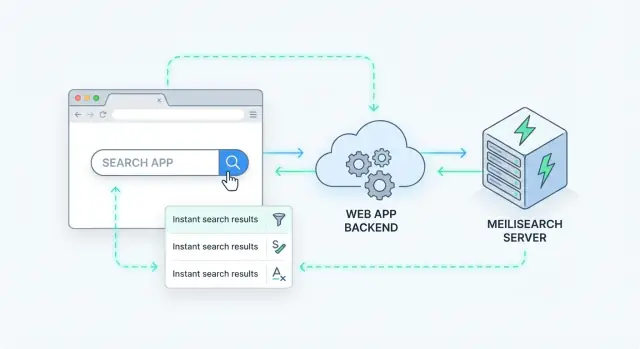
服务端搜索意味着查询在你的服务器(或专用搜索服务)上处理,而不是在浏览器内执行。你的应用发送一个搜索请求,服务器在索引上运行该查询,并返回排序后的结果。
当你的数据集过大无法下发到客户端、你需要在各平台间保持一致的相关性,或访问控制不可妥协(例如内部工具,用户只能看到有权限的记录)时,这一点很重要。它也是当你想要分析、日志记录和可预测性能时的默认选择。
人们不思考搜索引擎本身——他们在评判体验。良好的“即时”搜索流程通常意味着:
如果任何一项缺失,用户会通过尝试不同查询、更多地滚动或直接放弃搜索来补偿。
本文是使用 Meilisearch 构建上述体验的实用指南。我们将介绍如何安全地进行设置、如何构建和同步索引数据、如何调整相关性与排名规则、如何添加筛选/排序/分面,以及如何考虑安全性与扩展性,从而在应用增长时保持搜索快速。
Meilisearch 非常适合:
贯穿始终的目标是:结果感觉即时、准确且可信——而不是把搜索变成一个重大工程项目。
Meilisearch 是一个与你的应用并行运行的搜索引擎。你把文档(如产品、文章、用户或支持工单)发送给它,它会构建一个为快速搜索优化的索引。然后你的后端(或前端)通过简单的 HTTP API 查询 Meilisearch,并在毫秒级返回排序后的结果。
Meilisearch 专注于现代搜索应具备的特性:
它被设计得在查询短、小错或模糊时仍然响应迅速与宽容。
Meilisearch 不是替代主数据库。你的数据库仍然是写入、事务和约束的真实来源。Meilisearch 存储你选择的那些字段的副本,用于可搜索、可筛选或可展示的用途。
一个好的心智模型是:数据库用于存储与更新数据,Meilisearch 用于快速查找。
Meilisearch 可以非常快,但结果取决于几个实际因素:
对于小到中等的数据集,通常可以在单台机器上运行。随着索引增长,你需要更谨慎地决定索引内容以及如何保持更新——这些将在后续部分讨论。
在安装任何东西之前,先确定你到底要搜索什么。只有当你的索引与文档匹配用户浏览应用的方式时,Meilisearch 才会感觉“即时”。
从列出可搜索的实体开始——通常是 products(产品)、articles(文章)、users(用户)、help docs(帮助文档)、locations(位置)等。许多应用中,最清晰的方法是每种实体类型一个索引(例如 products、articles)。这能保持排名规则和筛选可预测。
如果你的 UX 希望在一个搜索框中跨类型搜索(“搜索所有”),你仍然可以保持分开的索引并在后端合并结果,或稍后创建一个专门的“全局”索引。不要把所有不同结构强行塞进一个索引,除非字段和筛选确实对齐。
每个文档都需要一个稳定的标识符(主键)。选择应满足:
id、sku、slug)对于文档形态,尽量偏好扁平字段。扁平结构更易于筛选与排序。嵌套字段在表示紧密且不常变的捆绑数据(例如 author 对象)时是可以的,但要避免深度嵌套成数据库式的完整关系结构——搜索文档应为读优化而非数据库形态。
设计文档的一个实用方法是为每个字段标注其角色:
这可以防止常见错误:把某字段“以防万一”也索引了,后来发现结果噪声太大或筛选变慢。
“语言”在数据中可能有不同含义:
lang: "en")尽早决定是使用按语言分开的索引(简单且可预测),还是使用带语言字段的单一索引(索引数更少,但逻辑更复杂)。正确答案取决于用户是否通常在单一语言下搜索以及你如何存储翻译内容。
运行 Meilisearch 很直接,但“默认安全”需要做出几项决定:部署位置、数据持久化方式以及如何管理主密钥。
存储: Meilisearch 会把索引写到磁盘。将数据目录放在可靠的持久存储上(不要放在容器的临时存储里)。为增长规划容量:大文本字段和许多属性会让索引迅速膨胀。
内存: 分配足够的 RAM 以在负载下保持响应。如果发生交换(swapping),性能会下降。
备份: 备份 Meilisearch 数据目录(或在存储层使用快照)。至少测试一次恢复;无法恢复的备份只是文件而已。
监控: 跟踪 CPU、内存、磁盘使用与磁盘 I/O。也要监控进程健康和日志错误。至少在服务停止或磁盘空间不足时告警。
在除本地开发外的任何环境中都应使用 master key(主密钥) 运行 Meilisearch。将其存放在秘密管理器或加密的环境变量存储中(不要放在 Git 中,也不要提交到仓库的明文 .env)。
示例(Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
还要考虑网络规则:绑定到私有接口或限制入站访问,使只有你的后端能访问 Meilisearch。
curl -s http://localhost:7700/version
Meilisearch 的索引是异步的:你发送文档,Meilisearch 将任务入队,只有在任务成功后这些文档才会可搜索。把索引当作一个作业系统,而不是一个单次请求。
id)。curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
taskUid。轮询直到状态为 succeeded(或 failed)。curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
如果计数不匹配,不要盲目猜测——先查看任务的错误详情。
批量的目标是让任务可预测且可恢复。
addDocuments 表现为 upsert(插入或更新):相同主键的文档会被更新,新的会被插入。将其用于常规更新。
当发生以下情形时做 全量重建:
若要删除文档,请显式调用 deleteDocument(s);否则旧记录可能会残留。
索引应可重试。关键在于稳定的文档 id。
taskUid 与你的批次/作业 id 一并持久化,并基于任务状态来重试。在真实数据前,索引一小批符合真实字段的数据(200–500 项)。示例:一个包含 id、name、description、category、brand、price、inStock、createdAt 的 products 集合。这足以验证任务流程、计数以及更新/删除行为——无需等待大规模导入。
“相关性”简单说就是:什么先展示以及为什么。Meilisearch 让你在不重写完整打分系统的情况下进行可调优。
两个设置决定了 Meilisearch 如何处理你的内容:
searchableAttributes:用户输入时 Meilisearch 会查找的字段(例如:title、summary、tags)。顺序很重要:靠前的字段被视为更重要。displayedAttributes:响应中返回的字段。它关系到隐私与载荷大小——如果字段不在此列,它不会被返回。实用基线是让少数高信号字段可搜索(title、关键文本),并把展示字段限定为 UI 所需。
Meilisearch 使用 排名规则(ranking rules) 把匹配到的文档排序——这是一系列“平手决胜”的管道。概念上,它优先:
你无需记住内部细节来有效调优;主要是选择哪些字段更重要以及何时应用自定义排序。
目标:“标题匹配应优先”。把 title 放在最前:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
目标:"较新的内容优先"。添加可排序属性,并在查询时按时间排序(或设置自定义排名):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
然后请求:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
目标:"提升热门商品"。使 popularity 可排序,并在适当时按此排序。
挑 5–10 个真实查询并保存更改前的前 N 条结果,然后比较更改后的结果。
示例:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer如果“之后”的列表更符合用户意图,就保留设置;若伤害到边缘案例,每次只改变一项(先属性顺序,再排序规则),以便知道改动效果来源。
一个好的搜索框不只是“输入单词,得到匹配”。人们也想缩小结果(“只看可用商品”)并按某种规则排序(“最便宜优先”)。在 Meilisearch 中,你用 filters(筛选)、sorting(排序) 与 facets(分面) 来实现这些功能。
筛选 是对结果集施加的规则。分面 则是帮助用户构建这些规则的 UI(通常为复选框或带计数的选项)。
非技术示例:
用户可能先搜索 “running”,然后筛选 category = Shoes 与 status = in_stock。分面可以显示计数,如 “Shoes (128)”、“Jackets (42)”,让用户了解可用性。
Meilisearch 需要你显式允许用于筛选与排序的字段。
category、status、brand、price、created_at(如果按时间筛选)、tenant_id(如果需要隔离客户)。price、rating、created_at、popularity。把列表保持紧凑。把所有字段都设为可筛选/可排序会增加索引大小并减慢更新。
即使有 50,000 个匹配,用户也只会看到第一页。使用较小页面(通常 20–50 条),设置合理的 limit,并使用 offset 分页(或使用更新的分页特性)。同时在应用中限制最大页深,防止昂贵的“第 400 页”请求。
一个清晰的方式是把 Meilisearch 当作后端后面的一种专用数据服务。你的应用接收搜索请求,调用 Meilisearch,然后返回给客户端一个经过策划的响应。
多数团队最终采用如下流程:
GET /api/search?q=wireless+headphones&limit=20)。此模式让 Meilisearch 更易替换,并防止前端依赖索引内部细节。
如果你在构建新应用(或重构内部工具)并想快速实现此模式,一些低代码/脚手架平台可以帮助生成完整流程——React UI、Go 后端与 PostgreSQL——然后在单一 /api/search 端点后接入 Meilisearch,让客户端更简单并把权限控制放在服务端。
Meilisearch 支持客户端直接查询,但后端查询通常更安全,因为:
对于公开数据、使用受限键的情况,前端查询仍可行,但如果存在任何基于用户的可见性规则,务必通过服务器路由搜索。
搜索流量常有重复(如 “iphone case”、“return policy”)。在 API 层加缓存可提升效率:
把搜索视为面向公众的端点:
limit 与最大查询长度。Meilisearch 常置于应用“后面”,因为它能快速返回可能包含敏感业务数据的结果。把它像数据库一样锁好,只暴露每个调用者应该看到的内容。
Meilisearch 有一个能做所有事的 master key(主密钥):创建/删除索引、更新设置、读写文档。仅在服务器端保管它。
为应用生成受限操作与受限索引的 API 密钥。常见模式:
最小权限意味着即使密钥泄漏,也无法删除数据或读取无关索引。
若为多个客户(租户)提供服务,有两种主要方案:
1)每个租户一个索引。
易于推理并降低跨租户访问风险。但缺点是索引数量更多,且需要一致地应用设置更新。
2)共享索引 + tenant filter。
在每个文档上存储 tenantId 字段,并强制所有搜索都带如 tenantId = "t_123" 的筛选。这在你能确保每次请求都应用该筛选时能很好地扩展(最好通过范围化密钥防止调用方移除筛选)。
即使搜索逻辑正确,结果也可能泄露你不想显示的字段(邮箱、内部备注、成本价)。配置可检索的字段:
做一次“最坏情况”测试:搜索一个常见词并确认没有私有字段出现。
如果不确定某个密钥是否应在客户端使用,默认答案是“否”,把搜索保留在服务端。
Meilisearch 快的前提是你关注两类工作负载:索引(写) 与 查询(读)。大多数“莫名慢”问题只是这两者在争夺 CPU、内存或磁盘资源。
索引负载 会在你导入大批量、频繁更新或添加许多可搜索字段时激增。索引是后台任务,但仍会消耗 CPU 与磁盘带宽。如果任务队列增长,即便查询量未变,搜索也会变慢。
查询负载 随访问量增长,还受功能影响:更多筛选、更多分面、更大的结果集与更强的容错拼写都会增加每次请求的工作量。
磁盘 I/O 常常是悄无声息的元凶。慢盘(或共享卷上的“噪声邻居”)会把“即时”变为“最终”。生产环境的典型基线是 NVMe/SSD 存储。
先做简单的容量规划:给 Meilisearch 足够的 内存以保持索引热存 与足够的 CPU 以应对峰值 QPS。然后分离关注点:
跟踪一组关键信号:
备份应成为例行操作,而非临时抱佛脚。使用 Meilisearch 的 snapshot 功能按计划生成快照,将快照存放到外部,并定期测试恢复。升级前阅读发行说明,在非生产环境演练升级,并预估版本变更是否会影响索引,从而需要重建索引时间。
如果你已经使用平台的环境快照与回滚(例如某些平台提供的 snapshot/rollback 工作流),把搜索的发布流程与同样的纪律对齐:变更前快照、验证健康检查,并保留快速回退到已知良好状态的路径。
即使集成干净,搜索问题通常集中在几个可复现的类别。好消息是:Meilisearch 提供了足够的可视性(任务、日志、确定性设置)来快速调试——前提是你按系统化方式检查。
filterableAttributes,或文档中该字段的形态与预期不符(字符串 vs 数组 vs 嵌套对象)。sortableAttributes/rankingRules 调整把“错误”的项排上去了。先检查 Meilisearch 是否成功应用了你最近的更改。
filter,再 sort,然后 facets。如果无法解释一个结果,暂时剥离你的配置:移除同义词、减少排名规则调整,并用一个小数据集测试。复杂的相关性问题在 50 条文档上比在 500 万条上更容易发现。
your_index_v2,应用设置并回放一部分生产查询样本。filterableAttributes 与 sortableAttributes 与 UI 要求一致。Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
服务端搜索意味着查询在你的后端(或专用搜索服务)上运行,而不是在浏览器内。适用场景包括:
用户在搜索体验上会立即注意到四点:
只要缺少其中一项,用户就会重写查询、翻得更多页或放弃搜索。
把 Meilisearch 看作一个搜索索引,而不是你的可信数据源。数据库仍然负责写入、事务和约束;Meilisearch 存储你选择的一份用于快速检索的字段副本。
一个有用的思维模型是:
一个普遍的默认做法是对每种实体类型使用一个索引(例如 products、articles)。这样可以保持:
如果需要“搜索所有内容”,可以在后端查询多个索引并合并结果,或稍后新增一个专门的全局索引。
选择一个主键应满足:
id、sku、slug)稳定的 ID 使索引具备幂等性:如果重试上传,相同主键会以更新(upsert)方式处理,不会产生重复项。
为避免过度索引或遗漏,需要为每个字段明确分工:
明确这些角色可以减少噪声结果,并避免索引过大或更新缓慢。
索引是异步的:文档上传会创建一个任务,只有当任务成功后,文档才会变为可搜索。
一个可靠的流程:
succeeded 或 failed如果结果看起来是旧的,先检查任务状态再做其他调试。
建议使用多个较小的批次而非一次性的大上传。实用起点:
较小的批次更容易重试、更容易排错(找出坏记录),也不容易超时。
两个高影响的调整杠杆是:
searchableAttributes:哪些字段被搜索,以及字段的重要性顺序publishedAt、price 或 popularity 等字段排序实用方法:取 5–10 个真实查询,记录调整前的前 N 条结果,修改一个设置后再比较“前后”差异。
大多数筛选或排序失败来自配置缺失:
filterableAttributes 中sortableAttributes 中还要确认文档中该字段的形态与类型(字符串、数组或嵌套对象)。如果筛选失败,检查最近的设置/任务状态,并确认索引文档确实包含预期的字段值。