2025年8月21日·1 分钟
Palantir Foundry 与 传统 BI:超越仪表盘
了解 Palantir Foundry 风格的运营决策系统与传统 BI 仪表盘、报告和自助分析有何不同——以及在何种场景下各自更合适。
了解 Palantir Foundry 风格的运营决策系统与传统 BI 仪表盘、报告和自助分析有何不同——以及在何种场景下各自更合适。
大多数“BI vs Foundry”的讨论卡在功能上:哪个工具图表更好、查询更快或仪表盘更漂亮。但这些很少是决定性因素。真正的比较取决于你想要达成的目标。
仪表盘可以告诉你发生了什么(或正在发生什么)。运营决策系统则用于帮助人们决定下一步该做什么——并使该决策可重复、可审计且与执行相连。
洞察不等于行动。知道库存不足不同于触发补货、重新规划运输、更新计划并跟踪决策是否生效。
本文拆解了:
尽管 Palantir Foundry 是一个有用的参考点,但这里的概念更为普适。任何将数据、决策逻辑和工作流连接起来的平台,其行为都会不同于主要用于仪表盘和报告的工具。
如果你负责运营、分析或在需要在时间压力下做出决策的业务(供应链、制造、客户运维、风控、现场服务),本比较将帮助你将工具与实际工作方式对齐——以及识别今天决策容易出问题的环节。
传统商务智能(BI)工具旨在通过仪表盘和报告帮助组织“看见”正在发生的事情。它们擅长将数据转化为共享指标、趋势和汇总,供领导和团队监控绩效使用。
仪表盘用于快速建立态势感知:销售是上升还是下降?服务水平是否在目标内?哪些地区表现不佳?
好的仪表盘让关键指标易于浏览、比较和深钻。它们为团队提供共同的语言(“这是我们信任的数字”),并帮助及早发现变化——尤其在配合告警或定期刷新时。
报告强调一致性和可重复性:月末报告、每周运营包、合规模块和高管记分卡。
目标是稳定的定义和可预测的交付:相同的 KPI 以相同方式计算,并按节奏分发。在这里,语义层和认证指标之类的概念很重要——每个人必须以相同方式解读结果。
当出现新问题时,BI 工具也支持探索:为什么上周转化下降?哪些产品导致退货?定价更新后发生了什么?
分析师可以按细分切片、过滤、构建新视图并测试假设,而无需等待工程工作。低摩擦的洞察访问是传统商务智能长久存在的主要原因之一。
BI 在输出是理解时表现卓越:快速上手仪表盘、熟悉的用户体验以及广泛的采用。
常见的限制在于“接下来发生什么”。仪表盘可以突出问题,但通常不执行响应:分配工作、强制执行决策逻辑、更新操作系统或跟踪动作是否执行。
这种“那又如何?”和“接下来做什么?”的差距,是当团队需要真正将分析转化为行动和决策工作流时寻找其他工具的重要原因。
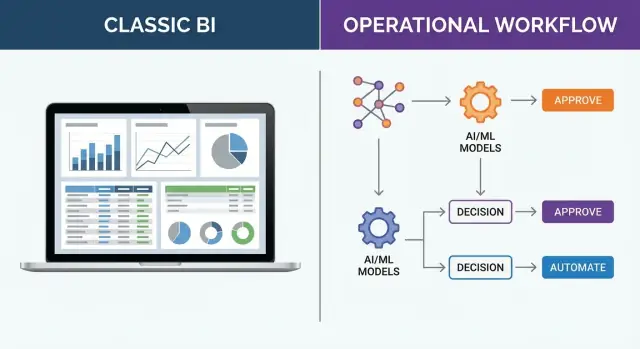
运营决策系统为企业在“工作进行中”所做的选择而建——而不是事后分析。这类决策频繁、时间敏感且可重复:关注的是“下一步我们该怎么做?”而不是“上个月发生了什么?”
传统 BI 擅长仪表盘和报告。运营决策系统更进一步,将 数据 + 逻辑 + 工作流 + 问责 打包,使分析能够可靠地在真实业务流程中转化为行动。
运营决策通常具有一些共同特征:
系统不是产出一个仪表盘格子,而是生成适用于工作的可执行输出:
例如,运营决策系统可能不会仅展示库存趋势,而是生成包含阈值、供应商约束和人工审批步骤的补货建议。它可能不会只给出客服仪表盘,而是创建带规则、风险评分和审计链的工单优先级。在现场运维中,它可能基于产能和新约束提出排班调整建议。
成功不是“更多报告被查看”。而是业务流程结果的改善:更少缺货、更快解决时间、降低成本、更高的 SLA 遵从率以及更清晰的问责机制。
在 Palantir Foundry vs BI 中最重要的区别不是图表类型或仪表盘精致度,而是系统是在洞察处停止(开环),还是延续到执行与学习(闭环)。
传统商务智能优化的是仪表盘和报告。常见流程为:
最后一步很关键:决策发生在人脑里、会议中或邮件往来之中。这适用于探索性分析、季度复盘以及下一步行动模糊的问题。
在仅用 BI 的方法中经常产生延迟的环节通常在于“我看到了问题”到“我们做了什么”之间:
运营决策系统 将管道延伸到洞察之外:
区别在于“decide”和“execute”是产品的一部分,而非手动交接。对于可重复的决策(批准/拒绝、优先级、分配、路由、排期),以工作流和决策逻辑编码可以降低延迟和不一致性。
闭环意味着每个决策都可以追溯到输入、逻辑和结果。你可以衡量:我们做了什么选择?接下来发生了什么?规则、模型或阈值是否应调整?
随着时间推移,系统从真实运营中学习,而不是只依赖人们后来记得讨论的内容。这正是将分析转化为行动的实际桥梁。
传统 BI 架构通常是一串各自优化特定步骤的组件:用于存储的数据仓库或数据湖、用于移动和整形数据的 ETL/ELT 管道、用于标准化指标的语义层,以及用于可视化的仪表盘/报告。
当目标是稳定的报告和分析时,这种方式效果很好,但“行动”通常发生在系统之外——通过会议、邮件和人工交接。
Foundry 风格的方法更像一个平台,数据、转换逻辑与操作界面更贴近地生活在一起。它不是把分析当作管道的终点,而是把分析视为生成决策、触发任务或更新操作系统的一个要素。
在许多 BI 环境中,团队为特定仪表盘或问题创建数据集(例如“第三季度按地区的销售”)。随着时间推移,你会产生许多相似但逐渐分化的表格。
采用“数据产品”思路的目标是创建可复用、定义清晰的资产(包含输入、负责人、刷新行为、质量检查和预期使用者)。这使得在相同受信任的构建模块上构建多个应用和工作流更容易。
传统 BI 通常倚重批处理更新:夜间加载、定期模型刷新和周期性报告。运营决策常常需要更新更频繁——有时接近实时——因为迟到的行动代价高(错过发货、缺货、延迟干预)。
仪表盘适合监控,但运营系统通常需要捕获与路由工作的界面:表单、任务队列、审批和轻量级应用。这是从“看数字”到“完成步骤”的架构转变。
仪表盘有时能容忍“差不多正确”的数据:如果两支团队对客户的计数不同,你仍能做出图表并在会议中解释不一致。但运营决策系统没有这种奢侈。
当决策触发工作——批准发货、优先派遣、阻止支付——定义必须在团队和系统间保持一致,否则自动化很快变得不安全。
运营决策依赖共享语义:什么是“活跃客户”、什么是“已履约订单”或“延迟交付”?没有一致定义,工作流的某一步会与下一步对同一记录产生不同解释。
这就是为什么语义层和良好维护的数据产品比完美的可视化更重要。
当系统无法可靠回答“这是不是同一供应商?”之类的基础问题时,自动化就会失效。运营环境通常需要:
如果这些基础缺失,每次集成都变成一次性映射,且一旦源系统变化就会失败。
多来源数据质量问题常见——重复 ID、缺失时间戳、单位不一致。仪表盘可以过滤或标注;运营工作流需要明确的处理方式:验证规则、回退和异常队列,以便人工干预而不致整个流程停止。
运营模型需要实体、状态、约束和规则(例如“订单 → 打包 → 发货”、产能限制、合规约束)。围绕这些概念设计管道,并预期会发生变化,有助于避免在新产品、新地区或新政策下崩溃的脆弱集成。
当你从“查看洞察”转向“触发行动”时,治理不再只是合规选项,而成为运营安全系统。
自动化会成倍放大错误的影响:一次错误的关联、陈旧的表格或过宽的权限可能在几分钟内传播到数百个决策。
在传统 BI 中,错误数据往往导致错误解读。在运营决策系统中,错误数据可能导致错误的结果——库存被重新分配、订单被改路、客户被拒绝、价格被更改。
这就是为什么治理必须直接位于数据 → 决策 → 行动的路径上。
仪表盘通常关注“谁能看到什么”。运营系统需要更细粒度的分离:
这能降低“读权限意外变成写影响”的风险,尤其当工作流集成到工单系统、ERP 或订单管理时。
良好的血缘不仅是数据来源——还是决策来源。团队应能追溯一条推荐或动作,回溯到:
同样重要的是可审计性:记录为何给出某项推荐(输入、阈值、模型版本、规则命中),而不仅是推荐了什么。
运营决策常需审批、覆盖与受控异常。将职责分离——构建者 vs 审批者、推荐者 vs 执行者——有助于防止无声失败,并在系统遇到边缘情况时创建可审查的痕迹。
仪表盘回答“发生了什么?”。决策逻辑回答“接下来我们该怎么做,以及为什么?”。在运营场景中,该逻辑需要明确、可测试且可安全变更——因为它能触发审批、改道、阻止或外呼。
当策略简单明了时,基于规则的决策非常有效:“如果库存低于 X,则加急”,或“如果工单缺少必要文件,先请求补齐再审查”。
优点是可预测和可审计。风险是脆弱性:规则可能冲突或随着业务变化变得过时。
许多真实决策不是二选一,而是分配问题。优化在资源有限(人员时长、车辆、预算)且目标竞争(速度 vs 成本 vs 公平)时很有用。
你不是用单个阈值,而是定义约束和优先级,然后生成“在约束下的最佳计划”。关键是让约束对业务负责人可读,而不仅对建模者。
机器学习通常适合作为评分步骤:排名线索、标记风险、预测延迟。在运营工作流中,ML 通常应作为推荐而非静默自动化——尤其当结果影响客户或合规时。
人们需要看到驱动推荐的主要因素:所用输入、原因代码以及会改变结果的因素。这能建立信任并支持审计。
运营逻辑必须被监控:输入数据偏移、性能变化和意外偏差。
使用受控发布(例如影子模式、有限滚动和版本控制),以便比较结果并能快速回滚。
传统 BI 优化的是查看:仪表盘、报告、切片与钻取视图,帮助人理解发生了什么及原因。
运营决策系统优化的是执行。主要用户是计划员、调度员、案卷处理员和主管——他们进行许多小而时间敏感的决策,且“下一步”不能是会议或另一个系统里的工单。
仪表盘擅长广泛可见性与讲故事,但在需要采取行动的瞬间常制造摩擦:
这种上下文切换会带来延迟、错误与决策不一致。
运营 UX 采用引导用户从信号到解决的设计模式:
界面不再是“这是图表”,而是回答:需要做什么决策、哪些信息重要、我能在这里直接做什么?
在像 Palantir Foundry 这样的平台中,这通常意味着将在组装底层数据与逻辑的同一环境中嵌入决策步骤。
BI 的成功常用报告使用率衡量。运营系统应像生产工具一样评估:
这些指标揭示系统是否真正改变了结果,而非仅生成洞察。
当目标不是“知道发生了什么”,而是“决定下一步做什么”——并做到一致、快速、可追溯时,运营决策系统价值凸显。
仪表盘能提示缺货或延迟发货;运营系统则帮助解决这些问题。
它能推荐跨配送中心的重新分配、基于 SLA 与利润率优先处理订单并触发补货请求——同时记录决策原因(约束、成本与例外情况)。
当出现质量问题时,团队需要的不仅是缺陷率图表。决策工作流可以路由事件、建议遏制措施、识别受影响批次并协调产线切换。
在维护排程中,它可以在风险、技工可用性和生产目标之间权衡,然后将批准的排期推入日常工作指令。
在临床运营与理赔中,瓶颈常在优先级判断。运营系统可以使用策略与信号(严重程度、等待时间、缺失文档)对案件进行分流,将其分配到合适队列,并支持无需丢失审计性的产能规划“假设-情景”分析。
在停电等事件中,决策必须快速且协调。运营系统可以合并 SCADA/遥测、天气、队伍位置与设备历史,推荐派工计划、恢复顺序和客户沟通,并在条件变化时跟踪执行与更新。
欺诈与信贷团队的工作流是:复核、请求资料、批准/拒绝、升级。运营决策系统可标准化这些步骤,应用一致决策逻辑并将事项路由到合适的复核人。
在客户支持中,它们可以基于意图、客户价值和所需技能来分配工单——改善结果,而不仅仅是对其进行报告。
运营决策系统在像产品一样实施时失败更少,而不是把它当作“数据项目”。目标是端到端证明一个决策回路:数据输入、决策产生、行动执行并测量结果,然后再扩展。
选择一个有明确商业价值且有真实负责人的决策。记录基础信息:
这能保持范围紧凑并使成功可衡量。
洞察不是终点。把“完成”定义为指定动作发生改变,并明确在哪里发生——例如在工单系统中更新状态、在 ERP 中批准、在 CRM 中生成呼叫列表。
良好定义应包含目标系统、精确的字段/状态变化以及如何验证其发生。
避免第一天试图自动化所有内容。先用异常优先工作流:系统标记需要关注的项,路由给合适的人并跟踪解决。
优先集成少数高杠杆点(ERP/CRM/工单),并显性化审批步骤。这样可降低风险,避免系统外的“影子决策”。
运营工具会改变行为。在推广计划中包括培训、激励和新角色(如工作流负责人或数据管理员),以保证流程真正落地。
实现运营决策系统的一个实际挑战是你通常需要轻量级应用——队列、审批界面、异常处理和状态更新——才能证明价值。
像 Koder.ai 这样的平台可以通过聊天驱动的 vibe-coding 方法快速为团队原型化这些工作流界面:描述决策流程、数据实体和角色,然后生成初始 Web 应用(通常是 React)和后端(Go + PostgreSQL),供你迭代。
这并不能替代健全的数据集成与治理,但可以缩短“从决策定义到可用工作流”的周期——尤其是在你使用规划模式对齐利益相关者,并用快照/回滚进行安全测试时。如果之后需要将应用迁移到其它环境,导出源代码可以降低锁定风险。
判断 Palantir Foundry vs BI 的最简单方式是从你想改进的决策入手——而不是你想买的功能。
当目标是可见性与学习时,选择传统商务智能(仪表盘和报告):
如果主要结果是更好的理解(而不是立即的操作行动),BI 通常是正确的选择。
当决策是重复且结果依赖于一致执行时,运营决策系统更合适:
这里的目标是从分析到行动:把数据变成可靠触发下一步的决策工作流。
许多组织在广泛可见性上保留 BI,并在需要标准化执行的地方增加决策工作流(以及受治理的数据产品和语义层)。
创建决策清单,对每项按商业影响与可行性评分,然后选取一个高影响的决策进行试点并设定清晰的成功指标。
Traditional BI is designed to monitor and explain performance through dashboards, reporting, and ad hoc analysis. An operational decision system is designed to produce and track actions by combining data + decision logic + workflow + auditability so decisions can be executed consistently inside real processes.
“Open loop” means the system ends at insight: ingest → model → visualize → human interprets, and execution happens in meetings, email, or other tools. “Closed loop” extends through decide → execute → learn, so actions are triggered, outcomes are recorded, and the decision logic can be improved based on real results.
Choose BI when the primary output is understanding, such as:
BI is usually enough when there isn’t a clear, repeatable “next action” that must be executed inside a workflow.
You need an operational decision system when decisions are:
In these cases, the value comes from reducing decision latency, inconsistency, and manual handoffs.
A dashboard typically outputs a metric or trend that requires someone to translate it into tasks elsewhere. A decision workflow outputs things like:
Success is measured by outcomes (e.g., fewer stockouts), not report views.
Operational systems need consistent semantics because automation can’t tolerate ambiguity. Common requirements include:
If these foundations are weak, workflows become brittle and unsafe to automate.
Because once insights trigger actions, mistakes scale fast. Practical controls include:
This turns governance into an operational safety system, not just a reporting checkbox.
Start with logic that’s explicit and testable:
Add monitoring and controlled releases (shadow mode, limited rollout, versioning) so you can measure impact and roll back safely.
Implement it like a product by proving one loop end-to-end:
Yes—many organizations use a hybrid:
A practical approach is to create a decision inventory, score candidates by impact and feasibility, then pilot one high-value loop before expanding.
This reduces scope risk while validating real operational value.