2025年12月18日·1 分钟
Postgres 架构设计规划模式:逐步方法
Postgres 架构设计的规划模式可帮助你在生成代码前先确定实体、约束、索引和迁移,从而减少后期重写。
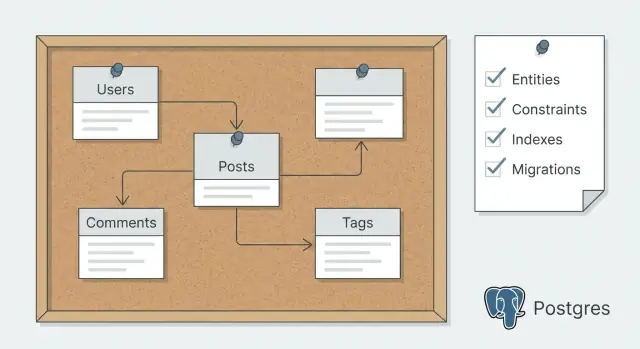
Postgres 架构设计的规划模式可帮助你在生成代码前先确定实体、约束、索引和迁移,从而减少后期重写。
如果你在数据库结构尚未明确时就先构建端点和模型,通常会发现自己把相同的功能重写了两次。应用为演示可用,但当真实数据和边界情况到来时,一切会变得脆弱。
大多数重写都来自三类可预测的问题:
每一项都会引发需要改动代码、测试和客户端应用的连锁反应。
规划 Postgres 模式意味着先决定数据契约,然后生成与之匹配的代码。实际流程通常是把实体、关系和几条关键查询写下来,然后在任何工具搭建表和 CRUD 之前确定约束、索引和迁移策略。
当你使用像 Koder.ai 这样的即写即生成平台时,这一点尤其重要:快速生成很好,但只有在模式稳定的情况下才更可靠。生成的模型和端点之后需要的修改会更少。
跳过规划时常见的问题包括:
一个好的模式规划很简单:用通俗语言描述实体、草拟表和列、列出关键约束和索引,并制定一个在产品增长时能安全变更的迁移策略。
最佳的模式规划从应用需要记住什么以及用户需要如何使用这些数据开始。用两到三句通俗的话写出目标。如果你不能简单地解释它,很可能会创建不必要的表。
接着,关注那些会创建或修改数据的动作。这些动作才是真正产生行的来源,也揭示了必须校验的内容。用动词来思考,而不是名词。
例如,一个预订应用可能需要创建预订、改期、取消、退款并向客户发送消息。这些动词会很快提示需要存储什么(时间槽、状态变更、金额),然后你才给表命名。
也要记录读取路径,因为读取会驱动后续的结构和索引。列出用户实际使用的界面或报表以及他们如何切分数据:按日期排序并按状态筛选的 “我的预订”,按客户名或预订编号的管理员搜索、按地点的每日收入以及谁在何时修改了数据的审计视图。
最后,注意会影响模式选择的非功能需求,比如审计历史、软删除、多租户隔离或隐私规则(例如限制谁能看到联系方式)。
如果你打算在这之后生成代码,这些笔记会成为强有力的提示。它们说明了哪些是必需的、哪些可能会变、更需要可搜索。如果你使用 Koder.ai,先把这些写清楚再生成会让规划模式更有效,因为平台是基于真实需求而非猜测工作。
在动手建表前,用通俗语言写出应用保存的内容。先列出重复出现的名词:user、project、message、invoice、subscription、file、comment。每个名词都是候选实体。
然后为每个实体补充一句话回答:它是什么,为什么存在?例如:“Project 是用户用来分组工作并邀请他人的工作空间。”这可以避免出现模糊的表名如 data、items 或 misc。
归属是下一个重要决策,会影响几乎每个查询。对每个实体决定:
再决定如何标识记录。UUIDs 在记录可能由多种途径创建(web、mobile、后台任务)或你不想要可预测 ID 时很有用。bigint 更小更快。如果你需要面向人的标识符,单独保留一个字段(例如在账户内唯一的短 project_code),不要把它强制做主键。
最后,在画图前用句子写出关系:user has many projects,project has many messages,users can belong to many projects。把每条连接标记为必需或可选,例如 “message 必须属于 project” vs “invoice 可能属于 project”。这些句子将在生成代码时成为事实依据。
当实体用通俗语言足够清楚后,把每个实体变成一个表,列出匹配需要存储的真实字段。
从可以坚持的命名和类型开始。选定一致的模式:snake_case 的列名、相同概念使用相同类型、可预测的主键。时间戳推荐使用 timestamptz,以免时区问题惊扰你。金额使用 numeric(12,2)(或以分为整数存储),不要用浮点数。
对于状态字段,使用 Postgres 枚举或 text 列加上 CHECK 约束来控制允许的值。
通过把规则翻译成 NOT NULL 来决定哪些字段是必需的。如果一个值对该行的存在是必要的,就设为必需;如果真的是未知或不适用,就允许为 null。
一个实用的默认列集合:
id(uuid 或 bigint,选一种并保持一致)created_at 和 updated_atdeleted_atcreated_by多对多关系几乎总是应该变成连接表。例如,如果多个用户可以协作一个应用,创建 app_members,包含 app_id 和 user_id,并在两列上强制唯一性以防止重复。
提前考虑历史记录。如果你知道需要版本控制,规划一个不可变表,例如 app_snapshots,每行是保存的版本,通过 app_id 关联到 apps,并带上 created_at。
约束是模式的护栏。决定哪些规则必须在任何服务、脚本或管理工具操作数据库时都成立。
从身份和关系开始。每个表都需要主键,任何 “belongs to” 的字段都应该是真正的外键,而不是你希望能匹配的整数。
然后添加在重复会造成真实损害的唯一性约束,比如两个账户有相同 email,或 (order_id, product_id) 重复的行项。
值得早期规划的高价值约束:
amount >= 0、status IN ('draft','paid','canceled') 或 rating BETWEEN 1 AND 5。级联行为是规划最能节省后期工时的地方。问一问人们实际上希望发生什么。如果删除客户会导致订单消失,通常应该使用 restrict 删除并保留历史。对于像订单行项这样的依赖数据,从订单到行项使用 cascade 可以合理,因为行项离开父记录就没有意义。
当你生成模型和端点时,这些约束会变成明确的需求:哪些错误需要处理、哪些字段是必需的、以及哪些边界情况从设计上就是不可能发生的。
索引应该回答一个问题:哪些操作需要对真实用户来说是快速的。
从你预计先发布的页面和 API 调用开始。一个按状态过滤并按最新排序的列表页面,与加载关联记录的详情页所需不同。
在选择索引前,用通俗语言写下 5 到 10 个查询模式。例如:“显示我最近 30 天的发票,按已付/未付过滤,按 created_at 排序”,或“打开项目并按 due_date 列出其任务”。这能让索引选择基于真实使用场景。
一个好的首批索引通常包括用于连接的外键列、常见的过滤列(如 status、user_id、created_at),以及一两个用于稳定多条件查询的复合索引,例如当你总是按 account_id 过滤然后按时间排序时,用 (account_id, created_at)。
复合索引的顺序很重要。把你更常用且更具区分度的过滤列放在前面。如果你每次请求都按 tenant_id 过滤,它通常应该位于很多索引的最前面。
避免“以防万一”而把每列都索引。每个索引都会在 INSERT 和 UPDATE 时增加额外工作,有时这比偶尔的慢查询更有害。
对文本搜索要单独规划。如果只需要简单的“包含”匹配,ILIKE 可能起初足够。如果搜索是核心需求,就早期规划全文搜索(tsvector),以免之后不得不重设计。
模式在创建第一批表后并不是“完成”的。每次你添加功能、修复错误或对数据有新认识时,都会变更模式。如果你提前决定迁移策略,就可以避免在代码生成后痛苦的重写。
保持一个简单规则:以小步改动数据库,每次只做一项功能。每个迁移都应该易于审查并能在每个环境安全运行。
大多数破坏来自重命名或删除列,或更改类型。不要一次性把所有事情做完,而是规划一条安全路径:
这需要更多步骤,但在实际中更快,因为它减少了宕机和紧急修复。
种子数据也是迁移的一部分。决定哪些参考表是“必须存在”的(roles、statuses、countries、plan types),并把这些插入和更新放在专门的迁移中,以便每个开发者和每次部署都得到相同结果。
及早设定期望:
回滚并不总是完美的 “down migration”。有时最好的回滚是恢复备份。如果你使用 Koder.ai,也值得决定在执行高风险更改前何时依赖快照与回滚,特别是在风险操作之前。
先规划 schema。它设定了一个稳定的数据契约(表、键、约束),这样生成的模型和端点就不需要不断重命名和重写。
实践建议:写下实体、关系和核心查询,然后在生成代码前确定约束、索引和迁移。
写 2–3 句描述应用必须记住的内容以及用户必须能做的事情。
然后列出:
这会给你足够的清晰度去设计表,而不会过度建模。
从你经常重复的名词开始列举(user、project、invoice、task)。对每个实体写一句话:它是什么,为什么存在。
如果你无法清楚描述它,你很可能会得到诸如 items 或 misc 这样模糊的表,后面会后悔。
在整个 schema 中保持一个一致的 ID 策略。
UUIDs:适合记录可能来自很多地方(web、mobile、后台任务)或不希望 ID 可预测的场景bigint:体积更小、性能略好,适合所有记录由服务器创建的情况如果需要面向人的可读标识符,单独增加一个唯一列(例如 project_code),不要把它当作主键。
按关系决定,基于用户预期和需要保留的数据。
常见默认:
RESTRICT/NO ACTION(例如 customer → orders)CASCADE(例如 order → line items)早点做出决定,因为这会影响 API 行为和边界情况。
把永久性规则放进数据库,这样所有写入者(API、脚本、导入、管理工具)都会遵守。
优先考虑:
从真实查询模式出发,而不是凭空猜测。
写下 5–10 个用例(过滤 + 排序),然后为这些用例建立索引:
status、user_id、created_at(account_id, created_at))避免把所有列都索引;每个索引都会增加 INSERT/UPDATE 的开销。
把多对多关系建成连接表,包含两列外键并加上复合唯一约束。
示例模式:
team_members(team_id, user_id, role, joined_at)UNIQUE (team_id, user_id) 防止重复这能避免“为什么这个用户出现两次”这类隐蔽的错误,并让查询更清晰。
默认设置:
timestamptz(避免时区问题)numeric(12,2) 或以分为单位的整数(避免浮点数)CHECK 约束来强制执行在表之间对相同概念保持一致的类型,这样连接和校验更可预测。
使用小而可审查的迁移,避免一次性破坏性更改。
安全流程示例:
还要提前决定如何处理种子/参考数据,确保每个环境一致。
PRIMARY KEYFOREIGN KEYUNIQUE(如 email,或 join 表上的 (team_id, user_id))CHECK(非负金额、允许的状态等)NOT NULL