2025年9月02日·2 分钟
API 中的 Protobuf 与 JSON:速度、大小与兼容性
比较 API 中的 Protobuf 与 JSON:有效载荷大小、速度、可读性、工具链、版本演进,以及在真实产品中各自最适合的场景。
比较 API 中的 Protobuf 与 JSON:有效载荷大小、速度、可读性、工具链、版本演进,以及在真实产品中各自最适合的场景。
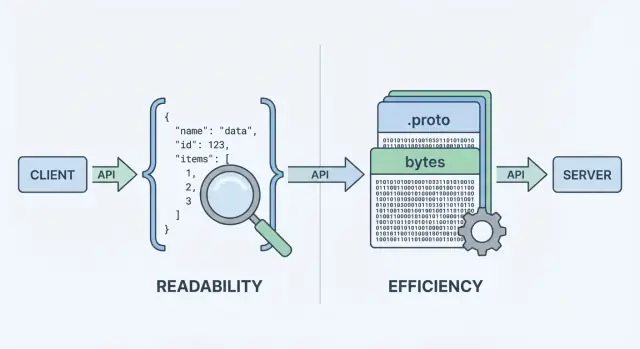
当你的 API 发送或接收数据时,需要一种数据格式——在请求和响应体中表示信息的标准化方式。该格式会被序列化(转换成字节)以在网络上传输,然后在客户端和服务器端反序列化回可用的对象。
两种常见选择是 JSON 和 Protocol Buffers(Protobuf)。它们都能表示相同的业务数据(用户、订单、时间戳、项目列表),但在性能、有线大小和开发工作流上做出不同的权衡。
JSON(JavaScript Object Notation) 是一种基于文本的格式,由对象和数组等简单结构构成。它在 REST API 中很流行,因为易于阅读、易于记录,并且可以使用 curl 和浏览器 DevTools 等工具方便地检查。
JSON 普及的一个重要原因是:大多数语言都有良好支持,你可以直观地查看响应并立即理解内容。
Protobuf 是 Google 创建的一种二进制序列化格式。它不是发送文本,而是根据 模式(.proto 文件)发送紧凑的二进制表示。模式描述字段、类型和数值标签。
由于是二进制且由模式驱动,Protobuf 通常会产生更小的有效载荷并且解析更快——这在高请求量、移动网络或对延迟敏感的服务中很重要(常见于 gRPC,但不限于 gRPC)。
将你发送的内容(是什么)与如何编码(如何发送)区分开很重要。一个包含 id、name 和 email 的“用户”可以用 JSON 或 Protobuf 建模。不同的是你为此付出的代价,体现在:
没有放之四海皆准的答案。对于许多面向公共的 API,JSON 仍是默认选择,因为它更易访问、更灵活。对于内部服务间通信、性能敏感系统或需要严格契约的场景,Protobuf 往往更合适。本指南旨在帮助你基于约束做决定,而非基于意识形态。
当 API 返回数据时,它不能直接在网络上发送“对象”。必须先把它们转换为字节流。这个转换就是序列化——可以把它想象成将数据“打包”成可传输的形式。另一端,客户端做相反的操作(反序列化),将字节“解包”回可用的数据结构。
典型的请求/响应流程如下:
在“编码步骤”上,格式选择就会显现差异。JSON 编码会产生可读文本,例如 {\"id\":123,\"name\":\"Ava\"};Protobuf 编码则产生紧凑的二进制字节,没有工具无法直接读取其含义。
因为每个响应都必须被打包与解包,格式会影响:
你的 API 风格常常会促使你倾向某种选择:
curl 测试并便于记录与检查。你当然可以在 gRPC 中使用 JSON(通过转码),也可以在普通 HTTP 上传输 Protobuf,但栈的默认可用性——框架、网关、客户端库与调试习惯——通常会决定日常运维的便利性。
当人们比较 protobuf vs json 时,通常先看两个指标:有效载荷大小和编码/解码所需的时间。结论很直接:JSON 是文本,往往冗长;Protobuf 是二进制,往往更紧凑。
JSON 会重复字段名并以文本形式表示数字、布尔与结构,因此通常在传输中占用更多字节。Protobuf 使用数字标签并高效打包值,常常导致明显更小的有效载荷——尤其是对于大对象、重复字段和深度嵌套的数据。
不过,压缩会缩小差距。启用 gzip 或 brotli 时,JSON 的重复键会非常容易被压缩,因此“JSON vs Protobuf 的大小差异”在真实部署中可能变小。Protobuf 也可以压缩,但相对收益往往更小。
JSON 解析器需要分词并验证文本、将字符串转换为数字,并处理边界情况(转义、空白、Unicode)。Protobuf 解码更直接:读取标签 → 读取类型化值。在许多服务中,Protobuf 能减少 CPU 时长与垃圾产生,从而在高负载下改善尾延迟。
在移动网络或高延迟链路上,更少的字节通常意味着更快的传输和更少的无线电打开时间(这也有助于省电)。但如果响应已经很小,握手开销、TLS 与服务器处理可能占主导——此时格式选择的可见性会变小。
用你的真实有效载荷来测量:
这会把“序列化争论”变成你可以信赖的数据。
在开发者体验方面,JSON 往往默认占优。你几乎可以在任何地方检查 JSON 请求或响应:浏览器 DevTools、curl 输出、Postman、反向代理和纯文本日志。当出问题时,“我们到底发送了什么?”通常只需复制粘贴一下即可。
Protobuf 则不同:它紧凑且严格,但不可人读。如果你记录原始的 Protobuf 字节,你会看到 base64 或不可读的二进制。要理解有效载荷,你需要正确的 .proto 模式和解码器(例如 protoc、特定语言的工具链或服务生成的类型)。
使用 JSON 时,复现问题很直接:抓取日志中的有效载荷、脱敏后用 curl 重放,通常就能得到最小测试用例。
使用 Protobuf 时,你通常需要:
这一步并不复杂,但前提是团队有可复现的工作流。
结构化日志对两种格式都有帮助。记录请求 ID、方法名、用户/账户标识和关键字段,而不是完整的请求体。
针对 Protobuf:
.proto?”的困惑。针对 JSON,考虑记录规范化的 JSON(稳定键顺序),以便更容易比较差异和查看事件时间线。
API 不只是移动数据——它们还传递语义。JSON 与 Protobuf 最大的区别在于对这些语义的定义与强制程度。
JSON 默认是“无模式”的:你可以发送任意对象与字段,只要看起来合理,许多客户端就会接受。
这种灵活性在早期很方便,但也会隐藏错误。常见问题包括:
userId,另一个响应中叫 user_id,或者不同代码路径漏发字段。"42"、"true" 或 "2025-12-23",易产生混淆。null 可能代表“未知”、“未设置”或“刻意为空”,不同客户端可能有不同处理方式。你可以为 JSON 添加 JSON Schema 或 OpenAPI 规范,但 JSON 本身并不强制消费者遵循它们。
Protobuf 要求在 .proto 文件中定义模式。该模式声明:
该契约有助于防止意外变更——比如把整数改成字符串——因为生成的代码期望特定类型。
在 Protobuf 中,数字保持为数字、枚举被限制在已知值范围,时间戳通常使用约定的类型表示(而不是随意字符串)。在 proto3 中,当你使用 optional 字段或包装类型时,“未设置”与默认值也能明确区分。
如果你的 API 需要精确类型和多语言间一致解析,Protobuf 提供了 JSON 通常需要约定才能达到的约束。
API 会演进:你会添加字段、调整行为、淘汰旧部分。目标是在不让消费者惊讶的情况下改变契约。
好的演进策略通常追求两者,但向后兼容通常是最低门槛。
在 Protobuf 中,每个字段都有一个编号(例如 email = 3)。编号,而不是字段名,是在线上编码时的身份标识。字段名主要用于人工与生成代码。
因此:
通常安全的变更
风险变更(通常会破坏兼容性)
最佳实践:对已移除的编号/名称使用 reserved 并保留变更日志。
JSON 没有内建模式,兼容性依赖于你的模式与实践:
提前文档化废弃计划:某字段被废弃时将支持多久、替代方案是什么。发布一个简单的版本策略(例如“增量更改为非破坏性,删除需要新主版本”)并遵守它。
在 JSON 与 Protobuf 之间选择,常常取决于你的 API 要运行在哪些环境——以及团队愿意维护什么。
JSON 几乎是通用的:每个浏览器和后端运行时都能解析它而无需额外依赖。在 Web 应用中,fetch() + JSON.parse() 是常规路径,代理、API 网关和可观测性工具也往往开箱理解 JSON。
Protobuf 也能在浏览器运行,但不是零成本默认。你通常需添加 Protobuf 库(或生成的 JS/TS 代码)、管理打包体积,并决定是否在浏览器端发送 Protobuf 以保持可检查性。
在 iOS/Android 以及后端语言(Go、Java、Kotlin、C#、Python 等)中,Protobuf 支持成熟。Protobuf 假设你会为每个平台使用相应库并通常从 .proto 文件生成代码。
代码生成带来的好处包括:
但也增加了成本:
.proto 包、版本固定)。Protobuf 与 gRPC 紧密相关,后者为你提供完整的工具链:服务定义、客户端存根、流式能力和拦截器。如果你在考虑 gRPC,Protobuf 是天然匹配。
如果你在构建传统的 JSON REST API,JSON 的工具生态(浏览器 DevTools、curl 友好调试、通用网关)仍然更简单——尤其是面向公共 API 与快速集成时。
如果你还在探索 API 面,原型化两种风格分别试验会很有帮助。例如,一些团队会快速搭建一个 JSON REST API 以获得广泛兼容,同时为内部服务使用 gRPC/Protobuf 来提高效率,再用真实有效载荷进行基准测试之后再确定默认方案。
(保留提及:Koder.ai 提供生成全栈应用的能力,并支持在不同平台上迭代契约,这类工具可帮助在不做大规模重构的情况下对比格式。)
选择 JSON 还是 Protobuf 不仅关乎有效载荷大小或速度,还影响 API 与缓存层、网关以及团队在事故期间依赖的工具的契合度。
大多数 HTTP 缓存(浏览器缓存、反向代理、CDN)是基于 HTTP 语义优化的,而不是针对某种主体格式。只要响应是可缓存的,CDN 可以缓存任何字节。
然而,许多团队习惯在边缘看到 HTTP/JSON,因为它易于检查和排障。使用 Protobuf 时缓存仍然可行,但需注意:
Vary)Cache-Control、ETag、Last-Modified)如果同时支持 JSON 与 Protobuf,请使用内容协商:
Accept: application/json 或 Accept: application/x-protobufContent-Type 响应确保缓存理解这一点:设置 Vary: Accept,否则缓存可能储存 JSON 响应并错误地返回给期待 Protobuf 的客户端(或反之)。
API 网关、WAF、请求/响应转换器和可观测性工具常常假设请求体为 JSON,用于:
二进制 Protobuf 会限制这些功能,除非你的工具支持 Protobuf(或你增加解码步骤)。
常见模式是 边缘使用 JSON,内部使用 Protobuf:
这既简化了外部集成,又能在可控环境中利用 Protobuf 的性能优势。
选择 JSON 或 Protobuf 会改变数据的编码与解析方式——但它不替代身份验证、加密、授权与服务端校验等核心安全需求。一个快速的序列化库并不能弥补接受不受信任输入而缺乏限制的 API。
把 Protobuf 当作“更安全因为不可读”是一种错误观念。攻击者不需要你的有效载荷对人类可读来发起攻击;他们只需访问你的端点。如果 API 泄露敏感字段、接受无效状态或授权薄弱,换格式不能解决问题。
无论选择哪种序列化,都应使用 TLS 加密传输,强制授权检查,验证输入并安全记录日志。
两种格式共享常见风险:
为了在负载与滥用下保持 API 可用,请给两种格式都应用相同的防护措施:
结论:"二进制 vs 文本格式"主要影响性能与易用性。安全与可靠性来自一致的限制、及时更新的依赖和明确的校验——而不是格式本身。
在 JSON 与 Protobuf 之间抉择,更在于你希望优化什么:面向人类与易用性,还是效率与严格契约。
当你需要广泛兼容与容易排查时,JSON 通常是最安全的默认:
典型场景包括:
当性能与一致性比人类可读性更重要时,Protobuf 更有优势:
典型场景包括:
可以用这些问题快速判断:
如果无法抉择,“边缘 JSON、内部 Protobuf”常是务实的折中方案。
格式迁移不是重写整个系统,而是减少对消费者的风险。最安全的做法是在迁移期间保持 API 可用并能回滚。
选择低风险的表面区域——通常是内网服务调用或单个只读端点。这样可以验证 Protobuf 模式、生成客户端与可观测性改动,而不把整个 API 变为一次性大工程。
一个实用的第一步是为现有资源添加 Protobuf 表示,同时保持 JSON 形状不变。你会快速发现数据模型的歧义(null 与 missing、数字与字符串、日期格式),并能在模式中加以解决。
对外部 API 来说,双格式支持通常是最平滑的路径:
Content-Type 和 Accept 协商格式;/v2/...)。在此期间,确保两种格式都从相同的单一事实来源(source-of-truth)生成,以避免细微的漂移。
计划好:
发布 .proto 文件、字段注释和具体的请求/响应示例(JSON 与 Protobuf),以便消费者确认他们对数据的理解是否一致。简短的“迁移指南”和变更日志能减少支持成本并加速采用。
JSON 是一种基于文本的格式,便于阅读、记录和用常见工具测试。Protobuf 是由 .proto 模式定义的紧凑二进制格式,通常能产生更小的有效载荷并加快解析速度。
根据约束来选择:可达性与可调试性优先选择 JSON;效率与严格契约优先选择 Protobuf。
API 传输的是字节,而不是内存对象。序列化 是将服务器对象编码为可传输的有效载荷(JSON 文本或 Protobuf 二进制);反序列化 则是将这些字节解码回客户端/服务器的对象。
你选择的格式会影响带宽、延迟和用于编码/解码的 CPU 资源。
通常是。对于大对象、重复字段或深度嵌套的数据,Protobuf 使用数字标签和高效的二进制编码,往往比 JSON 更紧凑。
不过,如果启用 gzip 或 brotli,JSON 中重复字段名会被很好地压缩,因此在实际部署中两者的大小差距可能会缩小。建议同时比较原始和压缩后的大小。
有可能。JSON 解析需要对文本进行分词、处理转义/Unicode,并将字符串转换为数字;Protobuf 解码更直接(读取标签 → 读取类型化值),因此常能减少 CPU 时间和内存分配。
但如果有效载荷非常小,整体延迟可能更多由 TLS、网络 RTT 及应用处理时间主导,而非序列化开销。
默认情况下更难。JSON 是人可读的,便于在 DevTools、日志、curl 和 Postman 中直接查看。Protobuf 是二进制的,通常需要配套的 .proto 模式和解码工具。
常见的改进做法是同时记录一个解码后且已脱敏的调试视图(通常用 JSON 表示),并在日志中保留 request id 与关键字段。
JSON 默认是“无模式”的,除非你强制使用 JSON Schema/OpenAPI。这种灵活性会导致字段不一致、“字符串化”数据(例如把数字或布尔当作字符串)、以及 null 语义不明确等问题。
Protobuf 通过 .proto 合约强制类型:数字就是数字,枚举受限于已知取值,时间戳常用约定类型表示。使用 Protobuf 时不同团队/语言之间保持一致性更容易。
Protobuf 的兼容性由**字段号(tag)**驱动。安全的变更通常是添加新的可选字段并使用全新的编号;破坏性变更包括重用旧字段号、以不兼容的类型替换字段、或移除字段而不保留编号。
最佳实践:对已移除的编号/名称使用 reserved,并保持变更日志。
JSON 则依赖惯例:尽量做增量变更,避免改变字段类型,必要时引入新字段名来替代旧字段。
可以。使用 HTTP 内容协商:
Accept: application/json 或 Accept: application/x-protobufContent-Type同时设置 Vary: Accept,避免缓存层混淆不同格式的响应。如果工具链不方便协商,临时也可以提供单独的端点(例如 /v2/...)来过渡。
视环境而定:
选择 Protobuf 时,还要考虑代码生成、CI 中的生成步骤和共享 .proto 版本管理的维护成本。
格式本身不是安全层。把 Protobuf 当成“更安全因为不可读”是一种误解。攻击者不需要人类可读的数据来发起攻击。
通用的防护措施对两种格式都适用: