2025年10月05日·2 分钟
RabbitMQ 在应用中的实战:模式、部署与运维
学习如何在应用中使用 RabbitMQ:核心概念、常见模式、可靠性技巧、扩展、安全和生产监控。
学习如何在应用中使用 RabbitMQ:核心概念、常见模式、可靠性技巧、扩展、安全和生产监控。
RabbitMQ 是一个消息代理:它位于系统各部分之间,可靠地把“工作”(消息)从生产者传递到消费者。当直接的同步调用(服务间 HTTP、共享数据库、定时任务)开始造成脆弱的依赖、不均衡的负载和难以排查的故障链时,应用团队通常会采用它。
流量突增与不均匀的工作负载。 如果你的应用在短时间内收到 10 倍的注册或订单,立即处理所有请求会压垮下游服务。有了 RabbitMQ,生产者可以快速将任务入队,消费者按受控速度逐条处理。
服务之间的强耦合。 当服务 A 必须调用服务 B 并等待时,故障和延迟会蔓延。消息化可以将它们解耦:A 发布消息后继续运行;B 在可用时消费并处理它。
更安全的失败处理。 并非所有失败都应该直接展示给用户。RabbitMQ 帮助你在后台重试、隔离“毒性”消息,并在临时故障时避免丢失工作。
团队通常会得到更平滑的负载(缓冲峰值)、解耦的服务(运行时依赖更少)以及受控的重试(减少人工重处理)。同样重要的是,更容易判断工作卡在哪里——在生产者、队列还是消费者。
本指南侧重于面向应用团队的实用 RabbitMQ:核心概念、常见模式(pub/sub、工作队列、重试与死信队列),以及运维关切(安全、扩容、可观测性、故障排查)。
它不旨在替代完整的 AMQP 规范或详尽介绍每个 RabbitMQ 插件。目标是帮助你设计在真实系统中可维护的消息流。
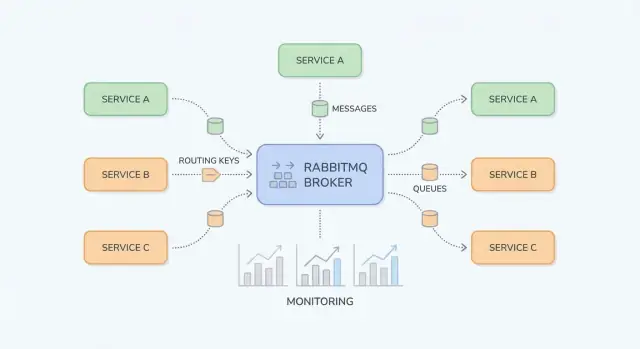
RabbitMQ 是一个在系统各部分间路由消息的消息代理,使得生产者可以移交工作,消费者可以在准备好时处理它。
通过直接 HTTP 调用,服务 A 向服务 B 发送请求并通常等待响应。如果服务 B 变慢或不可用,服务 A 要么失败要么阻塞,你必须在每个调用方中处理超时、重试和背压。\n\n使用 RabbitMQ(通常通过 AMQP),服务 A 将消息发布到代理。RabbitMQ 存储并路由它到合适的队列,服务 B 异步消费。关键的变化是你通过一个持久化的中间层通信,它能缓冲突发并平滑不均匀的负载。
消息化适合的情况:\n\n- 想要解耦团队/服务,使其能独立部署与扩展。\n- 需要异步工作(发送邮件、生成 PDF、运行风控)而不阻塞用户请求。\n- 预期突发流量并希望用队列吸收峰值。\n- 需要带确认、重试和死信队列的可靠投递。\n\n不适合的情况:\n\n- 真正需要即时答案来响应请求(例如“这个密码有效吗?”)。\n- 只是做简单的同步读取,直接调用更清晰、更易调试。\n- 没有计划处理消息版本化、重试和监控(你只会把复杂性转移而非减少)。
同步(HTTP):\n\n结账服务调用开票服务的 HTTP:"Create invoice"。用户等待开票完成。如果开票慢,结账延迟增加;如果开票不可用,结账失败。\n\n异步(RabbitMQ):\n\n结账发布 invoice.requested(包含订单 id)。用户立即收到已接收订单的确认。开票服务消费该消息,生成发票,然后发布 invoice.created,供邮件/通知服务消费。每一步都可以独立重试,临时故障不会自动打断整个流程。
把“消息从哪里发布”和“消息在哪里存储”分开会让 RabbitMQ 更易理解。生产者发布到 exchange;exchange 将消息路由到 queue;消费者从队列读取。
exchange 不存储消息。它根据规则把消息转发到一个或多个队列。\n\n- Direct exchange(直连交换器):按路由键的精确匹配路由。用于需要明确目标的场景(例如 billing 或 email)。\n- Topic exchange(主题交换器):基于路由键中的模式路由。用于灵活的 pub/sub 和“订阅某个类别”。\n- Fanout exchange(广播交换器):忽略路由键,广播到所有绑定队列。用于每个消费者都应收到每条事件的场景(例如缓存失效)。\n- Headers exchange(头交换器):基于消息头而非路由键路由。用于路由依赖多个属性的特殊情况(例如 region=eu 且 tier=premium),但要谨慎使用,因为它更难以推理。
队列(queue) 是消息停留直到消费者处理它的地方。队列可以被单个消费者或多个消费者(竞争消费者)消费,消息通常一次投递给一个消费者。\n\n绑定(binding) 将交换器与队列连接并定义路由规则。可以把它理解为:“当消息到达交换器 X 且路由键为 Y 时,投递到队列 Q。”你可以把多个队列绑定到同一交换器(实现 pub/sub),也可以为不同路由键多次绑定同一队列。
对于直连交换器,路由要求精确匹配。对于主题交换器,路由键是点分词的形式,例如:\n\n- orders.created\n- orders.eu.refunded\n\n绑定可以包含通配符:\n\n- * 匹配恰好一个词(例如 orders.* 匹配 orders.created)\n- # 匹配零个或多个词(例如 orders.# 匹配 orders.created 和 orders.eu.refunded)\n\n这让你在不改动生产者的情况下添加新消费者——只需创建新队列并用所需模式绑定即可。
RabbitMQ 将消息投递给消费者后,消费者需报告结果:\n\n- ack:"处理成功"。RabbitMQ 从队列中移除消息。\n- nack(或 reject):"处理失败"。可以选择丢弃或重新入队。\n- requeue:将消息放回队列,等待再次尝试(通常是立即)。\n\n对 requeue 要小心:一直失败的消息会无限循环并阻塞队列。许多团队将 nack 与重试策略和死信队列配合使用,以便可预测地处理失败(后文有详细说明)。
当你需要在系统各部分间传递工作或通知,而不希望所有步骤都阻塞在单个慢步骤时,RabbitMQ 就很适合。下面是日常产品中常见的实用模式。
当多个消费者需要对同一事件做出反应,而发布者不知道它们是谁时,发布/订阅是干净的选择。\n\n示例:当用户更新资料时,你可能需要并行通知搜索索引、分析系统和 CRM 同步。用 fanout 交换器则广播到所有绑定队列;用 topic 交换器可以按选择路由(例如 user.updated、user.deleted)。这避免了服务间的紧耦合,并允许团队在不改动生产者的情况下添加新订阅者。
如果某项任务耗时较长,把它推到队列并由 worker 异步处理:\n\n- 图像/视频处理\n- 发送事务性邮件\n- 生成 PDF 或报表\n- 导入/导出数据\n\n这让 Web 请求更快,同时可以独立扩展 worker。队列自然成为你的“待办列表”,worker 数量即为你的“吞吐调节钮”。
很多工作流跨越多个服务:经典例子是 order → billing → shipping。与其让一个服务调用下一个并阻塞,不如每个服务在完成其步骤后发布事件,下游服务消费这些事件并继续流程。\n\n这增强了弹性(shipping 的短暂故障不会破坏 checkout),并使职责更清晰:每个服务仅响应其关心的事件。
RabbitMQ 也可以作为应用与慢或不稳定依赖(第三方 API、遗留系统、批处理数据库)之间的缓冲区。你可以快速入队请求,然后以受控的重试频率处理它们。如果依赖不可用,工作会安全积压等待稍后排空——而不是造成整个应用的超时。
如果你打算逐步引入队列,一个小型的“异步 outbox”或单一后台作业队列通常是好的第一步(参见 /blog/next-steps-rollout-plan)。
当路由可预测、命名一致并且载荷演进不会破坏旧消费者时,RabbitMQ 的使用体验才会愉快。在添加新队列之前,先确保消息的“故事”清晰:它从何处产生,如何路由,团队成员如何端到端地调试它。
事先选对交换器可以减少零散的绑定和意外的广播:\n\n- Direct exchange:当路由键映射到特定队列时最佳(例如 billing.invoice.created)。\n- Topic exchange:当需要按模式灵活订阅时最佳(例如 billing.*.created、*.invoice.*)。这是事件式路由中最常用的选择。\n- Fanout exchange:当每个消费者都应接收每条消息时最佳(业务事件中罕见,广播类信号更常见)。\n\n经验法则:如果你在代码中“发明”复杂的路由逻辑,那它很可能属于 topic exchange 模式。
把消息体当作公共 API。使用显式的 版本控制(例如顶层字段 schema_version: 2),并力求 向后兼容:\n\n- 新增字段;不要重命名或删除字段。\n- 优先使用可选字段并提供安全默认值。\n- 若不可避免地要做破坏性变更,发布一个新消息类型/路由键,而不是悄悄修改旧格式。\n\n这样可以让旧消费者继续工作,新消费者按自己的节奏迁移。
通过标准化元数据让排查变便宜:\n\n- correlation_id:把属于同一业务动作的命令/事件串联起来。\n- trace_id(或 W3C traceparent):把消息与 HTTP 和异步流程中的分布式追踪关联。\n\n当每个发布者都一致设置这些字段时,你就能无歧义地跟踪单个事务跨多个服务的流转。
使用可预测、易检索的名字。一种常见模式:\n\n- 交换器:<domain>.<type>(例如 billing.events)\n- 路由键:<domain>.<entity>.<verb>(例如 billing.invoice.created)\n- 队列:<service>.<purpose>(例如 reporting.invoice_created.worker)\n\n一致性胜过聪明:未来的你(以及值班人员)会感谢这样的选择。
可靠消息传递主要是为故障设计:消费者崩溃、下游 API 超时、部分事件格式错误。RabbitMQ 提供工具,但应用代码需要配合。
常见做法是 至少一次投递:消息可能被多次投递,但不应被悄然丢失。通常发生在消费者接收到消息、开始处理但在 ack 前失败——RabbitMQ 会重新入队并再次投递。\n\n实践结论:重复是正常的,因此你的处理逻辑必须可重复执行(幂等)。
幂等性意味着“对同一条消息做两次处理的效果与做一次相同”。有用的方法包括:\n\n- 去重键(Dedupe keys):包含稳定的 message_id(或业务键如 order_id + event_type + version),并将其存入带 TTL 的“已处理”表/缓存。\n- 安全更新:使用条件写入(例如仅在状态仍为 PENDING 时更新)或数据库唯一约束防止重复创建。\n- Outbox/Inbox 模式:先持久化事件接收,然后再处理,这样重试不会重复执行副作用。
重试最好作为独立流处理,而不是消费者内部的紧密循环。常见模式:\n\n1. 在短暂失败时,拒绝并路由到带 TTL 的重试队列。\n2. 当 TTL 到期,消息通过 死信交换器(DLX) 被 dead-letter 回原队列。\n3. 通过 header(或在路由键中编码)跟踪尝试次数,并在达到上限后停止。\n\n这能实现退避机制,同时避免消息长期以 unacked 状态占用资源。
有些消息永远无法成功(格式坏、引用数据缺失或代码缺陷)。通过下列方式检测:\n\n- 达到最大重试次数\n- 在相同错误签名情况下反复失败\n\n将这些消息路由到 DLQ 进行隔离。把 DLQ 当作一个运维收件箱:检视载荷、修复根因,然后有选择地手动重放(最好通过受控的工具/脚本),而不是把所有消息一股脑放回主队列。
RabbitMQ 性能通常受限于少数实际因素:连接管理、消费者处理速度,以及队列是否被当作“存储”使用。目标是稳定吞吐而非无限积压。
常见错误是为每个发布者或消费者都建立新的 TCP 连接。连接比想象的要重(握手、心跳、TLS),所以应保持长连接并复用它们。\n\n使用 channels 在更少的连接上复用工作。经验法则:少量连接,多路复用通道(channels)。不过也不要盲目创建成千上万的通道——每个通道有开销,客户端库也可能有限制。建议为每个服务保持一个小型通道池并复用发布通道。
如果消费者一次拉取太多消息,会看到内存激增、处理时间变长和延迟不均。设置 prefetch(QoS),使每个消费者只持有受控数量的未 ack 消息。\n\n实用建议:\n\n- 对慢速任务(API 调用、文件处理),从每个消费者 prefetch 1–10 开始。\n- 对快速、轻量的处理器,逐步提高 prefetch,同时监控 ack 速率与主机资源。\n- 在大幅提高 prefetch 前,先通过增加消费者实例来扩容。
大消息会降低吞吐并增加内存压力(对发布者、代理和消费者均如此)。如果载荷较大(例如文档、图像或大型 JSON),考虑将其存储在对象存储或数据库中,仅通过 RabbitMQ 发送 ID + 元数据。\n\n一个良好启发式规则是:将消息保持在 KB 级别,而不是 MB 级别。
RabbitMQ 的安全主要集中在“边界”:客户端如何连接、谁能做什么、如何保护凭据。把下面的清单作为基线,并根据合规要求调整。
对于操作硬化(端口、防火墙与审计),准备一份简短的内部运行手册并在 /docs/security 中集中维护,便于团队遵循统一标准。
当 RabbitMQ 行为异常时,应用端通常会先出现症状:接口变慢、超时、更新缺失或作业“永远不完成”。良好的可观测性能帮你确认代理是否是根因、定位瓶颈(生产者/代理/消费者),并在用户察觉前采取行动。
代理日志能帮助你区分“RabbitMQ 宕机”与“客户端误用”。查看认证失败、阻塞连接(资源告警)和频繁的通道错误。在应用端,请确保每次处理尝试都记录 correlation_id、队列名和结果(acked、rejected、retried)。\n\n如果使用分布式追踪,请在消息属性中传播 trace 头,以便把“API 请求 → 发布消息 → 消费者工作”串联起来。
为关键流构建单页仪表盘:发布速率、ack 速率、深度、unacked、重投递与消费者数量。仪表盘中加入 /docs/monitoring 的运行手册链接和一个“值班首查项”清单,方便值班人员快速定位问题。
当某些东西“突然不动”时,先别急着重启。多数问题在检查(1)绑定与路由、(2)消费者健康、和(3)资源告警后就能显现。
如果发布端报告“发送成功”但队列为空(或错误的队列在增长),请先检查路由而不是代码。\n\n在 Management UI 中开始排查:\n\n- 验证 exchange 类型 并确认队列存在预期的 binding。\n- 确认生产者发布的 routing key 与绑定模式匹配(topic 时尤为常见问题)。\n- 确认是否在正确的 vhost 中发布。\n\n如果队列有消息但没人消费,确认:\n\n- 是否有消费者连接并订阅了正确的队列。\n- 消费者是否因 prefetch 设得太低/太高或被下游慢逻辑阻塞而卡住。\n- ack 是否发生(unacked 数增长通常意味着消费者未确认或过载)。
重复通常来自 重试(消费者在处理后崩溃导致未 ack)、网络中断或手动重新入队。通过在数据库中按消息 ID 去重可以缓解。\n\n当你有多个消费者或发生重新入队时,乱序交付是可预期的。如果需要按序处理,使用单消费者队列,或按键分区到多个队列。
告警表示 RabbitMQ 在自我保护:\n\n- 磁盘告警:释放磁盘空间、移动日志或扩容卷,然后确认告警清除。\n- 内存告警:减少 in-flight 消息(调小 prefetch、降低发布速率、清理队列),并检查是否有超大消息。
在重放前修复根因并防止“毒性消息”循环。以小批量重放、加入重试上限,并在元数据中标注尝试次数与最后错误。考虑先把重放的消息发到单独队列,这样如果同样错误重复出现可以快速停止。
选择消息工具不是看“谁最好”,而是看是否匹配你的流量模式、故障容忍度与运维熟悉度。
当你需要可靠的消息投递与灵活的路由时,RabbitMQ 很合适。它适合经典的异步工作流——命令、后台作业、广播通知与请求/响应模式,特别是当你需要:\n\n- 逐条消息确认与背压(慢消费者不会悄然丢失工作)\n- 丰富的路由能力(主题、头路由、直连),无需自行实现\n- 对许多团队而言运维上相对简单的扩展方式(增加消费者、调节 prefetch、管理队列)\n\n如果你的目标是移动工作而不是保留长久事件历史,RabbitMQ 往往是一个舒适的默认选择。
推广 RabbitMQ 最好把它当成一个产品来做:小范围开始、明确拥有者、在扩展前验证可靠性。
在实现这些模式的同时,考虑在团队间标准化脚手架。例如,使用 Koder.ai 的团队经常从一个聊天提示生成小型的生产者/消费者服务骨架(包括命名规范、重试/DLQ 配置和追踪/关联头),然后导出源代码供评审,并在“规划模式”下迭代以便推广。
当你想解耦服务、吸收流量突增,或把耗时工作移出请求路径时,使用 RabbitMQ。
适合的场景包括后台作业(发送邮件、生成 PDF)、向多个消费者分发事件通知,以及在下游短暂不可用时仍需继续处理的工作流。
不适合的场景是你真正需要立即响应(例如简单的校验或读取),或者你不能投入对版本控制、重试和监控的支持——在生产环境中这些并非可选项。
将消息发布到一个 exchange,再路由到 queue:
orders.* 或 orders.#)时,使用 topic exchange。region=eu 且 tier=premium)的特殊情况使用 headers exchange。多数团队默认选择 topic exchange 来实现可维护的事件式路由。
队列(queue)用于存放消息直到消费者处理;binding 是把 exchange 与 queue 连接起来的规则。
排查路由问题时:
这三项能解释大多数“发布了但没人消费”的情况。
当你希望多个 worker 竞争处理任务时,使用工作队列(work queue)。
实用设置建议:
prefetch,避免 worker 抢占过多未 ack 的消息。prefetch 调很高。“至少一次(at-least-once)”投递意味着消息可能会被投递多次(例如消费者在处理完成但还没 ack 前崩溃)。
处理重复的策略:
message_id(或业务键)并将已处理 ID 记录到带 TTL 的表/缓存中用于去重。PENDING 时更新)或数据库唯一约束来防止重复创建。把重复视为常态,并据此设计处理逻辑。
避免在消费者内部做紧密循环的重试。常见模式是“重试队列 + DLQ”:
仅在修复根因后,按小批量并受控地从 DLQ 回放消息。
把消息体当作公开 API 来对待:
schema_version。同时统一元数据:
关注能反映工作流是否通畅的关键信号:
报警应基于趋势(例如“backlog 持续增长 10 分钟”)而不是单点阈值。同时在日志中包含队列名、correlation_id 和处理结果(acked/retried/rejected),以便排查。
做到以下基本安全措施:
把这些内容写成简短的内部运行手册并集中链接(例如 /docs/security),方便团队遵循统一标准。
先定位消息流停止的位置:
prefetch 是否合适,以及 unacked 数是否在增长。通常重启不是第一选择,先看日志和绑定/消费者状态会更有用。
correlation_id 把属于同一业务动作的命令/事件串联起来。trace_id(或 W3C traceparent)把异步消息与分布式追踪关联。这些做法能显著降低后续维护和排障成本。