2025年6月15日·2 分钟
让 AI 设计后端模式、API 与数据模型
探索 AI 生成的 schema 与 API 如何加速交付、在哪些方面失灵,以及一套实用的复审、测试与治理工作流。
探索 AI 生成的 schema 与 API 如何加速交付、在哪些方面失灵,以及一套实用的复审、测试与治理工作流。
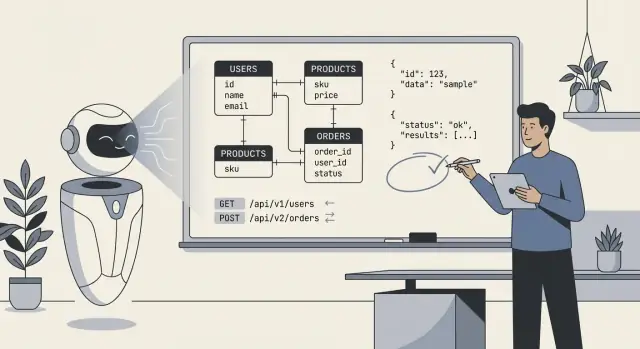
当人们说“AI 设计了我们的后端”时,通常指模型生成了核心技术蓝图的第一个草稿:数据库表(或集合)、这些部分如何关联,以及用于读写数据的 API。实际上,这更像是“AI 提出了一个可实现并可改进的结构”,而不是“AI 完全构建了一切”。
至少,AI 能生成:
users、orders、subscriptions 这样的表/集合,以及字段和基本类型。AI 能推断“典型”模式,但当需求模糊或具有领域特性时,它不能可靠地选择正确模型。它不会知道你的真实策略,例如:
cancelled 与 refunded 与 voided 的差别)。把 AI 输出看作快速、结构化的起点——在探索选项和发现遗漏时很有用——但不要把它当成可以直接发布的规范。你的职责是提供清晰的规则和边缘情况,然后像审查初级工程师的第一版草稿那样审查 AI 的产出:有帮助、偶尔令人印象深刻、有时在细节上含糊甚至错误。
AI 可以快速起草 schema 或 API,但它不能凭空发明让后端“契合”你的产品的缺失事实。最佳结果发生在你把 AI 当作一个高速的初级设计师:你提供清晰约束,它提出选项。
在请求表格、端点或模型之前,把要点写清楚:
当需求模糊时,AI 往往会“猜”默认值:到处都是可选字段、通用的状态列、不明确的所有权和不一致的命名。这常常导致看起来合理但在真实使用下崩溃的 schema —— 尤其在权限、报表和边缘场景(退款、取消、部分发货、多步审批)方面。后续你将为此付出迁移、权宜之计和混乱 API 的代价。
把下面作为起点,粘到你的 prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
把 AI 当作一个快速起稿的机器,它可以在几分钟内勾勒出合理的第一版数据模型及匹配的端点。这种速度改变了你的工作方式——不是因为输出“天然正确”,而是因为你能立刻在具体事物上迭代。
最大的收益是消除冷启动。给 AI 简短的实体描述、关键用户流与约束,它就能提出表/集合、关系和基础 API 表面。这在需要快速演示或探索不稳定需求时尤其有价值。
速度在以下场景回报最大:
人会累而偏离,AI 不会——所以它很适合在整个后端重复约定:
createdAt, updatedAt, customerId)/resources, /resources/:id)和载荷这种一致性让后端更易于文档化、测试与移交。
如果你要求完整的 CRUD 加常见操作(搜索、列表、批量更新),AI 通常会生成比匆忙的人类草稿更全面的起始表面。一项常见的快速胜利是标准化错误:统一的错误信封(code、message、details)。即便后面调整,有一个统一形状能防止杂乱的响应风格。
关键心态:让 AI 快速产出前 80%,把时间花在需要判断的那 20%:业务规则、边缘情况和模型背后的“为什么”。
AI 生成的 schema 初看“干净”:整齐的表、合理的命名、与幸福路径相匹配的关系。问题通常在真实数据、真实用户和真实工作流冲击系统时显现。
AI 容易在两端摇摆:
一个快速的味觉测试:如果你的常见页面需要 6 次以上 join,可能过度规范化;如果更新需要在许多行修改同一值,可能欠规范化。
AI 常常省略那些推动真实后端设计的“无聊”需求:
tenant_id,或在唯一约束中未强制租户范围。deleted_at,但未更新唯一性规则或查询模式以排除已删除记录。created_by/updated_by、变更历史或不可变事件日志。date 与 timestamp 而无明确规则(UTC 存储 vs 本地显示),导致日期偏差错误。AI 可能会猜测:
invoice_number)。这些错误常以尴尬的迁移和应用端的变通方式暴露出来。
大多数生成的 schema 没有反映你的查询方式:
tenant_id + created_at)如果模型不能描述应用会运行的前 5 个查询,它就无法可靠地为这些查询设计 schema。
AI 在生成看起来“标准”的 API 时往往表现不错,它会模仿流行框架和公共 API 的模式,这是显著省时的地方。风险在于它可能优化“看起来合理”而非“对你产品、数据模型与未来演进正确”。
资源建模基础。 在域清晰时,AI 倾向于选择合理的名词和 URL 结构(例如 /customers, /orders/{id}, /orders/{id}/items),并在端点命名上保持一致。
常见端点脚手架。 AI 常包含必要内容:列表与详情端点、创建/更新/删除操作,以及可预测的请求/响应形状。
基础约定。 如果你明确要求,它能标准化分页、过滤与排序,例如:?limit=50&cursor=...(游标分页)或 ?page=2&pageSize=25(基于页的分页),加上 ?sort=-createdAt 与诸如 ?status=active 的过滤器。
泄露的抽象。 一个经典失败是把内部表直接暴露为“资源”,尤其当 schema 有连接表、反规范化字段或审计列时。你会得到像 /user_role_assignments 这样的端点,它反映实现细节而非面向用户的概念,使 API 更难使用与更难改动。
错误处理不一致。 AI 可能混用风格:有时返回 200 携带错误体,有时使用 4xx/5xx。你需要明确契约:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })版本管理被当作事后考虑。 许多 AI 生成的设计会跳过版本策略直到出现痛点。第一天就决定使用路径版本(/v1/...)还是基于 header 的版本,并定义什么构成破坏性变更。即便你永远不升级版本,有明确规则也能防止意外破坏。
把 AI 用于速度与一致性,但把 API 设计当作产品接口。如果某个端点镜像你的数据库而非用户的思维模型,那就说明 AI 优化了易生成性而非长期可用性。
把 AI 当作高速的初级设计师:擅长产出草稿,不为最终系统负责。目标是利用其速度,同时保持架构是有意的、可审查的并以测试为驱动。
如果你使用像 Koder.ai 这样的编码平台,这种责任分离尤为重要:平台可以快速起草并实现后端(例如 Go 服务与 PostgreSQL),但你仍需定义不变量、授权边界与迁移规则。
先用紧凑的 prompt 描述领域、约束与“成功的标准”。要求先交付一个概念模型(实体、关系、不变量),而不是直接给出表。然后按以下固定循环迭代:
这个循环有效,因为它把“AI 建议”变成可被证明或被否决的产物。
保持三层独立:
要求 AI 把这些作为独立章节输出。当某件事变更(例如新增状态或规则),先更新概念层,再在 schema 与 API 间调和。这能减少意外耦合并使重构痛苦更小。
每次迭代都应留下痕迹。使用短小的 ADR 风格摘要(不超过一页)记录:
deleted_at 实现软删除”)。当你把反馈粘回 AI 时,逐字包含相关决策笔记,防止模型“忘记”先前选择并帮助团队在数月后理解后端设计。
把 prompt 当作规范写作练习:定义领域、说明约束,并坚持要具体输出(DDL、端点表格、示例)。目标不是“创意发挥”,而是“精确”。
要求数据模型并给出保持一致性的规则。示例:
如果你已有约定,写明:命名风格、ID 类型(UUID vs bigint)、可空策略与索引预期。
要求输出端点表格而非仅列路由:
加入业务行为:分页样式、排序字段与过滤行为。
让模型考虑发布节奏:
billing_address 字段。提供安全迁移计划:前向迁移 SQL、回填步骤、基于功能flag 的上线顺序与回滚策略。API 在 30 天内必须保持兼容;旧客户端可能省略该字段。”模糊的 prompt 会产生模糊的系统:
想要更好输出时,收紧 prompt:明确规则、边缘情况与交付物格式。
AI 能起草一个体面的后端,但安全上线仍需人工把关。把这份清单作为“发布闸门”:如果某项你不能自信回答,就暂停并修复,避免生产数据的问题。
(tenant_id, slug))。_id 后缀、时间戳)并统一应用。用书面形式确认系统规则:
合并前做一次“正常路径 + 最差路径”审查:一次正常请求、一次非法请求、一次未授权请求与一次高并发场景。如果 API 行为让你感到惊讶,它也会让你的用户惊讶。
AI 能快速生成合理的 schema 与 API,但不能证明后端在真实流量、真实数据与未来变更下的行为正确。把 AI 的输出当作草稿,并用测试来固定行为。
从合同测试开始,验证请求、响应与错误语义,而不是只测试“正常路径”。建立一套在真实实例(或容器)上运行的测试。
重点关注:
如果你发布了 OpenAPI 规范,从中生成测试,但还需为规范无法表达的复杂部分(授权规则、业务约束)手写测试。
AI 生成的 schema 常漏运维细节:安全默认值、回填与可逆性。添加迁移测试来:
为生产准备一套脚本化回滚计划:当迁移慢、锁表或破坏兼容性时该怎么做。
不要对通用端点做基准测试。捕获代表性的查询模式(顶级列表视图、搜索、连接、聚合)并进行压测。
测量:
这是 AI 设计常崩溃的地方:看似“合理”的表在负载下产生昂贵的 join。
增加自动化检测:
即便是基本安全测试也能防止 AI 最代价高的一类错误:端点能工作但泄露过多信息。
AI 可以起草一个不错的“版本 0” schema,但后端会活到版本 50。可持续的区别在于如何演进:迁移、受控重构与清晰的意图文档。
把每次 schema 更改视为一次迁移,即便 AI 建议“直接 alter 表”。使用显式、可逆步骤:先添加新列,回填,再收紧约束。偏好增量改动(新增字段、新表)而非破坏性改动(重命名/删除),直到确认没有依赖旧结构。
当你让 AI 提议 schema 更新时,包含当前 schema 与你的迁移规则(例如:“不删除列;采用 expand/contract 模式”)。这能减少它提出理论上正确但在生产危险的变更。
破坏性变更很少是单一时刻,它们是过渡期:
AI 能帮助产出逐步计划(含 SQL 片段与上线顺序),但你应验证运行时影响:锁、长事务,以及回填是否可中断并可恢复。
重构应当尽量隔离变更。如果需要规范化、拆表或引入事件日志,保留兼容层:视图、翻译代码或“影子”表。让 AI 提议一种在保留现有 API 合同的前提下的重构方案,并列出必须在查询、索引与约束上修改的内容。
长期漂移多数来自于下一个 prompt 忘记原始意图。保留一份简短的“数据模型契约”文档:命名规则、ID 策略、时间戳语义、软删除策略与不变量(例如“订单总额为派生字段,而非存储字段”)。把它链接到内部文档(例如 /docs/data-model)并在未来的 AI prompt 中重用,这样系统在相同边界内设计。
通常意味着模型生成了一个初稿,包括:
但仍需要人工团队验证业务规则、安全边界、查询性能和迁移安全性,才能上线。
在请求 schema 或 API 之前,提供 AI 无法可靠猜测的具体输入:
约束越清晰,AI 就越少以脆弱的默认值“填空”。
先用概念模型(业务概念 + 不变量)开始,然后分别导出:
将这些层分离可以更容易地在不破坏 API 的情况下更换存储,也能在不意外破坏业务规则的情况下调整 API。
常见问题包括:
tenant_id 与复合唯一约束)deleted_at)表面上“整洁”的 schema 在真实工作流与负载下仍可能失败。
要求 AI 按你的顶级查询设计,并验证:
tenant_id + created_at)如果你无法列出前 5 个查询/端点,则任何索引计划都不完整。
AI 在脚手架化 REST API 时很擅长,但要注意:
200 返回错误体,有时使用 4xx/5xx)把 API 当作产品接口:应基于用户概念建模,而不是数据库实现细节。
一个安全的迭代流程:
把 AI 的建议变成可验证或可否决的产物,而不是盲目信任的说明文档。
采用一致的 HTTP 状态码与统一的错误包,例如:
400, 401, 403, 404, 409, 422, 优先固定行为的测试:
测试是你拥有设计而不是继承 AI 假设的手段。
当模式和约束熟悉且风险较低时,AI 很适合用来做草稿(例如 CRUD 重的 MVP、内部工具)。但要谨慎或避免在以下场景完全依赖 AI:
实用策略:让 AI 提供备选方案,但必须有人类对不变量、授权和发布/迁移策略签字负责。
429{"error":{"code":"...","message":"...","details":[...]}}
确保错误信息不泄露内部细节(SQL、堆栈、密钥),并在所有端点保持一致。