2025年9月09日·2 分钟
如何搭建带事故历史的 SaaS 状态网站
学习如何规划、构建并发布包含事故历史、清晰信息与订阅功能的 SaaS 状态页,让客户在故障期间随时获得可靠信息。
学习如何规划、构建并发布包含事故历史、清晰信息与订阅功能的 SaaS 状态页,让客户在故障期间随时获得可靠信息。
SaaS 状态页是一个公开(或仅限客户)的网站,用来展示您的产品当前是否可用——以及在不可用时您正在采取什么措施。它在事故期间成为单一的可信来源,独立于社交媒体、支持工单和传言。
它帮助的对象比你预期的要多:
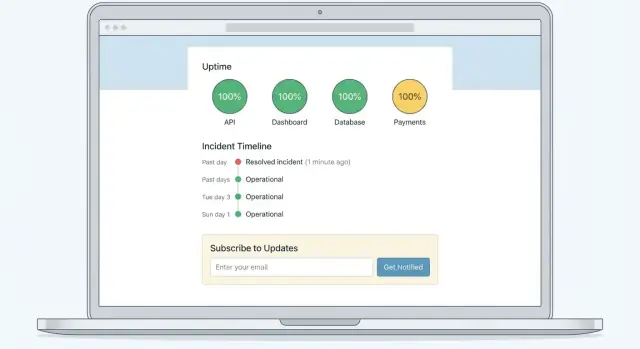
一个好的服务状态网站通常包含三层相关但不同的内容:
目标是清晰:实时状态回答“我能用产品吗?”,历史回答“这种情况多久发生一次?”,复盘回答“为什么发生了,我们做了什么改变?”。
状态页在更新快速、语言通俗且诚实说明影响时才有用。你不需要一个完美的诊断来沟通,但需要时间戳、范围(谁受影响)和下次更新时间。
你会在宕机、性能下降(登录慢、webhook 延迟)和可能引起短暂中断或风险的计划维护时依赖状态页。
一旦你把状态页当成一个产品界面(而不是一次性的运维页面),后续设置会容易很多:你可以定义负责人、建立模板、并把监控接入,而不必在每次事件时重新发明流程。
在选择工具或设计布局之前,先决定状态页要完成什么。一致的目标和明确的负责人能在事故时保持状态页的有效性——那时每个人都很忙、信息很混乱。
多数 SaaS 团队建立状态页是为实现三个实用结果:
写下 2–3 个可衡量信号以便上线后跟踪:故障期间重复工单减少、首次更新更快、更多客户订阅等。
你的主要读者通常是非技术客户,他们想知道:
这意味着要尽量减少行话。用“部分客户无法登录”优于“认证服务出现 5xx 提升”。若确需技术细节,放在短小的次要句子里。
选择在压力下也能保持稳定的语气:冷静、事实为主并透明。提前决定:
明确归属:不要让状态页成为“大家的事”,否则最终会变成“没人负责”。
常见两种选择:
如果主应用可能不可用,独立状态站点通常更安全。仍可在应用和帮助中心(例如 /help)显著链接到状态页。
状态页的价值取决于其背后的“地图”。在选择颜色或撰写文案之前,先决定你要实际报告什么。目标是反映客户感知到的产品体验,而不是组织结构。
列出客户在说“坏了”时可能描述的各部分。对许多 SaaS 产品,一个实用的起始集合包括:
若提供多个地域或层级,也要记录(例如 “API – US” 和 “API – EU”)。使用客户易懂的名称:比起 “IdP Gateway”,用“登录”更清晰。
选择与客户思考方式相匹配的分组:
避免列出无穷无尽的项。如果有数十个集成,考虑使用一个父组件(“集成”)加若干高影响的子项(例如 “Salesforce”、“Webhooks”)。
简单且一致的模型能防止事故时的混乱。常用级别包括:
为每个级别写下内部判定标准(即便不公开)。例如,“部分中断 = 某一区域不可用”或“性能下降 = p95 延迟超过 X 持续 Y 分钟”。一致性建立信任。
多数故障涉及第三方:云主机、邮件投递、支付处理或身份提供商。记录这些依赖项,以便事故更新时信息准确。
是否公开显示取决于受众。如果客户会直接受影响(如支付),显示依赖组件可能有帮助。若会增加噪音或引发责怪,保持内部记录并在相关更新中引用(例如 “我们正在调查支付提供商的错误率上升”)。
一旦有了组件模型,后续设置会更容易:每次事故从一开始就有清晰的“哪儿出问题”和“严重程度”。
状态页最有用的时候是能在几秒钟内回答客户问题。用户通常带着压力来访,想要的是清晰而非大量导航。
把关键内容放在最顶部:
用通俗语言撰写。“API 请求出错率升高”优于“上游依赖发生部分中断”。若必须使用技术术语,补上一句简短翻译(“部分请求可能失败或超时”)。
一个可靠的模式:
组件列表使用客户能理解的标签。若内部服务名是 “k8s-cluster-2”,客户更需要看到“API”或“后台作业”。
让页面在压力环境下也易读:
在顶部(横幅或横幅下方)放一组小链接:
目标是建立信心:客户应立刻理解发生了什么、受影响范围以及何时会有下次更新。
一旦发生事故,团队需在诊断、缓解和应对客户问题间切换。模板能去除不确定性,使更新在不同发布者下也保持一致、清晰且快速。
好的更新从相同的核心事实开始。至少标准化以下字段,以便客户快速理解:
若发布事故历史页,保持字段一致有助于对比与扫描过去事件。
目标是简短的更新,回答客户每次都会问的问题。下面是一个实用模板,可直接复制到状态页工具中:
Title: 简短且具体的概述(例如 “EU 区域 API 错误”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: 用户可见的现象(错误、超时、性能下降)及受影响对象
What we know: 在确认的情况下用一句话说明原因(避免推测)
What we’re doing: 具体行动(回滚、扩容、上游厂商升级)
Next update: 何时再次发布
Updates:
客户不仅要信息,还要可预测性。
计划维护应感觉冷静且结构化。标准化维护发布应包含:
维护语言要具体(改了什么、用户可能注意到什么),并避免过度承诺——客户更看重准确性而非乐观预期。
事故历史不仅仅是日志——它能让客户与团队快速理解问题发生频率、重复类型,以及应对方式。
透明的历史记录能建立信心,并提供趋势可视性:如果每隔几周出现“API 延迟”事件,那就是应该投入性能工作的信号。长期一致的报告还能减少支持工单,因为客户能自助获得答案。
选择与客户期望和产品成熟度匹配的保留窗口。
无论选择什么,都要明确告知(例如 “事故历史保留 12 个月”)。
一致性便于扫视。使用可预测的命名格式,例如:
YYYY-MM-DD — 简短摘要(例如 “2025-10-14 — 邮件投递延迟”)
每个事件至少展示:
如果你发布事后复盘,从事件详情页链接到复盘(例如:“阅读复盘” 链接到 /blog/postmortems/2025-10-14-email-delays)。这样既保持时间线简洁,又为想了解细节的客户提供入口。
状态页只有在客户会去查看时才有用。订阅能自动把更新推送给客户,无需他们刷新页面或联系支持确认。
通常至少提供几种选项:
支持多渠道时保持设置流程一致,避免让客户感觉要分别注册多次。
订阅应始终为 主动选择(opt-in)。在确认前清楚说明用户会收到什么——尤其是 SMS。
允许订阅者控制:
这些偏好能降低告警疲劳并保持通知可信度。如果暂时没有组件级订阅,先提供“所有更新”并在后续添加过滤功能。
事件发生时消息量激增,第三方提供商可能限流。请检查:
值得安排定期测试(例如每季度)以确保订阅仍按预期工作。
在状态首页上方(最好在首屏)放明显的订阅入口,让客户在下次事件前就能订阅。确保移动端也可见,并在支持门户或 /help center 等客户常找的地方加入链接。
如何构建状态页不是“能否构建”的问题,而是你想优化什么:上线速度、在事故期间的可用性和持续维护成本。
托管工具通常是最快的路径,提供现成的状态页、订阅、事故时间线和常见监控系统集成。
选择托管工具时关注:
若想完全控制设计、数据保留与事故历史展现,自建是个好选项。但代价是你要承担可用性与运维。
实用的 DIY 架构:
若自托管,提前规划失败模式:主数据库不可用或部署管道出问题时怎么办?许多团队把状态页放在与主产品不同的基础设施或不同提供商上。
如果想要 DIY 的控制权但不从零开始重做,像 Koder.ai 这类平台可以通过聊天驱动的规格快速构建自定义状态站点(前端 UI 加小型事故 API),并支持导出源码、部署与快速迭代,很适合需要定制组件模型、事故历史 UX 或内部管理工作流的团队。
托管工具通常有可预测的月度收费;DIY 则有工程时间、主机/CDN 成本与持续维护开销。对比选项时列出预期月度支出与内部维护工时,然后与预算做核对(见 /pricing)。
状态页只有在能快速反映现实时才有用。最简单的方法是把发现问题的系统(监控)与协调响应的系统(事故流程)连接起来,这样更新就能保持一致且及时。
多数团队结合三类数据源:
实用规则:监控负责检测;事故流程负责协调;状态页负责沟通。
自动化在关键时刻能节省分钟数:
初次对外发布的信息要保守。“正在调查错误率升高”比 “确认宕机” 更安全,尤其在验证阶段。
全自动发布有风险:
把自动化用作草案与建议,但在对外用语(尤其是 Identified、Mitigated 与 Resolved 状态)前要求人工确认。
把状态页当成面向客户的日志簿。确保你能回答:
审计轨迹有助事后复盘、减少交接时的混乱,并在客户询问时建立信任。
状态页只有在产品不可用时仍能访问才有用。最常见的失败是把状态页建立在与应用相同的基础设施上——当应用挂掉时,状态页也会一起消失,客户就没有可信来源了。
尽可能把状态页托管在与生产应用不同的提供商(或至少不同区域/账户)上。目标是降低冲击半径:应用平台的故障不应影响你的沟通渠道。
亦可考虑把 DNS 分离。如果主域的 DNS 与应用的边缘/CDN 在同一处管理,DNS 或证书问题可能同时挡住两者。许多团队把状态页放在独立子域(例如 status.yourcompany.com)并独立托管 DNS。
资源要精简:最少的 JavaScript、压缩的 CSS,且不要依赖应用 API 来渲染页面。在状态页前放 CDN,并对静态资源启用缓存,使其在故障高峰下仍能加载。
实用的安全网是回退静态模式:
客户不应登录即可查看服务健康。把状态页设为公开,但把管理/编辑工具放在认证(若有 SSO 更佳)后面,并启用强访问控制与审计日志。
最后,测试失败场景:在演练环境暂时屏蔽你的应用源,确认状态页仍能解析、快速加载并在需要时可被更新。
状态页只有在真实事故中持续更新才会建立信任。这种一致性不会凭空出现——你需要明确责任、简单规则和可预测的节奏。
把核心团队保持小而明确:
小团队中一人可兼任两职,但要事先决定。把角色交接与升级路径记录到值班手册(见 /docs/on-call)。
当告警升级为影响客户的事故时,遵循可重复的流程:
实用规则:首次更新在 10–15 分钟 内发布,然后在影响持续期间每 30–60 分钟 发布一次,即便信息是“无变化,仍在调查”。
在 1–3 个工作日内进行轻量事后复盘:
然后把最终总结更新到该事件条目,使事故历史不仅是“已解决”记录,而是有价值的参考。
状态页只有易查找、可信且持续更新才有用。在公布之前做一次“生产就绪”检查,然后设置轻量的改进节奏。
文案与结构
品牌与信任
访问与权限
测试完整流程
宣布
若自建状态站点,建议先在预演环境跑一遍上述上线清单。像 Koder.ai 这样的工具能加快迭代,生成网页 UI、管理界面与后端端点,从单一规格导出代码并快速部署。
每月复查几个简单结果:
保持基础分类以便历史可执行:
随着时间的推移,小改进——更清晰的措辞、更快的更新、更好的分类——会累积成更少的中断、更少的工单与更高的客户信心。
A SaaS 状态页是一个专门的页面,用于在一个规范位置显示 当前服务健康状况 和 事件更新。它可以减少“宕机了吗?”类的支持请求,在故障期间设定期望,并通过清晰且带时间戳的沟通建立信任。
实时状态回答“我现在能使用产品吗?”,展示各个组件的当前状态。
事件历史回答“这种情况多久发生一次?”,通过过去事件与维护的时间线展示模式和频率。
事后复盘(postmortems)回答“为什么会发生,以及我们改变了什么?”,给出根因与预防措施(通常会从事件条目链接到详细复盘)。
先写下 2–3 项可衡量的目标,例如:
把这些目标记录下来并每月复查,避免状态页变得过时。
指定一个明确负责人并设备份(通常是值班轮值)。常见分工:
提前定义规则:谁可以发布、是否需要审批、最小更新频率(例如重大事件时每 30–60 分钟)。
根据客户描述选择组件,而不是内部服务名。常见组件包括:
如果不同地域可用性差异明显,可按区域拆分(例如 “API – US”、“API – EU”)。
使用小而一致的状态集,并为每一项保留内部判定标准:
一致性比绝对精确更重要,让客户通过重复体验理解各级别含义。
有用的事件更新至少应包含:
即便尚未知道根因,也应沟通范围、影响与下一步动作。
尽快发布初始“Investigating”更新(通常在10–15 分钟内)。随后:
如果无法按承诺更新,发布简短说明重设期望,切勿沉默。
托管工具(Hosted)通常更快上线且更可靠,常包含订阅、时间线与监控集成。
DIY 则提供更高的控制权,但需要为可靠性买单:
权衡时列出月度费用与内部维护工时,然后对比预算(见 /pricing)。
提供客户常用的渠道(通常是邮箱与 SMS,另加 Slack/Teams 或 RSS)。保持订阅为 主动选择(opt-in),并说明:
定期测试送达率与速率限制,确保在事件高峰期通知仍可送达,减少告警疲劳。