2025年10月14日·2 分钟
什么是 GraphQL?面向 API 与 数据获取的清晰指南
了解 GraphQL 是什么、查询/变更/模式如何工作,以及在何种情况下应优先使用它而不是 REST——并附带实用的优缺点与示例。
了解 GraphQL 是什么、查询/变更/模式如何工作,以及在何种情况下应优先使用它而不是 REST——并附带实用的优缺点与示例。
GraphQL 是一个 用于 API 的查询语言和运行时。简单来说:它是一种让应用(网页、移动端或其他服务)使用清晰、结构化的请求向 API 获取数据——然后服务器返回与请求匹配的响应的方式。
许多 API 强制客户端接受固定端点返回的内容。这通常导致两个问题:
使用 GraphQL,客户端可以请求 精确需要的字段,不多也不少。当不同页面(或不同应用)需要相同底层数据的不同“切片”时,这尤其有用。
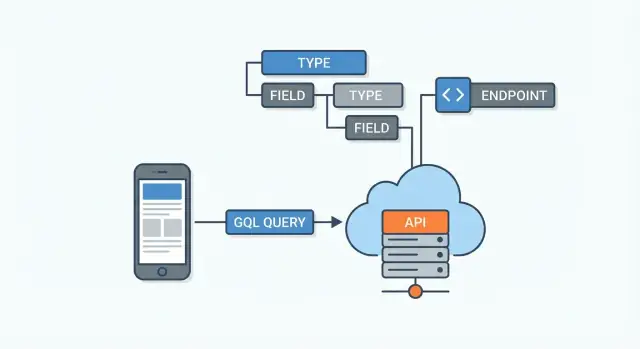
GraphQL 通常位于 客户端应用与数据源之间。这些数据源可能是:
GraphQL 服务器接收一个查询,确定如何从正确的地方获取每个被请求的字段,然后组装最终的 JSON 响应。
把 GraphQL 想象成 订购一个自定义形状的响应:
GraphQL 常被误解,下面是一些澄清:
如果你记住核心定义——查询语言 + API 的运行时——你就有了后续理解的正确基础。
GraphQL 的建立是为了解决实际的产品问题:团队把太多时间花在让 API 适配真实 UI 页面上。
传统的基于端点的 API 经常在“返回多余数据”与“要获得所需数据需额外请求”之间产生选择。随着产品增长,这种摩擦会表现为页面变慢、客户端代码更复杂,以及前后端团队之间的痛苦协调。
过度获取 发生在某个端点返回了一个“完整”对象,即使某个页面只需要几个字段。例如移动端的个人资料视图可能只需要姓名和头像,但 API 返回地址、偏好、审计字段等。那是在浪费带宽并可能损害用户体验。
欠获取 则相反:没有单一端点包含视图所需的所有内容,所以客户端必须发出多次请求并拼接结果。这会增加延迟并提高部分失败的概率。
许多 REST 风格的 API 面对变化时会添加新端点或版本化(v1、v2、v3)。版本化有时是必要的,但它会带来长期的维护工作:旧客户端继续使用旧版本,而新功能堆积在别处。
GraphQL 的做法是通过逐步添加字段和类型来演进模式,同时保持现有字段稳定。这通常减少了仅为支持新 UI 需求就创建“新版本”的压力。
现代产品很少只有一个消费者。网页、iOS、Android 以及合作伙伴集成都需要不同的数据形状。
GraphQL 的设计使得每个客户端可以只请求它需要的字段——而后端不需要为每个页面或设备创建单独端点。
GraphQL API 由其 模式(schema) 定义。把它当作服务器与每个客户端之间的协议:它列出有哪些数据、数据如何连接、以及可以请求或修改什么。客户端不再猜测端点——他们读取模式并请求具体字段。
模式由 类型(比如 User 或 Post)和 字段(比如 name 或 title)组成。字段可以指向其他类型,这就是 GraphQL 建模关系的方式。
这里有一个用模式定义语言(SDL)写的简单示例:
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
因为模式是 强类型 的,GraphQL 可以在运行前验证请求。如果客户端请求了一个不存在的字段(例如模式中没有 Post.publishDate),服务器可以在执行前拒绝请求或以清晰的错误部分地完成请求——而不会出现模糊的“也许能工作”的行为。
模式被设计为可增长。通常你可以 新增字段(比如 User.bio)而不破坏现有客户端,因为客户端只会接收它们请求的内容。移除或更改字段更敏感,所以团队通常先弃用字段并逐步迁移客户端。
GraphQL API 通常通过 单一端点(例如 /graphql)暴露。你不需要多个不同的 URL(像 /users、/users/123、/users/123/posts),而是向同一个端点发送一个 查询 并描述你希望返回的精确数据。
查询本质上是一个字段的“购物清单”。你可以请求简单字段(如 id 和 name),也可以在同一次请求中请求 嵌套数据(比如用户的近期帖子)——而无需下载你不需要的额外字段。
下面是一个小示例:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
GraphQL 响应是 可预测的:你得到的 JSON 会镜像查询的结构。这让前端更容易处理,因为你不用猜测数据会出现在何处或解析不同的响应格式。
一个简化的响应大致如下:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
如果你不请求某个字段,它就不会包含在响应中。如果你请求了它,你可以期待它出现在对应位置——这使得 GraphQL 查询成为为每个页面或功能抓取精确数据的整洁方式。
查询用于读取;变更(mutations) 则是你在 GraphQL API 中更改数据的方式——创建、更新或删除记录。
大多数变更遵循相同的模式:
input 对象),比如要更新的字段。GraphQL 变更通常有意返回数据,而不是只返回 “success: true”。返回更新后的对象(或至少它的 id 和关键字段)有助于 UI:
常见的设计是使用一个包含更新实体和任何错误的“载荷”类型。
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
对于以 UI 为驱动的 API,一个好的规则是:返回渲染下一状态所需的内容(例如,更新后的 user 以及任何 errors)。这让客户端更简单,避免猜测发生了什么,并使失败更容易被优雅地处理。
GraphQL 模式描述了可以被请求的内容。解析器描述了如何实际获取它。解析器是附加到模式中某个字段的函数。当客户端请求该字段时,GraphQL 调用解析器来获取或计算值。
GraphQL 通过遍历请求的形状来执行查询。对于每个字段,它找到相应的解析器并运行它。有些解析器只是返回内存中对象的一个属性;其他解析器可能调用数据库、其他服务,或合并多个来源。
例如,如果你的模式有 User.posts,那么 posts 解析器可能会按 userId 查询 posts 表,或调用独立的 Posts 服务。
解析器是模式与真实系统之间的粘合:
这种映射很灵活:只要模式保持一致,你就可以更改后端实现而不影响客户端查询的形状。
因为解析器可以按字段和按列表中的每一项运行,很容易无意中触发许多小调用(例如为 100 个用户分别获取帖子)。这种 “N+1” 模式会使响应变慢。
常见的修复方法包括批量处理和缓存(例如收集 ID 并一次性查询),并对你鼓励客户端请求的嵌套字段保持刻意控制。
授权通常在解析器中(或共享中间件)强制执行,因为解析器知道是谁在请求(通过 context)以及他们访问的是什么数据。验证通常发生在两个层面:GraphQL 自动处理类型/形状的验证,而解析器负责执行业务规则(例如“只有管理员可以设置此字段”)。
对初学者来说令人惊讶的一点是:一次请求可以“成功”,同时包含错误。这是因为 GraphQL 是面向字段的:如果某些字段可以解析而其他字段不能,你可能会得到部分数据返回。
典型的 GraphQL 响应可以同时包含 data 和 errors 数组:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
这很有用:客户端仍然可以渲染已有内容(例如用户资料),同时处理缺失的字段。
data 通常为 null。为最终用户编写错误信息,而不是为调试写。避免暴露堆栈跟踪、数据库名或内部 ID。一个好的模式是:
messageextensions.coderetryable: true)在服务器端记录带有请求 ID 的详细错误,以便在不暴露内部信息的情况下调查。
定义一个小的错误“契约”供 Web 和移动端共享:常见的 extensions.code 值(如 UNAUTHENTICATED、FORBIDDEN、BAD_USER_INPUT)、何时展示 toast 与何时展示行内字段错误、以及如何处理部分数据。在这方面保持一致可以防止每个客户端发明自己的错误处理规则。
订阅是 GraphQL 将数据在变化时推送给客户端的方法,而不是让客户端反复轮询。它们通常通过 持久连接(最常见是 WebSockets)传输,这样服务器可以在某事发生时立即发送事件。
订阅看起来很像查询,但结果不是一次性的响应,而是 结果流——每个结果代表一个事件。
在底层,客户端“订阅”一个主题(例如聊天应用中的 messageAdded)。当服务器发布事件时,任何已连接的订阅者都会收到与订阅选择集匹配的载荷。
订阅在用户期望即时变化时非常有用:
使用 轮询 时,客户端每隔 N 秒询问一次 “有新内容吗?”。这很简单,但当没有变化时会浪费请求,并且仍然有延迟感。
使用 订阅 时,服务器会立即发送更新。这可以减少不必要的流量并提升感知速度——代价是需要维持连接并管理实时基础设施。
订阅并不总是值得。如果更新不频繁、对实时性要求不高或容易批量处理,则轮询(或在用户操作后重新获取)通常就足够了。
订阅也会增加运维开销:连接扩展、长连接的认证、重试和监控。一个好的规则是:只有当 实时是产品需求 而不是锦上添花时,才使用订阅。
GraphQL 常被描述为“把能力交给客户端”,但这种能力伴随着成本。提前了解权衡可以帮助你决定何时 GraphQL 非常合适,何时可能是过度设计。
最大的收益是 灵活的数据获取:客户端可以请求精确字段,从而减少过度获取,并使 UI 更快地迭代。
另一个重要优势是 由 GraphQL 模式提供的强契约。模式成为类型和可用操作的单一事实来源,改善协作和工具链。
团队通常会看到 客户端生产力提升,因为前端开发者可以无须等待新端点即可迭代,而且像 Apollo Client 这样的工具可以生成类型并简化数据获取。
GraphQL 会使 缓存更复杂。在 REST 中,缓存通常是基于 URL 的;在 GraphQL 中,很多查询共享同一个端点,因此缓存依赖于查询形状、归一化缓存以及仔细的服务端/客户端配置。
在服务器端,也存在 性能陷阱。看似小的查询可能触发许多后端调用,除非你精心设计解析器(批量处理、避免 N+1 模式并控制昂贵字段)。
另外还有 学习曲线:模式、解析器和客户端模式对于习惯端点式 API 的团队来说可能不熟悉。
由于客户端可以请求大量内容,GraphQL API 应该强制执行 查询深度与复杂度限制,以防止滥用或意外的“过大”请求。
认证与授权应当按字段强制,而不仅仅在路由层,因为不同字段可能有不同的访问规则。
在运维上,应投资于能理解 GraphQL 的 日志、追踪与监控:跟踪操作名、变量(谨慎记录)、解析器耗时和错误率,这样你可以及早发现缓慢查询和回归。
GraphQL 和 REST 都帮助应用与服务器通信,但它们组织这种对话的方式很不相同。
REST 是 基于资源 的。你通过调用表示“事物”的多个端点(URL)来获取数据,例如 /users/123 或 /orders?userId=123。每个端点返回由服务器决定的固定数据形状。
REST 也依赖 HTTP 语义:像 GET/POST/PUT/DELETE 的方法、状态码和缓存规则。当你进行简单的增删改查或强烈依赖浏览器/代理缓存时,REST 会显得很自然。
GraphQL 是 基于模式 的。通常只有 一个端点,客户端向该端点发送描述所需字段的查询。服务器根据 GraphQL 模式 验证请求并返回与查询形状匹配的响应。
这种“客户端驱动选择”正是 GraphQL 能减少过度获取和欠获取的原因,尤其是当 UI 页面需要来自多个相关模型的数据时。
当以下情况存在时,REST 往往更合适:
许多团队同时混合使用两者:
实际问题不是“哪个更好?”,而是“哪种方式以最小复杂度适合这个用例?”
在把 GraphQL 设计为面向构建页面的人而不是简单照搬数据库表时,会更容易上手。先小范围试验,用真实用例验证,然后随着需求增长逐步扩展。
列出你的关键页面(例如 “产品列表”、“产品详情”、“结算”)。对每个页面写下它需要的精确字段以及支持的交互。
这能帮助你避免“上帝查询”,减少过度获取,并明确在哪些地方需要过滤、排序和分页。
先定义核心类型(例如 User、Product、Order)及其关系。然后添加:
优先使用面向业务的命名而不是数据库命名。“placeOrder” 比 “createOrderRecord” 更能传达意图。
保持命名一致:单数用于单项(product),复数用于集合(products)。关于分页,通常在两者中选择一种:
即使在高层也尽早决定,因为它会影响 API 的响应结构。
GraphQL 在模式中直接支持描述——对字段、参数和特殊情况使用它们。然后在文档中添加一些可复制示例(包括分页和常见错误场景)。一个注释良好的模式会让自省和 API 探索器更有用。
开始使用 GraphQL 大多是选择一些成熟工具并建立可信任的工作流。你不需要一次性全部采用——使一个查询端到端工作,然后再扩展。
根据你的栈和需要多少“开箱即用”,选择合适的服务器:
一个实用的第一步:定义一个小模式(几个类型 + 一个查询),实现解析器,并连接一个真实的数据源(即使它只是内存中的假数据列表)。
如果你想更快地从“想法”到一个可工作的 API,像 Koder.ai 这样的平台可以帮助你通过对话快速搭建一个小型全栈应用(前端 React,后端 Go + PostgreSQL),并通过聊天迭代 GraphQL 模式/解析器——准备好后再导出源码以便自主管理实现。
在前端,你的选择通常取决于你想要意见化的约定还是灵活性:
如果你正在从 REST 迁移,先在一个页面或功能上使用 GraphQL,其他保持 REST,直到该方法验证有效。
把你的模式当作 API 契约。实用的测试层包括:
要加深理解,请继续阅读:
GraphQL 是一个 用于 API 的查询语言和运行时。客户端发送一个描述所需字段的查询,服务器返回与该结构对应的 JSON 响应。
它更像是位于客户端与一个或多个数据源(数据库、REST 服务、第三方 API、微服务)之间的一层。
GraphQL 主要解决:
通过让客户端只请求特定字段(包括嵌套字段),GraphQL 可以减少多余的数据传输并简化客户端代码。
GraphQL 不是:
把它当作一个 API 合同 + 执行引擎,而不是存储或性能神奇工具。
大多数 GraphQL API 暴露一个 单一端点(通常是 /graphql)。而不是多个 URL,你向该端点发送不同的操作(查询/变更)。
实际含义:缓存和可观测性通常基于 操作名 + 变量,而不是 URL。
Schema(模式) 是 API 的契约。它定义了:
User、Post)User.name)User.posts)因为它是 的,服务器可以在执行前验证查询,并在字段不存在时给出明确错误。
GraphQL 查询是读取操作。你指定所需的字段,响应的 JSON 与查询结构一致。
提示:
query GetUserWithPosts)便于调试与监控。posts(limit: 2))。变更(mutations)是写操作(创建/更新/删除)。常见模式是:
input 对象返回数据(而不仅仅是 success: true)有助于 UI 立即更新并保持缓存一致性。
解析器是字段级别的函数,告诉 GraphQL 如何获取或计算每个字段的值。
在实践中,解析器可能会:
授权通常在解析器中(或通过共享中间件)强制执行,因为解析器知道谁在请求以及访问的是哪些数据。
很容易出现 N+1 问题(例如为 100 个用户分别加载帖子)。
常见缓解措施:
测量解析器耗时并注意单次请求中重复的下游调用。
GraphQL 可以返回 部分数据 与一个 errors 数组。当某些字段解析成功而其他字段失败时,就会出现这种情况(例如,字段无权限或下游服务超时)。
最佳实践:
messageextensions.code 值(例如 FORBIDDEN、BAD_USER_INPUT)客户端应决定何时渲染部分数据或将操作视为完全失败。