2025年10月21日·1 分钟
首次 SaaS 构建者的公共 API 设计:基础
为首次 SaaS 构建者实用的公共 API 设计:选择版本控制、分页、速率限制、文档,以及可快速交付的小型 SDK。
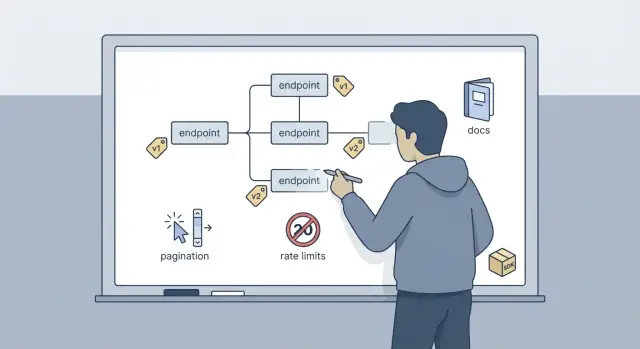
为首次 SaaS 构建者实用的公共 API 设计:选择版本控制、分页、速率限制、文档,以及可快速交付的小型 SDK。
公共 API 不只是你的应用暴露出的某个端点。它是对团队外部人的一种承诺:即使产品发生变化,这个契约也会继续生效。
困难的不是写出 v1,而是当你修复 bug、添加功能并在学习客户真实需求时,保持它的稳定。
早期的决策会在以后以支持工单的形式显现出来。如果响应结构在没有通知的情况下改变,如果命名不一致,或者客户端无法判断请求是否成功,你就在制造摩擦。那种摩擦会变成不信任,而不信任会让人停止基于你的平台构建。
速度也很重要。大多数首次 SaaS 构建者需要快速交付一些有用的东西,然后再逐步改进。权衡很简单:越快发布但不设规则,等真实用户来了你就越花时间去撤销这些决定。
对 v1 来说“足够好”通常意味着一小组映射到真实用户操作的端点、命名和响应形状的一致性、一个清晰的变更策略(即便只是 v1)、可预测的分页和合理的速率限制,以及能准确展示应发送什么和会收到什么的文档。
一个具体例子:想象客户构建了一个每晚创建发票的集成。如果你后来重命名了字段、改变了日期格式,或悄悄开始返回部分结果,他们在凌晨两点的作业就会失败。他们会归咎于你的 API,而不是自己的代码。
如果你使用像 Koder.ai 这样的聊天驱动工具生成端点,很容易快速产出很多接口。那没问题,但把公共表面保持小。你可以在学习哪些应该成为长期契约时把内部端点保持私有。
好的公共 API 设计从选择一小组与客户表达方式相匹配的名词(资源)开始。即便内部数据库变化,也要保持资源名称稳定。添加功能时,优先添加字段或新端点,而不是重命名核心资源。
很多 SaaS 产品的实用起点是:users、organizations、projects 和 events。如果你无法在一句话内解释一个资源,那它可能还没准备好公开。
让 HTTP 用法保持乏味且可预测:
认证在第一天不需要花哨。如果你的 API 主要是服务器间调用(客户从其后端调用),API key 往往足够。如果客户需要以个人终端用户身份操作,或你预期第三方集成需要用户授权,OAuth 通常更合适。用简单语言写下决定:谁是调用方,他们被允许访问谁的数据?
及早设定期望。明确说明哪些是支持的,哪些是尽力而为。例如:列表端点是稳定且向后兼容的,但搜索过滤可能会扩展且不保证穷尽。这样能减少支持工单并让你自由改进。
如果你在像 Koder.ai 这样的即兴编码平台上构建,把 API 当作一个产品契约:先把契约缩小,然后基于真实用量扩展,而不是基于猜测。
版本化主要是关于期望。客户端想知道:我的集成会在下周被弄坏吗?你想要有空间在不恐慌的情况下改进。
基于 Header 的版本化看起来更干净,但它很容易在日志、缓存和支持截屏中被隐藏。URL 版本化通常是最简单的选择:/v1/...。当客户发来失败请求时,你可以立即看到版本信息,也更容易并行运行 v1 和 v2。
如果一个守规矩的客户端在不改动代码的情况下可能停止工作,那么该变更就是破坏性的。常见示例:
customer_id 改为 customerId)安全的变更是旧客户端可以忽略的变更。添加新的可选字段通常是安全的。例如,在 GET /v1/subscriptions 的响应中添加 plan_name,不会破坏仅读取 status 的客户端。
一个实用规则:不要在同一主版本内移除或重新利用字段。添加新字段,保留旧字段,只有在准备弃用整个版本时才移除它们。
保持简单:提前宣布弃用,在响应中返回清晰的警告信息,并设定结束日期。对于第一个 API,90 天的窗口通常是现实的。在这段时间内,保持 v1 可用,发布简短的迁移说明,并确保支持团队能指向一句话:v1 在此日期前有效;v2 改动在这里。
如果你在像 Koder.ai 这样的平台上构建,把 API 版本看作快照:在新版本中发布改进,保持旧版稳定,并在给客户足够迁移时间后再停止旧版。
分页是建立或破坏信任的地方。如果结果在请求间跳动,人们就会停止信任你的 API。
当数据集较小、查询简单且用户常常需要第 3 页时,使用 page/limit。当列表可能增长很大、新项目频繁到达或用户会大量排序过滤时,使用基于游标的分页。游标分页在新记录被加入时能保持顺序稳定。
有几条规则可保持分页可靠:
总数(totals)比较棘手。total_count 在有过滤条件的大表上可能代价很高。如果能廉价提供就加上,否则省略或通过查询标志使其可选。
这里有几个简单的请求/响应示例。
// Page/limit
GET /v1/invoices?page=2limit=25sort=created_at_desc
{
"items": [{"id":"inv_1"},{"id":"inv_2"}],
"page": 2,
"limit": 25,
"total_count": 142
}
// Cursor-based
GET /v1/invoices?limit=25cursor=eyJjcmVhdGVkX2F0IjoiMjAyNi0wMS0wOVQxMDozMDowMFoiLCJpZCI6Imludl8xMDAifQ==
{
"items": [{"id":"inv_101"},{"id":"inv_102"}],
"next_cursor": "eyJjcmVhdGVkX2F0IjoiMjAyNi0wMS0wOVQxMDoyNTowMFoiLCJpZCI6Imludl8xMjUifQ=="
}
速率限制的目的不在于严苛,而是在于保持在线。它们保护你的应用免受流量冲击,保护数据库免于被代价高昂的查询频繁命中,也保护你的账单不被意外撑高。限制也是一种契约:客户端知道什么是正常使用。
先从简单开始并随后调优。选择一个覆盖典型使用场景并允许运行短暂突发的配额,然后观察真实流量。如果你还没有数据,一个安全的默认是每个 API key 每分钟 60 次请求加上一点突发允许。如果某个端点特别重(例如搜索或导出),对它单独设定更严格的限制或单独计费,而不是惩罚所有请求。
当你强制限流时,让客户端易于正确处理。返回 429 Too Many Requests 并包含几个标准头:
X-RateLimit-Limit: 窗口内允许的最大值X-RateLimit-Remaining: 剩余可用次数X-RateLimit-Reset: 窗口何时重置(时间戳或秒数)Retry-After: 在重试前应等待多长时间客户端应把 429 视为正常情况,而不是要对抗的错误。一个礼貌的重试模式能让双方都满意:
Retry-After 就等待该时长举例:如果客户做每晚同步导致大量请求触达你的 API,他们的任务可以把请求分散到一分钟内,并在遇到 429 时自动减速,而不是让整个任务失败。
如果你的 API 错误难以阅读,支持工单会迅速堆积。选一个错误格式并在所有地方坚持(包括 500)。一个简单标准是:code、message、details,以及用户可以粘贴到支持聊天中的 request_id。
这是一个小而可预测的格式:
{
"error": {
"code": "validation_error",
"message": "Some fields are invalid.",
"details": {
"fields": [
{"name": "email", "issue": "must be a valid email"},
{"name": "plan", "issue": "must be one of: free, pro, business"}
]
},
"request_id": "req_01HT..."
}
}
始终一致地使用 HTTP 状态码:400 表示输入错误,401 表示缺少或无效认证,403 表示已认证但无权限,404 表示资源未找到,409 表示冲突(如重复唯一值或错误状态),429 表示速率限制,500 表示服务器错误。稳定性比聪明更重要。
让校验错误易于修复。字段级提示应指向文档中使用的确切参数名,而不是内部数据库列名。如果有格式要求(日期、货币、枚举),说明你接受的格式并给出示例。
重试是很多 API 无意中制造重复数据的地方。对于重要的 POST 操作(付款、发票创建、发送邮件),支持幂等键以便客户端安全重试。建议做法:
Idempotency-Key 头。这个头能避免在网络不稳定或客户端超时情况下产生很多棘手的边缘情况。
假设你运行一个简单的 SaaS,它有三个主要对象:projects、users 和 invoices。一个 project 有许多 users,每个 project 每月生成发票。客户端希望将发票同步到他们的会计工具,并在自己应用中展示基本计费信息。
一个干净的 v1 可能像这样:
GET /v1/projects/{project_id}
GET /v1/projects/{project_id}/invoices
POST /v1/projects/{project_id}/invoices
现在发生了一个破坏性变化。在 v1 中,你以分整数(以美分为单位)存储发票金额:amount_cents: 1299。后来你需要多币种和小数,因此你想要 amount: "12.99" 和 currency: "USD"。如果你覆盖旧字段,所有现有集成都将崩溃。版本化可以避免恐慌:保持 v1 稳定,发布带新字段的 /v2/...,并在客户端迁移前同时支持两者。
对于发票列表,使用可预测的分页结构。例如:
GET /v1/projects/p_123/invoices?limit=50cursor=eyJpZCI6Imludl85OTkifQ==
200 OK
{
"data": [ {"id":"inv_1001"}, {"id":"inv_1000"} ],
"next_cursor": "eyJpZCI6Imludl8xMDAwIn0="
}
有一天某客户在循环中导入发票并触及你的速率限制。与其出现随机失败,他们会得到明确的响应:
429 Too Many RequestsRetry-After: 20{ "error": { "code": "rate_limited" } }在客户端,他们可以暂停 20 秒,然后从同一个 cursor 继续,而无需重新下载全部或创建重复发票。
把 v1 发布当作一次小型产品发布,而不是一堆端点堆在一起来做,会更顺利。目标很简单:人们能基于它构建,而你可以在不惊慌的情况下持续改进它。
先写一页解释你的 API 用来做什么、不做什么。把表面面积控制在你能在一分种内口头解释清楚的范围内。
按下列顺序执行,且在每一步达到“足够好”前不要前进:
如果你使用代码生成工作流(例如使用 Koder.ai 来脚手架端点和响应),仍然要做假客户端测试。生成的代码可能看起来正确,但使用体验上仍会让人尴尬。
回报是更少的支持邮件、更少的热修复发布,以及一个你真正能维护的 v1。
第一版 SDK 不是第二个产品。把它当作对 HTTP API 的一个精薄友好包装。它应让常见调用变得简单,但不应掩盖 API 的工作方式。如果有人需要你尚未封装的功能,他们仍应能直接发起原始请求。
选一种语言开始,基于客户实际使用的语言。对于许多 B2B SaaS API 来说,首选往往是 JavaScript/TypeScript 或 Python。发布一个成熟的 SDK 胜过同时发布三个半成品。
一个好的起始集合包括:
你可以手写这些,或从 OpenAPI 规范生成。生成在规范准确且你想要一致类型时很棒,但通常会产出大量代码。早期手写一个最小客户端加一份用于文档的 OpenAPI 文件通常已足够。只要公开的 SDK 接口保持稳定,你可以以后切换到生成客户端而不破坏用户体验。
API 版本应遵循你的兼容性规则。SDK 版本应遵循打包发布规则。
如果你添加了新的可选参数或新端点,那通常是 SDK 的次要版本更新。只在 SDK 本身破坏性改动(方法重命名、默认值改变)时发布主版本,即便 API 本身未改变。这种分离能让升级过程平稳并减少支持工单。
大多数 API 支持工单不是关于 bug,而是关于惊喜。公共 API 设计大部分是让它变得乏味且可预测,这样客户端代码才能在月复一月地正常工作。
失去信任最快的方法是未经告知地改变响应。如果你重命名字段、改变类型或开始返回 null(而原来是值),你会以难以诊断的方式破坏客户端。如果确实必须改变行为,要进行版本化,或添加新字段并在一段时间内保留旧字段并说明退役计划。
分页也是重复发生问题的来源。当一个端点使用 page/pageSize,另一个使用 offset/limit,第三个使用游标并且每个都有不同的默认值时,问题就出现了。为 v1 选择一种模式并在所有地方坚持。也要保持排序稳定,避免在有新记录到来时下一页跳过或重复项。
错误不一致会引发大量往返。一种常见失败模式是一个服务返回 { "error":"..." },另一个返回 { "message":"..." },并且对相同问题使用不同的 HTTP 状态码。结果是客户端构建了凌乱且针对端点的处理逻辑。
以下五个错误会产生最长的邮件线程:
一个简单习惯能带来很大帮助:每个响应都应包含 request_id,每个 429 都应说明何时重试。
在你发布任何东西之前,做一次面向一致性的最终检查。大多数支持工单发生是因为端点、文档和示例之间的小细节不匹配。
能抓到最多问题的快速检查:
发布后,关注用户实际调用的接口,而不是你希望他们使用的接口。早期一个小仪表盘和每周审查已足够。
先监控这些信号:
收集反馈但不要重写一切。在文档中添加一条简短的提交问题路径,并为每条报告标注端点、request id 和客户端版本。修复时,优先采用增量式改动:新字段、新可选参数或新端点,而不是破坏现有行为。
下一步:写一页 API 规范,列出你的资源、版本计划、分页规则和错误格式。然后生成文档并做一个涵盖认证和 2–3 个核心端点的小型入门 SDK。如果你想更快,可以先用像 Koder.ai 这样的聊天计划起草规范、文档和入门 SDK(它的规划模式是在生成代码前映射端点和示例的好帮手)。
从 5–10 个端点 开始,这些端点应映射到真实的客户动作。
一个好规则是:如果你无法用一句话解释一个资源(它是什么、谁拥有、如何使用),那就暂时把它保留为内部接口,等通过使用数据学到更多再公开。
选择一组 小而稳定的名词(资源),这些名称应当是客户在交流中已经使用的词,并在公开后保持稳定,即使你的数据库结构改变也不要重命名它们。
SaaS 常见的起点包括 users、organizations、projects 和 events——只有在有明确需求时才增加更多。
使用标准语义并保持一致:
GET = 读取(无副作用)POST = 创建或启动动作PATCH = 局部更新DELETE = 删除或禁用主要好处是可预测性:客户端不应去猜测某个方法会做什么。
默认采用 URL 版本化,例如 /v1/...。
这样在日志和截屏里更容易看清版本,也更方便在需要破坏性变更时同时运行 v1 和 v2 以便调试。
如果一个正确实现的客户端在不修改代码的情况下会失败,则该变更就是破坏性的。常见示例包括:
添加新的可选字段通常是安全的。
保持简单:
一个实用的默认值是为首次 API 提供 90 天窗口,让客户有时间迁移而不至于惊慌。
在所有列表端点中选一个分页模式并保持一致。
始终定义默认排序并增加一个决定性字段(例如 created_at + id),以避免结果在请求间跳动。
先定一个清晰的每键限额(例如 60 次请求/分钟 加上小幅突发允许),然后根据实际流量调整。
当触发限制时返回 429,并包含:
X-RateLimit-LimitX-RateLimit-RemainingX-RateLimit-Reset在所有地方使用统一的错误格式(包括 500)。一个实用的结构是:
code(稳定标识)message(易读文本)details(字段级问题)request_id(用于支持查询)同时保持状态码一致(400/401/403/404/409/429/500),让客户端能干净地处理错误。
如果你快速生成了许多端点(例如使用 Koder.ai),把公共表面保持小,并将其视为长期合约。
发布前要做的事:
POST 操作加入幂等性键然后发布一个小型 SDK,帮助处理认证、超时、对安全请求的重试和分页——但不要把 HTTP 工作细节完全隐藏起来。
Retry-After这样能让重试变得可预测并减少支持工单。