2025年10月24日·1 分钟
为什么数据库索引是最重要的性能提升
了解数据库索引如何缩短查询时间、何时有用(以及何时有害),以及为真实应用设计、测试和维护索引的实用步骤。
了解数据库索引如何缩短查询时间、何时有用(以及何时有害),以及为真实应用设计、测试和维护索引的实用步骤。
数据库索引是一个独立的查找结构,帮助数据库更快地找到行。它不是表的第二个副本。把它想象成书的索引页:你先跳到索引页附近,然后再翻到确切的页面(行)。
没有索引时,数据库通常只有一个安全的选项:逐行读取大量行以检查哪些行匹配查询。当表只有几千行时这可能没问题。但当表增长到数百万行时,“检查更多行”会转化为更多磁盘读取、更多内存压力和更多 CPU 工作——于是原本感觉瞬间完成的查询开始变慢。
索引减少了数据库为回答“找到 ID 为 123 的订单”或“获取这个邮箱的用户”这类问题必须检查的数据量。数据库不是扫描所有内容,而是先查看一个紧凑的结构来快速缩小搜索范围。
但索引并非万能。有些查询仍然需要处理大量行(宽泛的报表、低选择性的过滤、繁重的聚合)。而且索引有真实的成本:额外的存储和更慢的写入,因为插入和更新也必须修改索引。
你会看到:
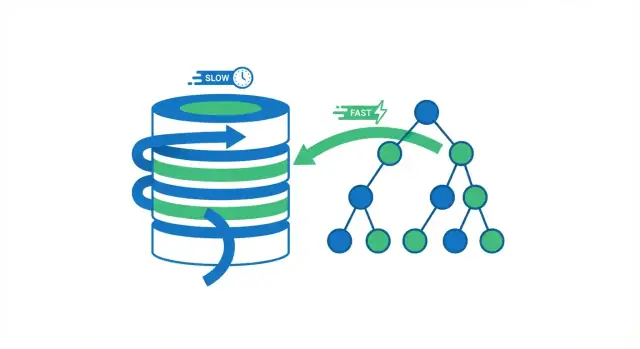
当数据库执行查询时,它有两种大致选择:逐行扫描整个表,或直接跳到匹配的行。大多数索引带来的提升都来自于避免不必要的读取。
全表扫描 就是字面意思:数据库读取每一行,检查它是否满足 WHERE 条件,然后才返回结果。小表可以接受,但随着表增大速度会按可预见的方式变慢——行越多,工作越多。
使用索引时,数据库通常可以避免读取大部分行。它先查索引(为搜索构建的紧凑结构),找到匹配行的位置,然后只读取那些特定行。
想象一本书。如果你想找到所有提到“光合作用”的页面,你可以从头到尾读(全表扫描),也可以用目录跳到列出的页面并只读那些部分(索引查找)。第二种方法更快,因为你跳过了几乎全部页面。
数据库大量时间花在等待读取上——尤其是当数据不在内存中时。减少数据库必须接触的行(和页面)通常会降低:
当数据量大且查询模式具有选择性(例如,从 1000 万条中取出 20 条匹配行)时,索引最有帮助。如果查询本来就返回大部分行,或表小到可以轻松放入内存,全表扫描可能同样快,甚至更快。
索引之所以有效,是因为它们组织了值,使数据库可以跳到接近目标的位置,而不是检查每一行。
SQL 数据库中最常见的索引结构是 B 树(通常写作 “B-tree” 或 “B+tree”)。概念上:
由于是排序的,B 树非常适合 等值查找(WHERE email = ...)和 范围查询(WHERE created_at >= ... AND created_at < ...)。数据库可以定位到正确的值邻域,然后按序向前扫描。
人们说 B 树查找是“对数级”的。实际含义是:当表从几千行增长到数百万行时,查找步骤数增长很慢,并非按比例增长。
不是“数据翻倍意味着工作翻倍”,而更像是“数据多了很多,但导航步骤只增加几次”,因为数据库沿着树的少数几个层级跟随指针。
一些引擎也提供 哈希 索引。对精确等值查询它们可以非常快,因为值被转换为哈希并直接定位条目。
权衡:哈希索引通常对范围或有序扫描无帮助,而且不同数据库的可用性/行为不同。
PostgreSQL、MySQL/InnoDB、SQL Server 等在存储与使用索引方面存在差异(页面大小、聚簇、包含列、可见性检查)。但核心概念不变:索引创建了一个紧凑、可导航的结构,使数据库能够以远少于全表扫描的工作量定位匹配行。
索引并不会普遍加速“SQL”,而是对特定的访问模式生效。当索引与查询的过滤、连接或排序方式匹配时,数据库可以直接跳到相关行,而不是读取整个表。
1) WHERE 过滤(尤其是在高选择性列上)
如果查询通常把大表缩小到很少的行,索引通常是首选。查找用户标识符就是经典示例。
没有在 users.email 上建立索引,数据库可能要扫描每一行:
SELECT * FROM users WHERE email = '[email protected]';
在 email 上有索引时,它能快速定位匹配行并提前结束。
2) 连接键(外键与被引用键)
连接时“小效率”会放大成巨大开销。如果你将 orders.user_id 与 users.id 连接,为连接列建立索引(通常为 orders.user_id 和主键 users.id)能帮助数据库在不反复扫描的情况下匹配行。
3) ORDER BY(当你需要已排序结果时)
当数据库必须在取回大量行后再排序时,排序代价很高。如果你经常运行:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
与 user_id 和排序列对齐的索引可以让引擎按需读取已排序的行,而不是对一个大中间结果排序。
4) GROUP BY(当分组与索引对齐时)
当数据库能按分组顺序读取数据时,分组操作会受益。这并非保证,但如果你常按一个既用于过滤又自然聚合在索引中的列分组,引擎可能会减少工作量。
B 树索引对范围条件尤其友好——比如日期、价格和 between 查询:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
对于仪表盘、报表和“最近活动”界面,这种模式非常常见,在范围列上建立索引通常能立竿见影地提升性能。
主题很简单:索引最有帮助的时候是它们反映了你的搜索和排序方式。如果查询与这些访问模式一致,数据库就可以进行有针对性的读取,而不是广泛扫描。
当索引能显著缩小数据库必须接触的行数时才有价值。这一属性称为选择性。
选择性基本上是:给定值会匹配多少行? 高选择性列有很多不同值,因此每次查找匹配行很少。
email、user_id、order_number(通常唯一或接近唯一)is_active、is_deleted、只有少数常见取值的 status高选择性时,索引能跳到很小的行集;低选择性时,索引指向的是表中很大的一块区域——因此数据库仍需读取并过滤很多行。
考虑一个有 1000 万行的表,列 is_deleted 中 98% 为 false。对 is_deleted 建索引并不能在下面的查询中节省多少时间:
SELECT * FROM orders WHERE is_deleted = false;
匹配集仍然是几乎整个表。使用索引甚至可能比顺序扫描更慢,因为引擎在索引条目与表页面之间跳转会带来额外开销。
查询规划器会估计成本。如果索引不能足够减少工作量——因为匹配行太多,或查询需要大部分列——它可能会选择全表扫描。
数据分布并非固定。一个 status 列可能起初均匀分布,但随着时间推移某个值占主导。如果统计信息未更新,规划器会做出错误决策,一个曾经有用的索引可能不再划算。
单列索引是起点,但很多真实查询在一列上过滤同时在另一列上排序或过滤。这时 组合(多列)索引 很有用:一个索引可以满足查询的多个部分。
多数数据库(尤其是 B 树索引)只能从最左列开始高效使用组合索引。把索引看成先按列 A 排序,然后在 A 内按列 B 排序,以此类推。
这意味着:
account_id 过滤并按 created_at 排序或过滤的查询created_at 过滤的查询(因为它不是最左列)常见工作负载是“显示此账户的最新事件”。如下查询模式:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
通常会从下面的索引获益良多:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
数据库可以直接跳到某个账户在索引中的片段并按时间顺序读取行,而不是扫描并排序大量数据。
覆盖索引 包含查询所需的所有列,因此数据库可以仅从索引返回结果,而无需去查表(减少读取,减少随机 I/O)。
注意:添加额外列会使索引变大且昂贵。
宽组合索引会降低写入性能并占用大量存储。只为具体的高价值查询添加它们,并在添加前后用 EXPLAIN 和真实测量验证效果。
索引常被描述为“免费加速”,但它们并非免费。每当表改变时,索引结构也必须维护,而且它们消耗真实资源。
插入新行时,数据库不仅写入行,还要向表上的每个索引插入对应条目。删除与许多更新也是如此。
这就是为什么“更多索引”会明显拖慢写密集型工作负载的原因。触及被索引列的 UPDATE 尤其昂贵:数据库可能需要移除旧的索引条目并添加新的(在某些引擎中,这会触发额外的页面分裂或内部重平衡)。如果你的应用有大量写入——订单事件、传感器数据、审计日志——为所有列建立索引会使数据库即使在读很快时也感觉迟钝。
每个索引都占磁盘空间。在大表上,索引可能会与表大小相当,尤其当你有多个重叠索引时。
这也影响内存。数据库严重依赖缓存;如果工作集包含多个大索引,缓存必须容纳更多页面以保持快速。否则你会看到更多磁盘 I/O 和更不可预测的性能。
索引就是选择你要加速的对象。如果工作负载以读为主,更多索引可能值得。如果以写为主,优先为最重要的查询建立索引并避免重复。一个有用的规则:只有在你能说出它为哪条查询服务时才添加索引——并验证读取速度的提升是否超过写入和维护成本。
添加索引看起来理应有用——但你应该验证。两个实用工具是查询计划(EXPLAIN)和真实的变更前/后测量。
在你关心的确切查询上运行 EXPLAIN(或 EXPLAIN ANALYZE)。
EXPLAIN ANALYZE 中):如果计划估计 100 行但实际触及了 100,000 行,优化器做了错误猜测——通常是因为统计信息过时或过滤比预期不具选择性。ORDER BY,该排序可能消失,这是很大的收益。用相同参数、在代表性数据规模下对查询基线进行记录,捕获延迟(p50/p95)、扫描行数及 CPU/IO 影响。
注意缓存效应:第一次运行可能较慢因为数据未在内存;重复运行可能在没有索引的情况下看起来也很快。为避免自欺,比较多次运行并关注计划是否变化(是否使用索引、读取行数是否减少),而不仅仅是绝对时间。
如果 EXPLAIN ANALYZE 显示触及的行数更少且昂贵步骤(如排序)更少,你就证明了索引确实有帮助,而不是仅有希望它有用。
即使你加了“正确”的索引,如果查询写法阻止数据库使用它,仍可能看不到加速效果。这类问题常常微妙,因为查询结果仍然正确——只是被迫走了慢路径。
1) 前置通配符
像这样写:
WHERE name LIKE '%term'
普通 B 树索引无法用于这种情况,因为数据库不知道“%term”在排序顺序中从何处开始,通常会回退为扫描大量行。
备选方案:
WHERE name LIKE 'term%'。2) 在被索引列上使用函数
看起来无害的写法:
WHERE LOWER(email) = '[email protected]'
但 LOWER(email) 改变了表达式,普通的 email 索引无法直接使用。
备选方案:
WHERE email = ...。LOWER(email)。隐式类型转换: 比较不同数据类型会强制数据库对一侧进行类型转换,这可能禁用索引。例如把整数列与字符串字面量比较。
不匹配的排序规则/编码: 如果比较使用的排序规则与索引建立时不同(不同区域设置下的文本列常见),优化器可能会回避索引。
LIKE '%x')?LOWER(col)、DATE(col)、CAST(col))?EXPLAIN 检查过数据库实际选择的计划?索引不是“建好就忘记”的东西。随着时间推移,数据变化、查询模式转移,表和索引的物理形态会偏离。精心选择的索引如果不维护,可能会逐渐变得低效,甚至有害。
大多数数据库依赖查询规划器(优化器)来选择如何执行查询:用哪个索引、选择哪个连接顺序、是否使用索引查找。为做这些决策,规划器使用统计信息——关于值分布、行数与偏斜的摘要。
当统计信息过时时,规划器的行数估计可能大相径庭,导致糟糕的计划选择,比如选了一个会返回远多于预期行数的索引,或跳过了本该更快的索引。
常规修复:安排定期更新统计(通常称为 “ANALYZE” 或类似操作)。在大量加载数据、重大删除或高变动后尽早刷新统计。
随着插入、更新与删除,索引会积累膨胀(不再有用的额外页面)与碎片(数据分布导致 I/O 增加)。结果是索引变大、扫描变慢——尤其对范围查询影响显著。
常规修复:在索引变得异常大或性能下降时,定期重建或重组织高使用率索引。具体工具和影响因数据库不同而异,因此把此作为有测量依据的操作,而非普遍规则。
建立监控以观测:
这个反馈回路能帮你在需要维护或调整/删除索引时尽早发现问题。关于如何验证改进的更多内容,请参见 /blog/how-to-prove-an-index-helps-explain-and-measurements。
添加索引应当是个有目的的变更,而不是猜测。轻量级工作流能让你聚焦可测的收益并防止“索引泛滥”。
从证据出发:慢查询日志、APM 跟踪或用户报告。挑一个既慢又频繁的查询——一个罕见的 10 秒报表比不上一个常见的 200 ms 查找更值得优先处理。
记录确切的 SQL 与参数模式(例如:WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50)。微小差异会改变哪个索引有用。
记录当前延迟(p50/p95)、扫描行数及 CPU/IO 影响。保存当前计划输出(如 EXPLAIN / EXPLAIN ANALYZE)以便后续对比。
选择与查询过滤和排序方式匹配的列。优先最小化的索引,能让计划停止扫描大范围。
在类似生产数据量的预发布环境中测试。索引在小数据集上看起来很漂亮,但在规模上可能失望。
在大表上使用在线选项(若支持,例如 PostgreSQL 的 CREATE INDEX CONCURRENTLY)。若数据库会锁写入,在流量较低时安排变更。
重新运行相同查询并比较:
如果索引提高了写入开销或膨胀了内存,干净地删除它(在可用的情况下,例如 DROP INDEX CONCURRENTLY)。保持迁移可回退。
在迁移或 schema 注释中写明该索引为哪条查询服务以及哪个指标得到改善。将来的你(或同事)会知道它为何存在以及何时可以安全删除。
如果你在构建新服务并想早期避免“索引泛滥”,Koder.ai 可以帮助你更快地在以上完整循环中迭代:从聊天生成 React + Go + PostgreSQL 应用,随着需求变化调整 schema/索引迁移,然后在准备好时导出源码。这样在实际操作中更容易从“某端点慢”变成“这是 EXPLAIN、最小索引和可回退迁移”的实际改进,而无需等待传统流水线。
索引是强有力的杠杆,但不是魔法按钮。有时请求慢的部分发生在数据库找到正确行之后——或者你的查询模式使索引不是首要改进方向。
如果查询已经使用了合适的索引但仍然缓慢,请排查这些常见原因:
OFFSET 999000 去获取第 1000 页哪怕有索引也会慢。优先键集分页(例如基于最后看到的 id/timestamp)。SELECT *)或返回数万条记录会在网络、JSON 序列化或应用处理上成为瓶颈。LIMIT,并有意识地分页结果。如果你想做更深入的瓶颈诊断,把本指南与 /blog/how-to-prove-an-index-helps 的工作流结合起来。
不要凭感觉。度量时间花在何处(数据库执行 vs 返回行 vs 应用代码)。如果数据库很快但 API 慢,更多索引不会有帮助。
数据库索引是一个独立的数据结构(通常是 B 树),它以可搜索、排序的形式存储选定的列值,并带有指向表行的指针。数据库使用它来避免读取大部分表以响应有选择性的查询。
它不是表的完整副本,但会复制某些列数据和元数据,这就是它会占用额外存储空间的原因。
如果没有索引,数据库可能需要做全表扫描:读取很多(或全部)行并检查每一行是否满足你的 WHERE 条件。
使用索引时,它通常可以直接跳转到匹配行的位置并只读取那些行,从而减少磁盘 I/O、CPU 过滤工作和缓存压力。
B 树索引将值保持排序并组织成指向其他页的页面,因此数据库可以快速导航到正确的“值邻域”。
这就是为什么 B 树既适合于:
WHERE email = ...)WHERE created_at >= ... AND created_at < ...)哈希索引在精确相等(=)场景下可以非常快:它将值哈希后直接定位到桶。
权衡:
在许多实际场景下,B 树是默认选择,因为它支持更多类型的查询。
索引通常最能提升以下场景:
WHERE 过滤(匹配行很少)JOIN 键(外键与被引用键)ORDER BY(可避免排序)GROUP BY 场景下,当按分组顺序读取数据能减少工作量时如果查询返回表的大部分行,索引带来的好处通常很小。
选择性是“给定值匹配多少行”。索引在谓词能把大表缩小到小结果集时才有价值。
低选择性的列(例如 is_deleted、is_active、只有少数取值的 status)通常匹配表的大部分行。在这种情况下,使用索引可能比顺序扫描更慢,因为引擎仍需读取并过滤大量行。
因为优化器估计使用索引不会显著减少工作量。
常见原因包括:
在大多数 B 树实现中,索引实际上按第一列排序,然后在该列内按第二列排序,依此类推。因此数据库能有效利用从最左边的列开始的前缀。
例如:
(account_id, created_at) 非常适合 WHERE account_id = ? 并按时间过滤/排序的查询。created_at 过滤的查询,它通常并不有帮助(因为 created_at 不是最左列)。覆盖索引包含查询所需的所有列,因此数据库可以直接从索引返回结果,而无需查表。
优点:
成本:
应将覆盖索引用于具体的高价值查询,而不是“以防万一”地添加。
检查两件事:
EXPLAIN / ,确认计划是否发生变化(例如 → ,读取行数减少,排序步骤消失)。EXPLAIN ANALYZESeq ScanIndex Scan/SeekINSERT/UPDATE/DELETE 的速度。