2025年5月13日·1 分钟
TypeScript 如何让大型 JavaScript 前端更易维护
TypeScript 引入了类型、更完善的工具链与更安全的重构,帮助团队以更少的 bug 和更清晰的代码扩展 JavaScript 前端。
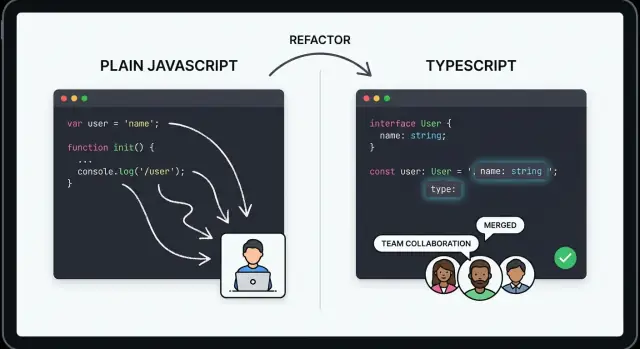
TypeScript 引入了类型、更完善的工具链与更安全的重构,帮助团队以更少的 bug 和更清晰的代码扩展 JavaScript 前端。
一个最初“只是几个页面”的前端,可能在不经意间成长为数千个文件、几十个功能区以及每天有多个团队同时发布变更的项目。到了这种规模,JavaScript 的灵活性不再感觉像自由,而更像不确定性。
在大型 JavaScript 应用中,许多错误不会在它们被引入的地方立刻显现。一个模块的小改动可能会破坏遥远的页面,因为它们之间的连接是非正式的:函数期望某种数据结构,组件假设某个 prop 总是存在,或者一个工具函数根据输入返回不同类型。
常见痛点包括:
可维护性不是一个模糊的“代码质量”分数。对团队来说,通常意味着:
TypeScript 是 JavaScript + 类型。它并不替代 Web 平台或要求新的运行时;它增加了一层在编译时描述数据形状和 API 契约的能力。
当然,TypeScript 并非魔法。它需要一些前期投入(定义类型、在动态模式下偶有摩擦)。但它在大型前端痛点最多的地方提供帮助:模块边界、共享工具、数据驱动的 UI,以及在“我觉得这样是安全的”需要变成“我知道这样是安全的”的重构场景。
TypeScript 并非取代 JavaScript,而是为团队多年来希望拥有的能力增加了一种方式:在不放弃现有语言和生态的前提下,描述代码“应该”接受和返回什么。
前端变成完整应用后,积累了更多可移动部件:大型单页应用、共享组件库、多个 API 集成、复杂的状态管理和构建流水线。在小型代码库中你可以“记在脑子里”。在大型代码库中,你需要更快的方式回答像:这份数据是什么形状?谁调用了这个函数?如果我改了这个 prop 会破坏什么?这类问题。
团队接受 TypeScript 的原因之一是它不要求从头重写。它能与 npm 包、熟悉的打包器和常见的测试配置协作,并最终编译成普通的 JavaScript。这使得它可以按增量方式引入,逐个仓库或文件夹推进。
“渐进式类型”意味着你可以在最有价值的地方添加类型,同时将其他区域暂时保持宽松。你可以从最小注解开始,允许 JavaScript 文件存在,并随着时间提升覆盖率——在第一天就获得更好的编辑器自动补全和更安全的重构,而不需要完美无缺。
大型前端实质上是很多小约定的集合:组件期望某些 props,函数期望某些参数,API 数据应具有可预测的形状。TypeScript 通过把这些约定变成类型来显式化它们——一种紧贴代码并随之演进的活契约。
类型告诉你:“你必须提供这个,会得到那个。”这同样适用于小工具和大型 UI 组件。
type User = { id: string; name: string };
function formatUser(user: User): string {
return `${user.name} (#${user.id})`;
}
type UserCardProps = { user: User; onSelect: (id: string) => void };
有了这些定义,任何调用 formatUser 或渲染 UserCard 的人都能立刻看到期望的形状,而无需阅读实现。对新成员而言,这大大提升了可读性,尤其是在他们还不知道“真正规则”在哪的时候。
在纯 JavaScript 中,像 user.nmae 这样的拼写错误或传入错误参数的情况经常会流到运行时,仅在该路径被执行时失败。用 TypeScript,编辑器和编译器会提前标记问题:
user.fullName,但对象只有 nameonSelect(user) 而不是 onSelect(user.id)这些错误看似微小,但在大型代码库中会带来数小时的调试和大量测试循环。
TypeScript 的检查发生在构建和编辑阶段。它可以在不执行任何代码的情况下告诉你“这个调用不符合契约”。
它不会在运行时验证数据。如果 API 返回了意外的内容,TypeScript 不会阻止服务器响应。相反,它帮助你编写基于明确形状的代码,并推动在真正需要时使用运行时验证。
结果是:边界更清晰了——契约以类型记录,类型不匹配能被早期发现,新贡献者可以在不猜测其他部分期望的情况下安全修改代码。
TypeScript 不仅仅是在构建时捕捉错误——它把编辑器变成了代码库的地图。当仓库增长到数百个组件与工具时,可维护性常常不是因为代码“错了”,而是因为人们无法快速回答简单问题:这个函数期望什么?在哪里被使用?如果我改了它会破坏什么?
TypeScript 的自动完成不只是方便。当你输入函数调用或组件 prop 时,编辑器能基于真实类型建议有效选项,而不是猜测。这意味着更少的搜索和更少的“它叫什么来着?”的时刻。
你还能看到内联文档:参数名、可选 vs 必需字段,以及 JSDoc 注释直接展示在工作区域。这在实践中减少了为了理解如何使用某段代码而打开额外文件的需要。
在大型仓库中,时间常常浪费在手动搜索上——grep、滚动、打开多个标签页。类型信息让导航功能更可靠:
这会改变日常工作方式:你不再需要把整个系统装在脑子里,而是可以沿着可靠的代码痕迹追踪。
类型让意图在审查时可见。一个添加了 userId: string 或返回 Promise<Result<Order, ApiError>> 的 diff,不需要过多注释就能传达约束和期望。
审查者可以把注意力放在行为和边界情形上,而不是争论某个值“应该”是什么。
许多团队使用 VS Code,因为它开箱即有很好的 TypeScript 支持,但你不需要特定编辑器来受益。任何能理解 TypeScript 的环境都可以提供相同类的导航与提示功能。
如果要把这些好处形式化,团队常会在 /blog/code-style-guidelines 中配合轻量约定,确保工具链在项目中保持一致性。
在没有类型系统的时代,重构大型前端常像在一屋子布满绊线的房间里行走:你可以改进某一处,但永远不知道两处之外会有什么爆炸。TypeScript 把许多高风险的修改变成可控的机械步骤。当你改变一个类型,编译器和编辑器会显示每一个依赖它的地方。
TypeScript 让重构更安全,因为它迫使代码库与所声明的“形状”保持一致。你不再依赖记忆或粗略搜索,而是得到精确的受影响调用点清单。
一些常见示例:
Button 之前接受 isPrimary,你把它改为 variant,TypeScript 会标记仍传 isPrimary 的组件。user.name 改为 user.fullName,类型更新会暴露应用中所有读取和假设的地方。最实用的好处是速度:改动后运行类型检查(或仅看 IDE)并把错误当作待办清单修复。你不需要猜测哪个视图会受影响——你修复编译器能证明不兼容的每一处。
TypeScript 并不能捕获所有 bug。它无法保证服务器确实发送了它承诺的数据,或者某个值不会在意外情况下为 null。用户输入、网络响应和第三方脚本仍然需要运行时验证和防御性的 UI 状态。
TypeScript 的胜利在于它消除了大量在重构期间的“意外破坏”,因此剩余的错误更常是关于真实行为的问题,而不是因为重命名遗漏引起的回归。
很多前端错误起源于 API:并非团队疏忽,而是因为真实的响应会随时间漂移:字段被添加、重命名、设为可选或暂时缺失。TypeScript 的作用是让数据的形状在每次交接处变得明确,因此端点的变化更可能以编译时错误显现,而不是生产异常。
当你为 API 响应添加类型(哪怕是粗略的),就强迫应用对“用户”、“订单”或“搜索结果”长什么样达成一致。这种清晰会迅速扩散:
一个常见模式是对数据进入应用的边界(fetch 层)进行类型化,然后把类型化的对象传递下去。
生产环境的 API 常包含:
null)TypeScript 会强迫你有意处理这些情况。如果 user.avatarUrl 可能缺失,UI 必须提供回退,或者映射层必须对其进行规范化。这会把“缺失时怎么办”的决策带入代码审查,而不是留给运气。
TypeScript 的检查发生在构建时,但 API 数据在运行时到达。这就是为什么运行时验证仍然有用——尤其是面对不可信或变化频繁的 API。一个实用的做法:
团队可以手写类型,也可以从 OpenAPI 或 GraphQL schema 生成类型。生成可以减少手动漂移,但不是强制性的——很多项目从少量手写响应类型开始,只有在带来回报时才采用生成。
TypeScript 在模块边界(函数输入/输出、组件 props、共享工具)处添加了编译时类型,把隐含的假设变成明确的契约。在大型代码库中,这会把“能跑”变成可强制检查的合同,在编辑/构建阶段捕获不匹配,而不是等到 QA 或生产环境才暴露。
不会。TypeScript 的类型在构建时被擦除,所以它本身不会验证 API 载荷、用户输入或第三方脚本的运行时行为。
建议:把 TypeScript 用作开发时的安全网,同时在数据不可信或需要可控失败处理的边界添加运行时验证(或在 UI 提供防御性状态)。
“活的契约”是指描述必须提供什么以及会返回什么的类型。
示例:
User、Order、Result)因为这些契约与代码紧密相邻并会被自动检查,它们比容易过时的文档更可靠。
它会捕获如下问题:
user.fullName,但实际上只有 name)这些是常见的“意外破坏”问题,否则通常只在特定路径被执行时才会显现。
类型信息让编辑器功能更准确:
这减少了为了解如何使用某段代码而在文件间反复查找的时间。
当你改变一个类型(比如 prop 名或响应模型)时,编译器可以指出所有不兼容的调用点。
一个实用的工作流程:
这会把许多重构变成可机械化、可追踪的步骤,而不是猜测性工作。
为你的 API 边界(fetch 层或客户端)添加类型,这样下游代码就能在可预测的形状上工作。
常见做法:
null/缺失字段映射为默认值)对于高风险端点,在边界层增加运行时验证,把经过验证的对象传播到应用其余部分。
带类型的 props 和 state 把假设变成显式约束,降低误用风险。
实际收益示例:
loading | error | success)这些都减少了依赖“隐式规则”的脆弱组件出现的概率。
常见的迁移策略是增量进行:
strict 等校验对于无类型依赖,可安装 包或在本地写小的声明,把 限制在适配层内。
现实的权衡包括:
避免的常见误区:把类型当成目标而不是工具。偏好可读的命名类型,用 unknown + 缩小来处理不可信数据,有限制地使用 any 或 @ts-expect-error 并注明何时移除。
@typesany