2025年9月06日·2 分钟
Vibe Coding 如何加速产品发现的构建—衡量—学习循环
了解 vibe coding 如何通过更快的原型、更紧的反馈与更智能的实验来缩短构建—衡量—学习循环,让团队更快发现可行想法。
了解 vibe coding 如何通过更快的原型、更紧的反馈与更智能的实验来缩短构建—衡量—学习循环,让团队更快发现可行想法。
产品发现本质上是一个学习问题:你要在投入数月时间构建错误的东西之前,弄清楚人们真正需要什么、会使用什么并愿意为啥买单。
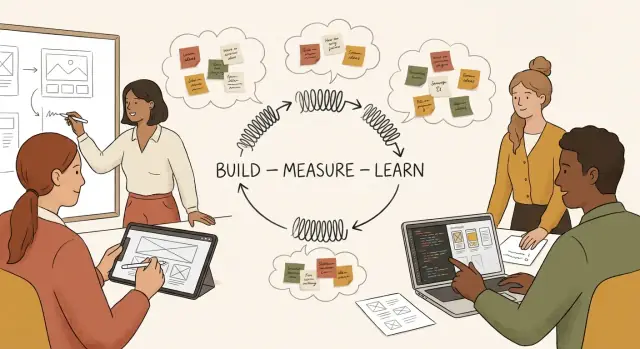
Build–Measure–Learn 是一个简单的循环:
目标不是“更快地构建”。而是缩短从问题到可靠答案的时间。
在产品语境里,vibe coding 指的是快速的探索性构建——通常结合 AI 辅助编码——把注意力放在表达意图(“做一个让用户能完成 X 的流程”)上,快速塑造成可用于测试的工作软件,给人一种足够真实的使用感。
它并不是把凌乱代码当作生产发布的做法。它是一种方式,用来:
只有在你仍然衡量正确的指标并对原型能证明的内容保持诚实时,vibe coding 才有帮助。速度有价值的前提是它在不削弱实验的情况下缩短循环时间。
接下来我们会把假设转成本周能执行的实验,构建能产生可靠信号的原型,添加轻量的测量,并在不自欺的情况下更快地做决策。
产品发现很少因为团队没有想法而失败。它变慢是因为从“我们认为这可能有效”到“我们知道了”这段路充满摩擦——很多摩擦在计划工作时看不见。
即便是简单的实验也会被设置时间卡住。需要新建仓库、配置环境、争论分析方案、申请权限、修复流水线。一天的测试悄悄变成两周,因为头几天只是用来达到“hello world”。
接着是过度工程。团队常常把发现原型当作生产特性来对待:干净的架构、边缘情况处理、完整的设计打磨和重构“以免后悔”。但发现工作是为减少不确定性而存在的,不是为了交付完美系统。
利益相关方的等待也是另一个杀环节。反馈周期依赖于审阅、批准、法律检查、品牌批准或只是约到某人开会。每一次等待都增加数日,实验的原始问题会随着更多人提出新偏好而被稀释。
当测试一个假设需要数周时,团队无法依赖新鲜证据。决策来自记忆、内部争论和最响亮的观点:
这些说法并非全错,但它们替代了直接的信号。
慢速发现的真实代价不仅仅是速度。它是每月丧失的学习量。市场在移动,竞争者在上线,客户需求在变化,而你还在准备运行测试。
团队也在消耗精力。工程师感觉自己在做忙碌的工作。产品经理被困在协商流程而不是发现价值上。动量下降,最终人们因为“我们永远做不成”而停止提实验。
仅仅追求速度不是目标。目标是缩短从假设到证据的时间,同时保持实验足够可信以指导决策。这正是 vibe coding 的价值所在:减少设置与构建摩擦,让团队能够运行更多小而集中的测试——更早学习——而不是把发现变成猜测。
Vibe coding 通过把“我们认为这可能有效”快速变成可点击、可用、可反应的东西,来压缩 Build–Measure–Learn 循环。目标不是更快地交付完美产品,而是更早得到可靠信号。
大多数发现周期变慢并不是因为团队不能写代码——而是因为代码之外的一切。Vibe coding 在几个可复用的环节去除摩擦:
传统计划经常试图在构建前减少不确定性。Vibe coding 则反其道而行:构建一个小产物通过使用来减少不确定性。与其在会议中争论边缘情况,不如创建一个狭窄的切片来回答一个问题——然后让证据驱动下一步。
压缩循环在以下条件下效果最好:
之前: 1 天范围定义 + 2 天设置/UI + 2 天集成 + 1 天 QA = ~6 天 学到“用户不理解第 2 步”。
使用 vibe coding 之后: 45 分钟脚手架 + 90 分钟组装关键界面 + 60 分钟模拟集成 + 30 分钟基础埋点 = ~4 小时 学到同样的事——并且当天再次迭代。
当你的目标是学习而非完美时,vibe coding 最有用。如果你要做的决策仍不确定——“人们会用吗?”“他们理解吗?”“会付费吗?”——那么速度与灵活性比打磨更重要。
适合用 vibe-coded 实验的场景举例:
这些通常易于范围限定、易于衡量且易于回退。
当错误代价高或不可逆时,vibe coding 并不合适:
在这些情况下,将 AI 辅助的速度作为补充,而不是主要驱动力。
在开始之前回答四个问题:
如果风险低、可逆性高、依赖最小并且受众可以限制,vibe coding 通常是合适的。
薄切片不是假演示——它是一个狭窄的端到端体验。
示例:不要“构建整个入职流程”,而是只做首屏 + 一个引导动作 + 一个清晰的成功态。用户能完成有意义的事,你可以在不承诺全部构建的情况下获得可靠信号。
快速迭代只有在你在学习具体东西时才有意义。最容易浪费一周 vibe coding 的方式是“改进产品”但不定义你想证实或否定的内容。
选一个一旦答案改变就会改变你下一步的单一问题。保持行为化和具体,而非哲学化。
示例:比起“用户是否喜欢入职?”,问“用户会完成第 2 步吗?”更好,因它指向流程中可衡量的时刻。
把假设写成几天内可检验的声明:
注意,假说包括谁、什么动作和阈值。这个阈值防止你把任何结果都解读为成功。
vibe coding 在你画出严格的范围边界时最有用。
决定为了最快学习你要构建什么(原型范围边界):
如果实验关于第 2 步,就不要去“清理”第 5 步。
选一个时限和“停止条件”以避免无休止的打磨。
例如:“两下午构建,一天运行 8 个会话。如果连续 6 个用户在同一点失败则提前停止。”这让你有权限快速学习并继续,而不是通过打磨来推迟决策。
速度只有在原型能产生你信任的信号时才有用。Build 阶段的目标不是“交付”,而是创建一个可信的体验切片,让用户尝试核心的待办事——而不需数周工程。
vibe coding 在你组装而非精雕细琢时效果最好。复用一小套组件(按钮、表单、表格、空状态)、页面模板和熟悉的布局。保留一个“原型起手仓库”,其中已经包含导航、认证桩和基础设计系统。
数据方面,有目的地使用模拟数据:
让关键路径真实;把其余部分维持为可信的模拟:
如果你无法衡量它,就会争论它。从一开始就加上轻量埋点:
事件命名保持通俗易懂,便于所有人阅读。
测验的有效性取决于用户是否理解该做什么。
既快速又易懂的原型会给你更干净的反馈,减少误报的负面结果。
快速构建只有在你能快速且可信地判断原型是否把你更接近真相时才有价值。对 vibe coding 而言,衡量应像构建一样轻量:足够用于决策,而不是全面的分析系统。
根据要回答的问题匹配方法:
对于发现,选择 1–2 个与行为相关的主要结果:
同时加上护栏以免“胜利”建立在破坏信任上的结果:如支持工单增加、退款率上升或核心任务完成率下降。
早期发现关乎方向而非统计确定性。少量会话能暴露主要 UX 问题;几十份点击测试响应能澄清偏好。把严格的功效计算留给优化阶段(高流量流程上的 A/B 测试)。
页面浏览、停留时长和“点赞”可能看起来很好,但用户可能并未完成任务。优先反映结果的指标:任务完成、激活账户、留存使用和可重复的价值。
速度只有在能带来清晰选择时才有用。"学习" 步骤是 vibe coding 可能出问题的地方:你可能构建并上线得太快,以至于把活动误认为洞见。解决办法很简单——标准化你总结发生情况的方式,并从模式而非个案做决策。
每次测试后,把信号汇总成简短的“我们观察到”的记录。寻找:
尽量把每个观察标记为频率(发生多少次)和严重性(对推进的阻碍程度)。一句有代表性的引用有帮助,但模式才会支撑决策。
使用一套小规则,避免每次都重新谈判:
保持一个持续的日志(每个实验一行):
Hypothesis → Result → Decision
示例:
如果你想要一个模板让这个流程更可执行,把它加到团队的检查清单里在 /blog/a-simple-playbook-to-start-compressing-your-loop-now。
速度只有在你学到正确的东西时有用。vibe coding 可以把你的周期压得很短,以至于你容易交付“答案”但这些答案实际上是由你如何提问、问了谁或先构建了什么决定的产物。
一些常见陷阱:
快速迭代可能在两方面悄悄降低质量:你会积累隐藏技术债务(以后难改)和接受薄弱证据(“对我有效”变成“有效”)。风险不在于原型丑陋——而在于你的决策基于噪音。
让循环保持快,但在“衡量”和“学习”阶段设置护栏:
明确告知:告诉用户什么是原型、会收集什么数据、接下来会发生什么。把风险降到最低(非必要时不要收集敏感数据),提供简单的退出方式,避免使用促使用户“成功”的黑暗模式。快速学习不是惊讶用户的借口。
当团队把它当作有协调的实验而不是个人的速度竞赛时,vibe coding 最奏效。目标是一起快速前进,同时保护那些不能“后来补救”的关键事项。
先指定核心部分的负责人:
这种分工让实验保持聚焦:PM 保护“为什么”,设计师保护“用户体验是什么”,工程师保护“如何运行”。
快速迭代仍需一个简短且不可妥协的检查表。要求审查的项目:
其他内容可以在发现循环中“足够好”。
运行 发现冲刺(2–5 天),并固定两项例行:
当利益相关方能看到进展时更易达成一致。分享:
具体产物减少意见之争——并让“速度”变得值得信任。
当你的技术栈使“构建、对少数人上线、学习”成为默认路径而非特殊项目时,vibe coding 最为轻松可行。
一个实用的基础栈看起来像:
exp_signup_started)。只追踪能回答假设的事件。如果你有 AI 辅助的构建工作流,工具要支持快速脚手架、迭代变更和安全回滚会很有帮助。例如,Koder.ai 是一个 vibe‑coding 平台,团队可以通过聊天界面创建 web、后端和移动原型——当你想从假设快速变到可测试的 React 流并在不花几天做设置的情况下迭代时,这类工具很实用。快照/回滚和规划模式等功能也能让并行快速实验更安全。
在实验开始时就决定这条路走向:
在启动时明确决定,并在首次学习里程碑后复查。
在实验票旁放一份简短清单:
可见性胜过完美:团队保持快速,同时后续没人会被惊讶。
这是一个可复制的 7–14 天循环,你可以用 vibe coding(AI 辅助 + 快速原型)把不确定想法变成明确决策。
第 1 天 — 框定赌注(学习 → 构建启动): 选一个如果错了就让这个想法不值得推进的假设。写下假说与成功指标。
第 2–4 天 — 构建可测试原型(构建): 交付能产生真实信号的最小体验:可点击流程、假门或薄的端到端切片。
检查点(第 4 天结束): 用户能在 2 分钟内完成核心任务吗?如果不能,缩减范围。
第 5–7 天 — 埋点 + 招募(测量设置): 只添加你会用到的事件,随后运行 5–10 个会话或小规模的产品内测试。
检查点(第 7 天结束): 你有可信数据和可引用的笔记吗?如果没有,先修复测量再继续构建。
第 8–10 天(可选) — 迭代一次: 针对最大流失或困惑点做一次有针对性的改动。
第 11–14 天 — 决策(学习): 选择:推进、转向或停止。记录所学和下次要测试的内容。
Hypothesis statement
We believe that [target user] who [context] will [do desired action]
when we provide [solution], because [reason].
We will know this is true when [metric] reaches [threshold] within [timeframe].
Metric table
Primary metric: ________ (decision driver)
Guardrail metric(s): ________ (avoid harm)
Leading indicator(s): ________ (early signal)
Data source: ________ (events/interviews/logs)
Success threshold: ________
Experiment brief
Assumption under test:
Prototype scope (what’s in / out):
Audience + sample size:
How we’ll run it (sessions / in-product / survey):
Risks + mitigations:
Decision rule (what we do if we win/lose):
(以上代码块为原样模板,便于复制粘贴。)
先 随意起步(一次性原型)→ 变得 可复现(相同的 7–14 天节奏)→ 达到 可靠(标准化指标 + 决策规则)→ 抵达 系统化(共享的假设积压、每周复盘与实验库)。
现在选 一个 假设,填写假设模板,并安排第 4 天的检查点。本周运行 一个 实验——然后让结果(而非兴奋)决定你接下来构建什么。
这是一种快速、探索性的构建方式——通常借助 AI 帮助——目标是尽快创建一个可测试的产物(薄的端到端切片、fake‑door 或可点击流程)。重点是将 问题 → 证据 的时间缩短,而不是把凌乱的生产代码投入线上。
这个循环是:
目标是在不削弱实验可信度的前提下缩短循环时间。
因为阻碍往往在代码之外:
快速原型通过减少这些摩擦,让团队能更快地运行更多小规模测试。
通过在可重复发生的任务上节省时间:
这样可以把多天的循环压缩到几个小时,让你当天就能学习并迭代。
当风险低且学习收益高时适用,例如:
这些通常易于范围限定、易于衡量并且容易回退。
当失败代价高或难以恢复时应避免或严格约束:
在这些场景下,速度可以作为辅助,但不应成为主要驱动因素。
把假设写成可以在几天内检验的语句:
示例:“至少 10 个首次到达连接页面的用户中有 4 个会在 60 秒内点击 ‘Connect’。”
画清界限:
目标是一个成功路径加上一个常见失败态即可产出可靠信号。
从一开始就添加轻量可观测性:
事件命名要直白,埋点只围绕能回答假设的内容,避免越埋越慢且仍然争论结果。
使用一致的决策规则并保留简单日志:
把每次实验记录为 Hypothesis → Result → Decision,避免事后篡改历史。