2025年10月03日·1 分钟
外部数据与内部数据 — Pat Helland 关于应用的教训
学习 Pat Helland 的“外部与内部数据”思想:划清边界、设计幂等调用,并在网络故障时对状态进行对账。
学习 Pat Helland 的“外部与内部数据”思想:划清边界、设计幂等调用,并在网络故障时对状态进行对账。
当你构建一个应用时,很容易想象请求整齐地、按顺序到达。真实的网络并不是这样。用户因为界面卡住而点了两次“支付”。移动网络在按钮点击后断开连接。一个 webhook 晚到或到达两次。有时它甚至永远不会到达。
Pat Helland 的 外部数据 vs 内部数据 思路是理解这类混乱的清晰方法。
“外部”是你系统无法控制的一切。它指你与他人和其他系统交互的地方,以及交付不可靠的场景:来自浏览器和移动应用的 HTTP 请求、队列消息、第三方 webhook(支付、邮件、物流)以及由客户端、代理或后台任务触发的重试。
对于外部,要假设消息可能延迟、重复或乱序到达。即便某个环节“通常可靠”,也要为它失效的一天做设计。
“内部”是你可以让其可靠的部分。它是你存储的持久状态、你强制执行的规则,以及你日后能证明的事实:
一个订单只能被支付一次)内部是你保护不变量的地方。如果你承诺“每个订单只收一次款”,那承诺必须在内部被强制执行,因为外部不能被信任。
思维方式的转换很简单:不要假设完美的交付或完美的时序。把每次外部交互当作不可靠的建议,可能会重复出现,让内部以安全的方式响应。
这对小团队和简单应用也很重要。第一次因网络故障导致重复扣款或卡住的订单时,这就不再是理论,而是退费、支持工单和信任的损失。
一个具体例子:用户点“下单”,应用发送请求,但连接中断。用户再次尝试。如果你的内部无法识别“这是同一次尝试”,你可能会创建两个订单、重复保留库存或发送两封确认邮件。
Helland 的观点直接:外部世界不确定,但系统内部必须保持一致。网络会丢包、手机会断线、时钟会漂移、用户会刷新。你的应用无法控制这些,但能控制的是一旦数据越过清晰边界后你接受为“真实”的内容。
想象有人在信号差的建筑里用手机点咖啡。他点“支付”。转圈加载。网络断了。他又点了一次。
也许第一个请求到达了服务器,但响应没回到客户端;也可能两个请求都没到。从用户视角,两种可能看起来一样。
这就是时间与不确定性:你还不知道发生了什么,可能稍后才知道。系统在等待时需要做出合理的行为。
一旦接受外部不可靠,一些“奇怪”的行为就变得正常:
外部数据是一个声明,而非事实。“我已付款”只是通过不可靠通道发送的一条陈述。只有当你在系统内部以持久、一致的方式记录它时,它才成为事实。
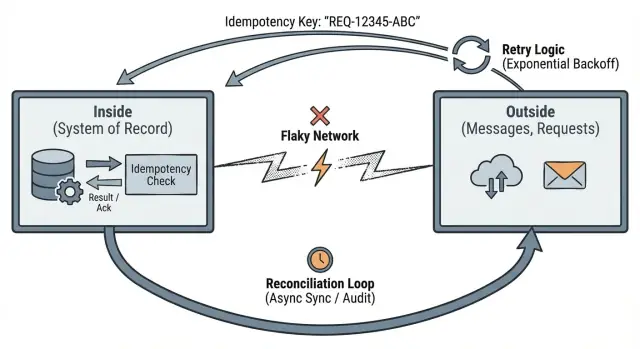
这会推动你养成三种实用习惯:划清边界、用幂等性让重试安全、并在现实不一致时进行对账。
“外部 vs 内部”从一个实用问题开始:你的系统的真实从哪里开始、在哪里结束?
在边界内部,你可以给出强有力的保证,因为你控制数据和规则。边界之外,你做尽力而为,假设消息可能丢失、重复、延迟或乱序到达。
在真实应用里,这个边界通常出现在:
一旦画出那条线,决定哪些不变量在内部是不可妥协的。例子:
order ID 在数据库中是唯一的。边界也需要对“我们处于哪个阶段”有明确定义。很多失败发生在“我们听到了你”与“我们完成了它”之间。一个有用的模式是区分三种含义:
当团队跳过这些区分时,就会出现只在高负载或局部故障下才出现的 bug。一个系统把“paid”当作钱被扣;另一个把它当作支付尝试开始。这种不匹配会产生重复、卡住的订单以及无法重现的支持问题。
幂等性意味着:如果相同的请求被发送两次,系统把它当作一次请求并返回相同的结果。
重试是正常的。超时会发生。客户端会重复自己。如果外部会重复,你的内部必须把它转成稳定的状态变更。
一个简单例子:移动应用发送“支付 $20”,连接断开。应用重试。没有幂等性,客户可能被重复扣款;有幂等性,第二次请求返回第一次的结果。
大多数团队使用以下模式之一(有时混合):
Idempotency-Key: ...)。服务器记录该键和最终响应。当重复请求到达时,最合适的行为通常不是返回 409 或通用错误,而是返回第一次的相同结果,包括相同的资源 ID 和状态。这样客户端和后台任务的重试才是安全的。
幂等记录必须存放在你边界内部的持久存储中,而不是内存里。如果 API 重启后忘记这些记录,安全保证就不存在了。
保存时间应足够覆盖现实的重试和延迟交付。窗口取决于业务风险:低风险创建操作为分钟到小时,支付/邮件/发货等高成本操作为几天,若合作方重试时间更长则更长。
分布式事务听起来令人安心:一次跨服务、队列和数据库的大提交。但实际上它们常常不可用、缓慢或太脆弱而无法依赖。一旦涉及网络跳数,你不能假设所有东西会一起提交。
一个常见陷阱是构建一个仅在每步都立即成功时才工作的工作流:保存订单、扣款、保留库存、发送确认。如果第 3 步超时,它是失败还是成功?如果你重试,会不会重复扣款或重复保留?
两种实用方法可以避免这类问题:
为每个工作流选定一种风格并坚持使用。混合使用“有时使用 outbox,有时假设同步成功”会制造难以测试的边缘情况。
一个简单规则:如果你不能在边界间原子提交,就为重试、重复和延迟而设计。
对账承认一个基本事实:当你的应用通过网络与其他系统通信时,偶尔会对发生的事情存在分歧。请求超时、回调晚到、用户重试。对账是你检测不一致并随时间修复它的方法。
把外部系统当作独立的真实来源。你的应用保留自己的内部记录,但需要一种比较那些记录与合作方、提供方和用户实际行为的方法。
大多数团队使用一小套“无聊但有效”的工具:重试待处理操作并重新检查外部状态的工作器、定期扫描不一致的计划任务,以及供支持使用的少量人工修复操作(重试、取消或标记为已审查)。
对账只有在你知道比较对象时才有效:内部账本 vs 提供方账本(支付)、订单状态 vs 发货状态(履约)、订阅状态 vs 计费状态。
使状态可修复。不要直接从“created”跳到“completed”,使用像 pending、on hold 或 needs review 这样的暂存状态。这能让你安全地表示“我们还不确定”,并给对账一个明确的落点。
在重要变更上捕获小型审计轨迹:
例如:如果你的应用请求了运输标签但网络中断,你的内部可能显示“无标签”而承运人实际上已经创建了标签。对账工作器可以按关联 ID 搜索,发现标签存在并推进订单(或在细节不匹配时标记为需审查)。
一旦默认网络会失败,目标改变:你不是尝试让每一步一次就成功,而是尝试让每一步安全地可重复并易于修复。
写一句话的边界声明。明确你的系统拥有什么(真相来源)、你镜像了什么以及你仅向他方请求了什么。
在快乐路径之前列出失败模式。至少包括:超时(你不知道是否成功)、重复请求、部分成功(一步发生了,下一步没有)和乱序事件。
为每个输入选择幂等性策略。对于同步 API,通常是幂等键加上存储的结果;对于消息/事件,通常是唯一消息 ID 和“我是否已处理它?”记录。
持久化意图,然后行动。先保存像 PaymentAttempt: pending 或 ShipmentRequest: queued 之类的持久记录,再调用外部,随后记录结果。返回一个稳定的引用 ID,让重试指向相同意图而不是创建新意图。
构建对账与修复路径,并使其可见。对账可以是扫描“待处理过久”的作业并重新检查状态。修复路径可以是安全的管理操作,如“重试”、“取消”或“标记为已解决”,并附带审计说明。添加基础可观测性:关联 ID、清晰的状态字段和一些计数(待处理、重试、失败)。
例如:如果结账在你调用支付提供方后超时,不要猜测。保存尝试并返回尝试 ID,让用户用相同的幂等键重试。稍后对账可以确认提供方是否已扣款并在不重复扣款的前提下更新尝试记录。
客户点“下单”。你的服务向提供方发送支付请求,但网络不稳定。提供方有自己的真实记录,你的数据库有你自己的。这两者会漂移,除非你为此设计。
从你的角度看,外部是一串可能迟到、重复或缺失的消息:
这些步骤都不保证“恰好一次”。它们只保证“可能”。
在你的边界内部,存储持久事实以及将外部事件与这些事实连接所需的最小信息。
当客户首次下单时,创建一个状态清晰的 order 记录,例如 pending_payment。同时创建一个带有唯一提供方引用和与客户动作绑定的 idempotency_key 的 payment_attempt 记录。
若客户端超时并重试,你的 API 不应创建第二个订单。它应查找 idempotency_key 并返回相同的 order_id 与当前状态。这个选择能防止网络故障时的重复。
当 webhook 到达两次时,第一次回调将 payment_attempt 更新为 authorized 并将订单转为 paid。第二次回调进入相同处理器,但你检测到已处理该提供方事件(通过存储提供方事件 ID 或检查当前状态),于是不再做任何操作。仍可返回 200 OK,因为结果已为真。
最后,对账处理更混乱的情况。如果订单在延迟后仍为 pending_payment,后台任务可使用存储的引用查询提供方。如果提供方返回“authorized”而你错过了 webhook,你更新记录;如果提供方说“failed”但你标记为已支付,你将其标记为需审查或触发补偿行动如退款。
大多数重复记录和“卡住”的工作流来自于将外部发生的事情(请求到达、消息被接收)与你在系统内部安全提交的事实混淆。
经典失败案例:客户端发送“下单”,服务器开始工作,网络断开,客户端重试。如果你把每次重试都当作全新的事实,就会出现重复扣款、重复订单或多封邮件。
常见原因:
一个问题会让一切更糟:没有审计轨迹。如果你覆盖字段且只保留最新状态,就会失去后来对账所需的证据。
一个好的自检问题是:“如果我两次运行这个处理器,会得到相同结果吗?”如果答案是否定的,那么重复不是罕见的边缘情况,而是必然会发生的事。
如果只记住一件事:即使消息迟到、到达两次或根本未到达,你的应用也必须保持正确。
使用此清单在问题变成重复记录、缺失更新或卡死工作流之前发现薄弱环节:
如果不能对其中某项迅速回答,那通常说明边界模糊或状态转换缺失。
实用的下一步:
先绘制边界和状态。为每个工作流定义一小组状态(例如:Created、PaymentPending、Paid、FulfillmentPending、Completed、Failed)。
在最重要处添加幂等性。先从高风险写入开始:创建订单、扣款、发起退款。在 PostgreSQL 中将幂等键存为有唯一约束的列以安全拒绝重复。
把对账当作常规功能。定期任务扫描“待处理过久”的记录,检查外部系统并修复本地状态。
安全迭代。调整转换与重试规则,然后通过刻意重发同一请求和重复处理同一事件进行测试。
如果你在像 Koder.ai (koder.ai) 这样的聊天驱动平台上快速构建,仍应尽早把这些规则融入你的生成服务:速度来自自动化,但可靠性来自清晰边界、幂等处理器与对账。
"外部" 是你无法控制的一切:浏览器、移动网络、队列、第三方 webhook、重试和超时。假设消息可能被延迟、重复、丢失或乱序到达。
"内部" 是你能控制的:你存储的状态、你执行的规则,以及你以后可以证明的事实(通常在你的数据库中)。
因为网络会“说谎”。
客户端超时并不意味着你的服务器没有处理该请求。Webhook 重复到达也不意味着提供方执行了两次相同的操作。如果你把每条消息都当作“新的事实”,就会产生重复订单、重复收费和卡住的工作流。
边界是指不可靠消息变为持久事实的那一点。
常见的边界包括:
一旦数据越过边界,你就在内部强制不变量(例如“订单只能被支付一次”)。
使用幂等性。原则是:同一个意图如果被发送多次,系统应产生相同的结果。
实用模式:
不要只放在内存中。将幂等记录存放在你的边界内的持久存储中(例如 PostgreSQL),这样重启不会丢失保护。
保留时间的经验法则:
保留时间应覆盖现实的重试与延迟回调窗口。
使用能承认不确定性的状态。
一个简单实用的集合:
pending_*(我们接受了意图,但还不知道结果)succeeded / failed(我们记录了最终结果)needs_review(检测到不匹配,需要人工或特殊任务处理)这样可以避免超时时的猜测,并让对账更容易落位。
因为你无法在跨网络的多个系统间做原子提交。
如果同步执行“保存订单 → 收款 → 保留库存”,当某步超时时你不知道它是成功还是失败。重试可能导致重复,放弃重试又可能留下未完成的工作。
为部分成功而设计:先持久化意图,再执行外部操作,最后记录结果。
outbox/inbox 模式在不指望网络完美的情况下,使跨系统消息可靠:
对账是在你的记录与外部系统不一致时的恢复手段。
良好默认做法:
needs_review对付款、履约、订阅或任何有 webhook 的场景,这不是可选项。
重要且依然适用。快速开发并不能消除网络故障——它只是让你更早遇到这些问题。
如果你用 Koder.ai (koder.ai) 自动生成服务,尽早把这些默认做法写入生成规则:
这样,重试与重复回调会变得平淡而可管理,而不是昂贵的故障。