2025年11月12日·2 分钟
为 AI 爬虫与 LLM 索引准备就绪的网站构建指南
了解如何组织内容、元数据、抓取规则与性能,使 AI 爬虫与 LLM 工具能够可靠地发现、解析并引用你的页面。
了解如何组织内容、元数据、抓取规则与性能,使 AI 爬虫与 LLM 工具能够可靠地发现、解析并引用你的页面。
“AI 优化”常被当作噱头,但在实际操作中,它意味着你的网站便于自动化系统发现、读取并被准确复用。
当人们说到AI 爬虫时,通常指的是由搜索引擎、AI 产品或数据提供方运行的机器人,这些机器人抓取网页以支持摘要、回答、训练数据集或检索系统等功能。LLM 索引通常指将页面转为可检索的知识库(通常是带元数据的“切片”文本),以便 AI 助手可以检索到正确段落并引用或引用它。
AI 优化少的是“排名”,多的是四个结果:
没有人能保证收录到特定的 AI 索引或模型。不同提供者的抓取方式不同、遵循的策略不同、刷新频率也不同。
你能做的是让内容易于访问、提取与归属——这样一旦被使用,就会被正确使用。
llms.txt 文件来引导面向 LLM 的发现如果你快速构建新页面与流程,选择不与这些需求对抗的工具会很有帮助。例如使用 Koder.ai 的团队通常会将 SSR/SSG 友好的模板、稳定路由和一致的元数据作为默认,这样“AI 就绪”就是内建,而不是事后补救。
LLM 与 AI 爬虫并不像人那样解释页面。它们提取文本、推断概念间关系,并尝试将页面映射为单一清晰的意图。你结构越可预测,模型需要做的错误假设就越少。
先让页面在纯文本下易于扫描:
一个有用的模式是:承诺 → 摘要 → 说明 → 论证 → 下一步。
在顶部放一段短摘要(2–5 行)。这能帮助 AI 系统快速分类页面并捕捉关键断言。
示例 TL;DR:
TL;DR: 本文说明如何组织内容,以便 AI 爬虫能可靠提取主题、定义与关键结论。
LLM 索引在每个 URL 回答一个意图时效果最好。如果你在同一页混合无关目标(例如把“定价”“集成文档”和“公司历史”放一起),页面就会更难分类,可能在错误的查询中出现。
若需涵盖相关但不同的意图,把它们拆到独立页面并用内部链接连接(例如 /pricing、/docs/integrations)。
如果受众可能对一个术语有多种解读,请在早处定义它。
示例:
AI 爬虫优化: 准备站点内容与访问规则,使自动化系统能可靠地发现、读取并解释页面。
为每个产品、功能、套餐和关键概念选一个名称并全站统一使用。命名一致能改善抽取(“Feature X”始终指同一事物),并在模型摘要或比较页面时减少实体混淆。
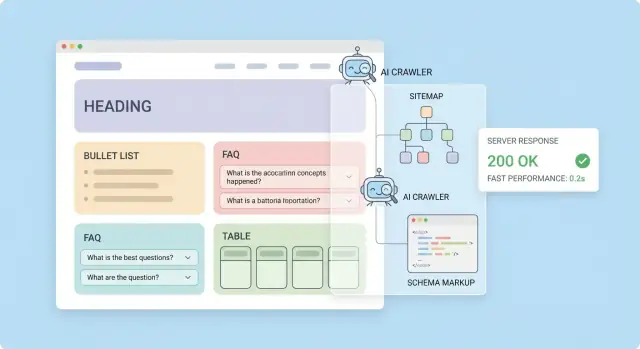
大多数 AI 索引流程会把页面切成片段并在后续检索时存取最佳匹配部分。你的任务是让这些片段显而易见、自成一体并便于引用。
每页保留一个 H1(页面的承诺),用 H2 表示用户可能搜索的主要章节,用 H3 表示子话题。
一个简单规则:如果你能把 H2 做成描述整页内容的目录,你就做对了。该结构帮助检索系统为每个片段附上正确上下文。
避免模糊的标签如“概览”或“更多信息”。让标题直接回答用户意图:
当片段被抽出上下文时,标题往往成为它的“标题”。让它有意义。
使用短段落(1–3 句)以提高可读性并让切片更聚焦。
项目符号列表适合列出需求、步骤与功能亮点。表格适合比较,因为它保留了结构。
| Plan | Best for | Key limit |
|---|---|---|
| Starter | Trying it out | 1 project |
| Team | Collaboration | 10 projects |
一个小型 FAQ 区块与直接、完整的回答能提升可抽取性:
Q: 你支持 CSV 上传吗?
A: 支持——单文件 CSV 最大 50 MB。
在关键页面末尾放导航模块,让用户和爬虫都能沿意图路径继续:
并非所有 AI 爬虫都像完整浏览器那样工作。许多能立即获取并读取原始 HTML,但难以(或直接跳过)执行 JavaScript、等待 API 调用和在水合后组装页面。如果你的关键内容仅在客户端渲染后出现,就有被做 LLM 索引的风险。
对于传统 HTML 页面,爬虫下载文档即可提取标题、段落、链接与元数据。
对于依赖 JS 的页面,首个响应可能只是一个薄壳(少量 div 与脚本)。有意义的文本只有在脚本运行、数据加载并组件渲染后出现。覆盖率下降的原因正是在这一步:一些爬虫不会执行脚本;另一些执行但有超时或只执行部分。
对于你希望被索引的页面——产品描述、定价、FAQ、文档——优先考虑:
目标不是“完全不使用 JavaScript”,而是先有有意义的 HTML,再用 JS 增强。
选项卡、手风琴和“阅读更多”控件没问题,前提是文本在 DOM 中。问题出现在选项卡内容仅在点击后通过请求加载或注入时。如果该内容对 AI 发现很重要,请把它包含在初始 HTML 中,并用 CSS/ARIA 控制可见性。
用下面两个检查:
如果你的标题、主要文本、内部链接或 FAQ 只在 Inspect Element 中出现而不在 View Source 中,请把这些内容转为服务器渲染的输出。
AI 爬虫与传统搜索机器人都需要清晰、一致的访问规则。如果你意外阻止了重要内容,或者允许爬虫进入私有/凌乱区域,会浪费抓取预算并污染被索引的内容。
用 robots.txt 定义宽泛规则:哪些目录或 URL 模式应该抓取或避免。
一个实用基线:
/admin/、/account/、内部搜索结果或产生无穷组合的参数 URL 等非公开区域。示例:
User-agent: *
Disallow: /admin/
Disallow: /account/
Disallow: /internal-search/
Sitemap: /sitemap.xml
重要:用 robots.txt 阻止抓取会阻止爬虫获取页面,但如果该 URL 被其他地方引用,页面仍可能出现在索引中。要控制索引,使用页面级指令。
在 HTML 页面中使用 meta name="robots",并对非 HTML 文件(PDF、feeds、导出文件)使用 X-Robots-Tag 头部。
常见模式:
noindex,follow,这样链接可以传递但页面本身不会被收录。noindex——应使用认证保护,并考虑同时禁止抓取。noindex 并辅以正确的规范化(稍后涵盖)。按环境记录并强制执行规则:
noindex(基于头部最简单)以避免意外被索引。如果访问控制影响用户数据,确保对外政策与实际行为一致(参见 /privacy 与 /terms 在相关场景下)。
若希望 AI 系统(及搜索爬虫)可靠地理解并引用你的页面,就需减少“相同内容、多 URL”的情况。重复会浪费抓取预算、分散信号,并可能导致错误版本被索引或引用。
目标是让 URL 保持多年有效。避免在可索引 URL 中暴露不必要的参数,如会话 ID、排序选项或跟踪代码(例如:?utm_source=...、?sort=price、?ref=)。如果参数对功能是必须的(筛选、分页、站内搜索),确保“主”版本仍通过稳定、干净的 URL 可访问。
稳定的 URL 提升长期引用可靠性:当 LLM 学习或存储引用时,如果你的 URL 结构在每次重设计时都改变,引用就很容易失效。
在预期会出现重复的页面上加入 \u003clink rel=\"canonical\"\u003e:
规范标签应指向首选的、可索引的 URL(且该规范 URL 最好返回 200)。
页面永久移动时使用 301 重定向。避免重定向链(A → B → C)和循环;它们会拖慢爬虫并导致部分索引。直接把旧 URL 重定向到最终目标,并在 HTTP/HTTPS 与 www/non-www 间保持一致的重定向策略。
仅在确有本地化等效页面时实现 hreflang(不是只是翻译片段)。错误的 hreflang 会造成关于哪个页面应被引用的混淆。
站点地图与内部链接是你“发现交付系统”:它们告诉爬虫什么存在、什么重要、什么应该被忽略。对于 AI 爬虫与 LLM 索引,目标很简单——让你最干净、最重要的 URL 易找且难漏。
站点地图只应包含可索引的规范 URL。如果页面被 robots.txt 阻止、标注为 noindex、被重定向或不是规范版本,就不应出现在站点地图中。这能让爬虫预算集中并减少 LLM 获取重复或过时版本的概率。
保持 URL 格式一致(尾部斜杠、小写、HTTPS),让站点地图镜像你的规范规则。
若 URL 很多,把它们拆成多个站点地图文件(常见限制:每文件 50,000 个 URL)并发布一个站点地图索引列出每个站点地图。按内容类型组织有助于维护,例如:
/sitemaps/pages.xml/sitemaps/blog.xml/sitemaps/docs.xml这让维护更容易,也便于监控发现情况。
谨慎更新 lastmod——只在页面有实质性变化时(内容、价格、策略、关键元数据)更新。如果每次部署都更新,爬虫会学着忽略该字段,而真正重要的更新反而可能被延后访问。
强有力的 hub-and-spoke 结构同时利于用户与机器。创建 hub(分类页、产品页或主题页)链接到最重要的 spoke 页面,并确保每个 spoke 能链接回 hub。在正文中添加上下文链接,而不是仅靠菜单。
如果你发布教育性内容,保持主要入口明显——将文章聚合在 /blog,将深入参考材料放在 /docs。
结构化数据是以机器能可靠读取的格式标注页面“是什么”(文章、产品、FAQ、组织)。搜索引擎与 AI 系统可以直接解析这些标注,而不必去猜哪个文本是标题、谁是作者或主要实体是什么。
使用与内容匹配的 Schema.org 类型:
每页选一个主要类型,然后添加辅助属性(例如 Article 可以引用 Organization 作为发布者)。
爬虫与搜索引擎会比对结构化数据与页面可见内容。如果你的标记声称有 FAQ 但页面上并未显示,或列出一个未展示的作者名,会造成混淆并有被忽略的风险。对于内容页面,若真实可用,请包含作者以及 datePublished 与 dateModified。这让时效性与问责更清晰——LLM 在判断信任时经常关注这些要素。
若有官方资料页,向 Organization schema 添加 sameAs 链接(例如公司经认证的社交资料)。
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Build a Website Ready for AI Crawlers and LLM Indexing",
"author": { "@type": "Person", "name": "Jane Doe" },
"datePublished": "2025-01-10",
"dateModified": "2025-02-02",
"publisher": {
"@type": "Organization",
"name": "Acme",
"sameAs": ["https://www.linkedin.com/company/acme"]
}
}
最后,用常见测试工具验证(例如 Google 的 Rich Results Test、Schema Markup Validator)。修复错误,并务实地处理警告:优先处理与你所选类型及关键属性(标题、作者、日期、产品信息)相关的警告。
llms.txt 是一个小而可读的“索引卡片”,为面向语言模型的爬虫(以及配置它们的人)指明重要入口:你的文档、关键产品页以及解释术语的参考材料。
它不是标准,不同爬虫的行为不一,不应替代站点地图、规范或robots 控制。把它当作一种有用的快捷发现方式与上下文提示。
放在站点根目录以便容易找到:
/llms.txt这与 robots.txt 的想法相同:可预测的位置,快速抓取。
保持简短并有经过策划的条目。好候选项:
也可以加入简短的风格注释以减少歧义(例如:“我们在界面中把客户称为‘workspace’”)。避免长篇营销文案、URL 大量堆砌或与规范 URL 冲突的内容。
下面是一个简单示例:
# llms.txt
# Purpose: curated entry points for understanding and navigating this site.
## Key pages
- / (Homepage)
- /pricing
- /docs
- /docs/getting-started
- /docs/api
- /blog
## Terminology and style
- Prefer “workspace” over “account”.
- Product name is “Acme Cloud” (capitalized).
- API objects: “Project”, “User”, “Token”.
## Policies
- /terms
- /privacy
一致性比数量更重要:
llms.txt 中列出被 robots.txt 阻止的 URL(这会产生混合信号)。一个可维持的常规:
llms.txt 中的每个链接,确认它仍是最佳入口。llms.txt。做好了的话,llms.txt 保持小而准确且真正有用——而无需对任何特定爬虫的行为作出承诺。
爬虫(包括面向 AI 的爬虫)在行为上很像不耐烦的用户:如果你的站点慢或不稳定,它们会抓取更少页面、重试更少并降低索引刷新频率。稳健的性能与可靠的服务器响应提高了内容被发现、被重新抓取并保持更新的概率。
若服务器经常超时或返回错误,爬虫可能会自动回退。这意味着新页面展示会更慢,更新也可能无法及时反映。
目标是高稳定性与峰值时段的可预测响应时间——而不是单纯追求好的“实验室”分数。
TTFB(首字节时间)是服务器健康的重要信号。一些高影响的优化:
尽管爬虫不像人类那样“看”图片,但大文件仍浪费抓取时间与带宽。
爬虫依赖状态码决定保留与丢弃:
若主文章文本需要认证,许多爬虫只会索引到壳层。保持核心阅读权限公开,或提供包含关键内容的可抓取预览。
保护站点免受滥用,同时避免粗暴阻断。建议:
Retry-After 头这能在保持站点安全的同时,让负责的爬虫完成工作。
“E‑E‑A‑T”(体验、专业、权威、可信)并不需要夸张的徽章。对于 AI 爬虫与 LLM,主要是网站清楚说明谁撰写了某条内容、事实来自何处以及谁负责维护。
陈述事实时,尽可能把来源放在事实附近。优先原始与官方参考(法律、标准机构、厂商文档、同行评审论文),而非二手摘要。
例如,谈到结构化数据时引用 Google 的文档(“Google Search Central — Structured Data”)以及相关 schema 定义(“Schema.org vocabulary”)。论及 robots 指令时引用相关标准与官方爬虫文档(例如 “RFC 9309: Robots Exclusion Protocol”)。即使不在每处都外链,也应提供足够细节以便读者定位原文档。
添加作者署名并附简短简介与资历,明确作者的责任。并显式标注归属:
避免使用“最佳”“保证”等绝对化措辞。描述你测试了什么、改变了什么及其局限性。在关键页面顶部或底部添加更新说明(例如“2025‑12‑10 更新:澄清了关于重定向的规范处理”),这为人和机器都提供了维护轨迹。
一次定义核心术语,然后在全站一致使用(例如“AI 爬虫”、“LLM 索引”、“渲染的 HTML”)。轻量级的术语表页面(例如 /glossary)能减少歧义,让你的内容更容易被准确摘要。
AI 就绪不是一次性工程。小变动——CMS 更新、新的重定向或改版导航——都可能悄然破坏发现与索引。简单的测试例程能让你不再靠猜测来判断流量或可见性变化。
从基础开始:跟踪抓取错误、索引覆盖情况与最高链接页面。如果爬虫无法抓取关键 URL(超时、404、被阻止资源),LLM 索引会迅速恶化。
还应监控:
每次发布后(即便“很小”),回顾发生了哪些变化:
一次 15 分钟的发布后审计通常能在问题长期影响可见性前把它们抓住。
挑选若干高价值页面并用 AI 工具或内部摘要脚本测试它们的摘要。关注:
摘要模糊时,通常的修复方法是编辑层面的:更强的 H2/H3 标题、更清晰的首段以及更明确的术语。
把学到的东西整理成周期性清单并指定负责人(使用真实姓名,而不是“市场部”)。让它可演进且可执行——并在内部链接最新版本,让全团队使用同一操作手册。发布一个轻量参考(如 /blog/ai-seo-checklist)并随着站点与工具发展更新它。
如果你的团队发布速度快(尤其是使用 AI 辅助开发时),考虑把“AI 就绪”检查直接加入构建/发布流程:模板始终输出规范标签、一致的作者/日期字段,并保证核心内容为服务器渲染。像 Koder.ai 这类平台能通过在新的 React 页面与应用界面中重复这些默认设置来帮忙,并提供计划模式、快照与回滚,以便在某次更改意外影响爬取性时快速恢复。
小而持续的改进会产生复利:减少抓取失败、清洁的索引以及对人和机器都更易理解的内容。
这意味着你的网站对自动化系统来说很容易被发现、解析和准确复用。
在实践中,这通常表现为可抓取的 URL、干净的 HTML 结构、清晰的署名(作者/日期/来源),以及以自包含块写就的内容,便于检索系统将特定回答与问题准确匹配。
不能可靠地保证你的内容会被某个 AI 索引或模型收录。不同服务提供商抓取方式、策略和刷新频率各不相同,有些甚至可能根本不抓取你的网站。
把精力放在你能控制的方面:让页面可访问、无歧义、快速可抓取且便于署名,这样如果被使用,使用方式就是正确的。
目标是让初次响应包含有意义的 HTML。
对重要页面(定价、文档、FAQ)使用 SSR/SSG 或混合渲染,然后再用 JavaScript 增强交互。如果主要文本仅在客户端水合或 API 调用后出现,许多爬虫会漏掉这些内容。
对比两者:
如果关键标题、正文、内部链接或 FAQ 只在 Inspect Element 中出现,而不在 View Source 中,则应将这些内容移入服务器渲染的 HTML。
把 robots.txt 用作全站抓取规则(例如阻止 /admin/)。把 meta robots 或 X-Robots-Tag 用于逐页的索引决定。
常见模式:对薄弱或工具性页面使用 noindex,follow,对私有区域使用认证保护(不仅仅依赖 noindex)。
为每段内容选一个稳定、可索引的规范 URL:
rel="canonical"。这有助于减少信号分散并让引用更持久一致。
只在站点地图中列出规范且可索引的 URL。
不要把被重定向、noindex、被 robots.txt 阻止或非规范的 URL 放入站点地图。保持 URL 格式一致(HTTPS、尾部斜杠规则、小写),并只在内容发生实质性变化时更新 lastmod。
把它当作一张精心挑选的“索引卡片”,指向你的最佳入口(文档中心、入门、术语表、策略页面)。
保持简短,仅列出你希望被发现和引用的 URL,并确保每个链接返回 200 且具有正确的规范。不要把它当作替代站点地图、规范或 robots 指令的工具。
按块写作,使检索时每个片段都能独立成章:
这些做法能提高检索准确性并减少错误的摘要。
加入并维护可见的信任信号:
datePublished 和有意义的 dateModified这些提示能提升爬虫与模型的归属与引用可靠性。