2025年4月14日·1 分钟
微框架如何支持灵活的自定义架构
了解微框架如何让团队通过清晰的模块、中间件和边界来组装自定义架构——并讨论权衡、常见模式与陷阱。
了解微框架如何让团队通过清晰的模块、中间件和边界来组装自定义架构——并讨论权衡、常见模式与陷阱。
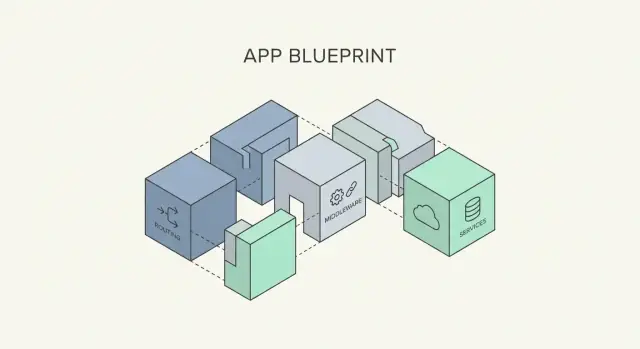
微框架是关注核心的轻量级 Web 框架:接收请求、将其路由到合适的处理器并返回响应。与完整栈框架不同,它们通常不会捆绑你可能需要的所有东西(管理面板、ORM/数据库层、表单构建器、后台作业、认证流程)。相反,它们提供一个小而稳定的内核,让你只添加产品实际需要的部分。
完整栈框架就像买了一套带家具的房子:一致且方便,但难以改造。微框架更像一个结构良好的空房子:你决定房间、家具和设施。
这种自由就是我们所说的自定义架构——围绕团队需求、领域和运维约束塑造的系统设计。通俗地讲:你选择组件(日志、数据库访问、校验、认证、后台处理)并决定如何连接它们,而不是接受一个预定义的“唯一正确方式”。
团队常在以下场景选择微框架:
我们将集中讨论微框架如何支持模块化设计:如何组合构建块、使用中间件,以及在不让项目变成“科学实验”的前提下引入依赖注入。
我们不会逐行比较具体框架或宣称微框架总是更好。目标是帮助你有意识地选择结构——并在需求变化时安全地演进它。
微框架最适合把应用当作套件而不是预构建房子来对待。你不是接受一个意见化的栈,而是从一个小内核开始,只有在值得时才添加功能。
一个实用的“内核”通常只包括:
这足以发布一个工作中的 API 端点或网页。其他一切在有明确理由之前都是可选的。
当你需要认证、校验或日志时,把它们作为独立组件添加——最好通过清晰的接口隐藏实现细节。这能保持架构易懂:每个新增部分都应能回答“解决了什么问题?”和“插在哪儿?”
“按需添加”的模块示例:
早期选择应避免将你锁死。优先使用薄包装和配置而不是深度框架魔法。如果你能在不重写业务逻辑的情况下替换模块,就做对了。
一个简单的架构“完成定义”:团队能解释每个模块的用途,能在一两天内替换它,并能独立测试它。
微框架通过设计保持精简,这意味着你可以选择应用的“器官”而非继承一个完整的身体。这使得自定义架构变得实用:可以从极简开始,只有在出现真实需求时才添加模块。
大多数基于微框架的应用以路由开始,将 URL 映射到控制器(或更简单的请求处理器)。控制器可以按功能组织(计费、账户)或按接口组织(Web 与 API),取决于维护方式。
中间件通常包裹请求/响应流,是处理横切关注点的最佳位置:
由于中间件是可组合的,你可以将其全局应用(所有请求都需要日志)或仅应用于特定路由(管理员端点需要更严格的认证)。
微框架很少强制数据层,所以你可以选择适合团队与负载的工具:
一个好的模式是把数据访问放在仓库或服务层背后,从而在稍后切换工具时不会蔓延到处理器中。
并非每个产品在第 1 天就需要异步处理。需要时再添加作业运行器和队列(邮件发送、视频处理、Webhook)。把后台作业当作进入领域逻辑的独立“入口点”,与 HTTP 层共享同样的服务,而不是重复业务规则。
中间件是微框架带来最大杠杆的地方:它让你处理每个请求都应完成的工作,而不把这些 plumbing 写进每个路由处理器。目标很简单:让处理器聚焦业务逻辑,让中间件处理基础设施。
不要在每个端点重复相同的检查和头部,添加一次中间件即可。一个干净的处理器看起来应该是:解析输入、调用服务、返回响应。其他事——认证、日志、校验默认值、响应格式化——都可以在前后完成。
顺序即行为。常见且可读的序列为:
如果压缩过早运行,可能错过错误;如果错误处理过晚,可能泄露堆栈或返回不一致的格式。
X-Request-Id 头并把它包含到日志中。{ error, message, requestId })。按用途分组中间件(可观测性、安全、解析、响应塑形),并在合适的作用域应用:全局用于真正通用的规则;路由组中间件用于具体区域(例如 /admin)。给每个中间件清晰命名并在设置处用简短注释记录预期顺序,避免未来的改动无意中破坏行为。
微框架给你一个薄薄的“请求进、响应出”内核。其他一切——数据库访问、缓存、邮件、第三方 API——都应可替换。这正是**控制反转(IoC)与依赖注入(DI)**的用武之地,且不应该把代码库变成一个科学实验。
如果某个功能需要数据库,很容易在功能内部直接创建它(“这里 new 一个数据库客户端”)。缺点是:每个“去逛商店”的地方都会与具体客户端紧耦合。
IoC 则相反:功能询问所需,应用的接线层交付给它。功能变得更易重用,也更易替换。
依赖注入就是传入依赖而不是在内部创建。在微框架环境中,这通常在启动阶段完成:
你不需要大型 DI 容器就能获得好处。先从一个简单规则开始:在一处构造依赖,并向下传递。
为了使组件可替换,定义一个简小接口来描述“你需要什么”,然后为具体工具写适配器。
示例模式:
UserRepository(接口):findById、create、listPostgresUserRepository(适配器):用 Postgres 实现这些方法InMemoryUserRepository(适配器):为测试实现相同方法你的业务逻辑只认识 UserRepository,而不认识 Postgres。切换存储成为配置选择,而非重写。
同样思路适用于外部 API:
PaymentsGateway 接口StripePaymentsGateway 适配器FakePaymentsGateway 用于本地开发微框架很容易让配置散落在各模块。要抵制这种做法。
一个可维护的模式是:
这能达成目标:在不重写应用的前提下替换组件。变更数据库、替换 API 客户端或引入队列,只需在接线层做小改动,而其余代码保持稳定。
微框架不会强制“唯一正确方式”来组织代码。相反,它们提供路由、请求/响应处理与少量扩展点——让你根据团队规模、产品成熟度和变化频率采用合适的模式。
这是熟悉且简洁的设置:控制器处理 HTTP 关注点,服务包含业务规则,仓库负责数据库交互。
当领域直观、团队小到中型且你想要可预测的代码放置位置时,这种方式很适合。微框架天然支持它:路由映射到控制器,控制器调用服务,仓库通过轻量手动组合接入。
当你预期系统会比当前选择活得更久(数据库、消息总线、第三方 API,甚至 UI 都可能变化)时,六边形架构很有用。
微框架在这里表现良好,因为“适配器”层通常是你的 HTTP 处理器加上一层薄薄的转换步骤,映射到领域命令。你的端口是域内的接口,适配器实现它们(SQL、REST 客户端、队列)。框架待在边缘,而非中心。
如果你想要接近微服务的清晰度但不愿承受运维开销,模块化单体是强有力的选择。保持一个可部署单元,同时将其拆分为功能模块(例如 Billing、Accounts、Notifications),并为每个模块定义显式公共 API。
微框架让这更容易,因为它们不会自动接线:每个模块可以注册自己的路由、依赖和数据访问,从而让边界可见且更难被无意跨越。
在这三种模式中,收益相同:你设定规则——文件夹布局、依赖方向与模块边界——而微框架提供一个稳定、精简的表面来接入。
微框架让你容易从小处开始并保持灵活,但它们不会替你决定“系统应该呈现什么形态”。正确选择更多取决于团队规模、发布频率以及协调成本何时变得痛苦。
单体作为一个可部署单元发布。通常是最快实现产品的路径:一次构建、统一日志、一个地方调试。
模块化单体仍然是一个可部署单元,但内部按明确模块分离(包、界限上下文、功能文件夹)。这是代码库增长后的常见“下一步”,尤其当使用微框架时,你可以保持模块显式。
微服务把可部署单元拆分为多个服务。它能降低团队间耦合,但也增加了运维工作量。
当边界在你工作中已真实存在时拆分:
避免因“这个文件夹太大”或服务仍需共享相同表而拆分,那通常表示你还没找到稳定的边界。
API 网关能简化客户端(统一入口、集中认证/限流)。缺点是:如果它承担过多职责,会成为瓶颈和单点故障。
共享库能加速开发(通用校验、日志、SDK),但也会制造隐性耦合。如果多个服务必须同时升级,就变成分布式单体。
微服务会带来持续成本:更多的部署流水线、版本控制、服务发现、监控、追踪、事件响应和值班轮班。如果团队无法舒适地运行这些机制,那么用微框架构建的模块化单体通常是更安全的架构。
微框架提供自由,但可维护性需要设计。目标是让“自定义”部分易于找到、易于替换且难以滥用。
挑选一个你能在一分钟内讲清楚并通过代码审查强制执行的结构。一个实用划分为:
app/(组合根:接线模块)modules/(业务能力)transport/(HTTP 路由、请求/响应映射)shared/(跨切关注工具:配置、日志、错误类型)tests/命名保持一致:模块文件夹使用名词(billing、users),入口点可预测(index、routes、service)。
把每个模块当作一个小型产品来对待,明确边界:
modules/users/public.ts)modules/users/internal/*)避免像 modules/orders/internal/db.ts 这样的穿透性导入。如果其他模块需要,提升它到公共 API。
即使是很小的服务也需要基本可见性:
把这些放在 shared/observability,让每个路由处理器使用相同约定。
让错误对客户端可预测、对人易于调试。定义一种错误形状(例如 code、message、details、requestId)和一种校验方法(每个端点的 schema)。集中把内部异常映射到 HTTP 响应,使处理器专注业务逻辑。
如果目标是在保持微框架式架构显式的同时快速推进,Koder.ai 可作为脚手架与迭代工具,而非替代良好设计的方案。你可以在对话中描述期望的模块边界、中间件栈与错误格式,生成一个可工作的基础应用(例如 React 前端加 Go + PostgreSQL 后端),然后有意识地完善接线。
两个特别契合自定义架构工作的功能:
因为 Koder.ai 支持源码导出,你可以保有架构所有权,并像手工构建的微框架项目一样在仓库中演进它。
基于微框架的系统可能看起来“手工组装”,这使得测试更侧重于保护模块间的接口而非某个框架的约定。目标是在不让每次改动都变成端到端跑通的前提下获取信心。
先写业务规则的单元测试(校验、定价、权限逻辑),它们运行快且能精确定位失败。
然后投入少量高价值的集成测试,覆盖接线流程:路由 → 中间件 → 处理器 → 持久层边界。这类测试能捕捉组件组合时出现的细微错误。
中间件通常隐藏横切行为(认证、日志、限流)。按流水线方式测试它:
对处理器,优先测试公共 HTTP 形状(状态码、头、响应体)而不是内部函数调用。这能让测试在内部变化时保持稳定。
利用依赖注入(或构造函数参数)替换真实依赖为假实现:
当多个服务或团队依赖某个 API,加入契约测试以固定请求/响应预期。提供方的契约测试确保即便微框架设置与内部模块演进,也不会无意破坏消费者。
微框架赋予自由,但自由并不等于清晰。主要风险在于团队扩大、代码库膨胀后——临时决策变成永久负担。
内置约定少时,不同团队可能用不同风格实现同样功能(路由、错误处理、响应格式、日志)。这种不一致会拖慢审查并加重入职成本。
简单的护栏能缓解:编写一页“服务模板”文档(项目结构、命名、错误格式、日志字段)并通过 starter 仓库与若干 lint 强制执行。
微框架项目常从干净开始,然后累积一个 utils/ 文件夹,慢慢变成第二个框架。当模块共享助手、常量和全局状态时,边界模糊,改动会带来意外破坏。
优先显式的共享包并带版本控制,或仅共享必要内容:类型、接口和经过良好测试的原语。如果某个 helper 依赖业务规则,那么它可能更应该放在领域模块而非 utils。
手动接线认证、授权、输入校验与限流时,容易遗漏某条路由、忘记中间件或只校验“快乐路径”输入。
把安全默认值集中化:安全头、一致的认证检查以及边缘处的校验。增加测试以断言受保护端点确实受保护。
未规划的中间件层会带来开销——尤其当多个中间件解析请求体、访问存储或序列化日志时。
让中间件保持精简并可测量。在设置处记录标准顺序,评审新中间件的成本。若怀疑膨胀,用探查工具分析请求并移除冗余步骤。
微框架给你选项——但选项需要决策流程。目标不是找到“最佳”架构,而是选一个团队能构建、运营并在没有戏剧性的情况下改变的形态。
在决定“单体”或“微服务”前,回答这些问题:
若不确定,默认选择用微框架构建的模块化单体。它能保持边界清晰同时易于发布。
微框架不会替你强制一致性,所以提前选好约定:
把一页“服务契约”文档保存在 /docs 通常就够了。
从每处都会用到的横切部分开始:
把这些当作共享模块,而不是复制粘贴的代码片段。
架构应随需求变化而改变。每季度回顾一次:哪些部署变慢了,哪些部分需要不同扩展,哪些最常出问题。如果某个领域成了瓶颈,那就是下一个拆分候选,而不是随便挑一个模块。
微框架设置很少从“完美设计”开始。通常从一个 API、一个团队和紧迫的截止开始。随着产品成长,价值显现:新功能进入、更多人触碰代码、架构需要在不断拉伸中不崩盘。
以最小服务起步:路由、请求解析和一个数据库适配器。大部分逻辑靠近端点以便快速交付。
加入认证、支付、通知与报表后,把它们拆为模块(文件夹或包),并定义清晰的公共接口。每个模块拥有自己的模型、业务规则与数据访问,只对外暴露必要部分。
日志、认证检查、限流与请求校验迁移到中间件,以便每个端点行为一致。由于顺序重要,务必记录它。
记录:
当模块开始共享过多内部实现、构建时间明显变慢,或“微小改动”需跨多个模块修改时,就要重构。
当团队因共享部署受阻、不同部分需要不同扩展,或某个边界已表现得像独立产品时,就考虑拆分为独立服务。
当你想围绕领域而非固定栈来塑造应用时,微框架是很合适的。它们特别适合那些更重视清晰而非便利的团队:你愿意选择(并维护)一些关键构建块,以换取一个随着需求变化仍然可理解的代码库。
灵活性只有在你以一些习惯保护它时才有价值:
最后,把决策写下来——即便是简短说明也有帮助。在仓库中维护一页“架构决策”并定期回顾,能防止昨天地捷径成为今天的约束。
一个微框架聚焦于核心:路由、请求/响应处理和基本的扩展点。
完整栈框架通常捆绑许多“开箱即用”的功能(ORM、认证、后台管理、表单、后台任务)。微框架以控制权换取便利——你只添加所需的部分,并自行决定各部分如何连接。
当你希望:
微框架通常是合适的选择。
一个“最小可用核心”通常包括:
从这里开始,先发布一个端点;只有当某个功能明确带来收益时再添加模块(认证、校验、可观测性、队列)。
中间件适合处理广泛适用的横切关注点,例如:
保留路由处理器专注于业务逻辑:解析 → 调用服务 → 返回响应。
顺序会改变行为。一个常见且可靠的序列是:
在设置代码附近记录顺序,避免未来修改无意中破坏响应或安全假设。
Inversion of Control 的意思是你的业务代码不去自己构造依赖(不去“自己买东西”)。相反,应用的组装层提供它所需的东西。
实际做法:在启动时构建数据库客户端、日志器和 API 客户端,然后把它们传入服务/处理器。这样可以减少紧耦合,并更容易测试与替换实现。
不需要。你可以通过一个简单的组合根获得大多数依赖注入好处:
只有在依赖图变得难以手工管理时,才考虑引入容器——不要一开始就引入复杂性。
把存储和外部 API 放在小接口(端口)后面,然后实现适配器:
UserRepository 接口:findById、create、listPostgresUserRepositoryInMemoryUserRepository一个实用的目录结构,能让边界保持清晰:
app/ 组合根(接线)modules/ 功能模块(领域能力)transport/ HTTP 路由与请求/响应映射shared/ 配置、日志、错误类型、可观测性tests/强制模块公开 API(例如 ),避免跨模块访问内部实现(“reach-through”)。
把精力优先放在快速的单元测试(业务规则)上,然后编写少量高价值的集成测试来覆盖完整管道(路由 → 中间件 → 处理器 → 持久层边界)。
使用 DI/假实现隔离外部服务;把中间件当作流水线来测试(断言头、副作用和阻断行为)。当多个团队依赖某个 API 时,加入合约测试以防止破坏性变更。
处理器/服务依赖接口而非具体实现。切换数据库或第三方提供商成为组装/配置层的改动,而不是重写业务代码。
modules/users/public.ts