2025年11月26日·1 分钟
为什么图数据库在处理关系上表现出色——但不是万能的
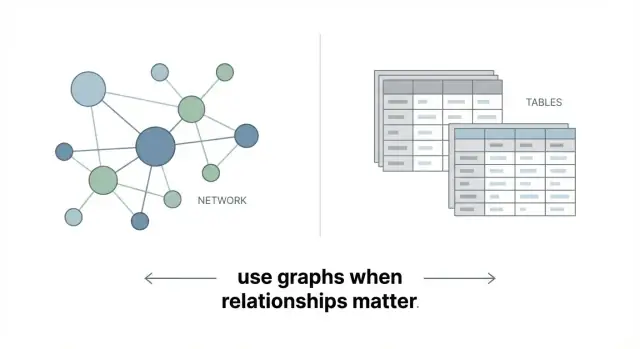
当问题由连接关系驱动时,图数据库最为出色。了解最佳使用场景、权衡取舍,以及何时关系型或文档数据库更合适。
当问题由连接关系驱动时,图数据库最为出色。了解最佳使用场景、权衡取舍,以及何时关系型或文档数据库更合适。
图数据库不是把数据塞进表格然后拼接关系——它把数据直接表示为网络。核心思想很简单:
就是这样:图数据库旨在直接表示连接数据。
在图数据库中,关系不是事后的想法——它们作为真实且可查询的对象被存储。关系可以有自己的属性(例如一个 PURCHASED 关系可以存储日期、渠道和折扣),并且你可以高效地从一个节点遍历到下一个节点。
这很重要,因为许多业务问题本质上是关于路径和连接的:“谁和谁相连?”,“这个实体相隔多少步?”,或者“这两个事物之间有哪些共同的链接?”
关系型数据库善于处理结构化记录:客户、订单、发票。那里也存在关系,但通常是通过外键间接表示,多跳连接往往需要跨多个表写 JOIN。
图把连接直接放在数据旁边,因此探索多步关系在建模和查询上通常更直接。
当关系是核心时,图数据库表现出色——推荐、欺诈团伙、依赖映射、知识图谱。但对于简单报表、计数或高度表格化的工作负载,图并不自动更好。目标不是替换所有数据库,而是在连接驱动价值时使用图。
大多数业务问题并不只是关于单条记录——而是关于事物如何相互连接。
一个客户不只是表中的一行;他们与订单、设备、地址、支持工单、推荐人,以及有时与其他客户相连。一次交易不仅仅是一个事件;它与商家、支付方式、地点、时间窗口和一系列相关活动相连。当问题是“谁/什么通过何种路径相连?”时,关系数据就成了主角。
图数据库为遍历而生:你从一个节点开始,通过跟随边“走”过网络。
不用反复 JOIN 表,你直接表达关心的路径:Customer → Device → Login → IP Address → Other Customers。这种逐步的表达方式与人们调查欺诈、追踪依赖或解释推荐时的思路一致。
真正的差异在于当你需要多跳(两步、三步、五步)且事先不知道哪些连接会有价值时。
在关系模型中,多跳问题常常变成长链 JOIN,再加上避免重复和控制路径长度的额外逻辑。在图中,“找到所有不超过 N 跳的路径”是一个正常且可读的模式——尤其是在许多图数据库使用的属性图模型中。
边不仅仅是线;它们可以携带数据:
这些属性让你可以提出更有意义的问题:“30 天内相连”、“最强连接”或“包含高风险交易的路径”——而无需把所有东西强行放进单独的查找表。
当你的问题依赖于连通性时,图数据库会更有优势:“谁通过什么相连?相隔多少步?”如果你的数据价值体现在关系上(而不仅仅是属性行),图模型会让数据建模和查询更自然。
任何呈网络状的事物——朋友、关注者、同事、团队、推荐——都能自然映射为节点和关系。典型问题包括“共同连接”、“到某人的最短路径”或“谁在连接这两个群体?”这些查询在被迫用大量关联表实现时常会变得尴尬或缓慢。
推荐引擎通常依赖多步连接:用户 → 项目 → 类别 → 相似项 → 其他用户。图数据库适合回答“喜欢 X 的人也喜欢 Y”、“经常被共同浏览的商品”,以及“找出通过共享属性或行为相连的商品”。当信号多元并且你不断增加新的关系类型时尤其有用。
欺诈检测图很适合,因为可疑行为很少是孤立的。账户、设备、交易、电话号码、邮箱和地址会形成共享标识符的网络。图能更容易发现团伙、重复模式和间接链接(例如通过一连串活动把两个“看似无关”的账户关联起来)。
对于服务、主机、API、调用和所有权,关键问题是依赖关系:“如果这个变动会影响谁?”图支持影响分析、根因探索和“冲击半径”查询,当系统互相连接时尤其重要。
知识图谱将实体(人、公司、产品、文档)与事实和引用相连,有助于搜索、实体解析以及追踪某条事实为何被认定(溯源)在多个链接来源中的来源。
当问题真的是关于连接时,图数据库会很出色:谁与谁相连、通过什么链路、以及哪些模式在重复。你不需要一遍又一遍地 JOIN 表,而是直接询问关系问题,并在网络增长时保持查询的可读性。
典型问题:
这对客户支持(“我们为什么会推荐这个?”)、合规(“展示所有权链”)和调查(“它如何传播?”)非常有用。
图可以帮助你发现自然分群:
你可以用它来对用户进行分段、发现欺诈团伙或理解产品的共同购买模式。关键在于“群体”是由连接方式定义的,而不是单列值。
有时问题不是“谁相连”,而是“谁最重要”在网络中:
这些中心节点通常指向影响者、关键基础设施或值得监控的瓶颈。
图擅长查找可重复的形状:
在 Cypher(常见的图查询语言)中,三角形模式可以像这样写:
MATCH (a)-[:KNOWS]-\u003e(b)-[:KNOWS]-\u003e(c)-[:KNOWS]-\u003e(a)
RETURN a,b,c
即便你从不亲自写 Cypher,这也说明了图的可亲近性:查询的表达和你脑海中的图形是一一对应的。
关系型数据库在其设计目标上表现优秀:事务和结构化记录。如果你的数据能整齐地放进表格(客户、订单、发票),且你大多数检索是按 ID、过滤和聚合,关系型系统通常是最简单且最稳妥的选择。
当 JOIN 偶尔且浅时没问题。但摩擦点在于当最重要的问题始终需要很多 JOIN跨越多个表时。
例子:
在 SQL 中这些问题可能变成冗长查询,并伴随重复自联接与复杂逻辑。随着关系深度增长,这些查询也会更难优化。
图数据库显式存储关系,所以跨连接的多步遍历是自然操作。你不必在查询时把表拼接在一起,而是去遍历节点和边。
这通常意味着:
如果你的团队经常问 多跳问题——“相连于”、“通过…”、“在同一网络中”、“在 N 步以内”——那么值得考虑图数据库。
如果你的核心负载是高并发事务、严格模式、报表以及简单 JOIN,关系型通常是更好的默认选择。许多真实系统两者并用;参见 /blog/practical-architecture-graph-alongside-other-databases。
图数据库在关系是“主角”时表现出色。如果你的应用价值并不依赖于遍历连接(谁认识谁、事物如何关联、路径、邻域),图可能会增加复杂性却收效甚微。
如果大多数请求是“按 ID 获取用户”、“更新资料”、“创建订单”,且所需数据存在于单条记录或可预测的小表集合中,图数据库通常不必要。你需要花时间建模节点与边、调优遍历并学习新查询风格——而关系型数据库对这类模式处理高效且工具成熟。
基于总和、平均和分组指标的仪表盘(按月收入、按地区订单、渠道转化率)通常更适合 SQL 和列式分析引擎。图引擎可以回答部分聚合问题,但对于重 OLAP 风格的工作负载,它们很少是最简单或最快的方案。
当你依赖成熟的 SQL 特性——复杂 JOIN、严格约束、先进索引策略、存储过程或成熟的 ACID 事务模式时,关系型系统通常是自然的选择。许多图数据库支持事务,但其周边生态和运维模式可能与团队现有依赖不匹配。
如果你的数据主要是独立实体(工单、发票、传感器读数),且交叉链接很少,图模型会显得生硬。在这些情况下先专注于干净的关系型或文档模型,只有在关系问题成为核心时再考虑图。
一个简单规则:如果你可以在不使用“连接”、“路径”、“邻域”或“推荐”等词的情况下描述你的核心查询,图数据库可能不是首选。
图数据库在需要快速跟随连接时很强——但这种优势是有代价的。在你投入之前,了解图在哪些场景效率较低、成本更高或日常运行不同很重要。
图数据库通常以能让“跳数”更快为代价来存储和索引关系(例如,从客户到其设备再到交易)。代价是内存和存储可能高于可比的关系型设置,尤其是在为常见查找添加索引并保持关系数据可快速访问时。
如果你的工作负载更像电子表格——大表扫描、数百万行的报表查询或重聚合(总和、平均、分组汇总)——图数据库可能更慢或更昂贵。图擅长遍历(“谁与谁相连?”),而非处理大量独立记录的批量计算。
运行复杂度是个实际因素。备份、扩展和监控与团队在关系型系统中的习惯不同。有些图平台通过纵向扩展(更大机器)更好地扩展,而另一些支持横向扩展但需要在一致性、复制和查询模式上精心规划。
团队可能需要时间学习新的建模模式和查询方法(例如属性图模型与 Cypher)。学习曲线是可管理的,但仍然是成本——尤其是当你要替换成熟的基于 SQL 的报表工作流时。
一个实际方法是:在关系密集且能产出价值的场景使用图,同时为报表、聚合和表格分析保留现有系统。
把图建模简单化地想:节点是事物,边是事物之间的关系。人、账户、设备、订单、产品、地点是节点。“购买”、“从…登录”、“协作”、“父子关系”是边。
大多数面向产品的图数据库使用属性图模型:节点和边都可以有属性(键–值字段)。例如,一个 PURCHASED 边可以存储 date、amount 和 channel,这使得建模“带细节的关系”很自然。
RDF 将知识表示为三元组:subject – predicate – object。它适合互操作的词汇和跨系统链接,但通常会把“关系的细节”转移到额外的节点/三元组中。实践上,你会发现 RDF 更倾向于标准本体和 SPARQL 模式,而属性图更接近应用数据建模。
初期无需记忆语法——重要的是图查询通常以路径和模式表达,而不是拼接表。
图通常模式灵活,意思是你可以在不做大规模迁移的情况下添加新节点标签或属性。但灵活性仍需约束:定义命名约定、必需属性(例如 id)以及关系类型规则。
选择能解释语义的关系类型(“FRIEND_OF” vs “CONNECTED”)。用方向来澄清语义(例如 FOLLOWS 从关注者到创作者),当关系自身有事实(时间、置信度、角色、权重)时就在边上加属性。
当难点不在于存储记录,而在于理解事物如何连接以及不同路径如何改变含义时,这个问题就是“以关系为驱动”。
先把前 5–10 个关键问题用自然语言写下来——那些利益相关者不断提出并且当前系统回答缓慢或不一致的问题。好的图候选问题通常包含“相连”、“通过”、“类似于”、“在 N 步内”或“谁还……”等短语。
例子:
有了问题后,把名词和动词映射出来:
然后决定什么必须是关系,什么应是节点。实用规则:如果某件事需要自己的属性并且会连接多方,就把它做成节点(例如 Order 或 Login event 当它携带细节并连接多方时)。
添加属性以便在不做额外 JOIN 或后处理的情况下缩小结果并排序。典型高价值属性包括 时间、金额、状态、渠道 和 置信度分。
如果你大多数重要问题都需要多步连接并且按这些属性过滤,那你很可能在处理一个图数据库擅长的问题。
大多数团队不会用图数据库替换所有东西。更实用的做法是把现有的“事实系统”保留在原位(通常是 SQL),并把图数据库作为处理关系密集型查询的专用引擎。
在关系型数据库中处理事务、约束和规范实体(客户、订单、账户)。然后把关系视图投影到图数据库——只包含用于连通查询的节点和边。
这让审计和数据治理更直接,同时仍能解锁快速遍历查询的能力。
图数据库在绑定到明确范围的功能时最能发挥作用,例如:
先从一个功能、一个团队和一个可衡量的结果开始。价值证明后再扩展。
如果你的瓶颈是快速搭出原型而不是模型争论,像 Koder.ai 这样的 vibe-coding 平台可以帮助你快速构建一个简单的图驱动应用:在聊天中描述功能,生成 React UI 和 Go/PostgreSQL 后端,然后在数据团队验证图模式和查询时迭代。
图需要多新鲜的数据?
常见模式是:写事务到 SQL → 发布变更事件 → 更新图。
当 ID 漂移时,图会变得凌乱。
定义稳定标识符(例如 customer_id、account_id),并与其他系统一致,记录谁“拥有”每个字段和关系。如果两个系统都可能创建相同的边(比如“knows”),提前决定哪方优先。
如果你在做试点,参见 /blog/getting-started-a-low-risk-pilot-plan 了解分阶段上线的方法。
图试点应该像实验而非重写。目标是证明(或驳斥)关系密集型查询是否变得更简单、更快——而不是押上整个数据栈。
从已经有痛点的数据子集开始:太多 JOIN、脆弱的 SQL 或“谁与谁相连?”类问题响应慢。把范围限定在一个工作流内(例如:customer ↔ account ↔ device,或 user ↔ product ↔ interaction),并定义几条从头到尾要实现的查询。
衡量的不仅仅是速度:
如果你无法写出“之前”的数字,你就不会信任“之后”。
不要把所有东西都建成节点和边。警惕“图膨胀”:过多的节点/边类型但没有明确查询需要它们。每个新标签或关系都应该通过能解决的真实问题来证明其存在价值。
提前规划隐私、访问控制和数据保留。关系数据可能揭示超过单条记录的信息(例如暗示某种行为的连接)。定义谁能查询什么、如何审计结果以及在需要时如何删除数据。
使用简单的同步(批量或流)把数据喂进图,同时现有系统保持事实来源。当试点证明有价值后,你可以谨慎地按用例扩展。
选数据库时别先选技术——先看你要回答的问题。如果你最难的问题关于连接和路径,而不仅仅是存储记录,图数据库会很有用。
用这个清单在投入前做个健康检查:
如果你对大部分问题都回答“是”,图就是强有力的选择——尤其是在你需要多跳模式匹配时,例如:
如果你的工作主要是按 ID/邮箱等做简单查找或聚合(“按月销售总额”),关系型或键值/文档存储通常更简单、更便宜运行。
把你的前 10 个业务问题写成自然语言,然后在真实数据上小规模测试。计时查询,记录表达困难之处,并短期记录模型变更。如果试点大多变成“更多 JOIN”或“更多缓存”,那说明图可能是个好选择。如果主要是计数和过滤,则可能不是。
图数据库将数据以节点(实体)和关系(连接)以及两者的属性来存储。它针对类似“ A 与 B 如何相连?”或“谁在 N 步以内?”这类以连接为中心的问题进行了优化,而不是以表格报表为主的查询。
因为关系被作为真实的、可查询的对象存储(而不仅仅是外键值)。你可以高效地跨多跳遍历,并且在关系上附加属性(例如 date、amount、risk_score),这让以连接为主的问题更容易建模和查询。
关系型数据库通常通过外键间接表示关系,多跳问题往往需要多个 JOIN。图数据库则把连接放在数据旁边存储,因此可变深度的遍历(例如 2–6 跳)通常更容易表达和维护。
当你的核心问题涉及路径、邻域和模式时适合使用图数据库,例如:
常见的图查询包括:
通常在以下场景下不是合适的工具:
在这些情况下,关系型或分析系统通常更简单、更便宜。
当连接主要用于“连接两个实体”且本身有属性(时间、角色、权重)时,应把它建模为边(edge)。当某个对象是有多属性且要连接多方的事件或实体(例如 Order 或 Login 事件),应把它建模为节点(node)。
典型的权衡包括:
属性图允许节点和关系都有属性(键值对),适合面向应用的数据建模。RDF 将知识表示为三元组(subject–predicate–object),更适合可互操作的词汇和跨系统链接,并通常使用 SPARQL。选择时考虑你需要的是应用级的关系属性(属性图)还是语义互操作性(RDF)。
保持现有系统(通常是 SQL)作为事实来源,然后把需要的节点和边投影到图数据库,作为针对关系密集型查询的专用引擎。通过批量或流式同步,使用稳定的标识符,并在一个有明确边界的功能上做试点(推荐、风险评分、身份解析),在验证价值后再扩展。参见 /blog/practical-architecture-graph-alongside-other-databases 和 /blog/getting-started-a-low-risk-pilot-plan。