2025年11月01日·1 分钟
无服务器数据库如何改变初创公司的成本模型
无服务器数据库将初创公司从固定容量成本转为按使用付费。了解定价机制、隐藏成本驱动因素,以及如何在数据不完善时预测支出。
无服务器数据库将初创公司从固定容量成本转为按使用付费。了解定价机制、隐藏成本驱动因素,以及如何在数据不完善时预测支出。
无服务器数据库改变了你在起步时要问的核心问题:不再是**“我们应该买多少数据库容量?”而是“我们将使用多少数据库?”**听起来很细微,但它重塑了预算、预测,甚至产品决策。
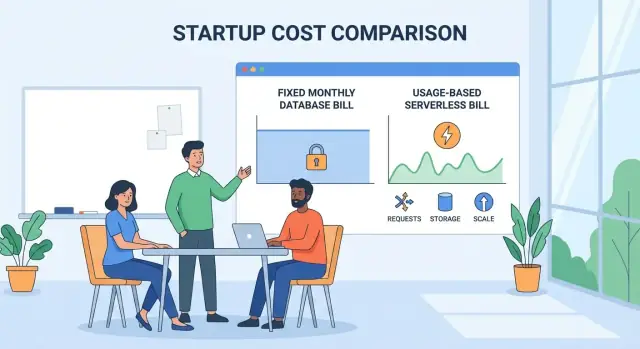
在传统数据库里,你通常选择一个规格(CPU/RAM/存储),保留它,然后无论忙或闲都要付钱。即便你使用自动扩缩容,你仍然以实例和峰值容量来思考。
而在无服务器模式下,账单通常跟踪消耗单元——例如请求数、计算时间、读/写操作、存储或数据传输。数据库可以自动上下扩,但代价是你直接为应用内部发生的每个峰值、后台任务和低效查询买单。
在早期,性能常常是“足够好”直到用户明显受影响。但成本会立即影响你的跑道(runway)。
无服务器可以大幅节省,因为你避免为闲置容量付费,尤其是在尚未找到产品市场(pre-product-market fit)时流量难以预测。但这也意味着:
因此,创始人通常会先把这种变化感知为财务问题,而不是扩容问题。
无服务器数据库能简化运维并减少前期承诺,但也带来新的权衡:定价复杂、在峰值时可能出现成本惊喜,以及新的性能表现(例如冷启动或限流,取决于厂商)。
接下来我们将分解常见的无服务器定价方式、隐藏成本驱动在哪儿,以及如何在没有完美数据时预测并控制支出。
在无服务器出现前,大多数初创公司购买数据库的方式像租办公空间:选择一个大小,签订计划,并为其付费,无论是否充分使用。
典型的云数据库账单由预置实例主导——你持续运行的特定机器大小或集群。即便流量在夜间下降,计费仍在继续,因为数据库“开着”。
为降低风险,团队常会购买保留容量(1 年或 3 年承诺以换取折扣)。这能降低单位小时费率,但也把你锁定在一个基线支出上——若产品转向、增长放缓或架构改变,这笔支出可能不再合适。
此外还有过度预置:为“以防万一”选择比当前需要更大的实例。这在担心故障时是合理的选择,但会让你在收入尚不足以支撑时就提前承担更高的固定成本。
初创公司很少有稳定、可预测的负载。你可能遇到媒体推送、产品发布高峰或月末报表流量。用传统数据库时,通常会为你能想象到的最糟糕的一周来配置,因为后续调整往往有风险(且需要规划)。
结果是熟悉的不匹配:整月为峰值容量付费,而平均使用远低于峰值。那部分“闲置支出”在发票上看起来正常,但却可能悄然成为最大的经常性基础设施费用之一。
传统数据库还带来时间成本,这对小团队影响很大:
即便使用托管服务,这些任务仍需有人承担。对初创公司来说,这往往意味着昂贵的工程时间本可以用于产品工作——这是一个不会在单行上出现但会影响跑道的隐性成本。
“无服务器”数据库通常是有弹性的托管数据库。你不需要运行数据库服务器、打补丁或预置实例;相反,提供商根据使用信号调整容量并按使用计费。
大多数厂商会组合若干计费维度(名称不同但思路一致):
有些厂商还会对备份、复制、数据传输或特殊功能(加密密钥、时间点恢复、分析副本)单独计费。
自动扩缩是行为上的主要变化:当流量激增时,数据库增加容量以维持性能,你在那段时间付更多;当需求下降,容量缩回,成本也会下降——对突发性负载这能带来显著节省。
这种灵活性很诱人,但它也意味着支出不再绑定到固定实例大小,而是随产品使用模式变化:一次市场活动、一个后台任务或一条低效查询都可能改变你的月度账单。
最好把“无服务器”理解为按使用付费 + 运维便利,而非保证降本。该模型奖励可变工作负载与快速迭代,但会惩罚持续高用量或未优化的查询。
在传统数据库下,早期成本常感觉像“房租”:你为服务器大小付费(加副本、备份和运维时间),无论用户是否来访。无服务器数据库把你推向“销售成本(COGS)”思维——支出跟随产品实际行为。
为做好管理,把产品行为翻译成数据库的计费单元。对很多团队来说,实用的映射包括:
一旦能把特性和可测量单元关联起来,你就能回答:“如果活动翻倍,账单上到底哪些项会翻倍?”
除了跟踪总云支出,建立一些与业务模型匹配的“每…成本”指标:
这些数字能帮助你评估增长是否健康。如果数据库使用增长速度超过营收,产品可能“在扩张”的同时悄然恶化利润率。
使用量计费会直接影响你如何设计免费层和试用期。如果每个免费用户都产生显著查询量,那么“免费”获客通道可能就是一项真实的可变成本。
实用的调整包括限制昂贵操作(例如重搜索、导出、长期历史)、缩短免费计划的保留期,或对触发突发工作负载的功能设置门槛。目标不是损害产品体验,而是确保免费体验与可持续的每激活客户成本一致。
初创公司通常在“今天需要什么”和“下个月可能需要什么”之间存在极端不匹配。这正是无服务器数据库改变成本对话的场景:它把容量规划(猜测)转成了一个紧贴实际使用的账单。
与拥有稳定基线与专门运维团队的成熟公司不同,早期团队常在跑道、快速产品迭代与不可预测的需求间博弈。一点流量变化就可能把数据库支出从“零钱”变成“重要行项”,并且反馈环极为即时。
早期增长并不会平滑到一条曲线;它以突发形式出现:
在传统数据库下,你通常为峰值整月付费以度过几小时的高峰。无服务器的弹性可以减少浪费,因为你无需一直保留昂贵的空闲冗余。
初创公司频繁调整方向:新功能、入职流程、定价层、市场。你的增长曲线未知,数据库工作负载也可能毫无征兆地改变(更多读取、更重分析、更大文档、更长会话)。
若你预先配置,错误会付出两种代价:
无服务器能降低因配置不足导致的宕机风险,因为它能随需扩展,而不必在事件期间等待人工调整。
对创始人而言,最大收益不仅仅是平均支出更低——而是承诺减少。按使用付费能让你将成本与牵引对齐并更快学习:你可以做实验、承受突发流量,然后再决定是否优化、预留容量或考虑替代方案。
代价是成本变得更可变,因此初创公司需要在早期建立轻量护栏(预算、告警、基础归因)以避免惊喜,同时仍能享受弹性带来的好处。
无服务器计费善于将支出与活动匹配——直到“活动”包括了大量你没意识到自己在产生的工作。最大惊喜通常来自小而重复的行为逐步放大。
存储很少保持不变。事件表、审计日志和产品分析往往比核心用户数据增长更快。
备份和时间点恢复也可能单独计费(或在效果上复制存储)。一个简单的护栏是为以下项设置明确的保留策略:
很多团队以为“数据库成本”只是读/写和存储。但当你:
网络费用就会悄然占比。即便供应商宣传每次请求的价格很低,跨区流量与出站带宽也能把适度负载变成明显的账单行项。
按使用计费会放大糟糕查询模式。N+1 查询、缺索引和无界扫描能把一次用户操作变成数十乃至数百次计费操作。
注意那些随数据量增长而延迟上升的端点——这些端点通常也是成本非线性上升的地方。
无服务器应用能瞬间扩容,这意味着连接数也能突然飙升。冷启动、自动扩缩事件与“雷鸣群”重试会产生突发,进而:
如果数据库按连接或并发计费,在部署或故障时这会特别昂贵。
回填、重建索引、推荐作业与仪表盘刷新看似“不是产品使用”,但它们通常产生最大的查询和最长时间的读取。
一个实用规则:把分析和批处理当作独立工作负载,分配独立预算与时间窗口,避免它们静悄悄地消费原本用于服务用户的预算。
无服务器数据库不仅改变你付多少,还改变你为啥付费。核心权衡很简单:你可以通过 scale-to-zero 最小化空闲支出,但可能引入用户可感知的延迟和波动性。
scale-to-zero 对突发负载很有用:管理后台、内部工具、早期 MVP 流量或每周批处理任务。你无需为未使用的容量付费。
但缺点是冷启动。如果数据库或其计算层空闲,下一个请求可能遭遇“唤醒”惩罚——有时是几百毫秒,有时是几秒,取决于服务和查询模式。这对以下场景尤其致命:
一个常见的初创陷阱是为了降低月度账单而不自觉地牺牲性能预算,进而影响转化或留存。
你可以降低冷启动影响同时避免放弃节省:
代价是每种缓解会把成本移到不同的行项(缓存、函数、调度任务)。一旦流量稳定,这仍然通常比持续常驻容量更便宜,但需要测量。
工作负载形态决定最佳成本/性能平衡:
对创始人来说,实用问题是:哪些用户行为需要一致的速度,哪些可以容忍延迟?把数据库模式与这个答案对齐,而不仅仅看账单。
早期你很少知道确切的查询组合、峰值流量或用户采用速度。对无服务器数据库来说,这些不确定性很重要,因为计费与使用紧密相关。目标不是完美预测,而是得到一个“足够好”的区间以避免账单惊喜并支持定价决策。
以代表性的“正常”周为起点(即便来自预发布或小型内测)。衡量供应商计费的几个关键指标(常见:读/写、计算时间、存储、出站)。
然后按三步预测:
这会给出一个区间:预期支出(基线 + 增长)和“压力支出”(峰值乘数)。把压力数视为现金流必须承受的范围。
针对代表性端点运行轻量压测,以估算在 1k、10k、100k 用户 等里程碑下的成本。目的不是完全真实再现——而是发现成本曲线何时发生弯折(例如一个聊天功能使写入翻倍,或某个分析查询触发大范围扫描)。
把假设与结果一起记录:每用户平均请求数、读写比、峰值并发等。
设定月度预算并加入告警阈值(例如 50%、80%、100%)以及“异常峰值”日支出告警。并配备应急玩法:禁用非必要作业、减少日志/分析查询、对昂贵端点进行速率限制。
最后,在比较厂商或不同层时,使用相同的使用假设并在 /pricing 页面核对计划细节,以确保可比性。
无服务器数据库奖励效率,但也会惩罚意外。目标不是“把一切都优化掉”——而是在你仍在学习流量模式时,防止失控支出。
把 dev、staging 与 prod 当作独立产品并分配独立限制。常见错误是让实验性工作负载与客户流量共享同一账单池。
为每个环境设置月度预算并加告警阈值(例如 50%、80%、100%)。开发环境应刻意紧凑:若迁移测试可能消耗真实资金,应使其大声失败。
如果你快速迭代,使用能让“安全变更 + 快速回滚”成为常态的工具会很有帮助。例如像 Koder.ai 这类平台(从对话生成 React + Go + PostgreSQL 应用)强调快照与回滚,让你在保持对成本和性能回归的紧密控制下发布实验。
无法归因就无法管理。从一开始就标准化标签/标识,让每个数据库、项目或计量项能归到某个服务、团队和(理想)功能上。
目标是可执行且能在评审中强制执行的简单方案:
这能把“数据库账单上涨”转变成“发布 X 后搜索读取翻倍”。
大多数成本尖刺来自少数坏模式:频繁轮询、缺分页、无界查询、意外扇出。加入轻量护栏:
当停机的代价小于无限账单的代价时,使用硬上限:
现在构建这些控制,你将来会感谢自己——尤其是当你开始认真做云支出管理与初创公司的 FinOps 时。
无服务器数据库在流量突发且不确定时表现出色。但一旦工作负载稳定且重度,按使用付费的数学可能会反转——有时差别很大。
如果数据库大部分时间都很忙,按使用付费的模型可能会比你可以持续付费的预置实例(或保留容量)更贵。
常见模式是成熟的 B2B 产品在工作时间保持稳定流量,加上夜间运行的后台作业。在这种情况下,固定大小的集群加上保留定价可能带来更低的每请求有效成本——前提是你能保持高利用率。
无服务器并不总是适合:
这些工作负载会造成双重打击:计量使用高与扩缩或并发上限处偶发的性能下降。
价格页看起来可能相似,但计量项不同。比较供应商时,确认:
当你注意到以下趋势时应重新评估:
此时运行一个并行成本模型:当前的 serverless 账单 vs 一个合理尺寸的预置方案(含保留定价),并把你要承担的运维开销计入。如果需要帮助构建该模型,请参见 /blog/cost-forecasting-basics。
当你流量不均且重视快速迭代时,无服务器数据库可能非常合适。但当计量项与产品行为不匹配时也会带来惊喜。使用此清单快速决策,避免签下一份你无法向团队(或投资人)解释的成本模型。
把定价模型与增长不确定性对齐:如果你的流量、查询或数据量可能快速变化,优先选择那些你能用少量可控驱动因子进行预测的模型。
为一个真实功能运行小规模试点,连续每周审查成本一个月,并记录哪一项计量驱动了每一次上涨。如果你无法用一句话解释账单,就不要放大规模。
如果你从零开始构建该试点,考虑你能多快迭代监测与护栏。例如,Koder.ai 可帮助团队快速生成 React + Go + PostgreSQL 应用、在需要时导出源码,并通过规划模式与快照让实验更安全——在你仍在学习哪些查询和工作流将驱动最终单位经济学时非常有用。
传统数据库要求你提前购买(并为之付费)容量——实例规格、副本和保留承诺——无论是否使用。无服务器数据库通常按消耗计费(计算时间、请求、读/写、存储,有时还有数据传输),因此你的成本会随着产品日常行为波动。
因为支出变得可变,并且能比人力或其他费用更快地变化。一点流量增加、新的后台任务或低效查询都可能实质性地改变你的发票,这让成本管理在跑道(runway)问题上比大多数扩展问题更早显现。
常见的计量项包括:
在供应商的 /pricing 页面上始终确认哪些包含在内、哪些单独计费。
先把用户行为映射到可计费单元。例如:
然后跟踪简单比率,比如 每活跃用户成本、每 1,000 次请求成本 或 每笔订单成本,以判断使用(和利润率)是否健康。
常见的“元凶”:
这些看似“每次很小”的费用会放大成显著的月度支出。
Scale-to-zero 可以降低空闲成本,但会带来 冷启动:空闲后第一个请求可能出现额外延迟(取决于服务和查询模式,有时是数百毫秒甚至几秒)。这对内部工具或批处理通常没问题,但对登录、结账、搜索等对 p95/p99 延迟敏感的用户路径风险较大。
采取有针对性的缓解措施:
先测量效果——这些措施可能把成本转移到缓存、函数或调度器等其它服务,但通常比一直保持常驻容量更省。
实用方法是 基线 + 增长 + 峰值乘数:
用“压力支出”数字来规划现金流,而不仅仅依赖平均值。
及早放置轻量护栏:
目标是在学习工作负载模式的同时防止账单失控。
当使用在大部分时间都很稳定且高负载时,按使用付费的成本可能高于预置实例(或保留实例)的成本。如果:
此时对比当前的 serverless 账单与一个合理尺寸的预置部署(含保留价格)及你要承担的运维开销,通常是必要的。