2025年8月26日·2 分钟
如何构建以 AI 为先 的产品:在应用逻辑中使用模型
实用指南:如何构建以 AI 为先 的产品,在此类产品中模型驱动决策,涵盖架构、提示、工具、数据、评估、安全与监控。
什么是“以 AI 为先”的产品
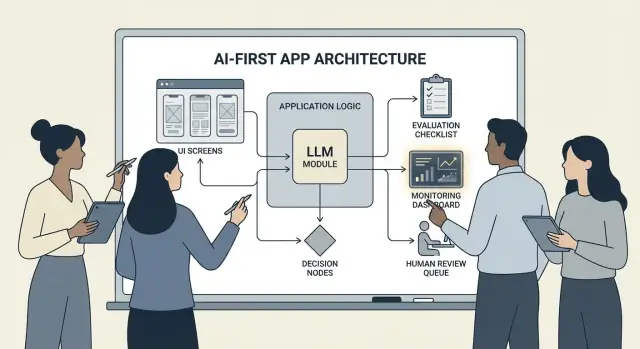
构建“以 AI 为先”的产品并不是简单地“加一个聊天机器人”。它意味着模型是真正的、工作中的应用逻辑的一部分——像规则引擎、搜索索引或推荐算法一样承担决策角色。
你的应用不仅仅是使用 AI;它是围绕模型会如何解释输入、选择动作并产生结构化输出来设计的,而系统的其余部分将依赖这些输出。
在实际层面上:与其将每条决策路径写死(“如果 X 则做 Y”),不如让模型处理那些模糊的部分——语言、意图、歧义、优先级——而你的代码负责必须精确的部分:权限、支付、数据库写入和策略执行。
何时适合采用以 AI 为先(何时不适合)
以 AI 为先 最适合这样的情形:
- 输入形式多样(自由文本、混乱的文档、不同的用户目标)
- 边界情况太多,无法手工维护规则
- 需要判断、摘要或综合信息,而不是完全确定性的输出
规则化自动化通常更适合那些需求稳定且精确的场景——例如税务计算、库存逻辑、资格核验或必须每次输出一致的合规工作流。
以 AI 为先 常见的产品目标
团队通常把模型驱动逻辑用于:
- 提升速度:草拟回复、提取字段、加速请求路由
- 个性化体验:定制解释、计划或推荐
- 支持决策:突出权衡、生成选项、汇总证据
必须接受(并为之设计)的权衡
模型可能不可预测,有时会自信但错误,并且随着提示、提供方或检索上下文变化其行为可能波动。它们还会带来每次请求的成本、增加延迟,并引发安全与信任问题(隐私、有害输出、策略违规)。
正确的心态是:把模型当作一个组件,而不是魔法答案箱。像对待任何依赖一样,为它定义规格、失败模式、测试和监控——这样你能获得灵活性,而不是把产品押注在不切实际的期望上。
选择合适的用例并定义成功
并非每个功能都适合让模型掌舵。最佳的以 AI 为先 用例,始于清晰的待完成工作(job-to-be-done),并以可衡量的结果结束,这些结果可以逐周追踪。
从工作开始,而不是从模型开始
写一个一句话的工作故事:“当 ___ 时,我想要 ___,以便我可以 ___。” 然后把结果量化。
示例:“当我收到一封很长的客户邮件时,我希望得到一条符合我们策略的建议回复,以便我能在 2 分钟内回复。” 这比“给邮箱加个 LLM”更加可执行。
绘制决策点
识别模型将选择动作的时刻。这些决策点应明确,以便你能测试它们。
常见决策点包括:
- 分类意图并路由到正确的工作流
- 决定是否询问澄清问题或继续执行
- 选择工具(搜索、CRM 查询、草拟、工单创建)
- 决定何时升级给人工处理
如果你无法说出这些决策,你还没准备好发布模型驱动的逻辑。
为行为编写验收标准
把模型行为当成任何其他产品需求。用明白易懂的语言定义“好”与“不好”。
例如:
- 好:使用最新策略、引用正确的订单 ID、在信息缺失时只问一个明确问题
- 不好:捏造折扣、引用不支持的地区、或在未核查必要数据时直接答复
这些标准将成为后续评估集的基础。
及早识别约束
列出影响设计选择的约束:
- 时间(响应延迟目标)
- 预算(每次任务成本)
- 合规(PII 处理、审计要求)
- 支持的本地化(语言、语气、文化预期)
定义可监控的成功指标
选一小组与工作相关的指标:
- 任务完成率
- 代表性用例的准确率(或策略遵循率)
- 客户满意度或定性评分
- 每次任务节省的时间(或解决时间)
如果你无法衡量成功,最终会在“感觉”上争论,而无法改进产品。
设计 AI 驱动的用户流程与系统边界
AI 驱动的流程不是“一个界面调用 LLM”。它是一个端到端的旅程,模型做出某些决策,产品安全地执行这些决策,并保持用户的可理解性。
绘制端到端闭环
先把管道画成一条简单链条:输入 → 模型 → 动作 → 输出。
- 输入: 用户提供的内容(文本、文件、选择)以及应用上下文(账户等级、工作区、最近活动)。
- 模型步骤: 模型负责决定的内容(分类、草拟、摘要、选择下一步动作)。
- 动作: 系统可能采取的操作(搜索、创建任务、更新记录、发送邮件)。
- 输出: 用户看到的内容(草稿、解释、确认界面、带下一步操作的错误提示)。
这个地图会强迫你明确哪些地方可以接受不确定性(例如草拟),哪些地方不行(例如计费变更)。
划分系统边界:模型 vs 确定性代码
把确定性路径(权限检查、业务规则、计算、数据库写入)与模型驱动决策(解释、优先级、自然语言生成)分离。
一个实用规则:模型可以建议,但在任何不可逆操作前,代码必须验证。
决定模型运行位置
根据约束选择运行时:
- 服务器端: 适合私有数据、一致工具链、审计日志。
- 客户端: 有利于轻量级辅助和本地处理以增强隐私,但更难控制。
- 边缘: 提供更快的全球延迟,但依赖受限。
- 混合: 在边缘进行快速意图检测,复杂工作放到服务器处理。
预算延迟、成本与数据权限
设定每次请求的延迟与成本预算(包含重试与工具调用),并基于此设计 UX(流式、渐进结果、“后台继续”)。
记录在每一步需要的数据源与权限:模型可以读取什么、可以写入什么、哪些需要用户明确确认。这成为工程与信任的契约。
架构模式:编排、状态与追踪
当模型成为应用逻辑的一部分时,“架构”不仅仅是服务器与 API——而是如何可靠地运行一连串模型决策且不丢失控制权。
编排:模型工作流的指挥者
编排层管理 AI 任务的端到端执行:提示与模板、工具调用、记忆/上下文、重试、超时与回退。
优秀的编排器把模型当作管道中的一个组件:决定使用哪个提示、何时调用工具(搜索、数据库、邮件、支付)、如何压缩或获取上下文,以及当模型返回无效内容时怎么办。
如果想更快从想法到可工作的编排,vibe-coding 工作流有助于在不重建应用骨架的情况下快速原型这些管道。例如,Koder.ai 允许团队通过聊天创建 Web 应用(React)、后端(Go + PostgreSQL),甚至移动应用(Flutter)——然后对“输入 → 模型 → 工具调用 → 验证 → UI”这类流程进行迭代,支持规划模式、快照与回滚,并在准备好接管代码时导出源码。
用状态机处理多步骤任务
多步骤体验(分诊 → 收集信息 → 确认 → 执行 → 汇总)适合用工作流或状态机建模。
一个简单模式是:每一步定义 (1) 允许的输入,(2) 期望的输出,以及 (3) 转移条件。这能防止漫无目的的对话,并让边界情况变得明确——例如用户改变主意或提供部分信息时怎么办。
单次与多轮推理
单次(single-shot)适用于封闭任务:对信息分类、草拟简短回复、从文档中提取字段。它更便宜、更快且更容易验证。
多轮推理适合模型需要询问澄清问题或需要迭代调用工具的场景(例如:计划 → 搜索 → 改进 → 确认)。有意使用它,并对循环次数/步骤设置上限。
幂等性:避免重复副作用
模型会重试,网络会失败,用户会双击。如果 AI 步骤会触发副作用(发送邮件、预订、扣费),务必保证幂等。
常见做法:为每个“执行”动作附加幂等键,存储动作结果,确保重试时返回相同结果而不是重复操作。
跟踪:让每一步可调试
添加可追溯记录,以便回答:模型看到了什么?它决定了什么?哪些工具被调用?
为每次运行记录结构化追踪:提示版本、输入、检索到的上下文 ID、工具请求/响应、验证错误、重试与最终输出。这样“模型做了奇怪的事”就能变成可审计、可修复的时间线。
把提示当成产品逻辑:清晰的契约与格式
当模型是应用逻辑的一部分时,提示就不再是“文案”,而是可执行的规范。把它们当作产品需求:明确范围、可预测输出与变更控制。
从定义契约的系统提示开始
你的系统提示应设定模型的角色、能做与不能做的事以及产品相关的安全规则。保持稳定与可复用。
应包括:
- 角色与目标: 它是谁(例如“支持分诊助理”)以及成功的衡量方式。
- 范围边界: 必须拒绝或升级的请求。
- 安全规则: PII 处理、医疗/法律免责声明、不做猜测。
- 工具策略: 何时调用工具,何时直接回答。
用清晰的输入/输出结构化提示
像写 API 一样写提示:列出你提供的确切输入(用户文本、账户等级、本地化、策略摘录)以及你期望的确切输出。加入 1–3 个匹配真实流量的示例,包括棘手的边界情况。
一个有用的模式是:上下文 → 任务 → 约束 → 输出格式 → 示例。
使用受限格式以获取机器可读结果
如果代码需要消费输出,不要依赖散文。要求返回匹配模式的 JSON,并拒绝其他格式。
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
对提示进行版本控制并安全发布
将提示存入版本控制、对发布打标签,并像发布功能一样逐步上线:分阶段部署、A/B(如适用)和快速回滚。在每个响应中记录提示版本以便调试。
构建提示测试套件
创建一小组具有代表性的用例(正常路径、模糊请求、策略违规、长输入、不同本地化),在每次提示变更时自动运行,输出若破坏契约则构建失败。
工具调用:让模型决定,让代码执行
迈向规模化
随着 AI 功能增长,从个人原型转向共享工作空间。
工具调用是分离职责的最清晰方式:模型决定需要做什么、用哪个能力,而你的应用代码去执行该动作并返回经验证的结果。
这将事实、计算与副作用(创建工单、更新记录、发送邮件)放在确定性、可审计的代码中,而不是信任自由文本。
设计小而周到的工具集
从能覆盖 80% 请求且易于加固的一小组工具开始:
- Search(你的文档/帮助中心)用于回答产品问题
- DB lookup(先做只读)获取用户/账户/订单状态
- Calculator 用于定价、总额、换算和规则性计算
- Ticketing 在用户需要人工跟进时创建支持请求
保持每个工具的用途窄而明确。能“做任何事”的工具难以测试且容易被滥用。
验证输入,清理输出
把模型当作未经信任的调用者对待。
- 验证工具输入:用严格的模式(类型、范围、枚举)校验。拒绝或修复不安全的参数(例如缺失 ID、过于宽泛的查询)。
- 清理工具输出:在将结果交回给模型前清除敏感信息、规范化格式,并仅返回模型需要的字段。
这样可以降低通过检索文本发生的提示注入风险,并限制意外数据泄露。
为每个工具添加权限与速率限制
每个工具应强制执行:
- 权限检查(谁能访问哪些记录、哪些动作)
- 速率限制(按用户/会话/工具),以减少滥用与无限循环
若工具能改变状态(工单、退款),要求更强的授权并写入审计日志。
始终支持“不调用工具”的路径
有时最好的动作是不行动:直接用现有上下文回答、询问澄清问题或说明限制。把“不调用工具”作为一等结果,防止模型为了显得忙碌而盲目调用工具。
数据与 RAG:让模型以你的现实为依据
如果产品的答案必须与公司的策略、库存、合同或内部知识一致,你需要让模型基于你的数据——而不仅仅是其通用训练。
RAG、微调与简单上下文的权衡
- 简单上下文(在提示中粘贴几段)适用于知识量小、稳定且每次可承担发送成本的场景(例如简短定价表)。
- RAG(检索增强生成) 适用于信息量大、频繁变化或需要引用来源的场景(例如帮助中心文章、产品文档、账户特定数据)。
- 微调 适合希望模型风格/格式一致或领域模式明显的情况——不要把微调作为存储事实的主要方式;用它改善写作与规则遵循,并与 RAG 配合以保证事实最新。
摄取基础:分块、元数据、时效性
RAG 的质量更多取决于摄取策略。
把文档分成适合模型处理大小的块(通常为几百个 token),最好按自然边界分割(标题、FAQ 条目)。存储元数据:文档标题、章节、产品/版本、受众、本地化和权限信息。
规划新鲜度:安排重建索引、追踪“最后更新”并让过期块失效。一个高权重但已陈旧的块会悄然降低整个功能的质量。
引用与校准化的答案
让模型返回引用: (1) 答案,(2) 片段 ID/URL 列表,(3) 置信说明。
若检索薄弱,指示模型说明它不能确认的内容并提供下一步建议(“我找不到该政策;建议联系 X”)。避免让模型填空式猜测。
私有数据:访问控制与脱敏
在检索之前执行访问控制(按用户/组织过滤),在生成之前再次脱敏敏感字段。
把嵌入与索引视为敏感数据存储,并做审计。
当检索失败时:优雅的回退
若顶级结果无关或为空,回退选项包括:询问澄清问题、路由到人工支持,或切换到非 RAG 的响应模式,明确说明限制而不是猜测。
可靠性:护栏、验证与缓存
当模型处在应用逻辑中,“大多数时候表现良好”不够。可靠性意味着用户看到一致的行为,系统可以安全地消费输出,且失败会优雅降级。
在修复前先定义可靠性目标
写明功能的“可靠”如何衡量:
- 输出一致性: 相似输入应产生可比答案(语气、细节层级、约束遵守)。
- 格式稳定性: 输出必须可解析(JSON、表格、项目符号)。
- 行为有界: 明确模型不该做的事(不做猜测、引用来源、在不确定时发问)。
这些目标成为提示与代码的验收标准。
护栏:验证、过滤与政策强制
把模型输出当作不受信任的输入。
- 模式验证: 要求严格格式(例如含必需键的 JSON),不解析则拒绝。
- 内容过滤: 在用户输入与模型输出上运行脏话检测、PII 检测或策略验证器。
- 业务规则: 在代码中强制约束(价格范围、资格规则、允许的动作),即便提示里也提到了这些规则。
若验证失败,返回安全回退(询问澄清、切换到更简单的模板或路由给人工)。
真正有用的重试
避免盲目重复。用改变过的提示重试以应对失败模式:
- “只返回有效 JSON。不要输出 markdown。”
- “若不确定,请把
confidence设为低并问一个问题。”
限制重试次数并记录每次失败原因。
确定性的后处理
用代码规范化模型输出:
- 规范化单位、日期与名称
- 去重条目
- 应用排序规则或阈值
这能降低方差,使输出更易测试。
在不泄露隐私的前提下缓存
缓存可重复结果(相同查询、共享嵌入、工具响应)以降低成本和延迟。
优先考虑:
- 针对用户特定数据使用短 TTL
- 缓存键排除原始 PII(或谨慎哈希)
- 对敏感流程设置“不缓存”标志
做得好,缓存能在保持用户信任的同时提升一致性。
安全与信任:在不破坏体验的前提下降低风险
交付完整应用栈
一次对话生成 React 前端及 Go + PostgreSQL 后端。
安全不是你在最后附加的合规层。在以 AI 为先 的产品中,模型会影响动作、措辞与决策——因此安全必须成为产品契约的一部分:助理被允许做什么、必须拒绝什么、何时寻求帮助。
需要设计的关键安全点
列明你的应用实际面临的风险,并为每一项匹配控制措施:
- 敏感数据: 个人标识符、凭证、私有文档与受监管信息
- 有害指引: 可能导致自我伤害、暴力、非法行为或不安全医疗/财务操作的指示
- 偏见与不公平结果: 服务质量、推荐或决策在不同群体间不一致
允许/禁用主题与升级路径
写一套可执行的产品策略:具体分类、示例与期望的响应。
使用三层策略:
- 允许: 正常回答。
- 受限: 以受限形式回答(例如仅给一般信息,不提供逐步指导)。
- 阻断: 拒绝并走升级路径(支持、资源或人工代理)。
升级应是产品流而非仅仅一条拒绝消息。提供“与人工沟通”选项,并确保交接时包含用户已共享的上下文(经用户同意)。
对高影响操作的人工复核
如果模型可能触发真实后果——付款、退款、账户变更、取消、数据删除——增加检查点。
良好模式包括:确认屏、“先草拟再批准”、限额(金额上限)以及边界情况的人工复核队列。
披露、同意与可测试的政策
告诉用户他们在与 AI 交互、使用了哪些数据以及哪些被存储。需要时征求同意,尤其是保存对话或使用数据改进系统时。
把内部安全策略当作代码来管理:版本化、记录理由并增加测试(示例提示 + 期望结果),以防随着提示或模型更新导致安全回归。
评估:像对待其他关键组件那样测试模型
如果 LLM 会改变你的产品行为,你需要可重复的方法证明它仍然有效——在用户发现回归之前。
把提示、模型版本、工具 schema 与检索设置当作发版级别的工件,需要测试。
从真实场景构建评估集
收集来自支持工单、搜索查询、聊天日志(经同意)和销售通话的真实用户意图。把它们变成测试用例,包含:
- 常见的正常路径请求
- 需要澄清问题的模糊提示
- 边界情况(缺失数据、冲突约束、不寻常格式)
- 涉及策略的敏感场景(个人数据、被禁止内容)
每个用例应包括期望行为:答案、所采取的决策(例如“调用工具 A”)以及任何必需的结构(JSON 字段存在、包含引用等)。
选择匹配产品风险的指标
单一分数无法捕捉质量。选择一小组映射到用户结果的指标:
- 准确率/任务成功率: 是否完成用户目标?
- 有据性(groundedness): 论断是否由提供的上下文或来源支持?
- 格式有效性: 输出是否符合契约(JSON、表格、项目符号)?
- 拒绝率: 应拒绝时是否拒绝,以及不应拒绝时是否避免拒绝?
同时追踪成本与延迟;更好的模型若使响应时间翻倍,可能会损害转化率。
在每次变更前运行离线评估
在发布前以及每次提示、模型、工具或检索更改后运行离线评估。版本化结果以便比较运行并快速定位问题。
添加在线测试并设护栏
用在线 A/B 测试衡量真实结果(完成率、编辑率、用户评分),但加入安全护栏:定义停止条件(例如无效输出、拒绝或工具错误激增)并在超过阈值时自动回滚。
生产监控:漂移、失败与反馈
上移动端
用相同的聊天工作流为你的以 AI 为核心的产品添加 Flutter 移动应用。
发布 AI-first 功能不是终点。真实用户会带来新的表述、边界情况与变化数据。监控能把“在预发布环境工作”变成“下个月依然可靠运行”。
记录重要信息(但不要收集敏感信息)
记录足够的上下文以重现失败:用户意图、提示版本、工具调用以及模型最终输出。
带隐私安全的脱敏方式记录输入/输出。把日志当作敏感数据处理:剥离邮箱、电话号码、令牌与可能包含个人信息的自由文本。保持可以对特定会话临时开启的“调试模式”,而不是默认最大化记录。
监控正确的信号
监控错误率、工具失败、格式违例与漂移。具体追踪:
- 工具调用成功率与超时(模型是否选对工具且执行成功?)
- 输出格式/模式合规率(验证器是否拒绝?)
- 回退使用率(不得不走更安全/更简单路径的频率)
- 内容安全阻断(拒绝或脱敏发生的频率)
对于漂移,比较当前流量与基线:主题分布变化、语言变化、平均提示长度与“未知”意图的增减。漂移不总是坏事——但它总是需要重新评估的信号。
告警、运行手册与事故响应
设定告警阈值与值班运行手册。告警应映射到具体动作:回滚提示版本、禁用不稳定工具、收紧验证或切换到回退。
为不安全或不正确行为规划事故响应。定义谁能触发安全开关、如何通知用户以及如何记录与复盘事件。
用用户反馈闭环
使用反馈回路:点赞/点踩、原因代码、错误报告。提供轻量的“为什么?”选项(事实错误、未遵循指示、不安全、太慢),以便把问题路由到正确的修复方向——提示、工具、数据或策略。
针对模型驱动逻辑的 UX:透明与控制
当模型驱动功能工作良好时,它们感觉像魔法;当它们失败时则显得脆弱。UX 必须假定不确定性存在,同时仍帮助用户完成任务。
在不让人负担过重的情况下展示“为什么”
当用户能看到输出来源时,他们更信任 AI——不是因为想要解释,而是因为这有助于他们决定是否采取行动。
使用渐进式披露:
- 先展示结果(答案、草稿、推荐)。
- 提供“为什么?”或“展示过程”切换,揭示关键输入:用户请求、使用的工具以及所检索的来源或记录。若使用检索,展示能跳转到精确片段的引用(例如“根据:政策 §3.2”)。保持易读。
- 若有更深入的解释,放到站内链接(例如 /blog/rag-grounding),不要把界面塞满细节。
为不确定性设计(不要使用可怕的警告)
模型不是计算器。界面应传达置信度并邀请核验。
实用模式包括:
- 用自然语言提示置信度(“可能正确”、“需要复核”)而非伪精确数字。
- 提供多个选项而非单一答案:“这里有 3 种回复方式。” 这能降低首选答案出错的成本。
- 对高影响操作做确认(发送邮件、删除数据、付款):问一个清晰的问题:“确定要发给 12 个收件人吗?”
让更正与恢复变得轻而易举
用户应能在不中断流程的情况下引导输出:
- 内联编辑并“应用更改”,让模型从用户修改处继续生成。
- 提供附带控制项的“重新生成”(语气、长度、约束)而不是盲目重试。
- 提供“撤销”和可见历史,确保错误可回滚。
提供人工脱身口
当模型失败或用户不确定时,提供确定性流程或人工帮助。
示例:“切换到手动表单”、“使用模板”或“联系支持”(例如 /support)。这不是有激光的回退,而是保护任务完成与信任的手段。
从原型到生产(无需重建一切)
大多数团队失败并非因为 LLM 无能,而是因为把原型转为可靠、可测试、可监控的功能所需的路径比预期更长。
缩短这条路径的实用方法是尽早标准化“产品骨架”:状态机、工具 schema、验证、追踪以及部署/回滚流程。当你想快速搭起 AI-first 工作流时,像 Koder.ai 这样的平台可以帮助你迅速构建 UI、后端与数据库,并通过快照/回滚、安全域名与托管来安全迭代。准备把功能落地到自己的 CI/CD 与可观测性栈时,还可以导出源码继续维护。