2025年8月28日·1 分钟
印度电商搜索的自动补全与拼写容错
了解针对印度电商搜索的自动补全与拼写容错:通过同义词规划、本地术语、音译规则和分析来提升搜索结果。
为什么印度商品命名会打破搜索
印度电商搜索失败的一个简单原因是:人们不会以相同的方式为同一件商品命名。相同的商品可能用英语、印地语、泰米尔语或二者混合输入,而且每个地区都有自己的日常用词。
一个购物者可能搜索 “atta”、“aata”、“gehu ka atta” 或仅输入品牌名。另一个人则输入 “jeera”、“zeera” 或只是 “cumin”。如果你的目录里只有其中一种写法,一个非常普通的查询可能返回空结果。
小的拼写差异比你想象的更容易造成伤害,因为搜索引擎常把查询当作精确文本处理。少一个元音、额外的空格或词序不同,都可能把正确的商品挤出前排结果,甚至导致零结果。
印度商品名称分裂成多种写法的常见原因:
- 多种文字与音译(用英文字母写印地语、本地拼写差异)
- 同一物品的区域性称呼(食物、服装、家居用品)
- 品牌优先和通用命名的差异(“Surf Excel 1kg” vs “detergent powder”)
- 缩写和口语形式(“kurti” vs “kurta top”,“1 ltr” vs “1L”)
- 键盘打字错误与自动纠正(“pista” 变成 “pita”,“saree” vs “sarri”)
自动补全和拼写容错改变了购物者的体验。自动补全通过在用户按下搜索前引导他们使用你商店理解的词汇来减少操作。拼写容错则防止“几乎正确”的查询失败,使购物者即使拼写不完美也能看到相关商品。
针对印度电商搜索,自动补全与拼写容错的实际目标不是“完美的语言支持”。它是可衡量的:更少的零结果搜索和更快的商品发现,从而更多购物者看到商品列表而不是走到死胡同。
关键思想(通俗说法)
在印度做好的搜索,与其说是高大上的算法,不如说是理解人们实际如何输入商品名称。许多购物者在英文和本地方言间切换,同一个词可能有三种写法,但他们仍然期望搜索能“理解”它。
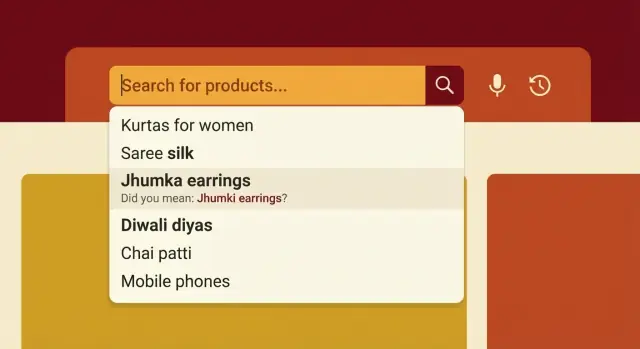
自动补全是在查询完成前提供帮助的部分。当有人输入 “jeer…” 时,你可以建议 “jeera rice”、“jeera powder” 或 “jeera whole”。做得好时,自动补全能减少输入并温和地引导购物者使用你目录中存在的词语。
拼写容错意味着当用户犯下常见错误时,你仍然能匹配到正确结果,例如 “zeera” vs “jeera” 或 “shampo” vs “shampoo”。目标是修复常见错误而不改变原意。过度的拼写容错会带来奇怪的匹配(例如短查询 “ram” 突然匹配到无关商品)。
同义词很简单:不同的词,相同的意图。“Atta” 和 “wheat flour” 应该指向同一组商品。在印度电商里,同义词经常包括品牌式的称呼(“biscuit” vs “cookies”)、地区化用语和品类昵称。
音译是指人们用英文字母输入印度语单词。有人可能会输入 “namkeen”、“nimeen” 或 “namkin”,这取决于习惯和键盘。音译规则帮助你匹配这些变体,即使目录只有一种写法。
把自动补全和拼写容错的实用思路总结为:
- 自动补全引导用户走向有效且流行的查询。
- 拼写容错在用户拼错时拯救他们。
- 同义词将不同词语连接到相同的购物意图。
- 音译将不同拼写连接到相同的本地语言术语。
明确这些后,你可以先构建一套小而受控的映射集合,并通过真实搜索分析逐步扩展,而不是凭空猜测。
构建你的印度命名词典(需要收集的输入)
好的搜索词典应从你的数据出发,而不是猜测。目标很简单:捕捉人们在印度实际如何命名商品,包括本地术语、拼写和速记,这样自动补全与拼写容错就有可靠的数据可用。
首先,挖掘你的目录。商品标题、类别名、属性、变体标签、品牌、包装尺寸和单位通常包含“官方”措辞,购物者应能通过这些措辞找到商品。对于生鲜杂货,这可能包含通用和具体术语,例如同时包含 “toor dal”、“arhar dal” 和 “split pigeon peas”。
接着,收集真实的客户语言。搜索日志显示人们匆忙时输入的内容,客服聊天则揭示用户描述商品的方式。即便几周的日志也能显示重复模式,比如 “aata/atta”、“dahi/curd” 或 “chilli/chili”。
从五个来源构建输入,然后合并清洗:
- 目录文本(标题、属性、变体、品牌、尺寸)
- 搜索查询(包括零结果查询)
- 客服聊天记录与通话记录
- 团队已有的区域和本地术语
- 单位与捆绑速记(ml、ltr、pcs、combo、1+1)
最后,把通用词和品牌词分开。“Atta” 应该匹配很多商品,而品牌名不应意外拉来无关商品。保持两个有标签的列表(通用 vs 品牌),以便后面的规则不会混淆意图或干扰排序。
逐步操作:创建同义词与音译计划
从小做起。挑 20 到 50 个推动大部分搜索和收入的品类,比如主食、美妆和热门电子产品。这能让工作集中并快速看到对自动补全和拼写容错的影响。
然后建立一个共享的“命名表”,每个人都能编辑(商品、内容、客服)。先用电子表格管理,然后同步到搜索索引。
1) 制定规范列表
为每个品类选一个你希望系统作为“主要”名称(规范词)。选择客户认可的说法,而不是供应商的命名。
创建类似的行:
| Canonical term | Synonyms (same product) | Common misspellings | Transliterations | Notes |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Keep “caraway” separate |
| face wash | cleanser | fash wash | fes wash | Don’t map to “face cream” |
把单位和包装模式作为可复用的独立令牌:1kg、500 g、2x、combo pack、family pack。用户输入完整的带单位查询时常造成零结果。
2) 制定严格的“同品”规则
同义词应当意味着客户对同一组搜索结果感到满意。写出简短规则以供团队遵循:
- 允许:区域性名称变体、品牌简称、常见拼写
- 允许:意义不变的 Hinglish 音译
- 不允许:邻近但不同商品(cleanser vs toner、cumin vs carom)
- 不允许:不同尺寸作为同义词(尺寸应作为筛选)
- 不允许:用“healthy”或“premium”替代基础商品
3) 保持易于维护
为每个品类指定一名负责人,并设置简单的复审节奏(起初每周)。当客服看到“找不到”的投诉时,应在当天把相关词加入表格。
如果你在构建自定义搜索堆栈,像 Koder.ai 这样的工具可以帮助你快速交付管理界面与同步工作流,同时保持同义词列表对非技术团队可编辑。
设计适合印度的自动补全体验
自动补全应当感觉快速、熟悉且宽容。对印度电商搜索来说,最大收益在于前 2 到 4 个字母就给出有用建议。人们常常打字快,在英语与本地用语间切换,也不总记得准确拼写。
先优化前缀。前 2 到 4 个字符就应该显示强烈的高意图建议。如果有人输入 "sha",不要把前排位置浪费给罕见商品。展示大多数购物者的真实意图以及你有充足库存的商品。
让建议具有类别感知,而不只是词感知。如果用户输入本地词如 "shakkar",建议应清晰指向商品类别(糖)以及你常备的子类型(细砂糖、有机等)。这能减少混淆并降低用户选择无关结果的概率。
保持建议简短可读。一个好模式是:品牌 + 商品(当品牌确实常见)或 商品 + 关键属性。避免在一行塞入尺寸、长型号和多个属性。
下面是通常有效的 UI 规则:
- 显示 5 到 8 条建议,前 3 条优化转化率。
- 规范化空格与标点,使 “t-shirt”、“tshirt” 和 “t shirt” 导向相同建议集合。
- 优先显示你能拣货并发货的商品(有库存、在售)。
- 类型混合要谨慎:1 到 2 条类别建议,然后是商品,再是品牌。
- 不要显示你无法销售的建议(无效类别、已停产品牌)。
示例:用户输入 "dett"。在印度很多人可能是指 “Dettol”(品牌意图),但也有人想找 “handwash” 或 “sanitizer”(商品意图)。你的自动补全可以显示 “Dettol Handwash”、“Dettol Sanitizer” 和一个像 “Handwash” 的类别建议,这样两类意图都被覆盖而不至于过度猜测。
当你持续这样做时,印度电商搜索的自动补全与拼写容错就不再依赖奇技淫巧,而是成为帮购物者迈出下一个明显步骤的工具。
设置拼写容错但避免杂乱匹配
在移动端测试搜索
创建轻量级 Flutter 应用,用于搜索质量测试和随时快速规则审核。
拼写容错能在用户输入错误时帮他们找到商品。但如果容错太宽松,搜索会开始显示“凑合”的商品,感觉很不对。目标很简单:捕获明显错误,对可能改变意图的情况保持谨慎。
从基于词长的安全编辑距离规则开始。短词更容易出错,所以保持严格;长词可以允许更多容错。
- 1–4 个字母:允许 0–1 次编辑(例如 “atta” -> “atta”,“atta” -> “attta”)
- 5–8 个字母:最多允许 2 次编辑
- 9+ 个字母:最多允许 3 次编辑
- 如果查询包含多个词,对每个词分别应用编辑限制,但为整个查询设置一个总编辑上限
把数字单独处理。“1kg” 和 “10kg” 不应互换,“500ml” 不应变成 “1500ml”。实用规则是:不要在数字令牌内应用拼写容错,也不要改变单位。只允许格式修正,如空格或大小写差异(“1 kg”、“1KG”、“1kg”)。
保护品牌名和高意图词免被“纠正”为通用词。保留一个小型保护列表(顶级品牌、私有品牌和常见的品牌式查询)。如果查询与保护词高度接近,优先显示建议而不是静默改写。
移动端常见键位相邻错误,尤其在 Hinglish 输入时。对邻键错误(a-s、i-o、n-m)增加额外容错,但仅在单词其余部分匹配很强时才应用。
当纠正存在歧义时,把纠正作为建议显示,而不是静默替换。例如,当 “dove” 可能成为 “done” 或 “dovee” 时,显示 “Did you mean dove?”(你是指 dove 吗?)并保留原始结果可见。这能维护信任并减少用户反感的返回操作。
音译与本地语词条(实用规则)
印度查询经常在一行中混合脚本与习惯写法:“जीरा rice”、“jeera चावल”、“zeera rice” 或 “poha nashta”。你的搜索应把这些当作相同意图,而不是分离的世界。自动补全与拼写容错的目标很简单:把多种写法映射到一个清晰的商品含义。
从一套小而实用的规则开始,只有在看到效果后再扩展。
实用规范化规则
- 允许脚本混合,通过将所有输入规范化为共享的“搜索形式”来匹配(保留原始查询用于分析)。
- 先为热门条目添加音译对(例如:namkeen、bhujia、poha、jeera),包含用户实际输入的常见写法。
- 在重要时对长元音变体做显式配对处理(poha vs pauha、jeera vs zeera),而不是尝试猜测所有元音变化。
- 谨慎且窄范围地使用发音替换:v-w、b-v、j-z。仅在已知的商品令牌上应用,避免对整句生效以免产生奇怪匹配。
- 对品牌名和 SKU 多保留“按原样输入”的策略,不要轻易把它们改写成别的东西。
先支持哪些语言
基于流量和零结果情况选择优先级,而不是按宏大的目标排序。常见顺序是先支持英语加 Hinglish,然后在有意义的查询量时加入印地语文字脚本。若后续在某区域看到需求,再按品类逐步扩展。
分析闭环:基于真实行为改进搜索
从想法到代码
通过聊天提示构建用于搜索配置流程的 React UI 和 Go API。
搜索质量不是一次性设置。把它当成每周例行工作:观察人们输入什么、点了什么以及在哪里放弃。通过这种方式,自动补全与拼写容错会在没有猜测的情况下变好。
从一小组核心指标开始,并在数周内保持一致:
- 零结果率(整体和热门查询)
- 细化率(用户在搜索后重输或添加筛选)
- 搜索后的加入购物车率(如果购物车数据嘈杂,可用搜索后商品点击代替)
- 自动补全使用率(建议点击 vs 完全手动输入)
- 纠正影响(拼写修正后导致点击 vs 跳出)
每周抽出时间,拉出顶部无结果查询并逐条分类。保持分类简单,便于团队实际使用:缺少同义词(jeera vs zeera)、拼写变体、品牌或型号不匹配、错误的语言/脚本,或目录缺货。目标是区分“搜索需要同义词”与“库存缺失”。
自动补全数据通常是最快的改进点。如果用户经常忽略建议并完成输入,说明建议可能过于通用、顺序不对或缺少本地词。如果用户点击建议但仍然细化或跳出,说明建议看起来对但带来的结果质量不足。
拼写修正需要审核,而不仅仅是提高容错率。每周抽样 20–50 条被修正的查询并标记为:
- 有帮助(修正到预期商品)
- 无害(足够接近,用户仍找到商品)
- 有害(修正到不同商品或类别)
把这些放在一个简单的仪表板中,产品和市场团队能在 2 分钟内读懂:顶部零结果查询及分配原因、热门自动补全建议和点击率,以及下一次发布的短行动清单。如果你快速构建内部工具(例如,用 Koder.ai),这个仪表板和每周导出流水线是很好的第一批项目。
常见错误与陷阱
印度的大多数搜索问题并不是“增加更多同义词”能解决的。它们来自一些可预测的错误,会逐步把用户推到错误结果并损害信任。
最大的陷阱之一是使用过宽的同义词把不同商品合并。如果把 “cream” 和 “lotion” 互换,想要厚重面霜的用户可能会看到轻薄身体乳,然后流失。保持同义词紧凑:映射相同意图的变体,而不是邻近类别。
另一个常见错误是忽视包装尺寸与单位意图。“Oil 1L” 和 “oil 5L” 不是同一购物任务,“atta 5 kg” 和 “atta 10 kg” 也不同。如果规则忽略单位,想囤货的用户可能会看到小包装,导致排序看起来很随机。
这里有高影响的错误要注意:
- 把相近商品当成同义词(cream vs lotion、shampoo vs conditioner)
- 忽视尺寸、数量和单位词(1L、5L、500 ml、10 pcs)
- 让拼写容错把品牌名改成其他品牌
- 显示你无法按该邮编配送的建议
- 设定好规则后就不再检查,尤其在促销和季节性波动后
品牌名需要额外小心。如果有人输入 “Himalya face wash” 而你的拼写设置把它“纠正”成另一个也很流行的品牌,会让用户感觉像诱导。更安全的规则是:对通用词宽容,对品牌和型号类令牌严格一些。
自动补全在建议缺货商品时也会适得其反。例如,因为“ghee 2L” 是热门查询而建议它,但实际上只有 1L 有货,会让用户失望。优先显示你今天能履约的建议。
如果你正在构建自动补全与拼写容错功能,建立复查习惯:在销售周后检查新增热门查询、上升的拼写错误和零结果词。哪怕是季节性的小变化(婚庆季、雨季、考试季)也会改变人们的搜索方式。
如果想快速验证规则变更,Koder.ai 可以帮助你原型化一个搜索规则服务和管理页面,用于管理同义词、单位和品牌保护,并在准备好时导出代码。
真实示例:修复 “jeera rice” 与 “zeera rice” 搜索
一个购物者输入 “zeera rice” 却得到零结果。他们并不是在寻找不同的商品,而是想说 “jeera rice”(孜然饭),只是按说法拼写了。“zeera” 在很多习惯里是 “jeera” 的写法。
你可以通过两项小而安全的改动解决这个问题:为常见拼写变体添加同义词,并设定保守的拼写规则。对这个查询,把 “zeera” 视为 “jeera” 的音译变体,而不是一个独立含义。
通常有效的映射如下:
- 查询同义词:zeera -> jeera
- 查询同义词:zira -> jeera
- 保持目录中商品命名不变(不要重命名 SKU)
然后添加一个对短词严格的拼写容错规则。例如,仅当令牌长度 >= 5 时允许 1 次编辑。这样既能捕捉 “jeera” vs “jeeraa” 的情况,又能避免短令牌带来的糟糕匹配。
改进后,自动补全应引导购物者而不是过度猜测。当他们输入 “zee…” 时,建议可以是:
- “jeera rice”
- “jeera basmati rice”
- “jeera (cumin)”
当他们提交 “zeera rice” 时,结果应优先展示你的 “jeera rice” 商品,并根据排序规则展示相关项如 cumin 和 basmati。
一周后,检查面向行为的电商搜索分析,而不仅仅看点击数:
- “zeera”、“zira” 和 “jeera” 的零结果率
- 搜索细化率(用户是否重输查询)
- 这些查询的加入购物车率
- 最高点击项以确认同义词没有拉入无关商品
如果结果变差(例如 “zira” 开始匹配某个品牌或别的类别),快速回滚,只禁用该同义词组,而不是撤销整个自动补全与拼写系统。保持简单的版本化配置以便在几分钟内恢复。
这种紧密的反馈回路就是印度电商搜索自动补全与拼写容错改进的核心。
上线前的快速检查清单
降低构建成本
通过与 Koder.ai 分享你的作品或邀请团队成员获取积分。
在推送新的同义词、自动补全或拼写设置前,做一次混合真实查询数据与人工测试的快速检查,防止“有帮助”的改动带来噪音结果(例如因为两个词形相近而匹配到错误商品)。
使用下面的预发布清单:
- 拉取最近 7–14 天内的前 50 条搜索查询,并按意图分组(品牌、通用商品、变体如尺寸或颜色,以及要解决的问题如 “hair fall oil”)。若查询有双重含义,记录两种可能。
- 拉取前 50 条零结果查询并为每条决定修复策略:映射到现有类别、添加同义词(本地词或拼写)、补充缺失商品或屏蔽无关查询。不要把它们留到“以后再修”。
- 在你的同义词与音译列表中记录负责人、最后更新时间和简短原因,避免出现随机编辑(例如在不同地方以三种写法重复添加 “atta = aata = aataa”)。
- 用真实用户的措辞在热门类别测试自动补全:尝试英文、Hinglish 和常见速记。检查建议是否不会过早跳到小众商品,并确认包含常见变体(如 “1kg”、“500g”、“pack of 2”)。
- 用 20 个棘手查询压力测试拼写容错:品牌拼写错误(尤其双写字母)、混合数字(“iPhone 15 pro 256”)和相似单词(“jeera/zeera”、“besan/besan flour”)。确认顶部结果仍然正确,而不仅仅是“接近正确”。
若有任何项不通过,先发布小范围变更。小步发布往往优于一次性大改带来的随机体验。
下一步:简单的发布计划(以及更快构建的方法)
从一个搜索痛点明显的品类开始,例如杂货、个人护理或手机配件。把范围控制在一周内,这样可以观测因果关系。选择 2–3 个你实际能影响的成功指标,例如零结果率、搜索到商品点击率和搜索后加入购物车率。
一个行之有效的简单发布流程如下:
- 第 1 天:基线采集——记录当前指标、热门查询和热门零结果查询(针对该品类)。
- 第 2–3 天:发布小词典——为前 50 个热门查询添加有限的同义词与 Hinglish 音译,并加入前 20 个品牌或包装/尺寸模式。
- 第 4 天:添加保护措施——对意义变化的查询加入排除规则(例如如果 “ATA” 是目录中的品牌或编码,不应与 “atta” 混淆)。
- 第 5–6 天:监控——跟踪改进(零结果减少、点击增加)与回退信号(无关点击增加、返回搜索率上升)。
- 第 7 天:决策——保留、微调或回滚,并根据改善计划下一个批次。
使更改可回滚。把同义词与拼写规则像代码一样版本化、快照并保留清晰的回滚路径。如果某条新规则突然把 “face wash” 显示为 “dishwash liquid”,你应该能在几分钟内回退,而不是几天。
归属比聪明的规则更重要。指定一人开展每周 30 分钟的复盘:顶部新增零结果查询、最成功的拼写拯救案例以及低质量点击的任何激增。
如果想更快构建与迭代,Koder.ai 可以帮助你通过对话式构建实现搜索层,使用规划模式在上线前映射规则与指标,并保持可导出的源码,便于团队长期维护。它还支持快照与回滚,适合需要快速撤销变更的场景。
根据可量化结果规划下一步。例如,如果 “zeera rice” 开始转化但 “jeera” 现在匹配到无关的 “zera” 商品,你就有明确的下个动作:收紧该规则,而不是全面重写系统。