2025年12月25日·1 分钟
印度的发货集成:CSV 上传 vs 快递 API
印度的运输集成:通过比较 CSV 上传与快递 API,决定哪些流程自动化、哪些保留人工;并附实用的跟踪事件清单。
这篇文章真正关心的:减少发货跟进
当订单量小的时候,发货更新可以靠快速核对、电子表格和几条与快递的消息来处理。随着订单增长,微小的缺口会累积:面单晚创建、取件错过、跟踪停滞。
模式很熟悉:客户问“我的订单在哪里?”,客服问运营,运营去查某个门户。有人手动更新了本该自动更新的状态。
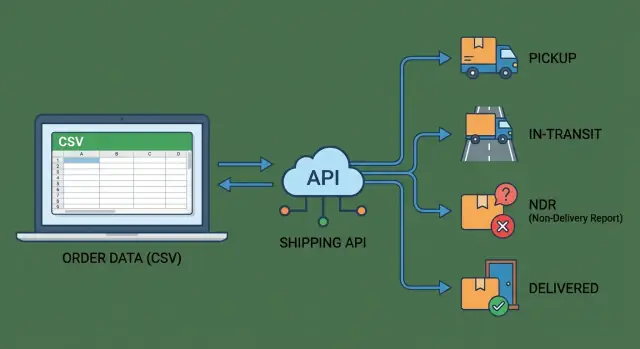
集成的意思很简单:你的系统可以可靠地把发货数据发出去(地址、重量、COD、发票金额),并把发货数据拉回来(AWB 号、取件确认、跟踪扫描、投递结果)。“可靠”很重要,因为它应该每天都可用,而不是只有有人记得上传文件时才有效。
这就是为什么要做比较的原因:
- CSV 上传工作流是基线。启动简单,但依赖人为按时重复相同步骤。
- 完整的快递 API 集成是不间断的版本。它可以创建运单、获取跟踪扫描并在不依赖人工的情况下响应异常。
大多数团队并不想“更多技术”。他们想要更少的延误、更少的人工修改和一套大家都能信任的跟踪。减少客户与内部团队的跟进,通常也会减少退款、重试成本和客服工单。
真实运营中发货工作出错的地方
多数团队从一个简单的例行流程开始:预约取件、打印面单、把跟踪 ID 贴到表格里,客户询问时再回复。低量时能行得通,但在印度尤其当你同时管理多家快递、COD 和不一致的地址质量时,裂缝很快显现。
单个手动步骤看起来并不大。有人选快递、创建运单、下载面单,并保证正确的包裹贴上正确的航空运单(AWB)。然后别人更新订单状态、分享跟踪并检查 COD 的投递凭证。
最常见的失败点包括:
- 错误的 AWB 粘到错误的包裹上,导致包裹丢失或被退回。
- 由于重复尝试或表格复制错误,创建了重复运单。
- 跟踪没有及时更新,客服无法给出明确答复,客户信任下降。
- 取件未被确认,订单显示“待发货”而快递方认为没有安排。
- COD 金额或费用不匹配,后续对账出现问题。
NDR 是 Non-Delivery Report(未投递报告)。当投递失败(地址错误、客户不在、拒收、付款问题)时会出现 NDR。NDR 会带来额外工作,因为它迫使你做决定:打电话给客户、更新地址、批准重试或标记退回。
运营首先感到压力。客服收到抱怨。财务卡在 COD 对账上。客户在状态不变时感到沉默。
选项 A:CSV 上传基线(你能得到什么、得不到什么)
CSV 上传是印度许多发货设置的默认起点。你从店铺或 ERP 导出一批已付款订单,按快递或聚合平台模板格式化,然后在后台上传文件以生成 AWB 和面单。
你得到的是简单性。通常不需要工程工作,一天内即可上线。对于低量或可预测的发货(同一取件地址、少量 SKU、少量异常),每日 CSV 可能“足够好”且易于培训。
它崩溃的地方在于上传之后的一切。大多数团队每天都要做相同的清理工作:修复失败行(因为邮编或手机号格式不匹配模板)、重新上传已修正的文件、检查意外重复、以及把跟踪号复制粘贴回店铺后台。
接下来是混乱部分:在邮件、电话和快递门户间追逐异常(地址问题、付款问题、RTO 风险),并在多个地方更新状态,因为快递后台不是你的事实系统。
隐藏成本是时间和不一致性。不同快递期望不同的列和规则,所以“一份 CSV”会演变为多个版本和表格技巧。而且因为更新不是实时的,客服往往只有在客户投诉时才知道延误。
选项 B:完整快递 API 集成(它解锁了什么,代价是什么)
完整的快递 API 设置意味着你的系统与快递的系统直接对话。你不再上传文件,而是自动发送订单和地址详情、接收面单,并持续拉取跟踪更新,而不需要有人去查看多个门户。通常这就是发货不再是每日运营琐事,而成为可靠基础设施的时候。
它解锁了什么
多数团队为三类核心动作开始做快递 API 集成:预订、面单和跟踪。典型能力包括:创建运单并即时获得 AWB、生成面单和发票数据、请求取件(若支持)、并近实时拉取跟踪扫描。
有了这些基础,你还能更干净地处理异常,比如地址问题和 NDR 状态更新。
回报很直接:更快的发货、减少复制粘贴错误、更清晰的客户更新。如果订单在下午 2 点付款,你的系统可以在几分钟内自动预订、打印面单并发送跟踪号,而不必等 CSV 导出再上传。
代价是什么
API 集成不是“设置完就忘”。你要为搭建、测试和持续维护安排时间。
常见的工作来源包括:
- 快递特定规则(邮编可达性、重量档、COD 限额)
- 状态代码不匹配(一个快递的“已发起 RTO”在另一个那里是“退回途中”)
- Webhook 的可靠性与漏掉事件的重试逻辑
- 面单格式与文档要求随时间变化
- 沙箱环境与生产环境不完全一致
如果你在早期就为这些怪癖做计划,设置会干净地扩展。否则,你可能会出现运单已预订但未取件,或客户看到令人困惑的状态因为跟踪事件映射不正确的情况。
什么应该自动化,什么保留人工(实用拆分)
构建一个简单的运维面板
制作一个运维面板,按订单 ID 或 AWB 搜索并查看完整事件历史。
一个简单规则效果很好:自动化那些每天发生很多次且因小错会造成大量返工的任务。
在印度,这通常意味着预订、面单和跟踪更新。一个错别字或一次漏扫就能触发一连串的跟进。
人工步骤仍有用武之地。当订单量低、异常频繁或快递流程不够稳定以至于不能信任自动化时,就保留人工。
按工作流的实用拆分:
- 优先自动化:从订单系统发起的运单预订、面单生成与打印、跟踪状态拉取或 webhook、带内部队列的 NDR 警报,以及供客服使用的投递确认消息。
- 保留人工(直到你有足够量):边缘案例的快递选择、电话协商取件变更、批准有风险的 COD 重试、需要判断的一次性地址修正。
构建前的一个快速决策表:
| 因素 | 何时人工可以 | 何时自动化更划算 |
|---|---|---|
| 日订单量 | 约 20 单/天以下 | 50+ 单/天或经常性峰值 |
| 快递数量 | 1 家快递 | 2 家以上或频繁切换 |
| SLA 压力 | 接受 3-5 天派送 | 保证当日/次日、罚金高 |
| 团队规模 | 有专职运维 | 运维/客服复用角色 |
一个简单检查点:如果团队会两次触碰同一数据(从订单复制到快递门户,再复制回表格),那么那一步就是强烈的自动化候选项。
跟踪事件清单:取件、运输中、NDR、已送达
如果你想减少“我的订单在哪里?”的询问,把跟踪当成事件时间线,而不是单一状态。这在印度很重要,因为同一快递可能在枢纽间、重试和退回之间反复移动。
捕捉下列阶段,让团队和客户看到相同的故事:
- 取件:取件是否已排程、是否尝试、最终结果(已取件或失败)。失败时存储快递方的失败原因,便于在不打电话给骑手的情况下采取行动。
- 运输中:首次扫描(通常是真正的开始)、主要枢纽扫描、异常或延迟标记,以及“外送中”。这些点触发大多数客服问题。
- NDR(未投递报告):当 NDR 被触发时,记录原因码、是否联系了客户、以及下一步(计划重试或开始退回)。这里通常有时间压力。
- 已送达(或未送达):记录送达时间和可用的投递凭证细节(姓名、签名、照片引用)。同时把“投递失败”和“已退回”分开,因为客户会把它们视为截然不同的结果。
对每个事件,存同样核心字段:时间戳、地点(城市与枢纽,如可用)、原始状态文本、标准化状态、原因代码和快递参考/AWB。同时保留原始与标准化值有助于审计和与快递争议时使用。
在集成前你需要的数据(以免日后出错)
有把握地变更流程
测试新快递或状态映射,并在出现问题时回滚。
许多发货集成因无聊的原因失败:缺少手机号、不一致的重量,或没有明确哪个系统是“真相来源”。在触碰 API 前,锁定每个订单你必须始终具备的最小数据集。
从也适用于 CSV 的基线开始。如果你不能可靠地导出这些字段,API 只会更快地放大错误:
- 订单 ID(唯一且永不重用)
- 完整收货地址(姓名、邮编、城市、省/州、地标)
- 手机号(已校验格式)和电子邮件(可选)
- 商品与发货信息(SKU、数量、毛重;有尺寸则一并)
- 支付详情(COD 金额、是否预付)
然后定义你期望从快递方得到的数据,因为这些将成为后续所有操作的“句柄”。至少存储运单 ID、AWB 号、快递名或代码、面单引用、取件日期或时段。
一个决定可以防止数周的混乱:选择你单一的货运状态真相来源。如果团队不断检查快递门户并覆盖你系统的记录,客户会看到一套内容而客服说另一套。
一个保持一致的映射计划:
- 选择你将使用的内部状态(例如:已创建、已取件、运输中、外送中、已送达、NDR)。
- 把每个快递状态映射到一个内部状态(即便它感觉丢失了细节)。
- 单独保存快递的原始状态文本以便审计。
- 决定哪些事件可以自动改变状态,哪些只能由人工改变。
如果你在像 Koder.ai 这样的工具内构建这些,把这些字段和映射尽早做成一等模型,这样在添加第二家快递时,导出、跟踪与回滚就不会出问题。
逐步迁移:从 CSV 到 API 的无缝过渡
最安全的升级路径是逐步切换,而不是一次性剪断。集成期间运维应继续完成发货工作。
1)在写代码前锁定范围
选定你实际会使用的快递,然后确认现在需要哪些动作、哪些可以以后再做:运单预订、跟踪、NDR 处理与退货(RTO)。这很重要,因为每家快递对状态命名不同并暴露不同字段。
2)先集成跟踪(只读)
在自动化预订或面单创建前,把跟踪事件拉入你的系统并在订单旁展示。这风险低,因为它不改变包裹的创建方式。
确保可以按 AWB 拉取事件,并处理 AWB 缺失或错误的情况。
3)映射状态,但保存原始真相
创建一个小型的内部状态模型(取件、运输中、NDR、已送达),然后把快递状态映射进来。同时按原样保存每一条原始事件负载。
当客户说“显示已签收但我没收到”时,原始事件能让客服快速回应。
4)谨慎地加入 NDR 自动化
先自动化简单部分:检测 NDR、分配到队列、通知客户并为重试窗口设置计时器。
为地址变更和特殊情况保留人工覆盖。
5)然后才添加预订、面单和取件排期
当跟踪稳定后,添加 API 预订、面单生成和取件请求。按快递逐步上线,同时保留 CSV 上传路径作为几周的回退。
用真实场景测试:
- NDR 后地址变更
- 请求了重试但未执行
- 触发了 RTO 后又被取消
- 部分或拆分发货
- 有已签收扫描但没有 OTP 或 POD 详情
常见错误会导致延误与客服工单
控制你的 NDR 处理
把 NDR 变成有负责人队列,包含原因代码、动作和下一次尝试时间。
大多数发货工单不仅仅是“我的订单在哪里?”而是期望不一致:你系统显示一套、快递显示另一套、客户看到第三套。
一个常见陷阱是以为状态文本是统一的。相同的里程碑在不同区域、服务类型或枢纽会有不同表述。如果你按精确文本映射而不是把它们标准化到你的小集合,仪表盘和客户消息就会偏离。
会造成延误与额外跟进的错误包括:
- 只保存最新状态:覆盖事件会丢失解释经过的时间线。保留完整历史、时间戳和地点。
- 把 NDR 当作一个状态:NDR 是一个过程。你需要原因、采取的动作和下一次尝试日期。
- 不处理迟到或乱序事件:快递可能批量发送事件或顺序怪异。没有对账与安全更新,你的系统可能来回翻转状态。
- 缺少重试逻辑与速率限制处理:API 调用会失败。若不安全重试就会丢失更新,若重试过猛又会被限速。
- 没有运维回退计划:当 API 不可用时如何处理?能否切换为一天的 CSV,暂停通知,或把订单标记为人工复查?
一个简单示例:客户来电说包裹“已退回”,而你系统只显示“NDR”。若你保存了 NDR 原因和重试历史,客服可以一条消息内回答,而不用升级到运营。
在宣布集成“完成”前的快速检查
在宣告成功前,用运维和客服在繁忙日会如何使用的方式测试集成。快递状态更新晚到或缺失关键细节,会产生与根本没有更新同样的问题。
对至少 10 个覆盖不同邮编和支付类型(预付与 COD)的真实订单做一次“单个运单端到端”演练。选一个订单并计时:
- 它现在在哪?
- 之前发生了什么?
- 接下来我们做什么?
一个能捕捉大多数空缺的检查清单:
- 能快速看到取件凭证:取件在预期窗口内被确认,并能区分“面单已创建”与“实际被取件”。
- NDR 是可操作的,而不仅仅是一个状态:你存储了 NDR 原因码以及下一步(重试/呼叫/RTO),并能改变该决定。
- 时间线易于查找:坐席能在 30 秒内拉出一个 AWB 的完整事件历史,包括时间戳与地点扫描。
- 已送达与款项/退回一致:已送达的运单能与 COD 汇款报告和退货/RTO 数据对上,避免周末财务追赶不匹配。
- 有安全的人工覆盖:可以更正地址、重新安排投递或在必要时改派给另一家快递,且每次人工变更都有日志。
如果你在构建内部界面,首版保持朴素有效:一个运单搜索框、一个清晰的时间线和两个按钮(人工备注与覆盖)。
像 Koder.ai 这样的工具可以快速帮你原型化这样的运维面板,并在你准备好时导出源码。如果你想以后探索,可以在 koder.ai 上找到它。
常见问题
When is a CSV upload workflow actually “good enough”?
CSV 上传在订单量低时是可以的(例如每天约 20 单以下),且只用一个快递、异常情况很少时很合适。它也可以作为 API 出现问题时的回退方案。风险在于任何一个遗漏步骤(晚上传、模板错误、复制粘贴错误)都会变成客服跟进和发货延迟。
What’s the clearest sign we should move from CSV to a courier API?
当你每天处理 50 单以上、使用 2 家以上快递,或频繁出现 NDR/重试时,快递 API 往往开始产生价值。它带来更快的预订与面单、近实时的跟踪,以及更少的人工更新。主要成本是为各快递差异做映射和持续维护。
What minimum order data should we standardize before integrating any courier?
先确保你能稳定导出:
- 唯一订单 ID(不重复使用)
- 完整收货地址(姓名、邮编、城市、省/州、地标)
- 已校验格式的手机号(电子邮件可选)
- 商品/发货信息(SKU、数量、毛重;有尺寸则一并)
- 支付信息(是否货到付款,COD 金额)
如果这些字段在导出时不一致,API 会更快地暴露问题,导致更多失败。
What shipping data should we always store back from the courier?
至少存储:
- 快递名/代码
- 快递方的运单 ID(若提供)
- AWB 编号
- 面单引用/元数据
- 取件日期或时段(若你请求取件)
这些字段是后续拉取跟踪、对账和客服查询的“锚”。
Which tracking events matter most to reduce “Where is my order?” tickets?
把跟踪当成时间线,而不是单一状态:
- 取件:已排程/尝试/确认(以及失败原因)
- 运输中扫描:首次扫描、枢纽扫描、例外标记、外送中
- NDR 发生:原因代码、采取的动作、下一次尝试或退回决策
- 已送达:送达时间与可用的凭证信息(姓名、签名、照片引用)
每个事件都记录时间戳、地点、原始状态文本、标准化状态、原因代码和 AWB。
How should we handle NDRs without creating more chaos?
把 NDR 当成工作流来处理:
- 捕捉 NDR 的原因代码和发生时间
- 将运单放入内部队列并指定负责人
- 记录决策(呼叫客户、地址修改、重试或退回)
- 跟踪下一次尝试的时间与结果
为地址修改和高风险 COD 重试保留人工覆盖,避免自动化带来重复错误。
How do we avoid confusing status mismatches across multiple couriers?
定义一组小而明确的内部状态(例如:已创建、已取件、运输中、外送中、已送达、NDR、已退回)。把每个快递事件映射到这些内部状态,同时保存快递返回的原始状态文本。不要仅靠精确文本映射——不同区域、服务类型与枢纽的用词会不同。
What’s the safest way to migrate from CSV to an API integration?
分阶段进行迁移:
- 先把跟踪事件拉入系统(只读)
- 将状态标准化并保存原始负载以便审计
- 添加 NDR 检测 + 队列 + 通知(并保留人工覆盖)
- 再自动化预订、面单和取件请求
并在几周内保留 CSV 作为回退,不要在一次切换中阻塞发货。
What reliability features should we build so tracking doesn’t go stale?
默认考虑失败情况:
- 对临时错误使用带退避的重试
- 识别并处理速率限制(放慢节奏,避免轰炸)
- 处理迟到或乱序事件并做安全的合并
- 记录每次请求/响应并保持幂等性以避免重复运单
- 定义运营回退(手动预订任务或临时 CSV 运行)
这些能防止静默的跟踪缺失,从而减少客服工单。
How do we prevent wrong AWBs, duplicates, and other costly ops mistakes?
通过流程与数据保护措施避免错误:
- 为每个订单/包裹生成并强制唯一的运单键
- 让预订具备幂等性,重试不会创建第二个运单
- 打印/扫描流程:在发货前核对 AWB 与包裹是否匹配
- 阻止重复使用 AWB,并自动标记重复项
大多数“丢失”运单始于 ID 混淆,而非单纯的快递问题。