2025年7月27日·1 分钟
语言、数据库与框架如何作为一个整体协同工作
了解语言、数据库和框架如何作为一个整体协同工作。比较权衡点、集成要点,并获得选择一致性技术栈的实用方法。
了解语言、数据库和框架如何作为一个整体协同工作。比较权衡点、集成要点,并获得选择一致性技术栈的实用方法。
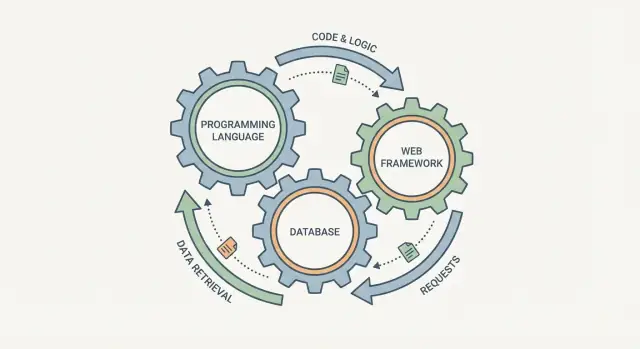
把编程语言、数据库和 Web 框架当成三个独立的复选项很诱人。但在实际中,它们更像相互啮合的齿轮:改变其中一个,其他的也会感受到影响。
一个 Web 框架决定请求如何被处理、数据如何被验证以及错误如何被呈现。数据库决定什么是“容易存储”的、如何查询信息以及在多用户并发时你能获得哪些保证。语言处在中间:它决定你如何安全地表达规则、如何管理并发以及可以依赖哪些库和工具链。
把技术栈视为一个系统意味着你不会孤立地去优化每一部分。你选择的组合应该:
本文尽量保持实用和非过度技术化。你不需要记住数据库理论或语言内部实现——只需观察选择如何在整个应用中产生连锁反应。
举个简单例子:为高度结构化且需要大量报表的业务数据选用无模式数据库,往往会导致规则散落在应用代码中,并在后期产生令人困惑的分析。更合适的做法是把这类领域与关系型数据库配对,并选用鼓励一致性验证和迁移的框架,这样随着产品演进数据才能保持连贯。
当你把技术栈一并规划时,你是在设计一组权衡,而不是做三张独立的赌注。
把“栈”看成一条单一的流水线是很有帮助的:用户请求进入系统,响应(以及持久化的数据)出来。编程语言、Web 框架和数据库不是独立的选择——它们是同一路程的三部分。
想象客户更新他们的配送地址。
/account/address)。验证检查输入是否完整且合理。当这三者对齐时,请求流动顺畅。当它们不对齐时,你会遇到摩擦:尴尬的数据访问、泄露的验证和微妙的一致性 bug。
多数关于“栈”的讨论从语言或数据库品牌开始。更好的起点是你的数据模型——因为它会悄然决定哪里会变得自然(或痛苦):验证、查询、API、迁移,甚至团队工作流。
应用通常同时处理四种形态:
理想的契合是你不会整天在这些形态之间翻译。如果核心数据高度关联(用户 ↔ 订单 ↔ 商品),行和连接可以让逻辑保持简单。如果数据大多是“每个实体一个 blob”并且字段可变,文档可以减少样板工作——直到你需要跨实体报表时问题出现。
当数据库有强模式时,许多规则可以靠近数据层:类型、约束、外键、唯一性。这通常能减少跨服务重复检查。
在灵活结构下,规则会向上移动到应用:验证代码、版本化的载荷、回填和谨慎的读取逻辑(“如果字段存在,则…”)。当产品需求每周都在变时这可能很有效,但它会增加框架与测试的负担。
你的模型决定代码主要是:
这反过来影响语言和框架的需求:强类型可以防止 JSON 字段的细微偏移,而成熟的迁移工具在频繁演化的模式下更重要。
先选模型;合适的框架和数据库选择通常随后就清晰了。
事务是应用默默依赖的“要么全做,要么全不做”的保证。当一次结账成功时,你希望订单记录、支付状态和库存更新要么都成功,要么都不发生。没有这种保证,你会遇到最难处理的错误:罕见、昂贵且难以重现。
事务把多个数据库操作组合为一个工作单元。如果中途发生失败(验证错误、超时、进程崩溃),数据库可以回滚到先前的安全状态。
这不仅关乎金钱流:账户创建(用户行 + 配置行)、发布内容(帖子 + 标签 + 搜索索引指针)或任何触及多个表的工作流都依赖事务。
一致性意味着“读取反映现实”。速度意味着“快速返回结果”。许多系统在这里做权衡:
常见的失败模式是选用了最终一致性的系统,却按强一致性去编码。
框架与 ORM 并不会因为你调用了多个“save”方法就自动创建事务。有些要求显式的事务块;有些在每次请求开始一个事务,这可能掩盖性能问题。
重试也很棘手:ORM 可能会在死锁或短暂故障时重试,但你的代码必须可安全重复运行。
部分写入发生在你先更新 A,然后失败而未更新 B。重复动作在请求超时后重试时发生——尤其是你在事务提交前就已对卡片收费或发送了邮件。
一个简单规则有帮助:把副作用(邮件、Webhook)放在数据库提交之后执行,并通过唯一约束或幂等键使操作可重复(安全重试)。
这是应用代码与数据库之间的“翻译层”。这里的选择往往比数据库品牌本身在日常更重要。
ORM(对象关系映射)让你把表当作对象来处理:创建一个 User、更新一个 Post,ORM 在后台生成 SQL。它能提高生产力,标准化常见任务并隐藏重复的样板代码。
查询构建器更显式:你用链式或函数式的方法构建类 SQL 的查询。你仍然按“连接、过滤、分组”思考,但获得参数安全和可组合性。
原生 SQL 是你自己写实际的 SQL。对于复杂报表查询通常最直接也最清晰——代价是更多手动工作与约定。
强类型语言(TypeScript、Kotlin、Rust)倾向于推动使用能在早期验证查询和结果形状的工具。这能减少运行时的意外,但也会促使团队集中化数据访问以防类型漂移。
具有灵活元编程的语言(Ruby、Python)通常使 ORM 看起来自然且便于快速迭代——直到隐藏的查询或隐式行为变得难以理解为止。
迁移是针对模式的版本化变更脚本:添加列、创建索引、回填数据。目标很简单:任何人部署应用时都能得到相同的数据库结构。把迁移当作代码来审查、测试并在必要时回滚。
ORM 可能会悄悄生成 N+1 查询、获取你不需要的巨大行或使连接变得尴尬。查询构建器可能演变成难以阅读的“链”。原生 SQL 可能被重复且不一致地散布。
一个好的规则:使用能让意图明显的最简单工具——对关键路径,检查实际执行的 SQL。
人们常把页面变慢归咎于“数据库”。但大多数用户可见的延迟是整个请求路径上多个小等待的总和。
单次请求通常要为以下几项付出时间:
即便数据库能在 5ms 回答,一个发出 20 条查询且在 I/O 上阻塞且花 30ms 序列化巨大响应的应用仍然会感觉很慢。
建立新数据库连接代价昂贵,会在负载下压垮数据库。连接池 重用现有连接,使请求不必重复付出建立连接的开销。
问题在于:合适的池大小取决于你的运行时模型。高并发的异步服务器可能产生巨大的同时需求;没有池限制你会看到排队、超时与嘈杂失败。池限制过严时,你的应用又成为瓶颈。
缓存可以在浏览器、CDN、进程内缓存或共享缓存(如 Redis)中出现。当许多请求需要相同结果时,缓存很有用。
但缓存无法拯救:
你的语言运行时决定吞吐量。每请求一个线程的模型在等待 I/O 时会浪费资源;异步模型能增加并发,但也使得背压(如连接池限制)变得至关重要。这就是为什么性能调优是一个栈决策,而非单纯的数据库决策。
安全不是用某个框架插件或数据库设置“添加”上的东西。它是语言/运行时、Web 框架和数据库之间的约定,关于在开发者犯错或增加新端点时哪些必须永远成立。
认证(这是谁?)通常在框架边缘处理:会话、JWT、OAuth 回调、中间件。授权(他们被允许做什么?)必须在应用逻辑和数据规则中一致地强制执行。
一种常见模式是:应用决定意图(“用户可以编辑这个项目”),数据库强制边界(租户 ID、所有权约束、以及在合适时的行级策略)。如果授权只存在于控制器中,后台作业和内部脚本可能会意外绕过它。
框架验证提供快速反馈和友好的错误信息。数据库约束提供最终的安全网。
在重要场景中两者都用:
CHECK、NOT NULL这样可以减少当两个请求竞争或新的服务以不同方式写入数据时出现的“不可能状态”。
密钥应该由运行时和部署工作流(环境变量、密钥管理器)管理,不应硬编码在代码或迁移中。加密可以在应用层(字段级加密)或数据库层(静态数据加密、托管 KMS)进行,但你需要明确谁轮换密钥以及如何恢复。
审计也是共享的:应用应发出有意义的事件;数据库应在合适时保留不可变日志(例如追加式审计表、受限访问)。
过度信任应用逻辑是经典问题:缺少约束、沉默的空值、“admin” 标志未受检查地存储。修复很简单:假设 bug 会发生,并设计栈使得数据库可以拒绝不安全的写入——即便它来自你自己的代码。
把它们当作每个请求的一条单一管道来对待:框架 → 代码(语言)→ 数据库 → 响应。如果某个环节鼓励的模式与其他环节冲突(例如无模式存储 + 重型报表),你会花大量时间在粘合代码、重复规则和难以调试的一致性问题上。
从你的核心数据模型和最常做的操作开始:
一旦数据模型明确,自然需要的数据库和框架特性通常会变得显而易见。
当数据库强类型时,很多规则可以靠近数据层:
NOT NULL、唯一性CHECK 约束在结构更灵活的情况下,更多规则会移到应用代码里(验证、版本化载荷、回填)。这能加速早期迭代,但会增加测试负担并提高跨服务漂移的风险。
当多次写入必须要么全部成功、要么全部失败时(例如:订单 + 支付状态 + 库存变更)就要使用事务。不使用事务会导致:
此外,把副作用(邮件、Webhook)放在提交之后执行,并使用幂等性设计(例如唯一约束或幂等键),以便安全重试。
选择能让意图清晰的最简单方案:
对关键路径,务必检查实际执行的 SQL。
把模式和代码保持同步,把迁移当作生产代码来对待:
如果迁移是手动或不可靠的,环境会发生漂移,部署变得危险。
把整个请求路径都分析清楚,而不是只看数据库:
即便数据库能在 5ms 内返回,如果应用发出 20 条查询或在 I/O 上阻塞,页面依然会感觉很慢。
使用连接池可以避免每次请求都建立连接的开销,并在负载下保护数据库。
实用指引:
错误配置的连接池通常会在流量突增时表现为超时和嘈杂失败。
使用双层验证:
NOT NULL、CHECK)这可以防止在请求竞态、后台作业写入或新端点忘记检查时出现“不可能的状态”。
给自己 2–5 天时间,做一个小型概念验证,覆盖真实的接缝:
然后写一页决策记录,让未来的改动更有意图(参见 /docs 与 /blog 的相关指南)。