2025年9月08日·2 分钟
为什么原生框架在高性能应用中仍然重要
原生框架在低延迟、平滑 UI、电池效率和深度硬件访问上仍有优势。了解何时应选择原生而非跨平台或混合方案。
原生框架在低延迟、平滑 UI、电池效率和深度硬件访问上仍有优势。了解何时应选择原生而非跨平台或混合方案。
“性能关键”并不是“希望快一点”。它意味着当应用哪怕稍有迟缓、不稳定或延迟,体验就会崩溃。用户不仅会注意到滞后——他们会失去信任、错过瞬间或犯错。
有几类常见应用能清楚地说明问题:
在这些场景中,性能不是隐藏的技术指标,而是在几秒钟内就能被看到和感受到的品质信号。
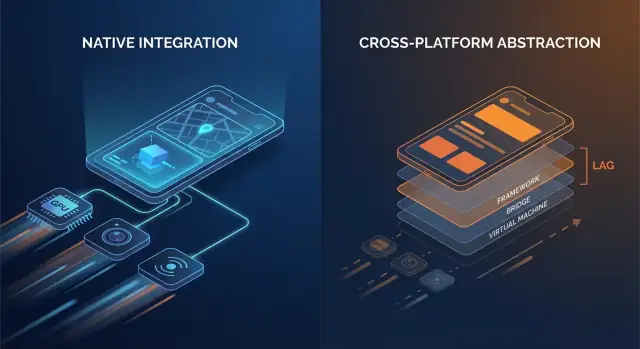
当我们说 原生框架,指的是在每个平台上的一等工具:
原生并不自动等于“工程更好”。它意味着你的应用直接使用平台语言——当你对设备进行高强度压榨时,这一点尤为重要。
跨平台框架对许多产品来说是很好的选择,尤其是当开发速度和共享代码比争取每毫秒更重要时。
本文并不是说“原生总是更好”。而是说明,当应用真正是性能关键时,原生框架常常能消除整类开销与限制。
我们将从几个实用维度评估性能关键需求:
这些是用户能感受到差别的领域,也是原生框架往往占优的地方。
当你构建典型页面、表单和基于网络的流程时,跨平台框架可能看起来“足够接近原生”。差异通常在应用对小延迟敏感、需要稳定帧节奏、或必须长时间高负载运行时显现。
原生代码通常直接调用 OS API。许多跨平台栈在应用逻辑与最终渲染之间增加一个或多个翻译层。
常见的开销点包括:
这些成本单独看并不巨大,但问题在于重复:它们可能出现在每次手势、每个动画滴答和每个列表项上。
开销不仅关乎原始速度,还关乎“工作发生的时间”。
原生应用也会遇到这些问题——但可动的部件更少,意味着隐藏惊喜的地方更少。
想象:层越少 = 惊喜越少。每增加一层,都会引入更多的调度复杂性、更多的内存压力和更多的翻译工作。即便每层都工程良好,它仍会增加出现问题的面。
对许多应用来说,这些开销是可接受的,生产力提升真实存在。但对于性能关键应用——快速滚动的 Feed、重动画、实时协作、音视频处理或任何对延迟敏感的场景——这些“小”成本很快就会在用户可见的路径上显现。
流畅的 UI 并非“锦上添花”——它是质量的直接信号。在 60 Hz 屏幕上,你大约有 16.7 ms 来生成每一帧;在 120 Hz 设备上,这个预算降到 8.3 ms。当你错过这个窗口,用户会看到卡顿(jank):滚动“卡住”、过渡卡顿或手势滞后。
人们不会有意识地数帧,但会注意到不一致。一次在慢速淡出中的丢帧可能可以接受;而在快速滚动中丢几帧则会立刻明显。高刷新率屏幕也提升了期望值——一旦用户体验到 120 Hz 的流畅,不稳定的渲染比在 60 Hz 时更令人反感。
大多数 UI 框架仍依赖主/UI 线程来协调输入处理、布局和绘制。当该线程在一帧内做太多工作时就会出现卡顿:
原生框架通常拥有经过优化的流水线和更清晰的最佳实践,帮助把工作移出主线程、最小化布局失效并使用 GPU 友好的动画。
关键差异在于渲染路径:
复杂列表是经典压力测试:快速滚动 + 图片加载 + 动态单元高度会产生布局抖动和 GC/内存压力。
过渡效果可以揭示管线低效:共享元素动画、模糊背景和多层阴影视觉丰富,但会显著提高 GPU 成本和过度绘制。
手势密集的屏幕(拖拽重排、滑动卡片、擦洗器)对延迟极其苛刻,因为 UI 必须持续响应。当帧迟到时,UI 就不再“贴合”用户的手指——而这正是高性能应用必须避免的感觉。
延迟是用户动作与应用响应之间的时间差。不是整体“快慢”,而是你在点击按钮、输入字符、拖动滑块、绘制笔触或演奏音符时感受到的间隙。
有用的经验阈值:
性能关键应用——消息、记笔记、交易、导航、创作工具——生死取决于这些延迟。
大多数框架在一个线程处理输入,在别处运行应用逻辑,然后再请求 UI 更新。当这条路径很长或不稳定时,延迟会飙升。
跨平台层可能增加额外步骤:
每次交接(一次“线程跳转”)都会增加开销,更重要的是增加抖动——响应时间变化,这往往比恒定延迟感觉更糟。
原生框架通常能提供更短、更可预测的触摸→UI 更新路径,因为它们与 OS 调度器、输入系统和渲染管线更为一致。
有些场景存在硬性上限:
原生优先实现更容易缩短“关键路径”——把输入与渲染的优先级放在后台工作之上,从而让实时交互保持紧凑可靠。
性能不仅关乎 CPU 或帧率。对于许多应用,关键时刻发生在边缘——你的代码接触相机、传感器、无线电和系统级服务的地方。这些能力通常先以原生 API 的形式提供,这影响了跨平台栈的可行性与稳定性。
像相机流水线、AR、BLE、NFC、运动传感器等功能常常需要与设备特定框架紧耦合。跨平台封装可以覆盖常见需求,但高级场景会暴露差距。
需要原生 API 的示例:
当 iOS 或 Android 推出新特性时,官方 API 立刻在原生 SDK 可用。跨平台层可能需要几周或更久去添加绑定、更新插件并处理边缘情况。
这种滞后不仅令人不便——还会带来可靠性风险。如果某个封装尚未适配新系统版本,你可能遇到:
对于性能关键的应用,原生框架能减少“等待封装更新”的问题,让团队能在第一时间采用系统新能力——这常常决定了功能是这个季度能发布还是要推迟。
演示中的速度只是半个故事。用户记住的性能是那种能在 20 分钟使用后依然保持的体验——手机发热、电量下降、应用曾后台切换过几次仍然顺滑。
大多数“神秘”的电量消耗都是自找的:
原生框架通常提供更清晰、可预测的工具来高效调度工作(后台任务、作业调度、系统管理的刷新),从而总体上做更少的工作并在更合适的时间做它们。
内存不仅影响崩溃,也影响流畅性。
许多跨平台栈依赖受管理的运行时并带有垃圾回收(GC)。当内存堆积时,GC 可能短暂停顿应用以回收不再使用的对象。你无需理解内部细节也会感受到:滚动、输入或过渡时的微冻结。
原生应用通常遵循平台惯用模式(例如 Apple 平台的 ARC 自动引用计数),这往往把清理工作更均匀地分摊,从而在紧张内存条件下减少“意外”暂停。
发热就是性能。随着设备升温,系统可能降频 CPU/GPU 以保护硬件,帧率会下降。这在游戏、导航、相机滤镜或实时音频等持续负载场景中很常见。
原生代码在这些场景中通常更节能,因为它能使用硬件加速、由系统调优的 API来处理重任务——比如原生视频播放管线、高效的传感器采样和平台媒体编解码器——减少无谓工作转化为热量。
当“快”也意味着“凉快且稳定”时,原生框架常常有优势。
性能工作成败取决于可见性。原生框架通常带有最深的系统、运行时和渲染管线钩子 —— 因为这些层由同一厂商定义和维护。
原生应用可以在引入延迟的边界处附加分析器:主线程、渲染线程、系统合成器、音频栈、网络与存储子系统。当你追踪一个每 30 秒才出现一次的卡顿或只在特定设备上出现的电量消耗时,底层的 trace 往往是唯一能给出确定答案的方法。
你不需要记住所有工具,但了解存在性有助于排查问题:
这些工具能回答具体问题:“哪个函数是热点?”,“哪个对象没被释放?”,“哪一帧错过了期限,为什么?”
最难的性能问题常隐藏在边缘情况:罕见的同步死锁、主线程上的慢 JSON 解析、触发昂贵布局的单个视图,或 20 分钟后才出现的内存泄漏。
原生分析能将症状(冻结或卡顿)与原因(具体调用栈、分配模式或 GPU 峰值)关联起来,而不是靠试错改善。
更好的可视性能缩短修复时间,因为它把争论变成证据。团队能捕获 trace、共享并快速就瓶颈达成共识——常把几天的“可能是网络问题”猜测缩短为一次有针对性的补丁和可测的前/后对比结果。
当你发布到数百万部手机时,崩溃的不仅是性能——还有一致性。同一款应用在不同 OS 版本、OEM 定制甚至 GPU 驱动上可能表现不同。在大规模下,可靠性就是在生态不稳定时保持可预测性的能力。
在 Android 生态中,OEM 皮肤会调整后台限制、通知、文件选择器和电源管理。同一 Android 版本的两台设备也可能不同,因为厂商会随设备附带不同的系统组件和补丁。
GPU 也引入变量。厂商驱动(Adreno、Mali、PowerVR)在着色器精度、纹理格式和优化激进度上会有差异。一个在某块 GPU 上表现正常的渲染路径在另一块上可能出现闪烁、条带或罕见崩溃——尤其在视频、相机和自定义图形周围。
iOS 更加封闭,但系统更新仍会改变行为:权限流程、键盘/自动填充怪异、音频会话规则和后台任务策略在小版本间可能细微变化。
原生平台会首先暴露“真实”API。当系统改变时,原生 SDK 与文档通常会立即反映这些改动,平台工具(Xcode/Android Studio、系统日志、崩溃符号)也与设备上运行的代码保持一致。
跨平台栈增加了翻译层:框架本身、运行时、渲染/运行时与插件。当出现边缘问题时,你需要同时调试应用与桥接层。
框架升级可能引入运行时改变(线程、渲染、文本输入、手势处理),而这些变化可能只在某些设备上失败。插件更麻烦:有些只是薄包装;另一些嵌入大量原生代码且维护不一。
在大规模下,可靠性很少是关于某一个 bug——而是减少隐藏惊喜的层数。
有些工作负载会放大即使是微小开销的代价。如果你的应用需要持续高 FPS、重 GPU 工作或对解码/缓冲有严格控制需求,原生框架通常胜出,因为它们能直接驱动平台最快的路径。
3D 场景、AR 体验、高帧率游戏、视频编辑和以相机为中心的实时滤镜就是典型例子。这些用例不仅“计算密集”——它们是流水线密集的:在 CPU、GPU、相机和编码器之间每秒钟往返移动大纹理与帧数十次。
额外的拷贝、迟到的帧或不同步会立即表现为掉帧、过热或操控迟滞。
在 iOS 上,原生代码可以直接调用 Metal 与系统媒体栈而无需中间层。在 Android 上,可以通过 NDK 访问 Vulkan/OpenGL 以及平台编解码器和硬件加速。
这很重要,因为 GPU 命令提交、着色器编译与纹理管理都对应用如何调度工作非常敏感。
典型的实时管线是:捕获或加载帧 → 转换格式 → 上传纹理 → 运行 GPU 着色器 → 进行 UI 合成 → 提交显示。
原生代码可以通过让数据更长时间保持 GPU 友好格式、批处理绘制调用及避免重复纹理上传来减少开销。即便每帧出现一次不必要的转换(例如 RGBA ↔ YUV)也可能增加足够的成本以破坏流畅播放。
设备端 ML 往往依赖 delegate/后端(神经引擎、GPU、DSP/NPU)。原生集成通常更早暴露这些能力并提供更多调优选项——当你关心推理延迟与电池同时时尤为重要。
你不必把整个应用都做成原生。很多团队对大部分界面保留跨平台实现,但为热点添加原生模块:相机流水线、自定义渲染器、音频引擎或 ML 推理。
这可以在关键处提供接近原生的性能,而无需重写所有内容。
选框架不是意识形态问题,而是把用户期望与设备需要做的工作匹配起来。如果你的应用感觉瞬时、在压力下保持凉爽且流畅,用户很少会关心它是用什么做的。
用这些问题快速缩小范围:
如果你在做多个方向的原型,先用快速方案验证产品流,然后再决定是否投入深度原生优化通常有益。例如,团队有时会用 Koder.ai 快速生成一个基于 Web 的可用版本来检验 UX 与数据模型,然后在性能关键屏幕明确后再做原生或混合移动实现。
混合并不等于“把网页塞进应用”。对性能关键产品来说,混合通常意味着:
这种方法可限制风险:你可以在不重写一切的情况下优化最热的路径。
在做出承诺前,先为最难的屏幕构建小原型(如实时 Feed、编辑器时间线、地图 + 覆盖层)。基准测试帧稳定性、输入延迟、内存和电量,持续 10–15 分钟。用数据而不是猜测来选择。
如果你在早期迭代中使用像 Koder.ai 的 AI 辅助构建工具,把它当作加速探索架构和 UX 的工具——而不是设备级性能分析的替代。目标是:当你面向性能关键体验时,在真实设备上测量、制定性能预算,并把渲染、输入、多媒体等关键路径尽量靠近原生。
先把应用做对并保证可观测性(基本性能分析、日志与性能预算)。只有当你能指向用户会感知的瓶颈时再优化。这样能避免团队在非关键路径上花费数周去争夺毫秒。
这意味着当应用稍有迟缓或不一致时,用户体验就会崩溃。小的延迟可能导致错过拍照时机(相机)、做出错误决策(交易)或丧失信任(导航),因为性能在核心交互中是直接可见的。
因为原生代码与平台的 API 和渲染管线直接对接,翻译层更少。通常带来:
常见开销来源包括:
这些代价单独看不大,但当它们在每帧或每次交互中重复出现时会累加可见的影响。
平滑度就是按时完成帧的稳定性。在 60 Hz 下每帧约 16.7 ms;在 120 Hz 下约 8.3 ms。错过期限时用户会看到滚动抖动、动画卡顿或手势延迟——这些往往比略慢的加载更显著。
UI/主线程通常负责协调输入、布局和绘制。当你在主线程上做太多事时,就会出现 jank,例如:
让主线程保持可预测性通常是提升流畅性的最大收益。
延迟是动作到响应之间的“感知差距”。常用经验阈值:
性能关键应用会优化从输入→逻辑→渲染的整条路径,既要低延迟也要低抖动。
许多硬件特性是原生优先并快速演进:高级相机控制、AR、BLE 后台行为、NFC、健康 API、后台执行策略等。跨平台封装可能覆盖常见用例,但在高级或边缘行为上通常需要直接调用原生 API 才能可靠并且及时。
因为 OS 发布总是首先在原生 SDK 中出现,而跨平台绑定/插件通常滞后。这种时间差可能导致:
对关键功能而言,原生可减少“等待封装修复”的风险。
持续性能关乎长期效率:
原生 API 往往提供更可预测的调度手段和系统加速路径,从而减少不必要的功耗。
可以。常见做法是采用混合策略:
这样只在最关键的地方投入原生工作,而不是全部重写。