2025年9月23日·1 分钟
ZSTD vs Brotli vs GZIP:为 API 选择压缩方式
比较 ZSTD、Brotli 和 GZIP 在 API 中的表现:压缩速度、压缩比、CPU 成本,以及在生产环境中针对 JSON 与二进制负载的实用默认值。
什么是 API 压缩(以及何时值得启用)
API 响应压缩指的是服务器在发送之前将响应体(通常是 JSON)编码成更小的字节流。客户端(浏览器、移动应用、SDK 或其他服务)随后解压它。在 HTTP 中,这通过诸如 Accept-Encoding(客户端可解码的编码)和 Content-Encoding(服务器选择的编码)之类的头进行协商。
它为 API 带来什么
压缩主要带来三点好处:
- 更少的带宽: 更小的响应端到端消耗更少的字节。
- 受限链路上的更低延迟: 更少的字节常常意味着在移动网络、拥堵的 Wi‑Fi 和跨区域调用上更快的下载。
- 更低的出站费用: 如果你为出站数据付费,减少传输大小可以直接降低费用。
权衡很直接:压缩节省带宽,但会消耗 CPU(压缩/解压),有时还需额外的 内存(缓冲)。是否值得取决于你的瓶颈所在。
什么时候压缩最有用
压缩在以下场景表现最佳:
- 以文本为主且重复性高,如 JSON、GraphQL 响应、HTML 或日志。
- 中等到大型 响应,当减少几十到几百 KB 很有意义时。
- 通过慢速或昂贵网络提供,例如移动端、跨国客户端或跨区域流量。
如果你返回大型 JSON 列表(目录、搜索结果、分析数据),压缩通常是最容易获得收益的方法之一。
什么时候效果最差
当响应是:
- 很小(例如几百字节),头部和 CPU 开销可能超过带宽节省。
- 已被压缩(JPEG/PNG、MP4、ZIP、许多 PDF),再次压缩通常收益甚微甚至变大。
- CPU 受限的服务(热点端点已经在算力上挣扎),增加压缩会提高尾延迟。
本指南的决策轴
在为 ZSTD vs Brotli vs GZIP 选择 API 压缩时,实用决策通常归结为:
- 压缩后大小(压缩率)
- 延迟(服务器到首字节时间加上客户端解码时间)
- 客户端支持度(你的调用方和中间件可靠地支持什么)
本文余下内容都围绕为你的 API 与流量模式平衡这三点展开。
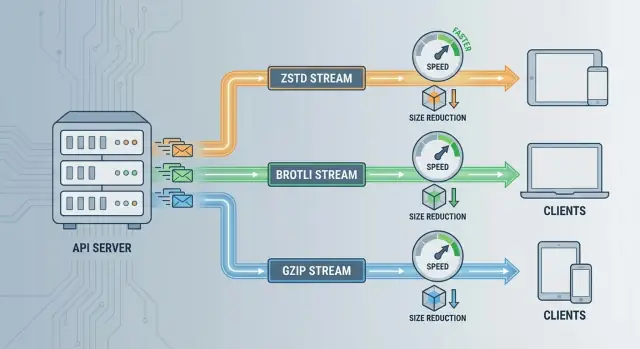
ZSTD vs Brotli vs GZIP:快速比较
三者都能减少负载,但它们针对不同约束进行优化——速度、压缩比和兼容性。
一眼看懂
- ZSTD(Zstandard): 当你关心低延迟和可预测的 CPU时,通常是 API 的最佳平衡。压缩比强而且不太慢。
- Brotli: 在字节最小化上常常获胜,尤其适用于文本密集的响应(JSON、类似 HTML 的内容)。较高的等级会消耗更多 CPU。
- GZIP: “无所不能”的选项。广泛支持,易于落地,但在类似 CPU 预算下通常比现代替代品慢或产生更大体积。
典型强项(以及这对 API 意味着什么)
ZSTD 的速度: 当你的 API 对尾延迟敏感或服务器受 CPU 约束时很合适。它能足够快地压缩,使得相较于网络时间的开销通常可以忽略,特别是针对中等到较大的 JSON 响应。
Brotli 的压缩比: 当带宽是主要约束(移动客户端、昂贵的出站、通过 CDN 交付)且响应以文本为主时表现最好。即便压缩耗时更长,也常常值得去换取更小的字节数。
GZIP 的兼容性: 当你需要最大程度的客户端支持且不能冒协商失败风险(老旧 SDK、嵌入式客户端、遗留代理)时最好使用它。它是一个安全的基线,尽管它不是性能最优。
“压缩级别”真正改变的是什么
压缩“级别”是一些预设,用来在CPU 时间和输出大小之间做权衡:
- 低级别: 压缩更快,输出更大。适合实时 API。
- 高级别: 输出更小,但压缩更慢(有时也更耗内存)。适合大型、可缓存的响应。
对于三种算法,解压通常比压缩便宜很多,但非常高的级别仍会增加客户端 CPU/电量消耗——这对移动端尤其重要。
简单经验法则
- 默认选择: 对大多数 JSON/REST/GraphQL API 使用 ZSTD,当延迟重要时。
- 切换到 Brotli: 当你以最少字节为目标(文本响应多、使用 CDN、网络慢)且能承受更多 CPU 时。
- 保留 GZIP: 当你需要广泛兼容性或基础设施/工具链不支持较新编码时。
压缩比 vs 延迟:核心权衡
压缩常被宣传为“更小的响应 = 更快的 API”。在慢速或昂贵网络上这通常成立——但并非必然。如果压缩增加了足够的服务器 CPU 时间,你可能会比未压缩时更慢——尽管线上的字节更少。
时间花在哪儿
把成本分为两类有助于理解:
- 压缩时间(服务器端): 在服务器开始发送字节之前完成的工作,会直接增加响应时间(TTFB)。
- 解压时间(客户端): 接收字节后所做的工作。通常比压缩便宜,但在低功耗设备或高吞吐客户端上仍然重要。
高压缩比可以减少传输时间,但如果压缩增加了(例如)每次响应 15–30 ms 的 CPU 时间,在快速连接上你可能得不偿失。
在负载下的尾延迟陷阱
在负载下,压缩可能比 p50 更伤害 p95/p99 延迟。当 CPU 使用率飙升时,请求会排队。排队会把微小的每次请求开销放大成巨大的延迟——平均延迟看起来还好,但最慢的用户会受到影响。
像对待性能特性一样测量
不要凭猜测。做 A/B 测试或分阶段发布,比较:
- p50 和 p95 延迟(最好还看 p99)
- API 实例的 CPU 利用与饱和度
- 响应大小与到首字节时间(TTFB)
用真实的流量模式和有效载荷测试。所谓“最佳”压缩级别是能减少总体时间的那个,而不仅仅是减少字节数。
服务器与客户端的 CPU/内存成本
压缩不是“免费”的——它把工作从网络转到服务器和客户端的 CPU/内存上。在 API 场景中,这表现为更长的请求处理时间、更大的内存占用,有时还会导致客户端变慢。
CPU 花费集中在哪儿
大部分 CPU 花费来自压缩响应。压缩需要发现模式、构建状态/字典并写出编码后的输出。
解压通常便宜得多,但仍值得注意:
- 服务器有时需要解压请求(在 JSON API 中较少见,上传或批量事件中更常见)。
- 客户端在解析 JSON 之前会解压响应。
如果你的 API 已经 CPU 密集(繁忙的应用服务器、复杂的认证、昂贵的查询),开启高压缩级别会在提升传输效率的同时,增加尾延迟。
内存考虑
压缩会以几种方式增加内存使用:
- 缓冲: 实现可能需要输入/输出缓冲;更大的响应意味着更大的缓冲区。
- 全量缓冲 vs 流式: 流式压缩可以更早开始发送并保持内存占用较低,而全量缓冲会增加每个请求的峰值内存。
在容器化环境中,更高的峰值内存可能导致 OOM 杀死或更严格的限制,进而降低实例密度。
对自动扩缩与容器限制的影响
压缩增加了每次响应的 CPU 周期,从而降低了每个实例的吞吐。这可能更早触发自动扩缩,提高成本。一个常见模式是:带宽下降,但 CPU 开销上升——所以哪种资源稀缺决定了最佳选择。
为什么客户端解压速度很重要
在移动或低功耗设备上,解压会与渲染、JavaScript 执行和电池消耗竞争。一个能节省几个 KB 但解压更慢的格式在“可用数据时间”上会感觉更慢,特别是当响应需要立即使用时。
ZSTD 在 API 场景的优点、限制与合理默认值
与团队协作构建
将团队带入同一工作区,共同构建、部署并审查性能变化。
Zstandard(ZSTD)是一种现代压缩格式,旨在在不显著减慢 API 的前提下提供较强压缩比。对于许多以 JSON 为主的 API,它是一个强有力的“默认”:相比 GZIP 在相近或更低延迟下能明显减小响应,而且客户端解压非常快。
ZSTD 最擅长什么
当你关心端到端时间而不仅仅是最小字节时,ZSTD 十分有价值。它通常压缩得快且解压极快——在每毫秒 CPU 时间都很关键的 API 场景下尤其适用。
它也在各种负载大小上表现良好:小到中等的 JSON 常能看到显著收益,而大型响应的收益通常更明显。
API 的合理压缩级别
对大多数 API,从低级别(通常 1–3)开始。这些级别通常能提供最佳的延迟/大小权衡。
仅在以下情况下使用更高的级别:
- 响应很大(数百 KB 到 MB 级别)
- 带宽昂贵或受限
- 已测得 CPU 不是瓶颈
务实的方法是设定较低的全局默认,然后对少数“大响应”端点选择性提高级别。
流式与字典模式
ZSTD 支持流式压缩,这能降低峰值内存并让大型响应更早开始发送。
字典模式对那些返回大量相似对象(重复键、稳定模式)的 API 有很大帮助。它在以下场景最有效:
- 响应比较小但频繁
- 你能安全地管理版本化字典
兼容性限制需注意
在很多栈中服务器端支持比较直接,但客户端兼容性可能是决定因素。一些 HTTP 客户端、代理和网关默认还不会声明或接受 Content-Encoding: zstd。
如果你面向第三方消费者,保留一个回退(通常是 GZIP),并仅在 Accept-Encoding 明确包含时启用 ZSTD。
常见问题
什么时候实际值得为 API 启用响应压缩?
当响应是文本密集(JSON/GraphQL/XML/HTML)、中等到较大,并且用户处在慢速/昂贵网络或你为出站流量付费时,启用响应压缩通常是有价值的。对微小响应、已压缩的媒体(JPEG/MP4/ZIP/PDF)以及CPU 已成为瓶颈的服务,应跳过压缩或设置较高的阈值,以免增加 p95/p99 延迟。
为什么压缩会在响应更小的情况下反而使 API 变慢?
因为压缩是在用CPU(有时还有内存)换取带宽。压缩时间会推迟服务器开始发送字节的时间(TTFB),而在负载下它会放大队列效应——经常导致尾延迟恶化,即使平均延迟有所改善。最优的设置是能减少端到端时间,而不仅仅是减少字节数。
我应该如何在 ZSTD、Brotli 和 GZIP 之间选择?
一个实用的默认优先级常见为:
zstd优先(快速、比率好)- 然后
br(文本时通常最小,但可能更耗 CPU) - 然后
gzip(兼容性最广)
最终选择应基于客户端在 中声明的能力,并保留安全回退(通常是 或 )。
动态 API 响应应使用哪些压缩级别作为合理默认?
从低级别开始并进行测量:
- ZSTD: 通常使用 1–3(或最多 3–5)适用于大多数动态 JSON API
- Brotli: 运行时压缩用 1–4;预压缩/静态内容可用 8–11
- 推荐 作为较好默认
我应该压缩每个响应,还是只在响应大于某个大小时才压缩?
使用最小响应大小阈值以避免在微小负载上浪费 CPU:
- 典型起点:1–2 KB
- 如果你受 CPU 限制或响应非常对话式:考虑 4 KB
按端点调优:比较节省的字节数、增加的服务器时间以及对 p50/p95/p99 的影响。
哪些负载类型压缩效果好(哪些通常效果不好)?
优先对结构化且重复性高的内容进行压缩:
Accept-Encoding 和 Content-Encoding 在 API 中如何工作?
压缩通过 HTTP 协商工作:
- 客户端发送
Accept-Encoding(例如zstd, br, gzip) - 服务器用支持的
Content-Encoding响应
如果客户端未发送 Accept-Encoding,最安全的做法通常是不进行压缩。切勿返回客户端未声明可解码的 Content-Encoding,否则可能导致客户端无法解析响应体。
使用压缩时为什么需要 `Vary: Accept-Encoding`?
添加:
Vary: Accept-Encoding
这样可以防止 CDN/代理缓存(例如)gzip 版本并错误地将其提供给未请求或无法解码 gzip(或 zstd/br)的客户端。如果你支持多种编码,该头对于缓存正确性至关重要。
生产环境中最常见的压缩问题有哪些?
常见的故障模式包括:
- 双重压缩(上游已压缩,网关/CDN 再次压缩)
我应如何安全地发布、监控和排查 API 压缩?
像对待性能特性一样发布压缩:
- 先做金丝雀或小流量测试(例如 1%),再逐步放量(1% → 5% → 25% → 50% → 100%)
- 保持快速回滚路径(特性开关或网关配置),并能针对特定端点排除压缩
- 监控: