21 ago 2025·8 min
6 JOINs de SQL que debes conocer (con ejemplos simples y claros)
Aprende los 6 tipos de JOIN en SQL que todo analista debería conocer: INNER, LEFT, RIGHT, FULL OUTER, CROSS y SELF —con ejemplos prácticos y errores comunes.
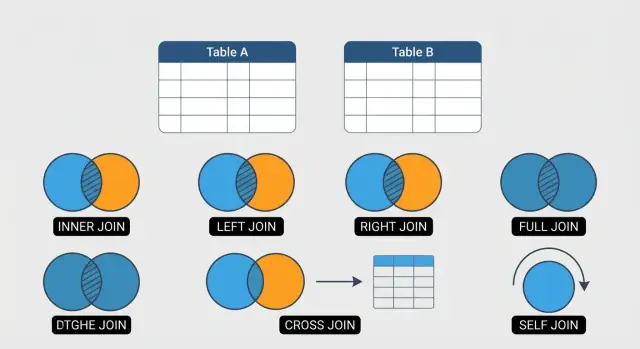
Qué son los JOINs en SQL y por qué los usas
Una JOIN en SQL te permite combinar filas de dos (o más) tablas en un solo resultado emparejándolas por una columna relacionada —normalmente un ID.
Por qué importan los JOINs
La mayoría de las bases de datos reales están intencionalmente divididas en tablas separadas para no repetir la misma información. Por ejemplo, el nombre de un cliente vive en una tabla customers, mientras que sus compras están en orders. Los JOINs son la forma de volver a conectar esas piezas cuando necesitas respuestas.
Por eso los JOINs aparecen en todas partes en reporting y análisis:
- Construir un informe de ventas que incluya nombres de clientes, totales de pedidos y estado de pago
- Encontrar clientes que aún no han comprado
- Auditar desajustes, como pedidos sin pagos
- Crear resúmenes "una fila por cliente" a partir de muchas filas relacionadas
Sin JOINs, tendrías que ejecutar consultas separadas y combinar resultados manualmente: lento, propenso a errores y difícil de repetir.
Si construyes productos encima de una base de datos relacional (dashboards, paneles de administración, herramientas internas, portales de clientes), los JOINs también son los que convierten "tablas crudas" en vistas orientadas al usuario. Plataformas como Koder.ai (que generan apps React + Go + PostgreSQL desde chat) siguen dependiendo de fundamentos sólidos de JOIN cuando necesitas páginas de listas, informes y pantallas de conciliación precisas —porque la lógica de la base de datos no desaparece, aunque el desarrollo sea más rápido.
Los 6 tipos de JOIN que usarás más
Esta guía se centra en seis JOINs que cubren la mayoría del trabajo diario en SQL:
- INNER JOIN: devuelve solo las filas que coinciden en ambas tablas (mejor para "mostrar relaciones confirmadas").
- LEFT JOIN: conserva cada fila de la tabla izquierda, y empareja lo que pueda de la derecha (mejor para "incluir datos relacionados faltantes").
- RIGHT JOIN: el espejo del LEFT JOIN (menos común, pero útil según el estilo o legibilidad de la consulta).
- FULL OUTER JOIN: conserva todas las filas de ambas tablas, emparejándolas cuando sea posible (ideal para conciliación y detección de huecos).
- CROSS JOIN: produce todas las combinaciones de filas (útil para generar calendarios, escenarios o datos de prueba—también fácil de usar mal).
- SELF JOIN: unir una tabla consigo misma (útil para jerarquías como empleados/gerentes).
Una nota rápida sobre la sintaxis
La sintaxis de JOIN es muy similar en la mayoría de las bases de datos SQL (PostgreSQL, MySQL, SQL Server, SQLite). Hay algunas diferencias —especialmente con el soporte de FULL OUTER JOIN y ciertos comportamientos de casos límite— pero los conceptos y patrones principales se transfieren con claridad.
Las tablas de ejemplo que usaremos (customers, orders, payments)
Para mantener los ejemplos simples usaremos tres tablas pequeñas que reproducen un escenario común: los clientes hacen pedidos y los pedidos pueden (o no) tener pagos.
Una nota pequeña antes de empezar: las tablas de ejemplo muestran solo unas pocas columnas, pero algunas consultas posteriores hacen referencia a campos adicionales (como order_date, created_at, status o paid_at) para demostrar patrones comunes. Trata esas columnas como campos "típicos" que a menudo verías en esquemas de producción.
1) customers
Clave primaria: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
2) orders
Clave primaria: order_id
Clave foránea: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Observa que order_id = 104 referencia customer_id = 5, que no existe en customers. Esa "coincidencia faltante" es útil para ver cómo se comportan LEFT JOIN, RIGHT JOIN y FULL OUTER JOIN.
3) payments
Clave primaria: payment_id
Clave foránea: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Dos detalles importantes para enseñanza aquí:
order_id = 102tiene dos filas de pago (un pago dividido). Cuando unasordersconpayments, ese pedido aparecerá dos veces—aquí es donde los duplicados suelen sorprender.payment_id = 9004referenciaorder_id = 999, que no existe enorders. Eso crea otro caso "sin coincidencia".
Qué esperar cuando unimos estas tablas
- Filas coincidentes: p. ej., cliente 1 ↔ pedidos 101/102; pedido 101 ↔ pago 9001.
- Filas sin coincidencia: p. ej., clientes 3 y 4 no tienen pedidos; el pedido 104 no tiene cliente; el pago 9004 no tiene pedido.
- Duplicados: unir
ordersconpaymentsrepetirá el pedido 102 porque tiene dos pagos.
INNER JOIN: conservar solo filas coincidentes
Un INNER JOIN devuelve únicamente las filas donde hay coincidencia en ambas tablas. Si un cliente no tiene pedidos, no aparecerá. Si un pedido apunta a un cliente inexistente (datos sucios), ese pedido tampoco aparecerá.
El patrón básico
Eliges una tabla "izquierda", unes una tabla "derecha" y las conectas con una condición en la cláusula ON.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
La idea clave es la línea ON o.customer_id = c.customer_id: le dice a SQL cómo se relacionan las filas.
Caso de uso real: clientes que hicieron pedidos
Si quieres una lista solo de clientes que han realizado al menos un pedido (y los detalles del pedido), INNER JOIN es la opción natural:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Esto es útil para cosas como "enviar un email de seguimiento de pedido" o "calcular ingresos por cliente" (cuando solo te interesan clientes con compras).
Error común: condiciones de join ausentes o poco claras
Si escribes una unión pero olvidas la condición ON (o unes por columnas equivocadas), puedes crear accidentalmente un producto cartesiano (cada cliente combinado con cada pedido) o producir coincidencias sutilmente incorrectas.
Malo (no lo hagas):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Asegúrate siempre de tener una condición clara en ON (o USING en los casos específicos donde aplique —cubierto más adelante).
LEFT JOIN: conservar todo de la tabla izquierda
Un LEFT JOIN devuelve todas las filas de la tabla izquierda, y añade los datos coincidentes de la tabla derecha cuando exista la coincidencia. Si no hay coincidencia, las columnas del lado derecho aparecen como NULL.
Cuándo usarlo
Usa LEFT JOIN cuando quieras una lista completa de tu tabla primaria, más datos relacionados opcionales.
Ejemplo: "Muéstrame todos los clientes, e incluye sus pedidos si los tienen."
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
- Los clientes con pedidos aparecerán con sus detalles.
- Los clientes sin pedidos siguen apareciendo, pero
o.order_id(y otras columnas deorders) seránNULL.
Encontrar las filas "sin coincidencia" (patrón clásico)
Una razón muy común para usar LEFT JOIN es encontrar elementos que no tienen registros relacionados.
Ejemplo: "¿Qué clientes nunca han realizado un pedido?"
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Esa condición WHERE ... IS NULL mantiene solo las filas de la tabla izquierda donde la unión no encontró coincidencia.
Cuidado: múltiples coincidencias multiplican filas
LEFT JOIN puede “duplicar” filas de la tabla izquierda cuando hay varias filas coincidentes en la derecha.
Si un cliente tiene 3 pedidos, ese cliente aparecerá 3 veces—una por cada pedido. Eso es esperado, pero puede sorprender si intentas contar clientes.
Por ejemplo, esto cuenta pedidos (no clientes):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Si tu objetivo es contar clientes, normalmente contarás la clave del cliente en su lugar (a menudo con COUNT(DISTINCT c.customer_id)), dependiendo de lo que estés midiendo.
RIGHT JOIN: conservar todo de la tabla derecha
Un RIGHT JOIN conserva todas las filas de la tabla derecha, y solo las filas coincidentes de la izquierda. Si no hay coincidencia, las columnas de la tabla izquierda aparecerán como NULL. Es esencialmente la imagen espejo de un LEFT JOIN.
Ejemplo sencillo
Usando nuestras tablas de ejemplo, imagina que quieres listar todos los pagos, incluso si no se pueden vincular a un pedido (tal vez el pedido fue eliminado o los datos de pago están sucios).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Lo que obtienes:
- Todos los pagos están incluidos (porque
paymentsestá a la derecha). - Si un pago no tiene pedido coincidente, entonces
o.order_idyo.customer_idseránNULL.
La misma consulta como LEFT JOIN (a menudo preferible)
La mayoría de las veces puedes reescribir un RIGHT JOIN como un LEFT JOIN intercambiando el orden de las tablas:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Esto devuelve el mismo resultado, pero mucha gente lo encuentra más legible: empiezas con la tabla "principal" que te interesa (aquí, payments) y luego traes los datos relacionados de forma "opcional".
Legibilidad: por qué muchos equipos evitan RIGHT JOIN
Muchas guías de estilo SQL desalientan el RIGHT JOIN porque obliga a los lectores a invertir mentalmente el patrón común:
- "Comienza con la tabla principal"
- "LEFT JOIN tablas adicionales"
Cuando las relaciones opcionales se escriben consistentemente como LEFT JOIN, las consultas se vuelven más fáciles de escanear.
Cuándo RIGHT JOIN aún puede ser conveniente
Un RIGHT JOIN puede ser útil cuando estás editando una consulta existente y te das cuenta de que la tabla "que debe conservarse" está actualmente a la derecha. En lugar de reescribir toda la consulta (especialmente si es larga y tiene varias uniones), cambiar una unión a RIGHT JOIN puede ser un ajuste rápido y de bajo riesgo.
FULL OUTER JOIN: conservar todas las filas de ambas tablas
Haz tuyos los códigos generados
Lleva el código fuente contigo cuando tu lógica con muchos JOINs requiera cambios personalizados.
Un FULL OUTER JOIN devuelve todas las filas de ambas tablas.
- Si una fila coincide por la clave, obtienes una fila combinada (como en
INNER JOIN). - Si una fila existe solo en la izquierda, aún aparece —con
NULLen las columnas de la derecha. - Si una fila existe solo en la derecha, aún aparece —con
NULLen las columnas de la izquierda.
Cuándo es útil
Un caso clásico de negocio es la conciliación pedidos vs. pagos:
- quieres ver pedidos pagados (coincidencias)
- pedidos sin pagar (pedido existe, pago faltante)
- pagos sueltos (existe pago pero no pedido — error de datos, reembolso, referencia errónea, etc.)
Ejemplo:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
Soporte por base de datos (quién puede ejecutarlo directamente)
FULL OUTER JOIN está soportado en PostgreSQL, SQL Server y Oracle.
No está disponible en MySQL ni en SQLite (necesitarás una solución alternativa).
Alternativa portátil: UNION de un LEFT JOIN y un RIGHT JOIN
Si tu base de datos no soporta FULL OUTER JOIN, puedes simularlo combinando:
- todas las filas de
orders(con los pagos coincidentes cuando estén disponibles), y - todas las filas de
paymentsque no coincidieron con un pedido.
Un patrón común:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Consejo: cuando veas NULL en un lado, esa es la señal de que la fila "faltaba" en la otra tabla —exactamente lo que quieres para auditorías y conciliaciones.
CROSS JOIN: crear todas las combinaciones (úsalo con cuidado)
Un CROSS JOIN devuelve todas las posibles combinaciones de filas entre dos tablas. Si la tabla A tiene 3 filas y la B tiene 4, el resultado tendrá 3 × 4 = 12 filas. Esto también se llama producto cartesiano.
Eso suena peligroso —y puede serlo— pero es genuinamente útil cuando quieres generar combinaciones.
Un ejemplo pequeño y seguro: tallas × colores (crear SKUs)
Imagina que mantienes opciones de producto en tablas separadas:
sizes: S, M, Lcolors: Red, Blue
Un CROSS JOIN puede generar todas las variantes posibles (útil para crear SKUs, preconstruir un catálogo o pruebas):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Resultado (3 × 2 = 6 filas):
- S / Red
- S / Blue
- M / Red
- M / Blue
- L / Red
- L / Blue
La gran advertencia: los resultados crecen rápido
Porque los recuentos de filas se multiplican, CROSS JOIN puede explotar con rapidez:
- 10,000 clientes × 50 productos = 500,000 filas
- 100,000 × 100,000 = 10,000,000,000 filas
Eso puede ralentizar consultas, abrumar la memoria y producir una salida que nadie puede usar. Si necesitas combinaciones, mantén las tablas de entrada pequeñas y considera agregar límites o filtros de forma controlada.
SELF JOIN: unir una tabla consigo misma
Practica JOINs en una app
Crea una app con PostgreSQL y aplica tu lógica de JOIN en una interfaz real.
Una SELF JOIN es exactamente lo que parece: unes una tabla contigo misma. Esto es útil cuando una fila de la tabla se relaciona con otra fila de la misma tabla —más comúnmente en relaciones padre/hijo como empleados y sus gerentes.
Por qué necesitas alias (y cómo ayudan)
Como estás usando la misma tabla dos veces, debes dar a cada "copia" un alias diferente. Los alias hacen la consulta legible y le dicen a SQL a qué lado te refieres.
Un patrón común es:
epara el empleadompara el gerente
Ejemplo práctico: empleados y sus gerentes
Imagina una tabla employees con:
idnamemanager_id(apunta alidde otro empleado)
Para listar cada empleado con el nombre de su gerente:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Manejar empleados de nivel superior (manager_id NULL)
Fíjate que la consulta usa LEFT JOIN, no INNER JOIN. Eso importa porque algunos empleados pueden no tener gerente (por ejemplo, el CEO). En esos casos, manager_id suele ser NULL, y un LEFT JOIN conserva la fila del empleado mostrando manager_name como NULL.
Si usaras un INNER JOIN en su lugar, esos empleados de nivel superior desaparecerían del resultado porque no hay una fila de gerente que coincida.
Condiciones de join: ON vs USING (y por qué importa)
Una JOIN no "adivina" cómo se relacionan dos tablas: tienes que decirlo. Esa relación se define en la condición de la unión, y debe ir justo al lado del JOIN porque explica cómo coinciden las tablas, no cómo quieres filtrar el resultado final.
ON: lo más flexible (y lo más común)
Usa ON cuando quieras control total sobre la lógica de coincidencia —nombres de columnas diferentes, múltiples condiciones o reglas adicionales.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON también es donde puedes definir coincidencias más complejas (por ejemplo, coincidir por dos columnas) sin convertir tu consulta en un juego de adivinanzas.
USING: más corto, pero solo para columnas con el mismo nombre
Algunas bases de datos (como PostgreSQL y MySQL) soportan USING. Es un atajo conveniente cuando ambas tablas tienen una columna con el mismo nombre y quieres unir por esa columna.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Un beneficio: USING típicamente devuelve solo una columna customer_id en la salida (en lugar de dos copias).
Evita nombres de columna ambiguos: siempre califícalos en joins
Una vez que unes tablas, los nombres de columnas a menudo se solapan (id, created_at, status). Si escribes SELECT id, la base de datos puede lanzar un error de "columna ambigua" —o peor, podrías leer el id equivocado.
Prefiere prefijos de tabla (o alias) para mayor claridad:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
Evita SELECT * en consultas con joins
SELECT * se vuelve desordenado rápidamente con joins: traes columnas innecesarias, arriesgas nombres duplicados y haces más difícil ver lo que la consulta pretende producir.
En su lugar, selecciona las columnas exactas que necesitas. Tu resultado será más limpio, más fácil de mantener y a menudo más eficiente —especialmente cuando las tablas son anchas.
Filtrar datos unidos: WHERE vs ON
Cuando unes tablas, WHERE y ON ambos "filtran", pero lo hacen en momentos diferentes.
- ON decide qué filas coinciden durante la unión.
- WHERE filtra el resultado final después de que la unión ya se formó.
Esa diferencia de momento es la razón por la que la gente convierte accidentalmente un LEFT JOIN en un INNER JOIN.
Cómo WHERE puede romper accidentalmente un LEFT JOIN
Supongamos que quieres todos los clientes, incluso aquellos sin pedidos recientes pagados.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Problema: para clientes sin pedido coincidente, o.status y o.order_date son NULL. La cláusula WHERE rechaza esas filas, así que los clientes sin coincidencia desaparecen —tu LEFT JOIN se comporta como un INNER JOIN.
Mueve las condiciones relacionadas con la unión a ON para conservar filas sin coincidencia
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Ahora los clientes sin pedidos que cumplan la condición siguen apareciendo (con columnas de pedido NULL), que normalmente es el objetivo de un LEFT JOIN.
Lista de comprobación rápida: qué pertenece en ON vs WHERE
- Pon condiciones en ON cuando describan qué filas de la tabla derecha pueden coincidir (filtros sobre estado/fecha/tipo en la tabla unida).
- Pon condiciones en WHERE cuando describan qué filas finales quieres conservar (filtros sobre la tabla izquierda, o cuando intencionalmente requieres una coincidencia).
- Si necesitas "conservar todas las filas izquierdas, pero restringir las filas derechas", prefiere LEFT JOIN + condiciones en ON.
- Si realmente quieres "solo filas con coincidencia", usa INNER JOIN (o
WHERE o.order_id IS NOT NULLexplícitamente).
Evitar filas duplicadas y sorpresas de muchos-a-muchos
Diseña tablas orientadas a JOINs
Relaciona clientes, pedidos y pagos claramente antes de escribir una sola consulta.
Las joins no solo "añaden columnas" —también pueden multiplicar filas. Eso suele ser el comportamiento correcto, pero a menudo sorprende cuando los totales se duplican (o peor).
Por qué las filas se multiplican
Una unión devuelve una fila de salida por cada par de filas coincidentes.
- Uno-a-muchos: Un cliente puede tener muchos pedidos. Si unes
customersconorders, cada cliente puede aparecer múltiples veces —una por pedido. - Muchos-a-muchos (la trampa real): Si unes
ordersconpaymentsy cada pedido puede tener múltiples pagos (cuotas, reintentos, reembolsos parciales), puedes obtener varias filas por pedido. Si además unes a otra tabla "muchos" (comoorder_items), puedes crear un efecto de multiplicación:payments × itemspor pedido.
Preagrega antes de unir
Si tu objetivo es "una fila por cliente" o "una fila por pedido", resume primero el lado "muchos" y luego únete.
-- Una fila por pedido a partir de payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Esto mantiene la "forma" de la unión predecible: una fila de pedido sigue siendo una fila de pedido.
DISTINCT como último recurso
SELECT DISTINCT puede aparentar arreglar duplicados, pero puede ocultar el problema real:
- Puede eliminar filas legítimas de forma silenciosa.
- Puede enmascarar una condición de unión incorrecta (por ejemplo, falta de parte de una clave compuesta).
- Puede estropear totales (especialmente sumas y conteos).
Úsalo solo cuando estés seguro de que los duplicados son puramente accidentales y entiendas por qué ocurrieron.
Comprobación rápida de seguridad: valida conteos
Antes de confiar en los resultados, compara recuentos de filas:
- Cuenta filas en tu tabla principal (p. ej., orders).
- Cuenta filas después de la unión.
- Si el número salta inesperadamente, inspecciona qué claves causan múltiples coincidencias y decide si necesitas preagregación o una ruta de unión diferente.
Conceptos básicos de rendimiento y una chuleta rápida de JOIN
Se culpa a menudo a los JOINs de "consultas lentas", pero la causa real suele ser cuánto dato pides combinar y qué tan fácilmente la base de datos puede encontrar filas coincidentes.
Indexación (conceptualmente) y por qué ayuda a los JOINs
Piensa en un índice como el índice de contenidos de un libro. Sin él, la base de datos puede necesitar escanear muchas filas para encontrar las coincidencias de tu condición ON. Con un índice en la clave de unión (por ejemplo, customers.customer_id y orders.customer_id), la base de datos puede saltar rápidamente a las filas relevantes.
No necesitas conocer los detalles internos para usar esto bien: si una columna se usa con frecuencia para coincidir filas (ON a.id = b.a_id), es buena candidata para ser indexada.
Une sobre claves estables (no nombres ni emails)
Siempre que sea posible, une sobre identificadores estables y únicos:
- Bueno:
customers.customer_id = orders.customer_id - Riesgoso:
customers.email = orders.emailocustomers.name = orders.name
Los nombres cambian y pueden repetirse. Los emails pueden cambiar, faltar o diferir por mayúsculas/formato. Los IDs están diseñados para coincidencias consistentes y suelen estar indexados.
Reduce el trabajo lo antes posible
Dos hábitos hacen que los JOINs sean notablemente más rápidos:
- Selecciona menos columnas. Evita
SELECT *cuando unas varias tablas; las columnas extra aumentan uso de memoria y red. - Limita filas antes o durante la JOIN. Filtra tan pronto como razonablemente puedas.
Ejemplo: limita orders primero y luego úne:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Si iteras sobre estas consultas dentro de la construcción de una app (por ejemplo, creando una página de reportes respaldada por PostgreSQL), herramientas como Koder.ai pueden acelerar el scaffolding —esquema, endpoints, UI— mientras mantienes el control de la lógica de JOIN que determina la corrección.
Chuleta rápida de JOIN
- INNER JOIN → solo filas que coinciden en ambas tablas
- LEFT JOIN → todas las filas de la tabla izquierda, más coincidencias de la derecha (no-coincidencias aparecen como
NULL) - RIGHT JOIN → todas las filas de la tabla derecha, más coincidencias de la izquierda (
NULLcuando faltan) - FULL OUTER JOIN → todas las filas de ambas tablas; las coincidencias se combinan, las no-coincidencias muestran
NULL - CROSS JOIN → cada combinación de filas (el tamaño se multiplica; úsalo con cuidado)
- SELF JOIN → una tabla unida consigo misma (útil para jerarquías y comparaciones)
Preguntas frecuentes
¿Qué es una JOIN en SQL en lenguaje sencillo?
Una JOIN en SQL combina filas de dos (o más) tablas en un único conjunto de resultados emparejando columnas relacionadas, normalmente una clave primaria con una clave foránea (por ejemplo, customers.customer_id = orders.customer_id). Así es como "reconectas" tablas normalizadas cuando necesitas informes, auditorías o análisis.
¿Cuándo debo usar INNER JOIN?
Usa INNER JOIN cuando solo quieras filas en las que exista la relación en ambas tablas.
- Los clientes sin pedidos no aparecerán.
- Los pedidos que apunten a un cliente inexistente no aparecerán.
Es ideal para relaciones "confirmadas", como listar únicamente los clientes que realmente hicieron pedidos.
¿Cómo encuentro filas que no tienen coincidencia en otra tabla?
Usa LEFT JOIN cuando necesites todas las filas de tu tabla principal (izquierda), más los datos relacionados de la derecha cuando existan.
Para encontrar "coincidencias faltantes", haz la unión y luego filtra el lado derecho a NULL:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
¿Realmente necesito RIGHT JOIN y cómo lo reemplazo con LEFT JOIN?
RIGHT JOIN conserva todas las filas de la tabla derecha y rellena las columnas de la izquierda con NULL cuando no hay coincidencia. Muchos equipos lo evitan porque se lee "al revés".
En la mayoría de los casos puedes reescribirlo como LEFT JOIN invirtiendo el orden de las tablas:
FROM payments p
orders o o.order_id p.order_id
¿Para qué sirve mejor FULL OUTER JOIN?
Usa FULL OUTER JOIN para conciliaciones: quieres coincidencias, filas solo-izquierda y filas solo-derecha en una misma salida.
Es genial para auditorías como "pedidos sin pagos" y "pagos sin pedidos", porque los lados no coincidentes aparecen con columnas NULL.
¿Qué hago si mi base de datos no soporta FULL OUTER JOIN?
Algunas bases de datos (notablemente MySQL y SQLite) no soportan FULL OUTER JOIN directamente. Un patrón común es combinar dos consultas:
orders LEFT JOIN payments- más las filas que solo están en payments
Normalmente se hace con UNION (o UNION ALL con cuidado) para conservar tanto los registros "solo-izquierda" como los "solo-derecha".
¿Qué es un CROSS JOIN y cuándo es realmente útil?
Un CROSS JOIN devuelve todas las combinaciones entre dos tablas (producto cartesiano). Es útil para generar escenarios (por ejemplo, tallas × colores) o construir una cuadrícula de calendario.
Ten cuidado: el número de filas se multiplica rápidamente y puede hacer explotar el tamaño de salida o ralentizar las consultas si las entradas no son pequeñas y controladas.
¿Qué es una SELF JOIN y por qué necesito alias de tabla?
Una self join es unir una tabla consigo misma para relacionar filas dentro de la misma tabla (común en jerarquías como empleado → gerente).
Debes usar alias para distinguir las dos "copias":
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
¿Cuál es la diferencia entre filtrar en ON y en WHERE para joins?
ON define cómo coinciden las filas durante la unión; WHERE filtra después de que el resultado de la unión ya se ha formado. Con LEFT JOIN, una condición WHERE sobre la tabla derecha puede eliminar las filas con NULL y convertirlo en un INNER JOIN efectivo.
Si quieres conservar todas las filas izquierdas pero restringir qué filas derechas pueden coincidir, pon el filtro de la tabla derecha en .
¿Por qué las joins crean duplicados y cómo evito contar doble?
Las joins pueden multiplicar filas cuando la relación es uno-a-muchos (o muchos-a-muchos). Por ejemplo, un pedido con dos pagos aparecerá dos veces al unir orders con payments.
Para conservar "una fila por pedido/cliente", agrega primero (preagrega) el lado "muchos" (por ejemplo, SUM(amount) agrupado por order_id) y luego únelo. Usa DISTINCT solo como último recurso porque puede ocultar problemas reales de la unión y estropear totales.