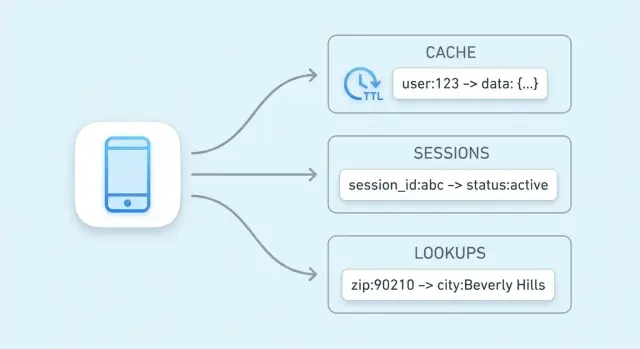
Por qué se usan los almacenes clave-valor para velocidad
El objetivo principal de un almacén clave-valor es simple: reducir la latencia para los usuarios finales y disminuir la carga sobre tu base de datos primaria. En lugar de ejecutar la misma consulta costosa o recalcular el mismo resultado, tu aplicación puede recuperar un valor precomputado en un solo paso predecible.
Rápido porque la ruta de acceso es simple
Un almacén clave-valor está optimizado en torno a una operación: “dada esta clave, devuelve el valor”. Ese enfoque estrecho permite un camino crítico muy corto.
En muchos sistemas, una búsqueda puede manejarse con frecuencia mediante:
- un índice en memoria (así no hay búsqueda en disco)
- hashing directo de clave → ubicación (poca búsqueda)
- menos características de alto coste en CPU que un motor de consultas de propósito general
El resultado son tiempos de respuesta bajos y consistentes—exactamente lo que necesitas para caching, almacenamiento de sesiones y otras búsquedas de alta velocidad.
Rápido porque evita trabajo en otro lado
Aunque tu base de datos esté bien afinada, aún tiene que parsear consultas, planificarlas, leer índices y coordinar concurrencia. Si miles de peticiones piden la misma lista de “top products”, ese trabajo repetido se acumula.
Una caché clave-valor desplaza ese tráfico de lectura repetido fuera de la base de datos. Tu base de datos puede dedicar más tiempo a lo que realmente lo requiere: escrituras, joins complejos, reporting y lecturas que necesitan consistencia estricta.
No todos los workloads encajan
La velocidad no es gratis. Los almacenes clave-valor suelen renunciar a consultas ricas (filtros, joins) y pueden ofrecer garantías distintas sobre persistencia y consistencia según la configuración.
Brillan cuando puedes nombrar los datos con una clave clara (por ejemplo, user:123, cart:abc) y quieres una recuperación rápida. Si necesitas con frecuencia “encontrar todos los ítems donde X”, una base relacional o documental suele ser mejor como almacén primario.
Fundamentos clave-valor: claves, valores y búsquedas
Un almacén clave-valor es el tipo más simple de base de datos: guardas un valor (datos) bajo una clave única (etiqueta), y luego recuperas el valor proporcionando la clave.
Qué son realmente una “clave” y un “valor”
Piensa en una clave como un identificador que es fácil de repetir exactamente, y un valor como lo que quieres recuperar.
- Guardarropas: tu número de ticket es la clave; tu abrigo es el valor.
- Agenda de contactos: “Alice Chen” (o un ID de contacto) es la clave; el teléfono y detalles son el valor.
- Sesiones: un token de sesión aleatorio es la clave; el ID de usuario y el estado de sesión son el valor.
Las claves suelen ser cadenas cortas (como user:1234 o session:9f2a...). Los valores pueden ser pequeños (un contador) o más grandes (un blob JSON).
Cómo funcionan las búsquedas de tiempo casi constante (alto nivel)
Los almacenes clave-valor se construyen para consultas “dame el valor para esta clave”. Internamente, muchos usan una estructura similar a una tabla hash: la clave se transforma en una ubicación donde se encuentra el valor rápidamente.
Por eso se habla a menudo de búsquedas en tiempo constante (O(1)): el rendimiento depende más de cuántas peticiones haces que de cuántos registros totales existen. No es magia: colisiones y límites de memoria importan, pero para uso típico de caché/sesiones es muy rápido.
Despliegues típicos: en memoria, en disco o híbrido
- En memoria: lecturas/escrituras más rápidas; los datos pueden perderse al reiniciar a menos que se persistan.
- En disco: más lento que RAM pero almacena más datos y sobrevive reinicios.
- Híbrido: mantiene datos calientes en memoria mientras escribe en disco para recuperación.
Qué significa “datos calientes” (y por qué importa)
Datos calientes es la porción pequeña de información solicitada repetidamente (páginas de productos populares, sesiones activas, contadores de rate-limit). Mantener datos calientes en un almacén clave-valor—especialmente en memoria—evita consultas más lentas a la base de datos y mantiene tiempos de respuesta predecibles bajo carga.
Caché 101: qué cachear y por qué
Cachear significa mantener una copia de datos que se necesitan con frecuencia en un lugar más rápido que la fuente original. Un almacén clave-valor es un sitio común para esto porque puede devolver un valor en una sola búsqueda por clave, a menudo en pocos milisegundos.
Cuando el caching ayuda más
El caching brilla cuando las mismas preguntas se repiten: páginas populares, búsquedas repetidas, llamadas de API comunes o cálculos costosos. También es útil cuando la fuente “real” es más lenta o tiene limitaciones de tasa—por ejemplo, una base de datos primaria bajo alta carga o una API de terceros que cobra por petición.
Qué cachear (ejemplos prácticos)
Buenos candidatos son resultados que se leen a menudo y no necesitan estar perfectamente al minuto:
- Resúmenes de perfil de usuario (nombre, URL de avatar, preferencias)
- Listas de productos y páginas de categoría
- Resultados computados (recomendaciones, totales, fragmentos de informes)
- Configuración y flags de función leídos en cada petición
- Respuestas de APIs externas que son seguras de reutilizar por un corto periodo
Una regla simple: cachea outputs que puedas regenerar si es necesario. Evita cachear datos que cambian constantemente o que deben ser consistentes en todas las lecturas (por ejemplo, un saldo bancario).
Por qué el caching reduce la presión sobre DBs y APIs
Sin caching, cada vista de página podría activar múltiples consultas a la base de datos o llamadas a APIs. Con una caché, la aplicación puede servir muchas peticiones desde el almacén clave-valor y solo “caer” a la base de datos o API en un cache miss. Eso reduce el volumen de consultas, disminuye la contención de conexiones y puede mejorar la fiabilidad durante picos de tráfico.
Riesgos: datos obsoletos y lecturas inconsistentes
Cachéar intercambia frescura por velocidad. Si los valores cacheados no se actualizan con rapidez, los usuarios pueden ver información obsoleta. En sistemas distribuidos, dos peticiones pueden leer versiones diferentes del mismo dato brevemente.
Gestionas estos riesgos eligiendo TTLs adecuados, decidiendo qué datos pueden estar “ligeramente anticuados” y diseñando la app para tolerar miss de caché o retrasos en el refresco.
Patrones comunes de caché y cuándo usarlos
Un “patrón” de caché es un flujo repetible sobre cómo tu app lee y escribe datos cuando hay una caché implicada. Elegir el correcto depende menos de la herramienta (Redis, Memcached, etc.) y más de la frecuencia de cambio de los datos subyacentes y cuánto toleras datos obsoletos.
Cache-aside (carga perezosa)
Con cache-aside, tu aplicación controla la caché explícitamente:
- Lee desde la caché por clave.
- Si hay miss, lee desde la base de datos/origen de la verdad.
- Mete el resultado en la caché con un TTL.
- Devuelve el resultado.
Mejor para: datos que se leen mucho y cambian poco (páginas de producto, configuración, perfiles públicos). También es bueno por defecto porque las fallas degradan con gracia: si la caché está vacía, aún puedes leer de la DB.
Read-through vs write-through
Read-through significa que la capa de caché carga desde la base de datos en un miss (tu app lee “desde la caché” y la caché sabe cómo cargar). Operativamente simplifica el código de la app, pero añade complejidad a la capa de caché (necesitas una integración de loader).
Write-through significa que cada escritura va a la caché y a la base de datos de forma síncrona. Las lecturas suelen ser rápidas y consistentes, pero las escrituras son más lentas porque deben completar dos operaciones.
Mejor para: datos donde quieres menos misses y lecturas más consistentes (ajustes de usuario, feature flags), y donde la latencia en escritura es aceptable.
Write-back / write-behind
Con write-back, tu app escribe primero en la caché y la caché vuelca cambios a la base de datos más tarde (a menudo en lotes).
Beneficios: escrituras muy rápidas y menor carga en la DB.
Riesgo añadido: si el nodo de caché falla antes de volcar, puedes perder datos. Úsalo solo cuando puedas tolerar pérdidas o tengas mecanismos de durabilidad fuertes.
Cómo elegir según la frecuencia de cambio
Si los datos cambian raramente, cache-aside con un TTL sensato suele bastar. Si cambian con frecuencia y lecturas obsoletas son problemáticas, considera write-through (o TTLs muy cortos más invalidación explícita). Si el volumen de escrituras es extremo y la pérdida ocasional es aceptable, write-behind puede valer la pena.
Controles de frescura: TTLs, expiración e invalidación
Mantener los datos cacheados “lo suficientemente frescos” trata principalmente de elegir la estrategia de expiración adecuada por clave. El objetivo no es la precisión perfecta: es evitar sorpresas por datos obsoletos mientras obtienes beneficios de velocidad.
TTLs y expiraciones: qué hacen (y cómo elegirlos)
Un TTL (time to live) establece una expiración automática para una clave para que desaparezca (o deje de estar disponible) tras una duración. TTLs cortos reducen la obsolescencia pero suben los misses y la carga en el backend. TTLs largos mejoran la tasa de aciertos pero arriesgan servir valores desactualizados.
Una forma práctica de elegir TTLs:
- Alinea con la frecuencia de cambio de los datos. Precios de producto pueden necesitar minutos; un perfil de usuario, horas.
- Considera el impacto de negocio. Un conteo de “likes” obsoleto suele ser aceptable; un “saldo” no.
- Añade pequeña aleatoriedad (jitter). Si muchas claves comparten TTL, pueden expirar juntas y causar picos.
Invalidación activa: borrar o actualizar cuando cambian datos
El TTL es pasivo. Cuando sabes que los datos han cambiado, a menudo es mejor invalidar activamente: borrar la clave vieja o escribir el nuevo valor de inmediato.
Ejemplo: después de que un usuario actualice su email, borra user:123:profile o actualízalo en la caché de inmediato. La invalidación activa reduce ventanas de obsolescencia, pero requiere que tu aplicación realice esas actualizaciones de forma fiable.
Claves versionadas: invalidación simple y de bajo riesgo
En lugar de borrar claves, incluye una versión en el nombre de la clave, como product:987:v42. Cuando el producto cambia, subes la versión y empiezas a usar v43. Las versiones antiguas expiran de forma natural después. Esto evita carreras donde un servidor borra una clave mientras otro la escribe.
Manejo de stampedes de caché
Un stampede ocurre cuando una clave popular expira y muchas peticiones la reconstruyen al mismo tiempo.
Soluciones comunes incluyen:
- Coalescencia/locking de peticiones: solo una petición recompone; las demás esperan.
- Servir obsoleto mientras se revalida: devolver el valor anterior brevemente mientras se refresca en background.
- Refresh anticipado: refrescar un poco antes de que acabe el TTL (especialmente para claves calientes).
Almacenamiento de sesiones con un almacén clave-valor
Planifica tu estrategia de caché
Usa el modo de planificación para diseñar claves, TTLs e invalidación antes de lanzar.
Los datos de sesión son el paquete pequeño de información que tu app necesita para reconocer un navegador o cliente móvil recurrente. Como mínimo, es un ID de sesión (o token) que mapea a estado del lado servidor. Dependiendo del producto, también puede incluir estado de usuario (flags de login, roles, nonce CSRF), preferencias temporales y datos sensibles al tiempo como el contenido del carrito.
Por qué los almacenes clave-valor encajan con sesiones
Los almacenes clave-valor encajan naturalmente porque lecturas y escrituras de sesión son simples: buscar un token, recuperar un valor, actualizarlo y fijar una expiración. También facilitan aplicar TTLs para que sesiones inactivas desaparezcan automáticamente, manteniendo el almacenamiento limpio y reduciendo riesgo si se filtra un token.
Flujo común:
- En login: crea un token de sesión aleatorio y guarda los datos bajo esa clave.
- En cada petición: lee por token, refresca TTL si usas expiración deslizante.
- En logout (o actividad sospechosa): borra la clave inmediatamente.
Diseño de claves de sesión
Usa claves claras, acotadas y valores pequeños:
- Nombres:
sess:\u003ctoken\u003e o sess:v2:\u003ctoken\u003e (versionar ayuda en cambios futuros).
- Escopado por usuario: opcionalmente mantiene
user_sess:\u003cuserId\u003e -> \u003ctoken\u003e para imponer “una sesión activa por usuario” o revocar sesiones por usuario.
- Límites de tamaño: evita meter perfiles enteros en la sesión. Guarda solo lo imprescindible; mantén datos más grandes en la DB primaria y referencia esa fuente.
Logout y rotación
El logout debe borrar la clave de sesión y cualquier índice relacionado (por ejemplo, user_sess:\u003cuserId\u003e). Para rotación (recomendado tras login, cambios de privilegios o periódicamente), crea un token nuevo, escribe la sesión nueva y luego borra la antigua. Esto reduce la ventana en la que un token robado sigue siendo útil.
Búsquedas de alta velocidad más allá del caching
El caching es el caso de uso más común, pero no es la única forma en que un almacén clave-valor puede acelerar tu sistema. Muchas aplicaciones dependen de lecturas rápidas para pequeñas piezas de estado referenciadas con frecuencia—cosas que están “adyacentes a la fuente de la verdad” y que deben comprobarse rápidamente en casi cada petición.
Datos de autorización: permisos y derechos
Los chequeos de autorización suelen estar en el camino crítico: cada llamada a la API puede necesitar responder “¿puede este usuario hacer esto?”. Extraer permisos de una base de datos relacional en cada petición añade latencia y carga.
Un almacén clave-valor puede contener datos compactos de autorización para búsquedas rápidas, por ejemplo:
perm:user:123 → una lista/conjunto de códigos de permisoentitlement:org:45 → características del plan habilitadas
Esto es útil cuando el modelo de permisos es de lectura intensiva y cambia relativamente poco. Cuando los permisos cambian (actualizaciones de rol, upgrades), puedes actualizar o invalidar un pequeño conjunto de claves.
Feature flags y lecturas de configuración
Los feature flags son valores pequeños leídos con frecuencia y que deben estar disponibles rápida y consistentemente en muchos servicios.
Un patrón común es almacenar:
flag:new-checkout → true/falseconfig:tax:region:EU → blob JSON o configuración versionada
Los almacenes clave-valor funcionan bien porque las lecturas son simples, predecibles y muy rápidas. También puedes versionar valores (por ejemplo, config:v27:...) para despliegues más seguros y permitir rollback rápido.
Limitación de tasa y throttling con contadores
La limitación de tasa suele reducirse a contadores por usuario, API key o IP. Los almacenes clave-valor normalmente soportan operaciones atómicas que permiten incrementar un contador con seguridad incluso cuando llegan muchas peticiones a la vez.
Por ejemplo:
rl:user:123:minute → incrementar cada petición, expirar tras 60 segundosrl:ip:203.0.113.10:second → control de ráfaga en ventanas cortas
Con un TTL en cada clave contador, los límites se reinician automáticamente sin trabajos en background. Esto es práctico para proteger intentos de login, endpoints costosos o hacer cumplir cuotas por plan.
Claves de idempotencia para endpoints seguros a reintentos
Pagos y otras operaciones "hacer exactamente una vez" necesitan protección contra reintentos—por timeouts, reintentos del cliente o reenvío de mensajes.
Un almacén clave-valor puede registrar claves de idempotencia:
idem:pay:order_789:clientKey_abc → resultado o estado guardado
En la primera petición procesas y guardas el resultado con un TTL. En reintentos posteriores devuelves el resultado guardado en vez de ejecutar la operación otra vez. El TTL evita crecimiento sin límite mientras cubre la ventana realista de reintentos.
Estos usos no siempre son “caching” en el sentido clásico; son mantener latencia baja para lecturas frecuentes y primitivas de coordinación que necesitan velocidad y atomicidad.
Estructuras de datos útiles y operaciones atómicas
Crea un starter full-stack
Genera un frontend en React y un backend en Go con PostgreSQL listo para caché.
“Almacén clave-valor” no siempre significa “string in, string out”. Muchos sistemas ofrecen estructuras de datos más ricas que te permiten modelar necesidades comunes directamente dentro del almacén—a menudo más rápido y con menos piezas móviles que poner todo en el código de la aplicación.
Hashes/maps: múltiples campos bajo una clave
Los hashes (o maps) son ideales cuando tienes una sola “entidad” con varios atributos relacionados. En lugar de muchas claves como user:123:name, user:123:plan, user:123:last_seen, puedes mantenerlos juntos bajo una clave user:123 con campos.
Esto reduce la proliferación de claves y te permite recuperar o cambiar solo el campo que necesitas—útil para perfiles, feature flags o pequeños blobs de configuración.
Sets y sorted sets: pertenencia y ranking
Los sets son excelentes para consultas “¿está X en el grupo?”:
- ¿ya canjeó este usuario un cupón?
- ¿qué IDs de producto están en la colección “summer-sale”?
Los sorted sets añaden orden por una puntuación, útil para tablas de líderes, “top N” y ordenación por tiempo o popularidad. Puedes almacenar puntajes como contadores de vistas o timestamps y leer rápidamente los ítems principales.
Incrementos atómicos y escrituras condicionales
Los problemas de concurrencia aparecen en características pequeñas: contadores, cuotas, acciones únicas y rate limits. Si dos peticiones llegan a la vez y tu app hace “leer → sumar 1 → escribir”, puedes perder actualizaciones.
Las operaciones atómicas resuelven esto realizando el cambio como un paso único e indivisible dentro del almacén:
- Incremento atómico para contadores (vistas, reintentos, llamadas a la API)
- Escritura condicional (solo setear si falta, solo actualizar si la versión coincide) para evitar doble procesamiento
Por qué las operaciones atómicas simplifican contadores y límites
Con incrementos atómicos no necesitas locks ni coordinación extra entre servidores. Eso significa menos condiciones de carrera, rutas de código más simples y comportamiento más predecible bajo carga—especialmente para rate limiting y límites de uso donde un “casi correcto” puede convertirse en un problema visible para clientes.
Escalado para tráfico: replicación, sharding y disponibilidad
Cuando un almacén clave-valor maneja tráfico serio, “hacerlo más rápido” suele significar “hacerlo más ancho”: repartir lecturas y escrituras entre múltiples nodos manteniendo el sistema predecible ante fallos.
Escalar lecturas y escrituras: replicación vs sharding
Replicación mantiene múltiples copias de los mismos datos.
- Para workloads con muchas lecturas (típico en caching), los réplicas pueden servir lecturas en paralelo.
- Las escrituras suelen ir a un nodo primario (o líder) y luego se copian a réplicas, lo que puede introducir pequeños retrasos antes de que las réplicas reflejen el último valor.
Sharding divide el espacio de claves entre nodos.
- Cada nodo posee un subconjunto de claves (por ejemplo, determinado por hashing de la clave).
- El sharding aumenta tanto el throughput de lectura como de escritura porque el trabajo se distribuye, pero añade complejidad operativa (re-balanceo de shards, manejo de “claves calientes”, y rastrear qué nodo posee qué claves).
Muchos despliegues combinan ambos: shards para throughput y réplicas por shard para disponibilidad.
Alta disponibilidad y failover en la práctica
“Alta disponibilidad” normalmente significa que la capa de caché/sesiones sigue sirviendo peticiones incluso si un nodo falla.
- Failover es la promoción automática de una réplica a primaria cuando la primaria muere.
- En la práctica, tu app debe tolerar errores breves o reintentos durante el switchover, y aceptar que algunas escrituras recientes pueden perderse si no se replicaron aún.
Enrutamiento lado cliente vs lado servidor
Con enrutamiento en el cliente, tu aplicación (o su librería) calcula qué nodo tiene una clave (común con hashing consistente). Esto puede ser muy rápido, pero los clientes deben aprender cambios de topología.
Con enrutamiento lado servidor, envías peticiones a un proxy o endpoint de cluster que las reenvía al nodo correcto. Esto simplifica clientes y despliegues, pero añade un salto.
Planificación de capacidad: memoria, margen y crecimiento
Planifica memoria de arriba hacia abajo:
- Estima el tamaño del working-set (lo que esperas mantener “caliente”), más overhead de metadatos.
- Añade margen (a menudo 20–50%) para picos de tráfico, re-balanceos y distribución desigual de claves.
- Valida el comportamiento de la política de evicción bajo carga para que el sistema degrade con gracia en lugar de entrar en thrashing.
Fiabilidad y compensaciones a entender
Los almacenes clave-valor se sienten “instantáneos” porque mantienen datos calientes en memoria y optimizan lecturas/escrituras rápidas. Esa velocidad tiene un coste: a menudo eliges entre rendimiento, durabilidad y consistencia. Entender las compensaciones desde el inicio evita sorpresas dolorosas más adelante.
Persistencia: cuánto dato puedes permitirte perder
Muchos almacenes clave-valor pueden ejecutarse con diferentes modos de persistencia:
- Ninguna (puro en memoria): más rápido y simple—hasta que un reinicio borre todo. Genial para cachés donde los datos se pueden recomputar.
- Snapshots: guardados periódicos a disco. Si el nodo falla, pierdes cambios desde el último snapshot.
- Registros append-only: las escrituras se graban secuencialmente. La recuperación es más lenta que en memoria pura, pero normalmente se pierde menos.
Elige el modo que coincida con el propósito de los datos: el caching tolera pérdidas; el almacenamiento de sesiones suele necesitar más cuidado.
Expectativas de consistencia: “¿mi escritura quedó realmente?”
En despliegues distribuidos, puedes ver consistencia eventual—las lecturas pueden devolver un valor antiguo tras una escritura, especialmente durante failover o lag de replicación. Consistencia más fuerte (por ejemplo, exigir reconocimientos de múltiples nodos) reduce anomalías pero aumenta latencia y puede reducir disponibilidad en problemas de red.
Cuando la memoria está llena: evicción y comportamiento bajo presión
Las cachés se llenan. Una política de evicción decide qué se elimina: least-recently-used, least-frequently-used, aleatorio, o “no evictions” (lo que convierte memoria llena en fallos de escritura). Decide si prefieres entradas de caché faltantes o errores bajo presión.
Si el almacén cae: plan para modo degradado
Asume que habrá outages. Fallbacks típicos incluyen:
- Saltar la caché y leer desde la DB primaria (con límites de tasa).
- Servir datos ligeramente obsoletos cuando sea seguro.
- Fallar cerrado para operaciones sensibles (por ejemplo, tokens de auth), mientras permites degradación en funcionalidades no críticas.
Diseñar estos comportamientos de forma deliberada es lo que hace que el sistema parezca fiable a los usuarios.
Seguridad, monitorización y costes básicos
Extiende a apps móviles
Añade una app móvil en Flutter que reutilice las mismas APIs en caché y flujos de sesión.
Los almacenes clave-valor suelen estar en el “camino caliente” de tu app. Eso los hace tanto sensibles (pueden contener tokens de sesión o identificadores de usuario) como caros (normalmente intensivos en memoria). Hacer bien lo básico desde temprano evita incidentes dolorosos después.
Seguridad: restringe el acceso
Empieza con límites de red claros: coloca el almacén en una subred/VPC privada y permite tráfico solo desde los servicios de aplicación que realmente lo necesitan.
Usa autenticación si el producto la soporta, y aplica principio de menor privilegio: credenciales separadas para apps, admins y automatización; rota secretos; evita tokens “root” compartidos.
Encripta datos en tránsito (TLS) siempre que sea posible—especialmente si el tráfico cruza hosts o zonas. El cifrado en reposo depende del producto/despliegue; si está disponible, actívalo para servicios gestionados y verifica que los backups también estén cifrados.
Monitorización: qué vigilar diariamente
Un pequeño conjunto de métricas te dice si la caché ayuda o perjudica:
- Hit rate: una caída puede significar claves pobres, TTLs demasiado cortos o churn por evicciones.
- Latencia (p95/p99): picos suelen indicar saturación, problemas de red o valores grandes.
- Uso de memoria & evicciones: uso sostenido alto más evicciones indica que tus datos no caben o la política de evicción no es la adecuada.
- Errores/timeouts: incluso outages breves pueden cascada hacia bases de datos y fallos visibles por usuarios.
Añade alertas por cambios bruscos, no solo umbrales absolutos, y registra operaciones clave con cuidado (evita loggear valores sensibles).
Coste: qué impulsa la factura
Los mayores motores de coste son:
- Huella de memoria: valores grandes, demasiadas claves o guardar datos “agradables de tener”.
- Tráfico: volumen de lecturas/escrituras y transferencias entre zonas.
- Réplica y alta disponibilidad: más nodos por resiliencia aumenta el coste.
- Retención: TTLs largos mantienen datos y aumentan memoria.
Una palanca práctica es reducir el tamaño de los valores y fijar TTLs realistas, para que el almacén guarde solo lo que está activamente útil.
Lista de verificación de implementación y siguientes pasos
Checklist práctico de despliegue
Empieza estandarizando nombres de clave para que tus claves de caché y sesión sean previsibles, buscables y seguras para operar en bloque. Una convención simple como app:env:feature:id (por ejemplo, shop:prod:cart:USER123) ayuda a evitar colisiones y acelera debugging.
Define una estrategia de TTL antes de lanzar. Decide qué datos es seguro expirar rápido (segundos/minutos), qué necesita vidas más largas (horas) y qué nunca debe cachearse. Si cacheas filas de la DB, alinea TTLs con la frecuencia de cambio de los datos subyacentes.
Escribe un plan de invalidación para cada tipo de ítem cacheado:
- Expiración basada en tiempo (solo TTL) para frescura “suficiente”
- Invalidación basada en eventos cuando sabes exactamente qué cambió (p. ej., actualización de producto)
- Claves versionadas (p. ej.,
product:v3:123) cuando quieres invalidar todo de forma simple
Cómo medir el éxito
Elige unas pocas métricas de éxito y monitorízalas desde el día uno:
- Tasa de aciertos de caché por endpoint (para muchas apps, 70–95% es un rango útil)
- Reducción de carga en DB (queries/sec, CPU, uso de réplicas de lectura)
- Cambios en latencia en p95/p99, no solo promedios
También monitorea conteos de evicción y uso de memoria para confirmar que la caché está bien dimensionada.
Errores comunes a evitar
Valores sobredimensionados aumentan tiempo de red y presión de memoria—prefiere cachear fragmentos más pequeños y precomputados. Evita olvidarte de TTLs (datos obsoletos y fugas de memoria) y crecimiento ilimitado de claves (por ejemplo, cachear cada consulta de búsqueda para siempre). Ten cuidado con cachear datos específicos de usuario bajo claves compartidas.
Siguientes pasos
Si estás evaluando opciones, compara un caché local en proceso frente a uno distribuido y decide dónde importa más la consistencia. Para detalles de implementación y orientación operativa, revisa /docs. Si planeas capacidad o necesitas supuestos de precio, ve a /pricing.
Si estás construyendo un producto nuevo (o modernizando uno existente), ayuda diseñar caching y almacenamiento de sesiones como preocupaciones de primera clase desde el inicio. En Koder.ai, los equipos a menudo prototipan una app completa (React en web, servicios en Go con PostgreSQL y opcionalmente Flutter para móvil) y luego iteran en rendimiento con patrones como cache-aside, TTLs y contadores de rate-limiting. Funciones como modo de planificación, snapshots y rollback facilitan probar diseños de claves y estrategias de invalidación de forma segura, y puedes exportar el código fuente cuando estés listo para ejecutarlo en tu propio pipeline.