24 ago 2025·8 min
Cómo construir una app web para onboarding de usuarios multi-pasos
Aprende a diseñar y construir una app web que cree, rastree y mejore flujos de onboarding multi-pasos con pasos claros, modelos de datos y pruebas.
Aprende a diseñar y construir una app web que cree, rastree y mejore flujos de onboarding multi-pasos con pasos claros, modelos de datos y pruebas.
Un onboarding multi-pasos es una secuencia guiada de pantallas que ayuda a un nuevo usuario a pasar de “registrado” a “listo para usar el producto”. En lugar de pedirlo todo de una vez, divides la configuración en pasos más pequeños que se pueden completar en una sesión o a lo largo del tiempo.
Necesitas onboarding multi-pasos cuando la configuración es más que un único formulario—especialmente cuando incluye elecciones, prerrequisitos o chequeos de cumplimiento. Si tu producto requiere contexto (industria, rol, preferencias), verificación (email/teléfono/identidad) o configuración inicial (workspaces, facturación, integraciones), un flujo por pasos mantiene todo comprensible y reduce errores.
El onboarding multi-pasos está en todas partes porque soporta tareas que naturalmente ocurren por etapas, como:
Un buen onboarding no son “pantallas completadas”, sino usuarios alcanzando valor rápidamente. Define el éxito en términos que encajen con tu producto:
El flujo también debe soportar reanudación y continuidad: los usuarios pueden salir y volver sin perder progreso, y deben aterrizar en el siguiente paso lógico.
El onboarding multi-pasos falla de maneras previsibles:
Tu objetivo es hacer que el onboarding se sienta como un camino guiado, no una prueba: propósito claro por paso, seguimiento de progreso fiable y una forma fácil de retomar donde el usuario lo dejó.
Antes de dibujar pantallas o escribir código, decide qué intenta lograr tu onboarding—y para quién. Un flujo multi-pasos solo es “bueno” si lleva de forma fiable a las personas correctas al estado final correcto con mínima confusión.
Diferentes usuarios llegan con distinto contexto, permisos y urgencia. Empieza nombrando tus personas de entrada principales y lo que ya se sabe de ellas:
Para cada tipo, lista restricciones (p. ej., “no puede editar nombre de empresa”), datos requeridos (p. ej., “debe elegir un workspace”) y atajos potenciales (p. ej., “ya verificado vía SSO”).
El estado final del onboarding debe ser explícito y medible. “Hecho” no es “completó todas las pantallas”; es un estado listo para el negocio, por ejemplo:
Escribe los criterios de finalización como una checklist que tu backend pueda evaluar, no como un objetivo vago.
Mapea qué pasos son requeridos para el estado final y cuáles son opcionales. Luego documenta dependencias (“no puedes invitar compañeros hasta que exista el workspace”).
Finalmente, define reglas de salto con precisión: qué pasos pueden saltarse, por qué tipo de usuario y bajo qué condiciones (p. ej., “saltar verificación de email si autenticado vía SSO”) y si los pasos saltados pueden revisitarse más tarde en la configuración.
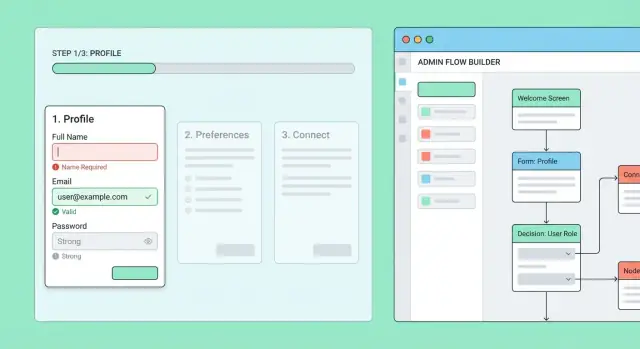
Antes de construir pantallas o APIs, dibuja el onboarding como un mapa de flujo: un diagrama pequeño que muestre cada paso, a dónde puede ir el usuario y cómo puede volver después.
Escribe los pasos con nombres cortos y orientados a la acción (los verbos ayudan): “Crear contraseña”, “Confirmar email”, “Añadir detalles de empresa”, “Invitar compañeros”, “Conectar facturación”, “Finalizar.” Mantén la primera versión simple y luego añade detalle como campos requeridos y dependencias (p. ej., facturación no puede ocurrir antes de la selección de plan).
Una comprobación útil: cada paso debería responder a una pregunta—o “¿Quién eres?” “¿Qué necesitas?” o “¿Cómo debe configurarse el producto?” Si un paso intenta hacer las tres, divídelo.
La mayoría de productos se benefician de una columna vertebral mayormente lineal con ramas condicionales solo cuando la experiencia realmente difiere. Reglas típicas para ramificación:
Documenta estas reglas como notas “if/then” en el mapa (p. ej., “If region = EU → show VAT step”). Esto mantiene el flujo entendible y evita construir un laberinto.
Lista cada lugar donde un usuario puede entrar al flujo:
/settings/onboarding)Cada entrada debe llevar al usuario al siguiente paso correcto, no siempre al paso uno.
Asume que los usuarios saldrán a mitad de paso. Decide qué ocurre cuando vuelvan:
Tu mapa debe mostrar una ruta de “reanudación” clara para que la experiencia se sienta fiable, no frágil.
Un buen onboarding se siente como un camino guiado, no una prueba. El objetivo es reducir la fatiga de decisión, dejar las expectativas claras y ayudar a los usuarios a recuperarse con rapidez cuando algo falla.
Un wizard funciona mejor cuando los pasos deben completarse en orden (p. ej., identidad → facturación → permisos). Un checklist encaja cuando el onboarding puede hacerse en cualquier orden (p. ej., “Añadir logo”, “Invitar compañeros”, “Conectar calendario”). Tareas guiadas (con consejos embebidos y llamadas de atención dentro del producto) son geniales cuando el aprendizaje ocurre haciendo, no rellenando formularios.
Si dudas, empieza con un checklist + deep links a cada tarea, y solo aplica bloqueos a los pasos realmente requeridos.
El feedback de progreso debe responder: “¿Cuánto falta?” Usa una de estas opciones:
También añade una indicación “Guardar y terminar más tarde”, especialmente en flujos largos.
Usa etiquetas claras (“Nombre de la empresa”, no “Entity identifier”). Añade microcopy que explique por qué pides algo (“Usamos esto para personalizar las facturas”). Prefill desde datos existentes cuando sea posible y elige valores por defecto seguros.
Diseña los errores como un camino a seguir: resalta el campo, explica qué hacer, conserva la entrada del usuario y enfoca el primer campo inválido. Para fallos del servidor, muestra una opción de reintento y conserva el progreso para que los usuarios no repitan pasos completados.
Haz targets de toque grandes, evita formularios de varias columnas y mantén la acción primaria visible. Asegura navegación por teclado completa, estados de foco visibles, inputs etiquetados y texto de progreso accesible para lectores de pantalla (no solo una barra visual).
Un flujo multi-pasos fluido depende de un modelo de datos que pueda responder tres preguntas de forma fiable: qué debería ver el usuario a continuación, qué ya ha proporcionado y qué definición del flujo está siguiendo.
Empieza con un conjunto pequeño de tablas/colecciones y crece solo cuando sea necesario:
Esta separación mantiene la “configuración” (Flow/Step) separada de los “datos de usuario” (StepResponse/Progress).
Decide desde temprano si los flujos estarán versionados. En la mayoría de productos, la respuesta es sí.
Cuando editas pasos (renombrar, reordenar, añadir campos requeridos), no quieres que usuarios a mitad del onboarding fallen validaciones o pierdan su lugar. Un enfoque sencillo es:
id y version (o flow_version_id inmutable).flow_version_id específico para siempre.Para guardar progreso, elige entre autosave (guardar mientras el usuario escribe) y guardado explícito con “Next”. Muchos equipos combinan ambos: autosave de borradores y sólo marcar el paso como “completado” al pulsar Next.
Registra timestamps para reporting y troubleshooting: started_at, completed_at y last_seen_at (más per-step saved_at). Estos campos alimentan la analítica de onboarding y ayudan al soporte a entender dónde se quedó alguien.
Un flujo multi-pasos es más fácil de razonar si lo tratas como una máquina de estados: la sesión de onboarding del usuario siempre está en un “estado” (paso actual + estado), y solo permites transiciones específicas entre estados.
En lugar de permitir que el frontend salte a cualquier URL, define un conjunto reducido de estados por paso (por ejemplo: not_started → in_progress → completed) y un conjunto claro de transiciones (por ejemplo: start_step, save_draft, submit_step, go_back, reset_step).
Esto te da comportamiento predecible:
Un paso solo está “completado” cuando ambas condiciones se cumplen:
Guarda la decisión del servidor junto al paso, incluyendo códigos de error. Esto evita casos donde la UI cree que un paso está hecho pero el backend discrepe.
Un caso fácil de pasar por alto: un usuario edita un paso anterior y hace que pasos posteriores queden inválidos. Ejemplo: cambiar “País” puede invalidar “Datos fiscales” o “Planes disponibles”.
Maneja esto trazando dependencias y re-evaluando pasos downstream tras cada envío. Resultados comunes:
needs_review (o revertir a in_progress).“Back” debe ser soportado, pero debe ser seguro:
Esto mantiene la experiencia flexible mientras asegura que el estado de la sesión siga siendo consistente y aplicable.
Tu API backend es la “fuente de verdad” sobre dónde está un usuario en el onboarding, qué ha introducido hasta ahora y qué puede hacer a continuación. Una buena API mantiene el frontend simple: puede renderizar el paso actual, enviar datos de forma segura y recuperarse tras refrescos o problemas de red.
Como mínimo, diseña para estas acciones:
GET /api/onboarding → returns current step key, completion %, and any saved draft values needed to render the step.PUT /api/onboarding/steps/{stepKey} with { "data": {…}, "mode": "draft" | "submit" }POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previousPOST /api/onboarding/complete (server verifies all required steps are satisfied)Mantén las respuestas consistentes. Por ejemplo, después de guardar, devuelve el progreso actualizado más el siguiente paso decidido por el servidor:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
Los usuarios harán doble clic, reintentarán en conexiones pobres o tu frontend puede reenviar peticiones tras un timeout. Haz que “guardar” sea seguro mediante:
Idempotency-Key para requests PUT/POST y deduplicar por (userId, endpoint, key).PUT /steps/{stepKey} como una sobrescritura completa del payload almacenado de ese paso (o documentar claramente las reglas de merge parciales).version (o etag) para impedir sobrescribir datos más nuevos con reintentos obsoletos.Devuelve mensajes accionables que la UI pueda mostrar junto a los campos:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
También distingue 403 (not allowed) de 409 (conflict / wrong step) y 422 (validation) para que el frontend reaccione correctamente.
Separa capacidades de usuario y admin:
GET /api/admin/onboarding/users/{userId} o overrides) deben estar con control de roles y auditados.Este límite evita fugas accidentales de privilegios y permite que soporte/ops ayuden a usuarios atascados.
La tarea del frontend es hacer que el onboarding se sienta fluido incluso cuando la red no lo está. Eso significa routing predecible, comportamiento de reanudación fiable y feedback claro cuando se están guardando datos.
Una URL por paso (p. ej. /onboarding/profile, /onboarding/billing) es usualmente lo más simple de razonar. Soporta atrás/adelante del navegador, deep linking desde emails y facilita refrescar sin perder contexto.
Una página única con estado interno puede valer para flujos muy cortos, pero eleva el riesgo ante refrescos, crashes y escenarios de “copiar enlace para continuar”. Si usas este enfoque, necesitarás persistencia fuerte (ver más abajo) y manejo cuidadoso del historial.
Almacena la finalización de pasos y los últimos datos guardados en el servidor, no solo en local storage. Al cargar la página, solicita el estado de onboarding actual (paso actual, pasos completados y cualquier valor de borrador) y renderiza desde ahí.
Esto habilita:
La UI optimista puede reducir fricción, pero necesita salvaguardas:
Cuando un usuario vuelve, no lo lleves siempre al paso uno. Propón algo como: “Estás al 60%—¿continuar donde lo dejaste?” con dos acciones:
/onboarding)Este pequeño toque reduce el abandono respetando a usuarios que no están listos para terminar todo de inmediato.
La validación es donde los flujos de onboarding se sienten fluidos o frustrantes. La meta es detectar errores temprano, mantener a los usuarios avanzando y todavía proteger tu sistema cuando los datos estén incompletos o sean sospechosos.
Usa validación del lado cliente para prevenir errores obvios antes de una petición de red. Esto reduce fricción y hace que cada paso responda rápido.
Comprobaciones típicas: campos requeridos, límites de longitud, formato básico (email/teléfono) y reglas cruzadas simples (confirmación de contraseña). Mantén mensajes específicos (“Introduce un email de trabajo válido”) y colócalos junto al campo.
Trata la validación del servidor como la fuente de verdad. Incluso si la UI valida perfectamente, los usuarios pueden evitarla.
La validación del servidor debe imponer:
Devuelve errores estructurados por campo para que el frontend destaque exactamente qué hay que corregir.
Algunas validaciones dependen de señales externas o retrasadas: unicidad de email, códigos de invitación, señales de fraude o verificación de documentos. Mánéalas con estados explícitos (p. ej., pending, verified, rejected) y un UI claro.
Si un chequeo está pendiente, permite al usuario continuar cuando sea posible y muestra cuándo lo notificará o qué paso se desbloqueará después.
El onboarding multi-pasos suele tener datos parciales como norma. Decide por paso si:
Un enfoque práctico es “guardar siempre borrador, bloquear solo en la finalización del paso”. Esto permite reanudación sin bajar la calidad de tus datos.
La analítica para onboarding multi-pasos debe responder a dos preguntas: “¿Dónde se atascan las personas?” y “¿Qué cambio mejoraría la finalización?” La clave es rastrear un conjunto pequeño de eventos consistentes en cada paso y hacerlos comparables aun cuando el flujo cambie con el tiempo.
Rastrea los mismos eventos clave para cada paso:
step_viewed (el usuario vio el paso)step_completed (el usuario envió y pasó validación)step_failed (intentó enviar pero falló validación o chequeos del servidor)flow_completed (llegó al estado final de éxito)Incluye un payload de contexto mínimo y estable en cada evento: user_id, flow_id, flow_version, step_id, step_index y un session_id (para separar “en una sesión” de “en varios días”). Si soportas reanudación, añade también resume=true/false en step_viewed.
Para medir abandonos por paso, compara conteos de step_viewed vs. step_completed para la misma flow_version. Para medir tiempo empleado, captura timestamps y calcula:
step_viewed → step_completedstep_viewed → siguiente step_viewed (útil cuando los usuarios saltan)Mantén métricas de tiempo agrupadas por versión; si mezclas versiones viejas y nuevas, las mejoras pueden quedar ocultas.
Si haces A/B tests de copy o reordenamiento de pasos, trátalo como parte de la identidad analítica:
experiment_id y variant_id a cada eventostep_id estable aun si cambia el texto mostradostep_id y usa step_index para la posiciónConstruye un dashboard simple que muestre tasa de finalización, abandono por paso, tiempo mediano por paso y “campos con más fallos” (desde metadatos de step_failed). Añade exportaciones CSV para que los equipos revisen progreso en hojas de cálculo y compartan resultados sin acceso directo a la herramienta de analítica.
Un sistema de onboarding multi-pasos necesitará eventualmente control operativo diario: cambios de producto, excepciones de soporte y experimentación segura. Construir un pequeño área admin evita que ingeniería se convierta en cuello de botella.
Empieza con un “flow builder” simple que permita a personal autorizado crear y editar flujos de onboarding y sus pasos.
Cada paso debería ser editable con:
Añade un modo de vista previa que renderice el paso tal como lo vería un usuario final. Esto detecta copy confuso, campos faltantes y branching roto antes de que llegue a usuarios reales.
Evita editar un flujo en vivo en su lugar. En su lugar, publica versiones:
Los despliegues deberían poder configurarse por versión:
Esto reduce riesgo y te da comparaciones limpias al medir finalización y abandono.
Los equipos de soporte necesitan herramientas para desbloquear usuarios sin editar la base de datos manualmente:
Cada acción admin debe registrarse: quién cambió qué, cuándo y los valores antes/después. Restringe acceso con roles (solo lectura, editor, publicador, override de soporte) para que acciones sensibles—como resetear progreso—estén controladas y trazables.
Antes de lanzar un flujo de onboarding multi-pasos, asume dos cosas: los usuarios tomarán caminos inesperados y algo fallará a mitad (red, validación, permisos). Una buena checklist de lanzamiento prueba que el flujo es correcto, protege datos de usuarios y te da señales tempranas cuando la realidad se aleja del plan.
Empieza con tests unitarios para la lógica del workflow (estados y transiciones). Estos tests deberían verificar que cada paso:
Luego añade tests de integración que ejerciten tu API: guardar payloads de pasos, reanudar progreso y rechazar transiciones inválidas. Los tests de integración son donde atrapas issues “funciona localmente” como índices faltantes, bugs de serialización o desajustes de versión entre frontend y backend.
Los E2E deben cubrir al menos:
Mantén los escenarios E2E pequeños pero significativos—concéntrate en los pocos caminos que representan a la mayoría de usuarios y el mayor impacto en ingresos/activación.
Aplica el principio de menor privilegio: los admins de onboarding no deberían tener automáticamente acceso total a registros de usuarios, y las cuentas de servicio solo deberían tocar las tablas y endpoints que necesitan.
Encripta donde importa (tokens, identificadores sensibles, campos regulados) y trata los logs como riesgo de fuga de datos. Evita loggear payloads de formularios completos; loggea IDs de pasos, códigos de error y tiempos. Si debes loggear fragmentos de payload para debugging, redacta campos consistentemente.
Instrumenta el onboarding como un funnel de producto y como una API.
Rastrea errores por paso, latencia de guardado (p95/p99) y fallos de reanudación. Configura alertas para caídas súbitas en la tasa de finalización, picos de fallos de validación en un paso concreto o elevación de errores API tras un release. Esto te permite arreglar el paso roto antes de que se acumulen tickets de soporte.
Si implementas un sistema de onboarding por pasos desde cero, la mayor parte del tiempo se va en los mismos bloques descritos arriba: enrutamiento de pasos, persistencia, validaciones, lógica de estado/progreso y una interfaz admin para versionado y rollouts. Koder.ai puede ayudarte a prototipar y entregar estas piezas más rápido generando apps full‑stack a partir de una especificación conversacional—típicamente con frontend en React, backend en Go y un modelo de datos en PostgreSQL que mapea claramente a flows, steps y step_responses.
Como Koder.ai soporta exportación de código, hosting/despliegue y snapshots con rollback, también es útil cuando quieres iterar versiones de onboarding de forma segura (y recuperar rápidamente si un rollout perjudica la finalización).
Usa un flujo multi-pasos cuando la configuración es más que un único formulario—especialmente si incluye prerrequisitos (p. ej., creación de workspace), verificación (email/teléfono/KYC), configuración (facturación/integraciones) o ramificaciones por rol/plan/región.
Si los usuarios necesitan contexto para responder correctamente, dividirlo en pasos reduce errores y abandonos.
Define el éxito como los usuarios alcanzando valor, no como terminar pantallas. Métricas comunes:
También mide éxito de reanudación (que los usuarios puedan dejar y continuar sin perder progreso).
Empieza por listar los tipos de usuario (p. ej., nuevo self‑serve, usuario invitado, cuenta creada por admin) y define para cada uno:
Luego codifica reglas de salto (skip rules) para que cada persona aterrice en el siguiente paso correcto, no siempre en el paso uno.
Escribe “hecho” como criterios verificables por el backend, no como la mera finalización de pantallas. Por ejemplo:
Así el servidor puede decidir de forma fiable si el onboarding está completo—even si la UI cambia con el tiempo.
Empieza con una columna vertebral básicamente lineal y añade ramas condicionales solo cuando la experiencia realmente difiera (rol, plan, región, caso de uso).
Documenta las ramas como reglas if/then explícitas (p. ej., “If region = EU → show VAT step”) y mantén los nombres de los pasos orientados a la acción (“Confirm email”, “Invite teammates”).
Prefiere una URL por paso (p. ej., /onboarding/profile) cuando el flujo tiene más de un par de pantallas. Soporta seguridad al actualizar, deep linking (desde emails) y navegación con atrás/adelante del navegador.
Usa una sola página con estado interno solo para flujos muy cortos—y solo si tienes persistencia sólida para sobrevivir refresh/crashes.
Trata al servidor como fuente de verdad:
Esto permite seguridad en refresh, continuación entre dispositivos y estabilidad cuando los flujos se actualizan.
Un modelo práctico mínimo es:
Versiona las definiciones de flujo para que los usuarios en curso no se rompan al añadir o reordenar pasos. El progreso debe referenciar un específico.
Trata el onboarding como una máquina de estados con transiciones explícitas (p. ej., start_step, save_draft, submit_step, go_back).
Un paso se considera “completado” solo cuando:
Una base sólida de API incluye:
GET /api/onboarding (paso actual + progreso + borradores)PUT /api/onboarding/steps/{stepKey} con mode: draft|submitPOST /api/onboarding/complete (el servidor verifica todos los requisitos)Añade (p. ej., ) para proteger contra reintentos/doble clic, y devuelve errores estructurados por campo (usa 403/409/422 con significado) para que la UI reaccione correctamente.
flow_version_idCuando cambian respuestas anteriores, reevalúa dependencias y marca pasos posteriores como needs_review o regrésalos a in_progress.
Idempotency-Key