26 jul 2025·8 min
Cómo construir una aplicación web para rastrear excepciones de procesos de negocio
Aprende los pasos para diseñar, construir y lanzar una aplicación web que registre, enrute y resuelva excepciones de procesos de negocio con flujos claros e informes.
Qué son las excepciones de procesos de negocio (y por qué hay que registrarlas)
Una excepción de proceso de negocio es cualquier cosa que rompe la “ruta feliz” de un flujo de trabajo rutinario: un evento que necesita atención humana porque las reglas estándar no lo contemplaron o porque algo falló.
Piensa en las excepciones como el equivalente operativo de los “casos límite”, pero en el trabajo diario de la empresa.
Ejemplos que se entienden fácilmente
Las excepciones aparecen en casi todos los departamentos:
- Desajuste en la factura: el total de la factura no coincide con la orden de compra, las cantidades difieren o falta una línea.
- Aprobación faltante: un contrato se ejecuta sin la firma adecuada o un gasto se presenta por encima del límite sin aprobación.
- Envío tardío: la entrega no llegó en la fecha prometida, llegó un envío parcial o se envió el SKU equivocado.
No son “raras”. Son comunes, y generan retrasos, rehacer trabajo y frustración cuando no hay una forma clara de capturarlas y resolverlas.
Por qué fallan las hojas de cálculo y los hilos de correo
Muchos equipos empiezan con una hoja de cálculo compartida y correos o mensajes de chat. Funciona, hasta que deja de hacerlo.
Una fila de hoja de cálculo puede decirte qué pasó, pero con frecuencia pierde el resto:
- Contexto perdido: detalles clave están en bandejas de entrada (capturas, respuestas de proveedores, aprobaciones), no adjuntos al registro.
- Sin propiedad clara: la gente asume que otro lo está manejando, especialmente cuando las excepciones cruzan equipos.
- Historial débil: es difícil ver quién cambió qué y por qué, lo cual importa cuando surgen consultas.
Con el tiempo, la hoja se convierte en un conjunto mixto de actualizaciones parciales, entradas duplicadas y campos de “estado” en los que nadie confía.
Qué ganas al rastrear excepciones correctamente
Una aplicación simple de seguimiento de excepciones (un registro de incidentes/problemas adaptado a tu proceso) crea valor operativo inmediato:
- Resolución más rápida: la persona correcta recibe la notificación, la información de soporte permanece con la excepción y el estado es visible.
- Menos repetición: emergen patrones (mismo proveedor, mismo paso, misma brecha de aprobación), así puedes corregir causas raíz.
- Responsabilidad clara: cada excepción tiene un responsable, fechas límite (SLA/objetivos) y un resultado documentado.
Pon expectativas: empieza simple e itera
No necesitas un flujo perfecto desde el primer día. Comienza capturando lo básico: qué pasó, quién lo tiene, estado actual y siguiente paso; luego evoluciona campos, enrutamiento e informes a medida que aprendes qué excepciones se repiten y qué datos realmente impulsan decisiones.
Define usuarios, alcance y métricas de éxito
Antes de dibujar pantallas o escoger herramientas, define con claridad a quién sirve la app, qué cubrirá en la versión 1 y cómo sabrás que funciona. Esto evita que una “app de seguimiento de excepciones” se convierta en un sistema de tickets genérico.
Identifica los roles principales
La mayoría de los flujos de excepción necesitan unos pocos actores claros:
- Solicitante: registra la excepción y aporta contexto (qué pasó, cuándo, impacto).
- Aprobador: decide si la excepción es aceptable y en qué condiciones.
- Responsable de resolución: soluciona el problema, aplica el workaround o actualiza los datos.
- Propietario del proceso: responsable del proceso subyacente y de las acciones de prevención.
- Auditor/visualizador: acceso de solo lectura para supervisión y comprobaciones de cumplimiento.
Para cada rol, anota 2–3 permisos clave (crear, aprobar, reasignar, cerrar, exportar) y las decisiones de las que son responsables.
Aclara los objetivos
Mantén los objetivos prácticos y observables. Objetivos comunes:
- Capturar excepciones de forma consistente (los mismos datos mínimos cada vez).
- Asignar propiedad clara para que nada quede sin atención.
- Documentar decisiones (por qué se aprobó/denegó una excepción, por quién).
- Reducir repeticiones rastreando causa raíz y acciones de prevención.
Decide el alcance para la v1
Elige 1–2 flujos de trabajo de alto volumen donde las excepciones sean frecuentes y el costo del retraso sea real (por ejemplo, desajustes de facturas, retenciones de pedidos, incorporación con documentos faltantes). Evita empezar con “todos los procesos de negocio”. Un alcance estrecho te permite estandarizar categorías, estados y reglas de aprobación más rápido.
Escribe 3–5 métricas de éxito
Define métricas que puedas medir desde el día uno:
- Tiempo hasta resolución (mediana y % dentro del SLA)
- Tasa de reapertura (calidad del cierre)
- Volumen de excepciones por tipo (principales impulsores)
- Tiempo de ciclo de aprobación (solicitud → decisión)
- Excepciones repetidas vinculadas a la misma causa raíz
Estas métricas serán tu línea base para iterar y justificar automatizaciones futuras.
Mapea el ciclo de vida de la excepción y los estados
Un ciclo de vida claro mantiene a todos alineados sobre dónde está una excepción, quién la posee y qué debe pasar después. Mantén pocos estados, sin ambigüedad y ligados a acciones reales.
Un ciclo por defecto práctico
Creado → Triaje → Revisión → Decisión → Resolución → Cerrado
- Creado: se registra una excepción con los detalles mínimos requeridos.
- Triaje: alguien la valida, asigna propietario y define urgencia.
- Revisión: el equipo adecuado recopila evidencia y evalúa opciones.
- Decisión: aprobar/denegar la excepción (o pedir cambios) con una razón registrada.
- Resolución: se ejecuta y verifica la acción correctiva.
- Cerrado: el registro se finaliza para informes y auditoría.
Define “hecho” con criterios de entrada/salida
Escribe lo que debe ser verdadero para entrar y salir de cada etapa:
- Creado (salida): campos requeridos completos; categoría seleccionada; solicitante identificado.
- Triaje (salida): propietario asignado; impacto + fecha objetivo establecido; duplicados comprobados.
- Revisión (salida): evidencia adjunta; partes consultadas; recomendación documentada.
- Decisión (salida): decisión registrada; aprobador identificado; condiciones (si las hay) capturadas.
- Resolución (salida): acciones completadas; resultado validado; SLA cumplido o motivo de incumplimiento registrado.
- Cerrado (salida): notas finales añadidas; sin tareas abiertas; historial de auditoría completo.
Reglas de escalado que evitan estancamientos
Agrega escalados automáticos cuando una excepción esté vencida (pasó la fecha/SLA), bloqueada (pendiente de una dependencia externa demasiado tiempo) o sea de alto impacto (umbral de severidad). El escalado puede significar: notificar a un gerente, reenviar a un nivel de aprobación superior o aumentar la prioridad.
Reapertura y manejo de duplicados
- Reabrir cuando la misma excepción reaparece (por ejemplo, la corrección falló). Requiere una razón y se envía de vuelta a Triaje o Revisión.
- Duplicado cuando dos registros describen el mismo problema subyacente. Marca uno como “primario”, vincula los duplicados y cierra los duplicados con un resultado “Fusionado” para que los informes sean precisos.
Diseña el modelo de datos y los campos requeridos
Una aplicación de seguimiento de excepciones buena se sostiene por su modelo de datos. Si la estructura es demasiado laxa, los informes serán poco fiables. Si está demasiado estructurada, los usuarios no introducirán datos consistentemente. Apunta a un conjunto pequeño de campos obligatorios y un conjunto mayor de campos opcionales bien definidos.
Entidades principales a incluir
Comienza con algunos registros centrales que cubran la mayoría de los escenarios:
- Excepción: el registro principal (qué pasó, dónde y qué hay que resolver).
- Comentario: discusión, aclaraciones y actualizaciones de progreso.
- Adjunto: capturas, PDFs, correos.
- Tarea: acciones discretas asignadas a propietarios.
- Decisión: aprobaciones/denegaciones, excepciones de política o cierres.
- Categoría: lista controlada que mantiene limpios los informes.
- Usuario: reporteros, asignados, aprobadores y visualizadores.
Campos obligatorios (mantenerlos pocos)
Haz obligatorios los siguientes en cada Excepción:
- Título y descripción (en lenguaje claro, qué pasó y por qué importa)
- Categoría
- Impacto (por ejemplo, financiero, cliente, cumplimiento, operativo)
- Área de proceso (por ejemplo, facturación, cumplimiento, devoluciones)
- Fecha límite (o fecha objetivo de resolución)
Valores estructurados que debes estandarizar
Usa valores controlados en lugar de texto libre para:
- Estado (Creado, Triaje, Revisión, Decisión, Resolución, Cerrado)
- Prioridad (Baja/Media/Alta/Urgente)
- Causa raíz (Error humano, defecto del sistema, datos faltantes, problema con proveedor, política poco clara)
- Tipo de resolución (Datos corregidos, reembolso emitido, workaround, proceso actualizado, capacitación, sin acción)
Vínculos y trazabilidad
Planifica campos para conectar excepciones con objetos empresariales reales:
- Referencias a registros afectados (ID de pedido, ID de factura, ID de cliente)
- IDs de sistemas externos (ticket ERP, caso CRM)
- Excepciones relacionadas (duplicados, patrones recurrentes, padre/hijo)
Estos vínculos facilitan detectar problemas repetidos y construir informes precisos luego.
Planifica la experiencia de usuario y las pantallas principales
Una buena app de seguimiento de excepciones se siente como una bandeja compartida: todos pueden ver rápidamente qué necesita atención, qué está bloqueado y qué está vencido. Empieza diseñando un conjunto pequeño de pantallas que cubran el 90 % del trabajo diario y añade funciones potentes (informes avanzados, integraciones) después.
Pantallas principales para diseñar primero
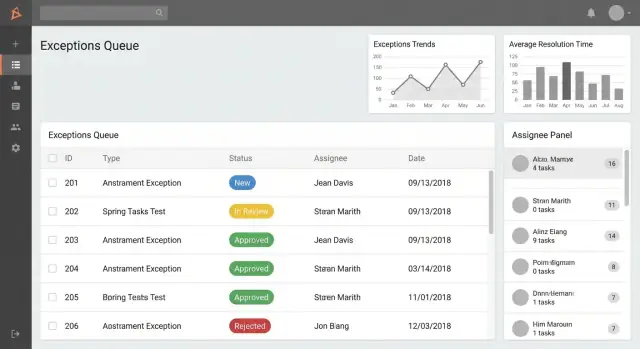
1) Lista/cola de excepciones (pantalla inicial)
Aquí es donde viven los usuarios. Hazla rápida, fácil de escanear y orientada a la acción.
Crea colas basadas en roles como:
- Mis excepciones (creadas por mí o asignadas a mí)
- Necesita mi aprobación (pendientes de decisión)
- Vencidas (fuera de SLA o fecha objetivo)
Agrega búsqueda y filtros que coincidan con cómo la gente habla del trabajo:
- Estado, categoría, área de proceso
- Rango de fechas (creado, vencimiento, cerrado)
- Asignado / equipo
2) Formulario de creación de excepción
Deja el primer paso ligero: algunos campos obligatorios, con detalles opcionales bajo “Más”. Considera guardar borradores y permitir valores “desconocido” (por ejemplo, “asignado TBD”) para evitar atajos.
3) Página de detalle de excepción
Esto debe responder “¿Qué pasó? ¿Qué sigue? ¿Quién lo tiene?”. Incluye:
- Resumen, estado, propietario/asignado, fecha límite/SLA
- Acciones primarias claras (Asignar, Solicitar aprobación, Cerrar)
- Un panel lateral para metadatos clave
Colaboración básica (sin convertirla en chat)
Incluye:
- Comentarios con @menciones para llamar a las personas correctas
- Adjuntos para evidencia (capturas, PDFs)
- Una línea de actividad que registre cambios (actualizaciones de estado, reasignaciones, aprobaciones) para que los usuarios no tengan que preguntar “¿quién cambió esto?”
Configuración de administrador (mínima pero necesaria)
Proporciona un área de administración pequeña para gestionar categorías, áreas de proceso, objetivos SLA y reglas de notificación—para que los equipos de operaciones puedan evolucionar la app sin desplegar código.
Elige un enfoque técnico y arquitectura
Exporta tu código fuente
Exporta código React, Go y PostgreSQL cuando necesites mayor personalización o un nuevo host.
Aquí equilibras velocidad, flexibilidad y mantenibilidad a largo plazo. La “respuesta correcta” depende de cuán complejo sea tu ciclo de excepción, cuántos equipos usarán la herramienta y cuán estrictos sean los requisitos de auditoría.
Tres enfoques prácticos de construcción
1) Desarrollo a medida (control total). Construyes UI, API, base de datos e integraciones desde cero. Funciona bien cuando necesitas flujos personalizados (enrutamiento, SLAs, historial de auditoría, integraciones ERP/tickets) y esperas evolucionar el proceso. El tradeoff es mayor costo inicial y necesidad de soporte de ingeniería continuo.
2) Low-code (más rápido para lanzar). Constructores internos producen formularios, tablas y aprobaciones básicas rápidamente. Ideal para un piloto o despliegue en un solo departamento. El inconveniente: puedes encontrar límites en permisos complejos, informes personalizados, rendimiento a escala o portabilidad de datos.
3) Vibe-coding / construcción asistida por agentes (iteración rápida con código real). Si quieres velocidad sin renunciar a una base de código mantenible, plataformas como Koder.ai pueden ayudarte a crear una aplicación web a partir de una especificación conversacional y luego exportar el código fuente cuando necesites control total. Los equipos suelen usarla para generar la UI en React y un backend en Go + PostgreSQL rápidamente, iterar en “modo planificación” y apoyarse en snapshots/rollback mientras el flujo se estabiliza.
Arquitectura simple y escalable
Apunta a una clara separación de responsabilidades:
- UI web para que los usuarios envíen, revisen y resuelvan excepciones
- API que aplique validación, permisos y reglas de flujo
- Base de datos que almacene excepciones, comentarios, metadatos de adjuntos, decisiones, tareas y eventos de auditoría
- Trabajos en segundo plano para notificaciones, escalados, temporizadores de SLA e informes programados
Esta estructura se mantiene comprensible a medida que la app crece y facilita añadir integraciones más adelante.
Hosting y entornos
Planifica al menos dev → staging → prod. Staging debe replicar prod (especialmente auth y correo) para probar enrutamientos, SLAs e informes con seguridad antes del lanzamiento.
Si quieres reducir la carga operativa al inicio, considera una plataforma que incluya despliegue y hosting (Koder.ai, por ejemplo, soporta despliegue/hosting, dominios personalizados y regiones globales en AWS)—luego revisa una configuración propia cuando el flujo esté probado.
Costes y compromisos de complejidad
Low-code reduce el tiempo hasta la primera versión, pero las necesidades de personalización y cumplimiento pueden aumentar costes después (workarounds, complementos, restricciones del proveedor). Los builds a medida cuestan más al inicio, pero pueden ser más económicos a largo plazo si el manejo de excepciones es central en la operación. Un camino intermedio—lanzar rápido, validar el flujo y mantener una ruta de migración clara (por ejemplo, exportación de código)—suele ofrecer la mejor relación coste/control.
Configura autenticación, roles y control de acceso
Los registros de excepción suelen incluir detalles sensibles (nombres de clientes, ajustes financieros, incumplimientos de política). Si el acceso es demasiado amplio, hay riesgo de problemas de privacidad y “ediciones en la sombra” que reducen la confianza en el sistema.
Inicio de sesión y sesiones seguras
Empieza con autenticación probada en lugar de construir tu propio sistema de contraseñas. Si la organización ya tiene un proveedor de identidad, usa SSO (SAML/OIDC) para que los usuarios inicien sesión con su cuenta laboral y heredes controles existentes como MFA y desactivación de cuentas.
Independientemente de SSO o inicio por correo, trata las sesiones como una característica de primera clase: sesiones de corta duración, cookies seguras, protección CSRF para apps de navegador y cierre automático tras inactividad en roles de alto riesgo. También registra eventos de autenticación (inicio, cierre, intentos fallidos) para investigar actividad inusual.
Roles y permisos (qué puede hacer cada persona)
Define roles en términos de negocio y asígnalos a acciones en la app. Un punto de partida típico:
- Reportero: crear excepciones, añadir notas/adjuntos, ver sus propios ítems
- Asignado/Resolutor: editar campos, proponer resolución, actualizar estado
- Aprobador/Gerente: aprobar o rechazar, pedir más info, cerrar ítems
- Admin: configurar el sistema (no procesamiento diario)
Sé explícito sobre quién puede eliminar. Muchos equipos desactivan eliminaciones permanentes y permiten solo archivado por administradores, preservando la historia.
Acceso a nivel de registro (quién puede ver qué excepciones)
Más allá de roles, añade reglas que limiten la visibilidad por departamento, equipo, ubicación o área de proceso. Patrones comunes:
- Los usuarios pueden ver ítems que crearon y los asignados a su equipo
- Los gerentes pueden ver todos los ítems dentro de su unidad organizativa
- Roles de cumplimiento/auditoría pueden ver todo, solo lectura
Esto evita el “explorar abierto” y a la vez permite colaboración.
Capacidades de administrador necesarias
Los administradores deben poder gestionar categorías y subcategorías, reglas SLA (fechas objetivo, umbrales de escalado), plantillas de notificación y asignaciones de roles. Mantén las acciones de admin auditables y exige confirmación elevada para cambios de alto impacto (como editar SLAs), ya que esas configuraciones afectan informes y responsabilidad.
Construye flujos, enrutamiento y notificaciones
Construye un rastreador de excepciones
Crea tu rastreador de excepciones en Koder.ai desde un chat sencillo y luego itera con seguridad.
Los flujos son lo que convierte un simple “registro” en una app en la que la gente confía. El objetivo es movimiento predecible: cada excepción debe tener un propietario claro, el siguiente paso y una fecha límite.
Reglas de enrutamiento: quién recibe qué y cuándo
Empieza con un pequeño conjunto de reglas fáciles de explicar. Puedes enrutar por:
- Categoría (por ejemplo, calidad de datos, desviación de política, fallo de sistema)
- Impacto (importe, número de clientes afectados, severidad)
- Área de proceso (AP/AR, incorporación, cumplimiento, fulfillment)
- Umbrales (por ejemplo, “Importe > $10.000” o “Alta severidad”)
Mantén las reglas deterministas: si coinciden varias reglas, define un orden de prioridad. Incluye además una ruta de seguridad (por ejemplo, la cola “Triaje de excepciones”) para que nada quede sin asignar.
Aprobaciones: simples, en varios pasos y anulaciones
Muchas excepciones requieren una aprobación antes de aceptarse, remediarse o cerrarse.
Diseña para dos patrones comunes:
- Aprobador único: una persona aprueba/rechaza (más rápido de implementar).
- Aprobación multi-paso: secuencia como Gerente → Cumplimiento → Finanzas.
Sé explícito sobre quién puede anular (y en qué condiciones). Si se permiten anulaciones, exige una razón y regístrala en el historial (por ejemplo, “Aprobado por anulación debido a riesgo de SLA”).
Notificaciones que no generen ruido
Añade notificaciones por correo y en la app en momentos que cambian propiedad o urgencia:
- Asignación y reasignación
- Nuevos comentarios o menciones
- Solicitud de aprobación / aprobado / rechazado
- Ítems vencidos y recordatorios de “próximo a vencerse”
Permite a los usuarios controlar notificaciones opcionales, pero mantiene activas por defecto las críticas (asignación, vencidos).
Haz visible el trabajo de resolución con tareas/listas de verificación
Las excepciones suelen fallar porque el trabajo ocurre “al margen”. Añade tareas o checklists ligeros vinculados a la excepción: cada tarea tiene propietario, fecha límite y estado. Esto hace el progreso rastreable, mejora los traspasos y da a los gerentes una vista en tiempo real de lo que bloquea el cierre.
Añade informes y paneles operativos
Los informes son donde una app deja de ser un “registro” y se convierte en una herramienta operativa. El objetivo es ayudar a los líderes a detectar patrones temprano y ayudar a los equipos a decidir qué trabajar sin abrir cada registro uno por uno.
Informes estándar para incluir
Comienza con un pequeño conjunto de informes que respondan preguntas comunes de forma fiable:
- Volumen en el tiempo (diario/semanal/mensual): ¿suben, bajan o son estacionales las excepciones?
- Por categoría/causa: ¿qué tipos de excepciones generan más fricción?
- Por equipo/propietario: ¿dónde se concentra la carga?
- Por estado: ¿cuánto hay en cada etapa (Creado, Triaje, Revisión, Decisión, Resolución, Cerrado)?
Mantén los gráficos simples (línea para tendencias, barras para desglose). El valor principal es la consistencia: los usuarios deben confiar en que el informe coincide con lo que verían en la lista de excepciones.
Rendimiento y seguimiento de SLA
Añade métricas operativas que reflejen la salud del servicio:
- Tiempo medio de resolución (y mediana, si es posible)
- Tasa de incumplimiento de SLA (porcentaje de excepciones fuera del objetivo)
- Tamaño del backlog (excepciones abiertas) y antigüedad (cuánto tiempo llevan abiertas)
Si almacenas timestamps como created_at, assigned_at y resolved_at, estas métricas son sencillas y explicables.
Drilling, exportaciones y resúmenes programados
Cada gráfico debe permitir drill-down: al hacer clic en una barra o segmento, el usuario va a la lista de excepciones filtrada (por ejemplo, “Category = Shipping, Status = Open”). Esto mantiene los paneles accionables.
Para compartir y analizar fuera de línea, ofrece exportación CSV tanto desde la lista como desde los informes clave. Si los stakeholders quieren visibilidad regular, añade resúmenes programados (email semanal o digest en la app) que destaquen cambios de tendencia, categorías principales y incumplimientos SLA, con enlaces a vistas filtradas (por ejemplo, /exceptions?status=open&category=shipping).
Garantiza auditabilidad y bases de cumplimiento
Si tu app influye en aprobaciones, pagos, resultados para clientes o reportes regulatorios, eventualmente tendrás que responder: “¿Quién hizo qué, cuándo y por qué?” Construir auditabilidad desde el día uno evita refactorizaciones dolorosas y da confianza para usar el registro como fuente de la verdad.
Captura un log de actividad inmutable
Crea un registro de actividad completo para cada excepción. Registra el actor (usuario o sistema), timestamp (con zona horaria), tipo de acción (creado, campo cambiado, transición de estado) y valores antes/después.
Mantén el log append-only. Las ediciones deben añadir nuevos eventos en lugar de sobrescribir la historia. Si hay que corregir un error, registra un evento de “corrección” con explicación.
Almacena decisiones con razones y evidencia
Las aprobaciones y rechazos deben ser eventos de primera clase, no solo un cambio de estado. Captura:
- Decisión (aprobado/denegado/devuelto)
- Código de motivo + nota en texto libre (obligatorio para decisiones clave)
- Adjuntos (capturas, PDFs, correos) y quién los subió
Esto agiliza revisiones y reduce el ida y vuelta cuando alguien pregunta por qué se aceptó una excepción.
Reglas de retención y eliminación (decídelas a propósito)
Define cuánto tiempo se retienen excepciones, adjuntos y logs. Para muchas organizaciones, un valor seguro por defecto es:
- Conservar registros y eventos de auditoría por un periodo fijo (por ejemplo, 3–7 años)
- Restringir la eliminación a un grupo pequeño de administradores, con justificación obligatoria
- Preferir “soft delete” (oculto de vistas normales) manteniendo el historial de auditoría intacto
Alinea la política con gobernanza interna y requisitos legales.
Diseña para revisiones y auditorías
Auditores y revisores de cumplimiento necesitan velocidad y claridad. Añade filtros específicos para trabajo de revisión: por rango de fechas, propietario/equipo, estado, códigos de motivo, incumplimiento de SLA y resultados de aprobación.
Proporciona resúmenes imprimibles e informes exportables que incluyan la historia inmutable (línea de tiempo de eventos, notas de decisión y lista de adjuntos). Una regla útil: si no puedes reconstruir la historia completa desde el registro y su log, el sistema no está listo para auditoría.
Prueba, piloto y despliegue
Crea colas basadas en roles
Crea colas y permisos para que cada rol vea solo lo que necesita.
Las pruebas y el despliegue son donde la app deja de ser “una buena idea” y se vuelve una herramienta confiable. Céntrate en los flujos que ocurren cada día y luego amplía.
Prueba los flujos clave de extremo a extremo
Crea un guion de pruebas simple (una hoja de cálculo sirve) que recorra el ciclo completo:
- Crear una excepción, adjuntar un archivo y confirmar que se aplican los campos requeridos.
- Asignarla a la persona/equipo correcto y verificar que pueda verla inmediatamente.
- Rutas de aprobar y rechazar: asegúrate de que cada decisión capture razón y timestamp.
- Cerrar la excepción y confirmar que pasa a solo lectura (o edición limitada) según lo previsto.
- Reabrirla y verificar que el historial/auditoría muestre claramente qué cambió.
Incluye variaciones “de la vida real”: cambiar prioridad, reasignaciones y elementos vencidos para verificar cálculos de SLA y tiempo de resolución.
Añade validaciones y manejo de errores que eviten datos malos
La mayoría de los problemas de informes vienen de entradas inconsistentes. Añade protecciones temprano:
- Campos obligatorios (por ejemplo, área de proceso, tipo de excepción, propietario, fecha límite).
- Límites de carga de archivos (tamaño/tipo) con mensajes claros.
- Detección de duplicados (por ejemplo, mismo cliente/pedido/fecha) con opción “vincular al existente”.
- Manejo seguro de casos extremos: asignado desconocido, fechas inválidas, usuarios eliminados.
También prueba caminos de error: interrupciones de red, sesiones expiradas y errores de permisos.
Ejecuta un piloto con un equipo primero
Elige un equipo con volumen suficiente para aprender rápido, pero lo bastante pequeño para ajustar con agilidad. Pilota 2–4 semanas y luego revisa:
- ¿Los campos capturan lo que la gente realmente necesita?
- ¿Los estados reflejan cómo se hace el trabajo?
- ¿Las notificaciones ayudan o son ruidosas?
Haz cambios semanalmente, pero congela el flujo la última semana para estabilizar.
Lanza con un kit de lanzamiento ligero
Mantén el despliegue simple:
- Una página “Cómo usamos la app” (estados, reglas de propiedad, SLAs).
- Una sesión de formación corta (15–30 minutos) y una grabación.
- Una checklist de lanzamiento: accesos/roles, enrutamiento por defecto, plantillas y contacto de soporte.
Después del lanzamiento, monitoriza adopción y salud del backlog diariamente la primera semana y luego semanalmente.
Mantén, mejora y escala con el tiempo
Lanzar la app es el inicio del trabajo real: mantener el registro de excepciones preciso, rápido y alineado con la operación.
Monitoriza uso y cuellos de botella
Trata el flujo de excepciones como una canalización operativa. Revisa dónde se estancan los ítems (por estado, equipo y propietario), qué categorías dominan el volumen y si los SLAs son realistas.
Un chequeo mensual simple suele ser suficiente:
- Tiempo de resolución mediano y percentil 90 por categoría
- Contadores de “antigüedad” (abierto > 7/30/60 días)
- Tasa de reapertura y bucles de “devuelto"
- Campos más frecuentemente vacíos (señal de fricción en la UX)
Usa estos hallazgos para ajustar definiciones de estado, campos obligatorios y reglas de enrutamiento—sin añadir complejidad constantemente.
Mantén un backlog de iteración
Crea un backlog ligero que capture solicitudes de operadores, aprobadores y cumplimiento. Elementos típicos:
- Nuevos campos (solo cuando realmente se necesiten para informes o decisiones)
- Automatizaciones (asignación automática por categoría, valores por defecto de fecha límite)
- Plantillas para tipos comunes de excepciones
- Pequeñas correcciones de UI que reduzcan la mala clasificación
Prioriza cambios que reduzcan tiempo de ciclo o prevengan excepciones recurrentes.
Integraciones: empieza seguro y profundiza luego
Las integraciones multiplican valor, pero también aumentan riesgo y mantenimiento. Empieza con enlaces de solo lectura:
- Almacenar IDs de registros externos (ERP/CRM/ticketing)
- Deep-link al sistema origen (p. ej., pedido, cliente, factura)
Una vez estable, pasa a escrituras selectivas (actualizaciones de estado, comentarios) y sincronización basada en eventos.
Asigna propiedad clara
Nombra responsables para las partes que más cambian:
- Taxonomía de categorías (y cuándo fusionar/retirar categorías)
- Definiciones SLA y reglas de escalado
- Reglas de flujo/enrutamiento y políticas de notificación
Cuando la propiedad es explícita, la app se mantiene confiable a medida que crece el volumen y los equipos se reorganizan.
Una nota sobre mantener alta la velocidad de desarrollo
El seguimiento de excepciones rara vez está “terminado”—evoluciona a medida que los equipos aprenden qué se debe prevenir, automatizar o escalar. Si esperas cambios frecuentes en el flujo, elige un enfoque que haga la iteración segura (feature flags, staging, rollback) y que mantenga el control del código y los datos. Plataformas como Koder.ai se usan a menudo para lanzar una versión inicial rápido (planes Free/Pro suelen bastar para pilotos) y luego escalar a Business/Enterprise cuando las necesidades de gobernanza, control de acceso y despliegue se vuelven más estrictas.