21 jul 2025·8 min
Construir una app web para el análisis de impacto de incidentes, paso a paso
Aprende a diseñar y construir una app web que calcula el impacto de incidentes usando dependencias de servicios, señales casi en tiempo real y paneles claros para los equipos.
Definir el impacto del incidente y las decisiones que debe impulsar
Antes de construir cálculos o paneles, decidan qué significa realmente “impacto” en su organización. Si saltan este paso, acabarán con una puntuación que parece científica pero no ayuda a nadie a actuar.
Qué cuenta como “impacto” (y qué no)
El impacto es la consecuencia medible de un incidente sobre algo que le importa al negocio. Dimensiones comunes incluyen:
- Usuarios: número de usuarios que no pueden iniciar sesión, picos en la tasa de errores en flujos clave, latencia degradada en una región.
- Ingresos: fallos en checkouts, renovaciones bloqueadas, disminución de impresiones publicitarias.
- Riesgo SLA/SLO: minutos de downtime contra un objetivo de disponibilidad, tasa de consumo del presupuesto de errores.
- Equipos internos: volumen de tickets de soporte, carga de on-call, despliegues bloqueados.
Elijan 2–4 dimensiones primarias y defíndanlas explícitamente. Por ejemplo: “Impacto = clientes de pago afectados + minutos de SLA en riesgo”, no “Impacto = cualquier cosa que se vea mal en los gráficos.”
Quién usa la app y qué necesita en los primeros 10 minutos
Diferentes roles toman distintas decisiones:
- Comandantes de incidentes necesitan un resumen rápido y defendible: qué está roto, quién está afectado y cómo evoluciona.
- Soporte necesita alcance orientado al cliente: qué cuentas, regiones o planes están impactados.
- Ingeniería necesita una hipótesis de blast-radius para guiar depuración y mitigación.
- Ejecutivos necesitan una declaración concisa de negocio: severidad, impacto en clientes y confianza en el ETA.
Diseñen las salidas de “impacto” para que cada audiencia responda su pregunta principal sin traducir métricas.
Tiempo real vs casi tiempo real: fijen expectativas temprano
Decidan qué latencia es aceptable. “Tiempo real” es costoso y a menudo innecesario; casi tiempo real (p. ej., 1–5 minutos) puede ser suficiente para la toma de decisiones.
Escriban esto como requisito de producto porque influye en la ingestión, el caché y la UI.
Decisiones que la app debe habilitar durante un incidente
Su MVP debe soportar directamente acciones como:
- Declarar severidad y nivel de escalado
- Disparar comunicaciones a clientes (página de estado, macros de soporte)
- Priorizar trabajo de mitigación (qué servicio/equipo primero)
- Decidir rollbacks, flags de features o cambios de tráfico
- Identificar qué clientes necesitan contacto proactivo
Si una métrica no cambia una decisión, probablemente no sea “impacto”: es solo telemetría.
Lista de requisitos: entradas, salidas y restricciones
Antes de diseñar pantallas o elegir una base de datos, anoten qué debe responder el “análisis de impacto” durante un incidente real. La meta no es precisión perfecta desde el día uno, sino resultados consistentes y explicables en los que los respondedores puedan confiar.
Entradas requeridas (el mínimo que necesitan)
Comiencen con los datos que deben ingerir o referenciar para calcular impacto:
- Incidentes: ID, tiempos de inicio/fin, estado, equipo propietario, resumen, enlaces al canal/ticket del incidente.
- Servicios: lista canónica de servicios (nombre, responsable, nivel/criticidad, enlace al runbook).
- Dependencias: qué servicios dependen de cuáles otros (incluso si la primera versión es tosca).
- Señales de telemetría: alertas, consumo de SLO, tasa de errores/latencia, eventos de despliegue: cualquier cosa que indique degradación.
- Cuentas de clientes: IDs de cuenta, plan/SLA, región, contactos clave, además de cómo las cuentas se mapean a servicios (directamente o vía cargas de trabajo).
Opcional al lanzamiento (planéenlo, no lo exijan)
La mayoría de equipos no tienen un mapeo perfecto de dependencias o clientes el primer día. Decidan qué permitirán que las personas ingresen manualmente para que la app siga siendo útil:
- Selección manual de servicios/clientes afectados cuando faltan datos
- Hora de inicio estimada o alcance cuando la telemetría llega con retraso
- Overrides con razones (p. ej., “alerta falso positivo”, “impacto solo interno”)
Diseñen estos como campos explícitos (no notas ad-hoc) para que sean consultables después.
Salidas clave (lo que la app debe producir)
Su primera versión debe generar de forma fiable:
- Servicios afectados y un “por qué” claro (señales + dependencias)
- Lista de clientes con conteos por plan/región y una vista de “cuentas principales”
- Puntuación de severidad/impacto que pueda explicarse en lenguaje llano
- Línea temporal de cuándo probablemente comenzó, alcanzó el pico y se recuperó el impacto
- Opcional pero valioso: una estimación de coste (créditos SLA, carga de soporte, riesgo de ingresos) con rangos de confianza
Restricciones no funcionales (lo que la hace confiable)
El análisis de impacto es una herramienta de decisión, así que las restricciones importan:
- Latencia: los paneles deben cargarse en segundos durante un incidente
- Disponibilidad: tratenla como una herramienta interna crítica; definan un objetivo de disponibilidad
- Auditabilidad: registren quién cambió un override, cuándo y cuál era el valor previo
- Control de acceso: restrinjan datos sensibles de clientes; separen permisos de lectura y escritura
Escriban estos requisitos como declaraciones comprobables. Si no pueden verificarlos, no podrán confiar en la herramienta durante una caída.
Modelo de datos: incidentes, servicios, dependencias y clientes
Su modelo de datos es el contrato entre ingestión, cálculo y UI. Si lo hacen bien, podrán cambiar herramientas, refinar puntuaciones y seguir respondiendo las mismas preguntas: “¿Qué se rompió?”, “¿Quién está afectado?” y “¿Durante cuánto tiempo?”.
Entidades núcleo (manténganlas pequeñas y enlazables)
Como mínimo, modelen estos registros:
- Incidente: el contenedor narrativo (título, severidad, estado, propietario), más punteros a evidencia.
- Servicio: la unidad para mapear dependencias (API, base de datos, cola, proveedor externo).
- Dependencia: una arista dirigida servicio A → servicio B con metadatos (tipo, criticidad).
- Señal: una observación con sello temporal (alerta, consumo SLO, pico de errores, fallo de chequeo sintético).
- Cliente: una cuenta u organización que consume servicios.
- Suscripción/SLA: lo que un cliente tiene derecho a recibir (plan, objetivos SLA/SLO, reglas de reporte).
Mantengan IDs estables y consistentes entre fuentes. Si ya tienen un catálogo de servicios, trátenlo como fuente de verdad y mapeen identificadores externos a él.
Modelado temporal (el impacto es un problema de ventana temporal)
Almacenen múltiples timestamps en el incidente para soportar reportes y análisis:
- start_time / end_time: ventana de impacto real (puede refinarse después)
- detection_time: cuándo se supo por primera vez
- mitigation_time: cuándo las acciones empezaron a reducir el impacto
También guarden ventanas de tiempo calculadas para puntuación (p. ej., buckets de 5 minutos). Esto facilita la reproducción y comparaciones.
Relaciones que responden “¿quién está afectado?”
Modele dos grafos clave:
- Dependencias servicio→servicio (blast radius)
- Uso cliente→servicio (alcance afectado)
Un patrón simple es customer_service_usage(customer_id, service_id, weight, last_seen_at) para poder ordenar el impacto según “qué tanto depende el cliente”.
Versionado e historial (las dependencias cambian)
Las dependencias evolucionan y los cálculos de impacto deben reflejar lo que era verdad en el momento. Añadan fecha de vigencia a las aristas:
dependency(valid_from, valid_to)
Hagan lo mismo para suscripciones y snapshots de uso. Con versiones históricas, podrán volver a ejecutar incidentes pasados y producir reportes SLA consistentes.
Recopilar y normalizar datos desde sus herramientas
El análisis de impacto es tan bueno como las entradas que lo alimentan. La meta es simple: tirar señales de las herramientas que ya usan y convertirlas en un flujo de eventos consistente que la app pueda razonar.
Qué ingerir (y por qué)
Comiencen con una lista corta de fuentes que describan de forma fiable “algo cambió” durante un incidente:
- Alertas de monitoreo (PagerDuty, Opsgenie, CloudWatch alarms): indicadores rápidos de síntomas y severidad
- Logs y trazas (ELK, Datadog, backends OpenTelemetry): evidencia de alcance (qué endpoints, qué clientes)
- Actualizaciones de la página de estado (Statuspage, Cachet): narrativa oficial y timestamps orientados al cliente
- Herramientas de ticketing/incidentes (Jira, ServiceNow): ownership, timestamps y datos post-incidente
No intenten ingerir todo a la vez. Elijan fuentes que cubran detección, escalado y confirmación.
Métodos de ingestión para elegir
Diferentes herramientas soportan patrones distintos:
- Webhooks para actualizaciones casi en tiempo real (mejor para alertas y páginas de estado)
- Sondeo (polling) para APIs sin webhooks (usen backoff y límites de tasa)
- Importes por lotes para backfills históricos (útil para validación inicial)
- Entrada manual para correcciones de “última milla” (un analista puede arreglar una etiqueta faltante)
Un enfoque práctico: webhooks para señales críticas, más importes por lotes para cubrir huecos.
Normalizar a un esquema común
Normalicen cada item entrante a una sola forma de “evento”, incluso si la fuente lo llama alerta, incidente o anotación. Como mínimo, estandaricen:
- Timestamps: occurred_at, detected_at, resolved_at (cuando estén disponibles)
- Identificadores de servicio: mapeen etiquetas/nombres de origen a sus IDs canónicos
- Severidad/prioridad: conviertan niveles específicos de herramienta a su escala
- Fuente y payload crudo: conserven el JSON original para auditoría y depuración
Higiene de datos: duplicados, orden y campos faltantes
Esperen datos desordenados. Usen claves de idempotencia (source + external_id) para deduplicar, toleren eventos fuera de orden ordenando por occurred_at (no por tiempo de llegada) y apliquen valores por defecto seguros cuando falten campos (marcándolos para revisión).
Una pequeña cola de “servicio no emparejado” en la UI evita errores silenciosos y mantiene los resultados de impacto confiables.
Mapear dependencias de servicios para un blast radius preciso
Diseña para los primeros 10 minutos
Comienza con requisitos casi en tiempo real y crea las pantallas mínimas que necesitan tus respondedores.
Si su mapa de dependencias está equivocado, su blast radius también lo estará, incluso si las señales y la puntuación son perfectas. La meta es construir un grafo de dependencias confiable durante el incidente y después.
Comiencen con un catálogo de servicios (su “fuente de verdad”)
Antes de mapear aristas, definan los nodos. Creen una entrada en el catálogo para cada sistema que puedan referenciar en un incidente: APIs, workers, almacenes de datos, proveedores terceros y otros componentes compartidos críticos.
Cada servicio debe incluir al menos: equipo propietario, nivel/criticidad (p. ej., orientado al cliente vs interno), objetivos SLA/SLO y enlaces a runbooks y docs de on-call (por ejemplo, /runbooks/payments-timeouts).
Capturar dependencias: estáticas vs aprendidas
Usen dos fuentes complementarias:
- Dependencias estáticas (declaradas): lo que los equipos dicen que dependen (desde IaC, config, manifests, ADRs). Estable y fácil de auditar.
- Dependencias aprendidas (observadas): lo que los sistemas realmente llaman (trazas, telemetry de service mesh, logs del gateway, logs de auditoría de DB). Capturan “unknown unknowns”.
Traten estas como tipos de arista separados para que la gente entienda la confianza: “declarado por el equipo” vs “observado en los últimos 7 días”.
La direccionalidad y la criticidad importan
Las dependencias deben ser direccionales: Checkout → Payments no es lo mismo que Payments → Checkout. La dirección guía el razonamiento (“si Payments está degradado, ¿qué upstreams pueden fallar?”).
Modelemos también dependencias duras vs suaves:
- Dura: la falla bloquea funcionalidad crítica (servicio de auth para login).
- Suave: la degradación reduce calidad pero hay fallback (recomendaciones, enriquecimiento opcional).
Esta distinción evita sobrestimar impacto y ayuda a priorizar.
Hacer snapshots del grafo para reproducción y análisis post-incidente
La arquitectura cambia semanalmente. Si no almacenan snapshots, no podrán analizar con precisión un incidente de hace dos meses.
Conserven versiones del grafo de dependencias a lo largo del tiempo (diario, por deploy o al cambiar). Al calcular el blast radius, resuelvan el timestamp del incidente al snapshot más cercano para que “quién fue afectado” refleje la realidad en ese momento—no la arquitectura actual.
Cálculo de impacto: desde señales a puntuaciones y alcance afectado
Una vez que ingieren señales (alertas, consumo SLO, checks sintéticos, tickets de clientes), la app necesita una forma consistente de convertir entradas desordenadas en una declaración clara: qué está roto, qué tan grave es y quién está afectado.
Elijan un enfoque de puntuación (empiecen simple)
Pueden llegar a un MVP usable con cualquiera de estos patrones:
- Puntuación basada en reglas: “Si la tasa de errores en checkout \u003e 5% durante 10 minutos, impacto = Alto.” Fácil de explicar y depurar.
- Fórmula ponderada: Combinar métricas normalizadas en una sola puntuación (p. ej., 0–100). Útil cuando hay muchas señales y se quiere una curva suave.
- Mapeo por niveles: asignar sistemas a niveles de negocio (Nivel 0–3) y limitar o aumentar severidad según nivel. Mantiene los resultados alineados con prioridades de negocio.
Sea cual sea el enfoque, almacenen los valores intermedios (umbral alcanzado, ponderaciones, nivel) para que la gente entienda por qué ocurrió la puntuación.
Definir dimensiones de impacto
Eviten colapsar todo en un número demasiado pronto. Rasten unas pocas dimensiones por separado y luego deriven una severidad general:
- Disponibilidad: downtime, requests fallidos, endpoints inalcanzables
- Latencia: degradación de p95/p99 respecto a una línea base o SLO
- Errores: picos en la tasa de errores, jobs fallidos, timeouts
- Corrección de datos: registros faltantes/incorrectos, procesamiento con retraso
- Riesgo de seguridad: patrones de acceso sospechosos, indicadores de exposición de datos
Esto ayuda a comunicar con precisión (p. ej., “disponible pero lento” vs “resultados incorrectos”).
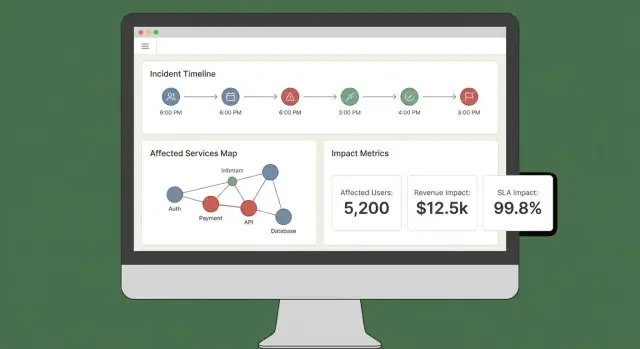
Calcular alcance afectado (clientes/usuarios)
El impacto no es solo salud de servicios: es quién lo sintió.
Usen mapeo de uso (tenant → servicio, plan de cliente → features, tráfico de usuarios → endpoint) y calculen clientes afectados dentro de una ventana temporal alineada al incidente (start time, mitigation time y cualquier período de backfill).
Sean explícitos sobre supuestos: logs muestreados, tráfico estimado o telemetría parcial.
Ajustes manuales—con responsabilidad
Los operadores necesitarán hacer overrides: alerta falso positiva, rollout parcial, subconjunto de tenants conocido.
Permitan ediciones manuales a severidad, dimensiones y clientes afectados, pero requieran:
- Quién cambió qué
- Cuándo
- Por qué (razón corta + enlace opcional a ticket/runbook)
Esta traza de auditoría protege la confianza en el panel y acelera las revisiones post-incidente.
UX y paneles: hacer el impacto entendible en minutos
Un buen panel de impacto responde tres preguntas rápido: ¿Qué está afectado? ¿Quién está afectado? ¿Qué tan seguros estamos? Si los usuarios deben abrir cinco pestañas para ensamblar eso, no confiarán en la salida ni actuarán.
Vistas principales para el MVP
Comiencen con un conjunto pequeño de vistas “siempre presentes” que mapeen a flujos reales de incidentes:
- Resumen del incidente: estado, hora de inicio, puntuación actual de impacto, servicios/clientes más afectados y la evidencia más reciente.
- Servicios afectados: lista ordenada mostrando severidad, región y la ruta de dependencia (para que ingenieros identifiquen dónde intervenir).
- Clientes afectados: conteos y cuentas nombradas por nivel/plan, más impacto estimado por usuario si lo miden.
- Línea temporal: un stream cronológico combinando detecciones, despliegues, alertas, mitigaciones y cambios de impacto.
- Acciones: pasos sugeridos, responsables y enlaces a playbooks o tickets.
Hacer visible el “por qué”
Las puntuaciones sin explicación parecen arbitrarias. Cada puntuación debe ser trazable a entradas y reglas:
- Mostrar qué señales contribuyeron (errores, latencia, health checks, volumen de soporte) y sus valores actuales.
- Mostrar reglas y umbrales usados (p. ej., “latencia p95 \u003e 2s por 10 min = degradado”).
- Añadir un indicador ligero de confianza (p. ej., “Alta confianza: confirmado por 3 fuentes”).
Un panel o cajón “Explicar impacto” puede hacer esto sin sobrecargar la vista principal.
Filtros y drilldowns que respondan preguntas reales
Faciliten cortar el impacto por servicio, región, nivel de cliente y rango temporal. Permitan que el usuario haga clic en cualquier punto de un gráfico o fila para profundizar en la evidencia cruda (los monitores, logs o eventos exactos que provocaron el cambio).
Compartir y exportar
Durante un incidente activo, la gente necesita actualizaciones portables. Incluyan:
- Enlaces compartibles a la vista del incidente (respetando permisos)
- Exportación CSV para listas de servicios/clientes
- Exportación PDF para actualizaciones de estado y resúmenes post-incidente
Si ya tienen una página de estado, enlácenla vía ruta relativa como /status para que los equipos de comunicaciones puedan cruzar referencias rápidamente.
Seguridad, permisos y registro de auditoría
Ponlo en marcha para el equipo
Despliega rápidamente tu aplicación interna de impacto para que los responsables la usen durante incidentes reales.
El análisis de impacto solo es útil si la gente confía en él—lo cual implica controlar quién puede ver qué y mantener un registro claro de cambios.
Roles y permisos (empiecen simples)
Definan un conjunto pequeño de roles que reflejen cómo se ejecutan los incidentes:
- Viewer: acceso solo lectura a resúmenes y alto nivel de impacto.
- Responder: puede añadir notas, confirmar servicios afectados y actualizar campos operativos.
- Comandante de incidentes: puede aprobar overrides, establecer estado orientado al cliente y cerrar incidentes.
- Admin: gestiona integraciones, asignaciones de roles y retención de datos.
Mantengan permisos alineados a acciones, no a títulos. Por ejemplo, “puede exportar reporte de impacto de clientes” es un permiso que pueden dar a comandantes y a un subconjunto de admins.
Proteger datos sensibles de clientes
El análisis de impacto a menudo toca identificadores de clientes, niveles contractuales y a veces detalles de contacto. Apliquen mínimos privilegios por defecto:
- Enmascaren campos sensibles (p. ej., mostrar los últimos 4 caracteres de un ID de cuenta) a menos que el usuario tenga acceso explícito.
- Separar “quién está impactado” de “qué está roto”. Muchos usuarios solo necesitan nivel de servicio, no listas de clientes.
- Exportaciones seguras: marquen PDFs/CSVs, incluyan el usuario que solicitó la exportación y restrinjan a roles aprobados. Prefieran enlaces de descarga firmados y de corta duración.
Registro de auditoría que responda “quién cambió qué?”
Registro de acciones clave con contexto suficiente para revisiones:
- Ediciones manuales a entradas de impacto (servicios/clientes afectados)
- Overrides de puntuación (valor antiguo, nuevo valor, razón)
- Acknowledgments y transiciones de estado
- Generación de reportes y exportaciones
Almacenen logs de auditoría append-only con timestamps e identidad del actor. Háganlos buscables por incidente para que sean útiles en la revisión post-incidente.
Planear necesidades de cumplimiento (sin prometer de más)
Documenten lo que pueden soportar ahora—periodo de retención, controles de acceso, cifrado y cobertura de auditoría—y lo que está en roadmap.
Una página corta de “Seguridad & Auditoría” en la app (p. ej., /security) ayuda a fijar expectativas y reduce preguntas ad-hoc durante incidentes críticos.
Flujos de trabajo y notificaciones durante un incidente activo
El análisis de impacto solo importa durante un incidente si impulsa la siguiente acción. La app debe comportarse como un “copiloto” para el canal del incidente: convertir señales entrantes en actualizaciones claras y empujar a la gente cuando el significado del impacto cambie.
Conectar a chat y canales de incidentes
Empiecen integrando con el lugar donde respondedores ya trabajan (a menudo Slack, Microsoft Teams o una herramienta de incidentes). La meta no es reemplazar el canal: es publicar actualizaciones con contexto y mantener un registro compartido.
Un patrón práctico es tratar el canal como entrada y salida:
- Entrada: los respondedores etiquetan la app (p. ej., “/impact summarize”, “/impact add affected customer Acme”) para corregir o enriquecer el alcance.
- Salida: la app publica actualizaciones concisas y consistentes (puntuación actual, servicios/clientes afectados, tendencia vs la última actualización).
Si prototipan rápido, consideren construir primero el flujo end-to-end (vista de incidente → resumir → notificar) antes de perfeccionar la puntuación. Plataformas como Koder.ai pueden ayudar a iterar un dashboard React y un backend Go/PostgreSQL mediante un flujo de trabajo guiado por chat, y luego exportar el código cuando el equipo esté de acuerdo con la UX.
Notificaciones basadas en umbrales (no ruido)
Eviten spam de notificaciones disparando solo cuando el impacto cruce umbrales explícitos. Triggers comunes:
- Alcance: el conteo de clientes afectados salta (p. ej., 10 → 100)
- Nivel: un servicio Nivel 1 se ve afectado
- Ingresos / riesgo SLA: proyección de incumplimiento SLA o implicación de cliente de alto valor
- Expansión del blast radius: nuevos servicios dependientes se suman al conjunto afectado
Cuando un umbral se cruza, envíen un mensaje que explique qué cambió, quién debe actuar y qué hacer a continuación.
Enlazar a runbooks y flujos de trabajo
Cada notificación debe incluir enlaces de “siguiente paso” para que los respondedores actúen rápido:
- Runbooks: /blog/incident-runbook-template
- Política de escalado: /pricing
- Página de ownership del servicio: /services/payments
Mantengan estos enlaces estables y relativos para que funcionen entre entornos.
Actualizaciones para stakeholders: internas y orientadas al cliente
Generen dos formatos de resumen a partir de los mismos datos:
- Actualización interna: detalle técnico, causa sospechada, progreso de mitigación, confianza en ETA.
- Actualización para clientes: lenguaje llano, impacto actual a usuarios, soluciones alternativas, hora de la próxima actualización.
Soporten resúmenes programados (p. ej., cada 15–30 minutos) y acciones de “generar actualización” on-demand, con un paso de aprobación antes de enviar externamente.
Validación: pruebas, reproducción y cheques de exactitud
Conecta tus señales
Diseña rutas de ingestión por webhooks y polling y normaliza los eventos en un único esquema.
El análisis de impacto solo es útil si la gente confía en él durante y después de un incidente. La validación debe probar dos cosas: (1) el sistema produce resultados estables y explicables, y (2) esos resultados coinciden con lo que la organización acuerda que ocurrió en la revisión post-incidente.
Estrategia de pruebas: reglas y pipelines
Comiencen con tests automatizados que cubran las dos áreas más propensas a fallos: lógica de puntuación e ingestión de datos.
- Tests unitarios para reglas de puntuación: traten cada regla como un contrato. Dadas señales específicas (tasa de error, latencia, checks sintéticos, volumen de tickets), el test debe afirmar la puntuación de impacto esperada y el alcance afectado. Incluyan pruebas de borde (justo por debajo/por encima de umbrales) para que el jitter no invierta resultados inesperadamente.
- Tests de integración para ingestión: validen el camino completo desde webhook/input de evento hasta registros normalizados y cálculo de impacto. Usen payloads grabados de sus herramientas de observabilidad e incidentes para detectar drift de esquemas temprano.
Mantengan los fixtures de test legibles: cuando alguien cambie una regla, debe entender por qué cambió una puntuación.
Reproducir incidentes pasados para validar salidas
Un modo de reproducción es una vía rápida hacia la confianza. Ejecuten incidentes históricos a través de la app y comparen lo que el sistema habría mostrado “en el momento” con lo que los respondedores concluyeron después.
Consejos prácticos:
- Reconstruyan líneas de tiempo usando timestamps de eventos (no tiempo de ingestión) para reflejar la realidad.
- Congelen grafos de dependencias según la fecha del incidente si el catálogo cambió.
- Conserven resultados de replay para comparar versiones después de ajustes en las reglas.
Manejar casos límite que rompen puntuaciones ingenuas
Los incidentes reales rara vez son cortes limpios. Su suite de validación debe incluir escenarios como:
- Outages parciales (algunos endpoints o segmentos de clientes fallando)
- Degradación de rendimiento (lento pero no fallando) donde el impacto de negocio aún puede ser alto
- Fallos multi-región donde el mismo servicio tiene salud distinta por región
Para cada caso, validen no solo la puntuación sino también la explicación: qué señales y qué dependencias/clientes motivaron el resultado.
Medir exactitud contra hallazgos post-incidente
Definan exactitud en términos operacionales y luego monitórenla.
Comparen el impacto calculado con los resultados de la revisión post-incidente: servicios afectados, duración, número de clientes, incumplimiento SLA y severidad. Registren discrepancias como issues de validación con una categoría (datos faltantes, dependencia incorrecta, umbral inadecuado, señal retrasada).
Con el tiempo, la meta no es la perfección: es menos sorpresas y más acuerdo rápido durante incidentes.
Despliegue, escalado e iteración después del MVP
Lanzar un MVP de análisis de impacto se trata principalmente de fiabilidad y bucles de feedback. Su primera elección de despliegue debe optimizar la velocidad de cambio, no la escala teórica futura.
Elijan un estilo de despliegue que puedan evolucionar
Empiecen con un monolito modular salvo que ya tengan un equipo de plataforma robusto y límites de servicio claros. Una unidad desplegable simplifica migraciones, depuración y pruebas end-to-end.
Divídanse solo cuando haya dolor real:
- la canalización de ingestión necesita escalado independiente
- varios equipos requieren desplegar independientemente
- los dominios de fallo son difíciles de razonar en una sola app
Un punto medio pragmático: una app + workers en background (colas) + un borde de ingestión separado si hace falta. Si quieren iterar rápido sin construir una plataforma grande, Koder.ai puede acelerar el MVP: su flujo de trabajo guiado por chat facilita construir una UI React, una API en Go y un modelo en PostgreSQL, con snapshots/rollback mientras iteran reglas y flujos.
Elegir almacenamiento según patrones de acceso
Usen almacenamiento relacional (Postgres/MySQL) para entidades núcleo: incidentes, servicios, clientes, ownership y snapshots calculados. Es fácil de consultar, auditar y evolucionar.
Para señales de alto volumen (métricas, eventos derivados de logs), añadan una store temporal o columnar cuando la retención cruda y los rollups se vuelvan caros en SQL.
Consideren una base de datos de grafos solo si las consultas de dependencia se convierten en cuello de botella o el modelo de dependencias es muy dinámico. Muchos equipos hacen mucho con tablas de adyacencia más caching.
Añadir observabilidad a la propia app
Su app de análisis de impacto entra a formar parte de la cadena de herramientas de incidentes, así que instrumentenla como software de producción:
- tasa de errores y endpoints lentos (especialmente “recalcular impacto”)
- profundidad/lag de colas de workers y tasas de retry
- throughput de ingestión y recuento de fallos por fuente
- frescura de datos (tiempo desde la última extracción/ingesta exitosa)
- duración de cálculos y tasa de aciertos de caché
Expongan una vista de “salud + frescura” en la UI para que los respondedores puedan confiar (o cuestionar) los números.
Planear iteraciones y refactors deliberadamente
Definan el alcance MVP con cuidado: un conjunto pequeño de herramientas para ingerir, una puntuación clara de impacto y un panel que responda “quién está afectado y cuánto”. Después iteren:
- Siguientes funciones: mayor precisión en dependencias, ponderación por cliente, reportes SLA, reproducción de incidentes pasados
- Disparadores de refactor: añadieron casos especiales semanalmente, la recalculación es demasiado lenta o el modelo de datos no puede expresar la realidad sin trucos
Traten el modelo como un producto: versionenlo, migrenlo de forma segura y documenten cambios para la revisión post-incidente.
Preguntas frecuentes
¿Qué es el “impacto del incidente” en este contexto?
El impacto es la consecuencia medible de un incidente sobre resultados críticos para el negocio.
Una definición práctica nombra 2–4 dimensiones primarias (por ejemplo, clientes de pago afectados + minutos de SLA en riesgo) y excluye explícitamente “cualquier cosa que se vea mal en los gráficos”. Esto mantiene la salida ligada a decisiones, no solo a telemetría.
¿Qué dimensiones de impacto deberíamos seguir primero?
Elija dimensiones que se vinculen a las acciones que los equipos toman en los primeros 10 minutos.
Dimensiones comunes aptas para un MVP:
- Usuarios/clientes afectados (conteos, niveles, regiones)
- Riesgo de ingresos (fallos en el checkout, bloqueos de renovaciones)
- Riesgo SLA/SLO (minutos de downtime, consumo del presupuesto de errores)
- Carga interna (volumen de tickets, despliegues bloqueados)
Limítelo a 2–4 para que la puntuación siga siendo explicable.
¿Quiénes son los usuarios principales de una app de análisis de impacto y qué necesitan?
Diseñe las salidas para que cada rol pueda responder su pregunta principal sin traducir métricas:
- Comandante de incidentes: resumen rápido (qué falla, quién está afectado, tendencia)
- Soporte: cuentas/regiones/planes afectados y alcance listo para comunicación
- Ingeniería: hipótesis de blast radius y evidencias para guiar mitigación
- Ejecutivos: severidad, impacto en el negocio y confianza en el ETA
¿Cómo deberíamos fijar expectativas entre datos en tiempo real y casi tiempo real?
“Tiempo real” es caro; muchos equipos se arreglan con casi tiempo real (1–5 minutos).
Escriba un objetivo de latencia como requisito porque afecta a:
- método de ingestión (webhooks vs sondeo)
- estrategia de caché
- cuán confiables pueden ser los números “actuales”
También muestre la frescura en la UI (por ejemplo, “datos con 2 minutos de antigüedad”).
¿Qué decisiones debería permitir tomar el panel MVP durante un incidente?
Empiece listando las decisiones que los respondedores deben tomar y haga que cada salida las habilite:
- declarar severidad y nivel de escalado
- activar comunicaciones a clientes (página de estado, macros de soporte)
- priorizar mitigación (qué servicio/equipo primero)
- decidir rollbacks, flags de funcionalidades o cambios de tráfico
- identificar clientes que requieren contacto proactivo
Si una métrica no cambia ninguna decisión, mantenla como telemetría, no como impacto.
¿Cuáles son los inputs mínimos requeridos para calcular el impacto del incidente?
Los insumos mínimos típicos incluyen:
- Incidentes: ID, inicio/fin, estado, responsable, enlaces
- Servicios: catálogo canónico (responsable, nivel, runbooks)
- Dependencias: aristas servicio→servicio (aunque sean toscas al principio)
¿Cómo manejamos datos faltantes o señales incorrectas al principio?
Permita campos manuales explícitos y consultables para que la app sea útil cuando faltan datos:
- seleccionar servicios/clientes afectados manualmente
- estimar hora de inicio o alcance cuando la telemetría llega tarde
- aplicar overrides con motivo (p. ej., falso positivo, impacto solo interno)
Requiera quién/cuándo/por qué para los cambios para que la confianza no decaiga con el tiempo.
¿Qué salidas debería generar la primera versión?
Un MVP fiable debería generar:
- Servicios afectados ordenados con un “por qué” claro (señales + camino de dependencias)
- Lista de clientes afectados con conteos por plan/región y "cuentas principales"
- Puntuación de severidad/impacto explicable en lenguaje simple
- Línea temporal de impacto (inicio, pico, recuperación)
Opcionalmente: estimaciones de coste (créditos SLA, riesgo de ingresos) con rangos de confianza.
¿Cómo recopilamos y normalizamos los datos de las herramientas existentes?
Normalice cada fuente en un único esquema de evento para mantener consistencia.
Como mínimo, estandarice:
- timestamps:
occurred_at,detected_at,
¿Cuál es un buen enfoque para la puntuación de impacto y el cálculo del alcance afectado?
Empiece simple y explicable:
- Basado en reglas: umbrales claros (fácil de depurar)
- Fórmula ponderada (0–100): puntuación suave con muchas señales
- Mapeo por niveles: alinee resultados con criticidad del negocio
Guarde los valores intermedios (umbrales, ponderaciones, nivel, confianza) para que los usuarios vean cambió la puntuación. Primero mantenga dimensiones separadas (disponibilidad/latencia/errores/datos/seguridad) antes de colapsar a un número.