21 may 2025·8 min
Crear una app web para informes SLA centralizados de clientes
Aprende a planear, construir y lanzar una app web multi-cliente que recopile datos SLA, normalice métricas y entregue dashboards, alertas e informes exportables.
Aprende a planear, construir y lanzar una app web multi-cliente que recopile datos SLA, normalice métricas y entregue dashboards, alertas e informes exportables.
El informe SLA centralizado existe porque la evidencia de SLA rara vez vive en un solo lugar. La disponibilidad puede estar en una herramienta de monitoreo, los incidentes en una página de estado, los tickets en un helpdesk y las notas de escalado en email o chat. Cuando cada cliente tiene una pila ligeramente distinta (o convenciones de nombres diferentes), el informe mensual se convierte en trabajo manual de hojas de cálculo—y las discusiones sobre “qué pasó realmente” se vuelven comunes.
Una buena app de informes SLA sirve a múltiples audiencias con objetivos distintos:
La app debe presentar la misma verdad subyacente en distintos niveles de detalle, según el rol.
Un panel SLA centralizado debe entregar:
En la práctica, cada número SLA debe ser rastreable hasta eventos en crudo (alertas, tickets, líneas de tiempo de incidentes) con timestamps y propiedad.
Antes de construir nada, define qué está en alcance y fuera de alcance. Por ejemplo:
Límites claros evitan debates posteriores y mantienen el reporte consistente entre clientes.
Como mínimo, el informe SLA centralizado debe soportar cinco flujos:
Diseña alrededor de estos flujos desde el día uno y el resto del sistema (modelo de datos, integraciones y UX) se mantendrá alineado con necesidades reales de reporte.
Antes de construir pantallas o pipelines, decide qué medirá tu app y cómo deben interpretarse esos números. El objetivo es consistencia: dos personas leyendo el mismo informe deben llegar a la misma conclusión.
Empieza con un conjunto pequeño que la mayoría de los clientes reconozca:
Sé explícito sobre qué mide cada métrica y qué no mide. Un panel de definiciones corto en la UI (y un enlace a /help/sla-definitions) evita malentendidos posteriores.
Las reglas son donde el informe SLA suele fallar. Documenta en oraciones que el cliente pueda validar, y luego tradúcelas a lógica.
Cubre lo esencial:
Elige periodos por defecto (mensual y trimestral son comunes) y si soportarás rangos personalizados. Aclara la zona horaria usada para los cortes.
Para incumplimientos, define:
Para cada métrica, lista las entradas requeridas (eventos de monitoreo, registros de incidentes, timestamps de tickets, ventanas de mantenimiento). Esto será el plano para integraciones y cheques de calidad de datos.
Antes de diseñar dashboards o KPIs, aclara dónde vive realmente la evidencia de SLA. La mayoría de equipos descubre que sus “datos SLA” están repartidos entre herramientas, son propiedad de distintos grupos y se registran con significados ligeramente distintos.
Empieza con una lista simple por cliente (y por servicio):
Para cada sistema, nota propietario, periodo de retención, límites de API, resolución temporal (segundos vs minutos) y si los datos son scoped por cliente o compartidos.
La mayoría de apps de informes SLA usan una combinación:
Una regla práctica: usa webhooks donde la frescura importa y API pulls donde la completitud importa.
Diferentes herramientas describen lo mismo de maneras distintas. Normaliza en un conjunto pequeño de eventos en los que tu app pueda confiar, como:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedIncluye campos consistentes: client_id, service_id, source_system, external_id, severity y timestamps.
Almacena todos los timestamps en UTC, y convierte en la visualización según la zona horaria preferida del cliente (especialmente para cortes mensuales).
Planifica también las brechas: algunos clientes no tendrán página de estado, algunos servicios no se monitorizarán 24/7 y algunas herramientas pueden perder eventos. Haz la “cobertura parcial” visible en los informes (p. ej., “datos de monitoreo no disponibles durante 3 horas”) para que los resultados SLA no engañen.
Si tu app informa SLAs para varios clientes, las decisiones de arquitectura determinan si puedes escalar sin fugas de datos entre clientes.
Empieza por nombrar las capas que necesitas soportar. Un “cliente” puede ser:
Anótalo temprano, porque afectan permisos, filtros y cómo almacenas configuración.
La mayoría de apps SLA elige uno de estos:
tenant_id. Es económico y más sencillo de operar, pero requiere disciplina estricta en consultas.Un compromiso común es DB compartida para la mayoría y DBs dedicadas para clientes “enterprise”.
El aislamiento debe mantenerse en:
tenant_id para que resultados no se escriban en el tenant equivocadoUsa guardrails como row-level security, scopes de consulta obligatorios y tests automáticos para límites de tenant.
Clientes distintos tendrán objetivos y definiciones diferentes. Planea para settings por tenant como:
Los usuarios internos suelen necesitar “impersonar” la vista de un cliente. Implementa un cambio deliberado (no un filtro libre), muestra el tenant activo prominentemente, registra los cambios para auditoría y evita enlaces que puedan saltarse las comprobaciones de tenant.
Una app centralizada de informes SLA vive o muere por su modelo de datos. Si modelas solo “% SLA por mes” te costará explicar resultados, manejar disputas o actualizar cálculos más tarde. Si modelas solo eventos crudos, el reporte será lento y caro. El objetivo es soportar ambos: evidencia trazable y rollups rápidos listos para clientes.
Mantén separación entre quién es reportado, qué se mide y cómo se calcula:
Diseña tablas (o colecciones) para:
La lógica SLA cambia: horarios laborales se actualizan, exclusiones se clarifican, reglas de redondeo evolucionan. Añade un calculation_version (y idealmente una referencia a un “rule set”) a cada resultado calculado. Así los informes antiguos pueden reproducirse exactamente después de mejoras.
Incluye campos de auditoría donde importan:
Los clientes a menudo preguntan “muéstrame por qué”. Planea un esquema para evidencia:
Esta estructura mantiene la app explicable, reproducible y rápida—sin perder la prueba subyacente.
Si tus entradas son desordenadas, tu panel SLA también lo será. Una canalización fiable convierte datos de incidentes y tickets de múltiples herramientas en resultados SLA consistentes y auditables—sin doble conteo, huecos o fallos silenciosos.
Trata ingestión, normalización y rollups como etapas separadas. Ejecútalas como jobs en background para que la UI siga siendo rápida y puedas reintentar con seguridad.
Esta separación también ayuda cuando la fuente de un cliente está caída: la ingestión puede fallar sin corromper cálculos existentes.
Las APIs externas fallan por timeouts. Los webhooks pueden entregarse dos veces. Tu canalización debe ser idempotente: procesar la misma entrada más de una vez no debe cambiar el resultado.
Enfoques comunes:
Entre clientes y herramientas, “P1”, “Critical” y “Urgent” pueden significar lo mismo—o no. Construye una capa de normalización que estandarice:
Almacena tanto el valor original como el normalizado para trazabilidad.
Añade reglas de validación (timestamps faltantes, duraciones negativas, transiciones de estado imposibles). No descartes datos malos silenciosamente—rígelos en una cola de cuarentena con motivo y un workflow de “arreglar o mapear”.
Para cada cliente y fuente, calcula “última sincronización exitosa”, “evento no procesado más antiguo” y “rollup actualizado hasta”. Muestra esto como un indicador simple de frescura de datos para que los clientes confíen en los números y tu equipo detecte problemas temprano.
Si los clientes usan tu portal para revisar SLA, la autenticación y permisos deben diseñarse con tanto cuidado como las matemáticas SLA. El objetivo es simple: cada usuario ve solo lo que debe—y puedas demostrarlo después.
Empieza con un conjunto pequeño y claro de roles y expande solo con razones fuertes:
Mantén principio de mínimo privilegio: nuevas cuentas deberían empezar en viewer salvo promoción explícita.
Para equipos internos, SSO reduce el sprawl de cuentas y el riesgo en offboarding. Soporta OIDC (Google Workspace/Azure AD/Okta) y, donde se requiera, SAML.
Para clientes, ofrece SSO como upgrade, pero permite email/contraseña con MFA para organizaciones pequeñas.
Aplica límites de tenant en cada capa:
Registra acceso a páginas sensibles y descargas: quién accedió a qué, cuándo y desde dónde. Esto ayuda en cumplimiento y confianza del cliente.
Construye un flow de onboarding donde admins o editores del cliente puedan invitar usuarios, fijar roles, exigir verificación de email y revocar acceso instantáneamente cuando alguien sale.
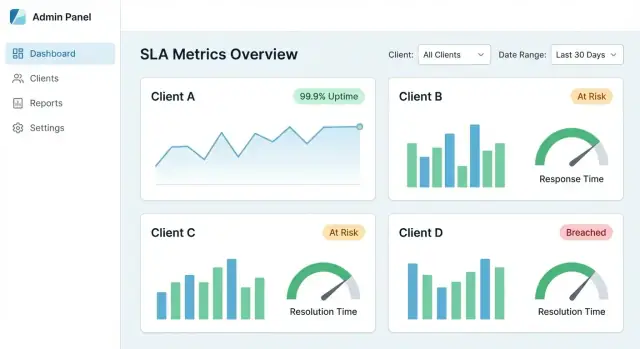
Un dashboard SLA centralizado triunfa cuando un cliente puede responder tres preguntas en menos de un minuto: ¿Estamos cumpliendo SLAs? ¿Qué cambió? ¿Qué causó las fallas? Tu UX debe guiar desde la vista general hasta la evidencia—sin obligar a aprender tu modelo de datos interno.
Empieza con un conjunto pequeño de tarjetas y gráficos que coincidan con conversaciones comunes SLA:
Haz cada tarjeta clicable para que sea una puerta a detalles, no un elemento muerto.
Los filtros deben ser consistentes en todas las páginas y “permanecer” mientras el usuario navega.
Defaults recomendados:
Muestra chips de filtros activos arriba para que el usuario siempre entienda qué está viendo.
Cada métrica debe tener un camino hacia “por qué”. Un flujo de drill-down sólido:
Si un número no se puede explicar con evidencia, será cuestionado—especialmente en QBRs.
Añade tooltips o un panel de “info” para cada KPI: cómo se calcula, exclusiones, zona horaria y frescura de datos. Incluye ejemplos como “Ventanas de mantenimiento excluidas” o “Disponibilidad medida en el API gateway”.
Haz vistas filtradas compartibles mediante URLs estables (p. ej., /reports/sla?client=acme&service=api&range=30d). Esto convierte tu dashboard SLA centralizado en un portal listo para clientes que soporta check-ins recurrentes y trails de auditoría.
Un dashboard SLA central es útil día a día, pero los clientes suelen querer algo que puedan reenviar internamente: un PDF para dirección, un CSV para analistas y un enlace que puedan marcar.
Soporta tres salidas desde los mismos resultados SLA subyacentes:
Para informes basados en enlace, haz los filtros explícitos (rango de fechas, servicio, severidad) para que el cliente entienda exactamente qué representan los números.
Añade programación para que cada cliente reciba informes automáticos—semanal, mensual y trimestral—enviados a una lista específica o un inbox compartido. Mantén las agendas scoped por tenant y auditables (quién la creó, última vez enviada, próxima ejecución).
Si necesitas un punto de partida simple, lanza con un “resumen mensual” más una descarga con un clic desde /reports.
Construye plantillas que lean como slides de QBR/MBR en forma escrita:
Los SLAs reales incluyen excepciones (mantenimientos, caídas de terceros). Permite que los usuarios adjunten notas de cumplimiento y marquen excepciones que requieran aprobación, con un trail de aprobaciones.
Los exports deben respetar aislamiento por tenant y permisos de rol. Un usuario solo debe exportar los clientes, servicios y periodos que puede ver—y el export debe coincidir exactamente con la vista del portal (sin columnas extras que filtren datos ocultos).
Las alertas son donde una app SLA pasa de “dashboard interesante” a herramienta operacional. El objetivo no es enviar más mensajes, sino ayudar a las personas correctas a reaccionar temprano, documentar lo ocurrido y mantener informados a los clientes.
Empieza con tres categorías:
Asocia cada alerta a una definición clara (métrica, ventana temporal, umbral, scope de cliente) para que los destinatarios confíen en ella.
Ofrece múltiples opciones de entrega para que los equipos encuentren a los clientes donde ya trabajan:
Para reporting multi-cliente, enruta notificaciones usando reglas por tenant (p. ej., “Incumplimientos Cliente A van al Canal A; incumplimientos internos van al on-call”). Evita enviar detalles específicos de clientes a canales compartidos.
La fatiga de alertas mata la adopción. Implementa:
Cada alerta debe soportar:
Esto crea un trail ligero que puedes reutilizar en resúmenes listos para clientes.
Proporciona un editor de reglas básico para umbrales y ruteo por cliente (sin exponer lógica de query compleja). Los guardrails ayudan: defaults, validación y vista previa (“esta regla habría disparado 3 veces el mes pasado”).
Una app SLA centralizada se vuelve crítica rápidamente porque los clientes la usan para juzgar calidad de servicio. Eso hace que velocidad, seguridad y evidencia (para auditorías) sean tan importantes como los gráficos.
Clientes grandes pueden generar millones de tickets, incidentes y eventos de monitoreo. Para mantener páginas responsivas:
Los eventos crudos son valiosos para investigaciones, pero mantener todo para siempre aumenta costo y riesgo.
Define reglas claras como:
Para cualquier portal de informes, asume contenido sensible: nombres de clientes, timestamps, notas de tickets y a veces PII.
Aunque no busques un estándar específico, buena evidencia operacional genera confianza.
Mantén:
Lanzar una app de informes SLA es menos un release de impacto y más probar precisión y escalar de forma repetible. Un plan de lanzamiento sólido reduce disputas haciendo que los resultados sean fáciles de verificar y reproducir.
Elige un cliente con un conjunto manejable de servicios y fuentes de datos. Ejecuta los cálculos SLA de tu app en paralelo con sus hojas de cálculo existentes, exports de tickets o informes de vendors.
Concéntrate en áreas de desajuste comunes:
Documenta las diferencias y decide si la app debe igualar el enfoque actual del cliente o reemplazarlo por un estándar más claro.
Crea una checklist repetible para que cada nuevo cliente tenga una experiencia predecible:
Una checklist también ayuda a estimar esfuerzo y a justificar discusiones en /pricing.
Los dashboards SLA solo son creíbles si están frescos y completos. Añade monitorización para:
Envía alertas internas primero; cuando esté estable, puedes introducir notas de estado visibles para clientes.
Recoge feedback sobre dónde sucede la confusión: definiciones, disputas (“¿por qué es esto un incumplimiento?”) y “qué cambió” desde el mes pasado. Prioriza pequeñas mejoras UX como tooltips, change logs y notas claras sobre exclusiones.
Si quieres lanzar un MVP interno rápido (modelo tenant, integraciones, dashboards, exports) sin semanas de boilerplate, un enfoque de "vibe-coding" puede ayudar. Por ejemplo, Koder.ai permite a equipos esbozar e iterar una app multi-tenant vía chat—y luego exportar el código fuente y desplegar. Eso encaja bien con productos SLA, donde la complejidad central son las reglas de dominio y la normalización de datos más que el scaffolding UI.
Puedes usar el modo de planning de Koder.ai para definir entidades (tenants, servicios, definiciones SLA, eventos, rollups) y luego generar una UI en React y un backend Go/Postgres base que extiendas con integraciones y lógica de cálculo específicas.
Mantén un doc vivo con próximos pasos: nuevas integraciones, formatos de export y trails de auditoría. Enlázalo con guías relacionadas en /blog para que clientes y compañeros puedan auto-servirse detalles.
El informe SLA centralizado debe crear una única fuente de verdad reuniendo disponibilidad, incidentes y líneas de tiempo de tickets en una vista única y trazable.
En la práctica, debería:
Empieza con un conjunto pequeño que la mayoría de los clientes reconozcan y amplía solo cuando puedas explicarlos y auditarlos.
Métricas iniciales comunes:
Para cada métrica, documenta qué mide, qué excluye y las fuentes de datos necesarias.
Escribe las reglas en lenguaje natural primero y luego conviértelas en lógica.
Normalmente necesitas definir:
Si dos personas no se ponen de acuerdo en la versión en frase, la versión en código será discutida después.
Almacena todas las marcas temporales en UTC y convierte para la visualización según la zona horaria de reporte del tenant.
También decide desde el inicio:
Sé explícito en la UI (por ejemplo: “Los cortes de periodo se calculan en America/New_York”).
Usa una mezcla de métodos según prioridad entre frescura y completitud:
Regla práctica: webhooks cuando la frescura importa, pulls cuando la completitud importa.
Define un pequeño conjunto canónico de eventos normalizados para que distintas herramientas remapen a los mismos conceptos.
Ejemplos:
incident_opened / incident_closedElige un modelo de multi-tenant y aplica aislamiento más allá de la UI.
Protecciones clave:
tenant_idAsume que las exportaciones y jobs en background son los lugares más probables para fugas si no diseñas el contexto del tenant correctamente.
Almacena tanto eventos en crudo como resultados derivados para ser rápido y explicable a la vez.
División práctica:
Añade un para poder reproducir informes antiguos exactamente tras cambios en las reglas.
Haz la canalización por etapas y idempotente:
Para fiabilidad:
Incluye tres categorías para que el sistema sea operativo y no solo un dashboard:
Reduce ruido con deduplicación, horas silenciosas y escalado; haz cada alerta accionable con reconocimiento y notas de resolución.
downtime_started / downtime_endedticket_created / first_response / resolvedIncluye campos consistentes como tenant_id, service_id, source_system, external_id, severity y timestamps en UTC.
calculation_version