Aclarar objetivos, usuarios y métricas de éxito
Antes de bocetar pantallas o elegir una base de datos, alinea lo que tu equipo entiende por una aplicación web de seguimiento de incidentes —y qué debe lograr la “gestión de postmortems”. Los equipos suelen usar las mismas palabras de forma diferente: para un grupo, un incidente es cualquier problema reportado por un cliente; para otro, solo es un outage Sev-1 con escalado de guardia.
Define “seguimiento de incidentes” para tu equipo
Escribe una definición corta que responda:
- ¿Qué califica como incidente (impacto al cliente, solo interno, eventos de seguridad, SLA incumplidos)?
- ¿Cuándo “empieza” y “termina” un incidente (primera alerta vs. primer reconocimiento humano; totalmente arreglado vs. en monitorización)?
- ¿Qué datos son obligatorios (servicio afectado, severidad, responsable, marcas de tiempo, actualizaciones de estado)?
Esta definición guía tu flujo de respuesta a incidentes y evita que la app sea demasiado rígida (nadie la usa) o demasiado laxa (datos inconsistentes).
Define “gestión de postmortems” (y por qué lo haces)
Decide qué es un postmortem en tu organización: un resumen ligero para cada incidente o un RCA completo solo para eventos de alta severidad. Haz explícito si el objetivo es aprendizaje, cumplimiento, reducir incidentes repetidos, o los tres.
Una regla útil: si esperas que un postmortem genere cambios, la herramienta debe soportar seguimiento de acciones, no solo almacenamiento de documentos.
Lista los problemas que estás resolviendo
La mayoría de equipos construyen este tipo de app para solucionar un pequeño conjunto de dolores recurrentes:
- Visibilidad: “¿Qué está pasando ahora?” “¿Con qué frecuencia falla este servicio?”
- Coordinación: propiedad clara, transferencias y una línea de tiempo compartida del incidente
- Aprendizaje: plantillas RCA consistentes y un proceso de revisión que realmente ocurra
- Seguimiento: las acciones no desaparecen después de la reunión
Mantén esta lista ajustada. Cada característica que añadas debería mapearse a al menos uno de estos problemas.
Elige métricas de éxito que coincidan con el comportamiento
Escoge unas pocas métricas que puedas medir automáticamente desde el modelo de datos de la app:
- Tiempo para detectar, reconocer, mitigar y resolver (tu línea de tiempo de incidentes debe capturar esto)
- Frecuencia por severidad, servicio y categoría de causa raíz
- Tasa de cierre de acciones y tiempo medio para cerrar
- Señales de calidad: porcentaje de incidentes con postmortem completado dentro de N días; porcentaje con propietario claro y actualizaciones de estado
Estas se convierten en tus métricas operativas y en la “definición de terminado” para el primer lanzamiento.
Aclara tus usuarios (y qué necesita cada uno)
La misma app sirve a diferentes roles en operaciones de guardia:
- Ingeniero de guardia: entrada rápida, campos mínimos, actualizaciones sencillas
- Incident commander: vista de coordinación, estado actual, responsables, puntos de control
- Managers: tendencias, problemas recurrentes, seguimiento de acciones
- Stakeholders: actualizaciones de estado claras sin ruido interno
Si diseñas para todos a la vez, crearás una UI abarrotada. En su lugar, elige un usuario primario para v1—y asegura que los demás puedan obtener lo que necesitan mediante vistas personalizadas, paneles y permisos más adelante.
Diseñar el flujo de incidentes y los roles
Un flujo claro previene dos fallos comunes: incidentes que se estancan porque nadie sabe “qué sigue”, e incidentes que parecen “resueltos” pero nunca producen aprendizaje. Empieza mapeando el ciclo de vida de extremo a extremo y luego asigna roles y permisos a cada paso.
Mapea el ciclo de vida del incidente
La mayoría de equipos sigue un arco simple: detectar → triage → mitigar → resolver → aprender. Tu app debería reflejar esto con un pequeño conjunto de pasos predecibles, no un menú interminable de opciones.
Define qué significa “hecho” para cada etapa. Por ejemplo, mitigar puede significar que el impacto al cliente está detenido, incluso si la causa raíz aún se desconoce.
Define roles y responsabilidades
Mantén los roles explícitos para que la gente pueda actuar sin esperar reuniones:
- Reporter: crea el incidente, añade contexto inicial, adjunta enlaces/logs.
- Responder: investiga, añade actualizaciones, ejecuta mitigaciones.
- Incident Commander: coordina, asigna respondedores, aprueba la severidad, controla las actualizaciones a stakeholders.
- Reviewer: lidera la revisión post-incidente, asegura la calidad del postmortem.
Tu UI debe hacer visible el “propietario actual”, y tu flujo debe soportar delegación (reasignar, añadir respondedores, rotar comandante).
Estados y transiciones
Elige estados requeridos y transiciones permitidas, tales como Investigando → Mitigado → Resuelto. Añade salvaguardas:
- Requerir una severidad antes de avanzar más allá del triage.
- Requerir un resumen de resolución antes de marcar Resuelto.
- Prevenir “Resuelto → Investigando” a menos que se capture una razón de reapertura.
Planifica canales de comunicación
Separa actualizaciones internas (rápidas, tácticas, pueden ser desordenadas) de actualizaciones para stakeholders (claras, fechadas, curadas). Construye dos flujos de actualizaciones con plantillas, visibilidades y reglas de aprobación distintas—a menudo el comandante es el único que publica para stakeholders.
Modelar los datos: entidades, relaciones e historial
Una buena herramienta de incidentes se siente “simple” en la UI porque el modelo de datos subyacente es consistente. Antes de construir pantallas, decide qué objetos existen, cómo se relacionan y qué debe ser históricamente preciso.
Entidades principales (los objetos que guardas)
Empieza con un pequeño conjunto de objetos de primera clase:
- Incident: el contenedor de todo lo ocurrido.
- Service: lo que operas (API, base de datos, app móvil), usado para impacto e informes.
- Update: actualizaciones legibles por humanos (para notas internas y estado externo).
- Timeline Event: hechos precisos con marca de tiempo ("alerta disparada", "rollback", "mitigación aplicada").
- Action Item: seguimientos con responsables y fechas de vencimiento.
- Postmortem: el informe estructurado (impacto, análisis de causa raíz, lecciones, enlaces).
Relaciones e identificadores
La mayoría de relaciones son uno-a-muchos:
- Un Incident → muchas Updates / Timeline Events / Action Items
- Un Incident → un (o cero) Postmortem
- Un Incident ↔ muchos Services (normalmente many-to-many vía una tabla de unión “affected_services”)
Usa identificadores estables (UUIDs) para incidentes y eventos. Las personas todavía necesitan una clave legible como INC-2025-0042, que puedes generar a partir de una secuencia.
Modela esto desde temprano para poder filtrar, buscar e informar:
- Severidad, estado (abierto/mitigado/resuelto), etiquetas
- Hora de inicio, hora de fin, tiempo de detección
- Incident commander, equipo propietario, rotación de guardia (opcional)
- Servicios afectados, resumen de impacto al cliente
Historial, retención y auditabilidad
Los datos de incidentes son sensibles y a menudo se revisan después. Trata las ediciones como datos—no como sobrescrituras:
- Guarda created_at/created_by en cada registro.
- Para ediciones, conserva un registro de auditoría (cambios de campo + actor + marca de tiempo), o versiona documentos importantes (postmortem, actualizaciones).
- Decide la retención desde el principio (por ejemplo, guardar incidentes para siempre, purgar transcripciones de chat después de N días).
Esta estructura facilita futuras funciones—búsqueda, métricas y permisos—sin rehacer el diseño.
Construir la entrada de incidentes, actualizaciones y la línea de tiempo
Cuando algo falla, la tarea de la app es reducir la escritura y aumentar la claridad. Esta sección cubre la “ruta de escritura”: cómo las personas crean un incidente, lo mantienen actualizado y reconstruyen lo ocurrido después.
Entrada de incidente: campos mínimos, valores por defecto inteligentes
Mantén el formulario de entrada lo suficientemente corto para completarlo mientras solucionas. Un buen conjunto predeterminado de campos obligatorios es:
- Título (lenguaje llano: “Errores en checkout en móvil”)
- Servicio/Sistema (elige de una lista para evitar variantes ortográficas)
- Severidad (por defecto según servicio o hora, pero editable)
- Reporter (autorrelleno desde el usuario logueado)
Todo lo demás debe ser opcional al crear (impacto, enlaces a tickets de cliente, causa sospechada). Usa valores por defecto inteligentes: establece hora de inicio a “ahora”, preselecciona el equipo de guardia del usuario y ofrece una acción de un toque “Crear y abrir sala de incidentes”.
Actualizaciones rápidas: estado, impacto, próximos pasos
Tu UI de actualizaciones debe optimizarse para ediciones pequeñas y repetidas. Proporciona un panel de actualización compacto con:
- Estado (Investigando / Identificado / Mitigado / Resuelto)
- Resumen de impacto (una o dos frases)
- Notas clave (qué cambió desde la última actualización)
- Próximos pasos (qué se hará a continuación, por quién)
Haz que las actualizaciones sean aditivas: cada actualización se convierte en una entrada con marca de tiempo, no en una sobrescritura del texto anterior.
Línea de tiempo: historial automático más eventos manuales
Construye una línea de tiempo que mezcle:
- Eventos autograbados: cambios de campo (severidad, estado), asignaciones, enlaces añadidos, hora de resolución
- Eventos manuales: “Desplegado hotfix”, “Rollback”, “Failover de BD iniciado”
Esto crea una narración fiable sin forzar a la gente a recordar registrar cada clic.
Diseña para velocidad en móvil
Durante un outage, muchas actualizaciones ocurren desde el teléfono. Prioriza una pantalla rápida y de baja fricción: objetivos táctiles grandes, una única página desplazable, borradores offline-friendly y acciones de un toque como “Publicar actualización” y “Copiar enlace del incidente”.
Añadir severidad, checklists y contexto de apoyo
La severidad es el “dial de velocidad” de la respuesta: indica cuánto urgir actuar, qué tan ampliamente comunicar y qué compensaciones son aceptables.
Define niveles de severidad (y qué implican)
Evita etiquetas vagas como “alto/medio/bajo.” Haz que cada nivel de severidad mapee a expectativas operativas claras—especialmente tiempo de respuesta y cadencia de comunicación.
Por ejemplo:
- SEV1 (Crítico): outage visible para usuarios o riesgo mayor de seguridad. Notificar de inmediato, abrir bridge/chat del incidente, actualizar a stakeholders cada 15–30 minutos, y considerar una actualización pública de estado.
- SEV2 (Mayor): degradación parcial o impacto severo. Responder rápido, coordinar en chat, actualizar a stakeholders cada 30–60 minutos.
- SEV3 (Menor): impacto limitado, existe workaround. Manejar en horario laboral si procede, actualizar en hitos.
- SEV4 (Info): sin impacto inmediato; rastrear como asunto operativo.
Haz estas reglas visibles en la UI dondequiera que se escoja la severidad, para que los respondedores no tengan que buscar documentación.
Añade checklists de respondedores que coincidan con tu flujo
Los checklists reducen la carga cognitiva cuando la gente está estresada. Manténlos cortos, accionables y ligados a roles.
Un patrón útil es dividir en secciones:
- Triage: confirmar impacto al cliente, identificar radio de blast, fijar severidad, asignar líder del incidente.
- Mitigación: validar rollback/feature flag, verificar señales de recuperación, monitorizar regresiones.
- Comunicaciones: notificar soporte, publicar actualización interna, decidir actualización pública, capturar messaging para clientes.
Haz que los ítems del checklist tengan marca de tiempo y autoría para que formen parte del registro del incidente.
Enlaza artefactos de apoyo (para no perder contexto)
Los incidentes rara vez viven en una sola herramienta. Tu app debe permitir adjuntar enlaces a:
- Dashboards y gráficas específicas
- Consultas de logs
- Tickets/issue trackers
- Hilos de chat o canales de war-room
- Runbooks y playbooks
Prefiere enlaces “tipados” (por ejemplo, Runbook, Ticket) para que luego se puedan filtrar.
Captura impacto de SLA/SLO cuando sea relevante
Si tu organización rastrea objetivos de fiabilidad, añade campos ligeros como ¿SLO afectado? (sí/no), estimación de consumo de presupuesto de error, y riesgo para SLA de cliente. Déjalos opcionales—pero fáciles de completar durante o justo después del incidente, cuando los detalles están frescos.
Crear plantillas de postmortem y flujo de revisión
Lanza la primera versión
Crea formularios de entrada, actualizaciones, cronograma e informes postmortem sin semanas de configuración.
Un buen postmortem es fácil de empezar, difícil de olvidar y consistente entre equipos. La forma más simple de lograrlo es proporcionar una plantilla por defecto (con campos mínimos obligatorios) y autocompletarla desde el registro del incidente para que la gente pase tiempo pensando, no reescribiendo.
Una plantilla práctica de postmortem (qué incluir)
Tu plantilla integrada debe equilibrar estructura con flexibilidad:
- Resumen: Qué pasó en lenguaje llano (2–5 frases).
- Impacto: Quién/qué fue afectado, cuánto tiempo, síntomas visibles por el usuario y impacto al negocio (pedidos retrasados, tasa de errores, SLA incumplidos).
- Causa raíz: La causa técnica/procesal primaria. Manténlo factual, sin culpas.
- Factores contribuyentes: Problemas secundarios (fallos de monitoreo, propiedad poco clara, timing riesgoso de cambios).
- Qué salió bien / qué salió mal / dónde tuvimos suerte: Prompts que generan reflexiones honestas y accionables.
Haz “Causa raíz” opcional al principio si quieres publicar más rápido, pero requiérelo antes de la aprobación final.
Autoenlaza el postmortem a la línea de tiempo del incidente
El postmortem no debería ser un documento separado flotando. Cuando se crea un postmortem, adjunta automáticamente:
- La línea de tiempo del incidente (actualizaciones clave, cambios de estado, pasos de mitigación)
- Participantes (incident commander, respondedores, comunicaciones)
- Artefactos (tickets relacionados, dashboards, enlaces de logs—almacenados como referencias)
Usa esto para precargar secciones del postmortem. Por ejemplo, el bloque “Impacto” puede arrancar con las horas de inicio/fin del incidente y la severidad, mientras que “Qué hicimos” puede extraer entradas de la línea de tiempo.
Flujo de revisión y aprobación que favorezca el aprendizaje
Añade un flujo ligero para que los postmortems no se queden estancados:
- Borrador (creado automáticamente al cierre del incidente, o manualmente)
- En revisión (revisores asignados—a menudo IC + propietario del servicio)
- Aprobado (resumen bloqueado + notas de decisión capturadas)
- Publicado (compartido internamente; opcionalmente ligado a una actualización para clientes)
En cada paso, captura notas de decisión: qué cambió, por qué cambió y quién lo aprobó. Esto evita “ediciones silenciosas” y facilita auditorías o revisiones futuras.
Si quieres mantener la UI simple, trata las revisiones como comentarios con resultados explícitos (Aprobar / Solicitar cambios) y guarda la aprobación final como un registro inmutable.
Para equipos que lo necesiten, enlaza “Publicado” con tu flujo de actualizaciones de estado (ver /blog/integrations-status-updates) sin copiar contenido a mano.
Rastrear acciones hasta su finalización
Los postmortems solo reducen futuros incidentes si el trabajo de seguimiento realmente se hace. Trata las acciones como objetos de primera clase en tu app—no como un párrafo al final de un documento.
Define acciones como registros estructurados
Cada acción debe tener campos consistentes para poder rastrearla y medirla:
- Owner (una persona responsable, aunque la ejecución sea compartida)
- Due date (y opcional “start not before”)
- Priority (por ejemplo, P0–P3 o Alta/Media/Baja)
- Status (Abierta, En progreso, Bloqueada, Hecha, No se hará)
- Verification criteria (cómo confirmar que la solución funcionó)
Añade metadatos pequeños pero útiles: etiquetas (por ejemplo, “monitoreo”, “docs”), componente/servicio y “creado desde” (ID del incidente y del postmortem).
Facilita encontrar trabajo a través de incidentes
No encierres las acciones dentro de una única página de postmortem. Proporciona:
- Búsqueda global por propietario, servicio, etiqueta y estado
- Filtros como “vencidas”, “por vencer esta semana”, “bloqueadas”, “alta prioridad”
- Informes simples: conteos por equipo/servicio, tasa de completado, tiempo medio para cerrar
Esto convierte los seguimientos en una cola operativa en lugar de notas dispersas.
Trabajo recurrente y enlaces externos (opcional)
Algunas tareas se repiten (jams trimestrales, revisiones de runbook). Soporta una plantilla recurrente que genere nuevos ítems según un calendario, manteniendo cada ocurrencia rastreable por separado.
Si los equipos ya usan otro tracker, permite que una acción incluya un enlace de referencia externo y un ID externo, mientras mantienes tu app como la fuente para el enlace con incidentes y la verificación.
Recordatorios y reglas de escalado
Construye empujones ligeros: notifica a propietarios cuando se acerquen las fechas, marca las acciones vencidas para un lead de equipo y muestra patrones crónicos de vencimiento en los informes. Mantén las reglas configurables para que los equipos las adapten a su realidad de operaciones de guardia.
Permisos, control de acceso y auditabilidad
Empieza pequeño, escala después
Comienza en el plan gratuito y actualiza solo cuando tu equipo necesite más.
Los incidentes y postmortems a menudo contienen detalles sensibles—identificadores de clientes, IPs internas, hallazgos de seguridad o problemas con proveedores. Reglas de acceso claras mantienen la herramienta colaborativa sin convertirla en una fuga de datos.
Define niveles de permiso
Empieza con un conjunto pequeño y entendible de roles:
- Solo lectura (stakeholders): pueden leer resúmenes, líneas de tiempo y postmortems finales, pero no editar. Ideal para liderazgo, soporte al cliente y equipos asociados.
- Editores (responders): pueden crear incidentes, añadir actualizaciones, gestionar la línea de tiempo y redactar postmortems.
- Admins (propietarios): pueden gestionar roles, configurar plantillas, conectar integraciones y resolver disputas de acceso.
Si tienes múltiples equipos, considera escalar roles por servicio/equipo (por ejemplo, “Editores de Pagos”) en lugar de dar acceso global amplio.
Decide qué es privado vs. compartible
Clasifica el contenido desde temprano, antes de que la gente adopte hábitos:
- Campos internos: PII de clientes, notas de investigación de seguridad, logs crudos, transcripciones de chat internas.
- Campos compartibles: impacto de alto nivel, horas de inicio/fin, mitigaciones, actualizaciones públicas.
Un patrón práctico es marcar secciones como Internas o Compartibles y aplicarlo en exportaciones y páginas de estado. Los incidentes de seguridad pueden requerir un tipo separado con defaults más estrictos.
Registros de auditoría en los que puedas confiar
Para cada cambio en incidentes y postmortems, registra: quién lo cambió, qué cambió y cuándo. Incluye ediciones a severidad, marcas de tiempo, impacto y aprobaciones “finales”. Haz los registros de auditoría buscables y no editables.
Autenticación y seguridad de sesiones
Soporta autenticación fuerte desde el principio: email + MFA o magic link, y añade SSO (SAML/OIDC) si los usuarios lo esperan. Usa sesiones de corta duración, cookies seguras, protección CSRF y revocación automática de sesiones en cambios de rol. Para consideraciones de despliegue, ver /blog/testing-rollout-continuous-improvement.
UX: paneles, búsqueda y navegación
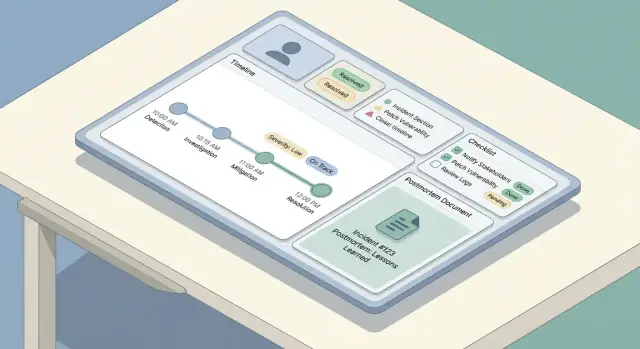
Cuando un incidente está activo, la gente escanea—no lee. Tu UX debe hacer obvio el estado actual en segundos, permitiendo a los respondedores profundizar sin perderse.
Pantallas principales para diseñar primero
Empieza con tres pantallas que cubren la mayoría de flujos:
- Lista de incidentes (dashboard): tabla o tarjetas mostrando distintivo de estado, severidad, título, servicios impactados, propietario/incident commander, hora de la última actualización y duración.
- Detalle del incidente: base para todo sobre un incidente—resumen, estado actual, enlaces clave, participantes y panel de acciones.
- Vista de línea de tiempo: feed cronológico de actualizaciones y eventos (alertas, notas manuales, cambios de estado), con marcas de tiempo grandes y legibles.
Una regla simple: la página de detalle debe responder “¿Qué está pasando ahora?” arriba, y “¿Cómo llegamos aquí?” abajo.
Filtrado y búsqueda que los respondedores realmente usen
Los incidentes se acumulan rápido, así que facilita el descubrimiento:
- Filtros rápidos: servicio, severidad, estado (abierto/mitigando/resuelto/postmortem pendiente), etiqueta, rango de fechas, propietario.
- Buscar en: título, ID del incidente, componentes afectados y etiquetas.
Ofrece vistas guardadas como Mis incidentes abiertos o Sev-1 esta semana para que los ingenieros de guardia no rehagan filtros cada turno.
Distintivos de estado y consistencia del “estado actual”
Usa distintivos consistentes y con buen contraste en toda la app (evita tonos sutiles que fallen bajo estrés). Mantén el mismo vocabulario de estado en lista, cabecera de detalle y eventos de la línea de tiempo.
De un vistazo, los respondedores deberían ver:
- Estado actual + severidad
- Hora de la última actualización (y quién la publicó)
- Próximo checkpoint (p. ej., “Próxima actualización en 8 min” si soportas cadencia de actualizaciones)
Legibilidad bajo presión
Prioriza la capacidad de escaneo:
- Tiempos grandes y encabezados de sección claros
- Cabecera del incidente fija mientras se hace scroll
- Secciones colapsables para datos ruidosos (alertas crudas, logs largos)
- Navegación amigable por teclado (/, n/p para siguiente/anterior incidente)
Diseña para el peor momento: si alguien está fatigado y revisando desde el móvil, la UI aún debe guiarlo a la acción correcta rápidamente.
Integraciones: alertas, chat, ticketing y actualizaciones de estado
Las integraciones convierten un rastreador de incidentes de “lugar para escribir notas” en el sistema con el que tu equipo realmente opera incidentes. Empieza listando los sistemas que debes conectar: monitoreo/observabilidad (PagerDuty/Opsgenie, Datadog, CloudWatch), chat (Slack/Teams), email, ticketing (Jira/ServiceNow) y una página de estado.
Elige el estilo de integración
La mayoría de equipos acaba con una mezcla:
- Webhooks entrantes para alertas y comandos de chat (rápidos, casi en tiempo real, bajo coste operativo).
- Polling cuando una herramienta no puede empujar eventos, pero mantén intervalos conservadores y caching.
- Enlace manual como plan de contingencia (pegar una URL de alerta, adjuntar un key de ticket), útil cuando las APIs están caídas.
Evita incidentes duplicados (idempotencia)
Las alertas son ruidosas, se reintentan y a menudo llegan fuera de orden. Define una clave de idempotencia por evento del proveedor (por ejemplo: provider + alert_id + occurrence_id) y guárdala con una restricción única. Para deduplicación, decide reglas como “mismo servicio + misma firma dentro de 15 minutos” debe anexarse a un incidente existente en lugar de crear uno nuevo.
Define límites y modos de fallo
Sé explícito sobre lo que tu app posee frente a lo que permanece en la herramienta origen:
- Tu app puede poseer el registro del incidente, la línea de tiempo, roles y postmortem.
- El sistema de tickets puede poseer ejecución del trabajo y aprobaciones.
Cuando una integración falle, degrada de forma graciosa: encola reintentos, muestra una advertencia en el incidente (“publicación en Slack retrasada”) y permite siempre que los operadores actúen manualmente.
Trata las actualizaciones de estado como una salida de primera clase: una acción estructurada de “Update” en la UI debe poder publicar en chat, anexarse a la línea de tiempo del incidente y opcionalmente sincronizarse con la página de estado—sin pedir al responder que escriba el mismo mensaje tres veces.
Arquitectura y elección de stack tecnológico
Itera con seguridad con instantáneas
Guarda una versión estable antes de cambios importantes y vuelve atrás si es necesario.
Tu herramienta de incidentes es un sistema que debe funcionar “durante un outage”, así que prioriza simplicidad y fiabilidad sobre novedades. El mejor stack suele ser el que tu equipo puede construir, depurar y operar a las 2 a.m. con confianza.
Elige un stack que tu equipo pueda mantener
Comienza con lo que tus ingenieros ya despliegan en producción. Un framework web mainstream (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) suele ser más seguro que uno nuevo que solo entiende una persona.
Para almacenamiento, una base relacional (PostgreSQL/MySQL) encaja bien con registros de incidentes: incidents, updates, participants, action items y postmortems se benefician de transacciones y relaciones claras. Añade Redis solo si realmente necesitas caching, colas o locks efímeros.
El hosting puede ser tan simple como una plataforma gestionada (Render/Fly/Heroku-like) o tu nube existente (AWS/GCP/Azure). Prefiere bases de datos administradas y backups gestionados si es posible.
Tiempo real: websockets vs. refresco periódico
Los incidentes activos se sienten mejor con actualizaciones en tiempo real, pero no siempre necesitas websockets en el día uno.
- Refresco periódico (polling) es más fácil de implementar y operar. Para muchos equipos, actualizar la línea de tiempo cada 10–30 segundos es “suficiente”.
- Websockets/SSE son valiosos cuando hay muchos espectadores concurrentes, actualizaciones rápidas o quieres colaboración tipo chat.
Un enfoque práctico: diseña la API/eventos para empezar con polling y poder pasar a websockets más tarde sin reescribir la UI.
Observabilidad de la propia herramienta de incidentes
Si esta app falla durante un incidente, pasa a formar parte del incidente. Añade:
- Logs estructurados (quién cambió qué y contexto de la petición)
- Métricas (latencia, tasa de errores, profundidad de colas, conexiones websocket)
- Seguimiento de errores (excepciones no capturadas, reportes de fallos en frontend)
Backups, migraciones y recuperación ante desastres
Trátalo como un sistema productivo:
- Backups diarios automáticos (y pruebas de restauración regulares)
- Migraciones de esquema seguras (patrones expand/contract, checks en CI)
- Un plan DR mínimo: cómo levantarlo en una nueva región/cuenta y cómo acceder a los datos si el entorno principal cae
Una vía rápida para prototipar (sin comprometer diseño erróneo)
Si quieres validar flujos y pantallas antes de invertir en un build completo, un enfoque de prototipo funcional puede funcionar bien: usa una herramienta como Koder.ai para generar un prototipo funcional desde una especificación detallada por chat, luego itera con respondedores durante ejercicios tabletop. Como Koder.ai puede producir frontends React con backend Go + PostgreSQL (y permite exportar código), puedes tratar versiones tempranas como prototipos descartables o como punto de partida que endurecerás—sin perder los aprendizajes de las simulaciones reales.
Pruebas, despliegue y mejora continua
Lanzar una app de seguimiento sin ensayar es apostar. Los mejores equipos tratan la herramienta como cualquier otro sistema operativo: prueban caminos críticos, hacen drills realistas, despliegan gradualmente y ajustan con base en uso real.
Prueba los caminos críticos de extremo a extremo
Concéntrate primero en los flujos que la gente usará bajo estrés:
- Crear un incidente, asignar severidad y notificar respondedores
- Publicar actualizaciones (incluyendo cambios de estado), verificar el orden en la línea de tiempo y que las ediciones queden marcadas
- Resolver y cerrar el incidente, luego generar un postmortem desde el estado final
- Confirmar que enlaces y referencias (servicios, propietarios, tickets, hilos de chat) permanecen intactos
Añade tests de regresión que validen lo que no debe romper: marcas de tiempo, zonas horarias y orden de eventos. Los incidentes son narrativas—si la línea de tiempo está mal, se pierde la confianza.
Verifica permisos y auditabilidad
Los bugs de permisos son riesgos operativos y de seguridad. Escribe tests que prueben:
- Solo roles autorizados pueden cambiar severidad, editar campos críticos o cerrar incidentes
- Usuarios de solo lectura no pueden acceder a incidentes restringidos
- Cada acción sensible deja rastro en el log de auditoría (quién, qué, cuándo), y el log no puede editarse
También prueba “casi fallos”, como un usuario que pierde acceso a mitad de incidente o una reorganización de equipos que cambia membresías.
Realiza ejercicios tabletop con respondedores reales
Antes del despliegue amplio, corre simulaciones usando tu app como fuente de verdad. Elige escenarios que la org reconozca (p. ej., degradación parcial, retraso de datos, fallo de tercero). Observa fricciones: campos confusos, contexto faltante, demasiados clicks, propiedad poco clara.
Captura feedback inmediatamente y conviértelo en mejoras pequeñas y rápidas.
Despliega con un piloto y un bucle de feedback
Empieza con un equipo piloto y unas pocas plantillas preconstruidas (tipos de incidente, checklists, formatos de postmortem). Proporciona entrenamiento corto y una guía de una página “cómo ejecutamos incidentes” enlazada desde la app (p. ej., /docs/incident-process).
Mide métricas de adopción e itera en puntos de fricción: tiempo para crear, % incidentes con actualizaciones, tasa de postmortems completados y tiempo de cierre de acciones. Trátalas como métricas de producto—no de cumplimiento—y mejora en cada release.