Aclara el objetivo y el alcance de la app
Antes de diseñar pantallas o elegir una pila tecnológica, deja explícito qué significa “riesgo operativo” en tu organización. Algunos equipos lo usan para cubrir fallos de proceso y error humano; otros incluyen caídas de TI, problemas con proveedores, fraude o eventos externos. Si la definición es difusa, tu app se convertirá en un vertedero—y el reporting será poco fiable.
Define qué vas a rastrear
Redacta una declaración clara sobre lo que cuenta como riesgo operativo y lo que no. Puedes enmarcarlo en cuatro cubos (procesos, personas, sistemas, eventos externos) y añadir 3–5 ejemplos por cada uno. Este paso reduce debates posteriores y mantiene los datos coherentes.
Acordar los resultados
Sé específico sobre lo que la app debe lograr. Resultados comunes incluyen:
- Visibilidad: un único lugar para ver riesgos, controles, incidentes y acciones
- Responsabilidad: cada elemento tiene un propietario nombrado y una fecha de vencimiento
- Seguimiento de remediación: las acciones pasan de “abiertas” a “verificadas” con evidencia
- Informes y preparación para auditoría: puedes explicar qué cambió, cuándo y por qué
Si no puedes describir el resultado, probablemente sea una petición de función—no un requisito.
Identifica los usuarios principales
Enumera los roles que usarán la app y lo que necesitan más:
- Propietarios de riesgo (identifican y actualizan riesgos)
- Propietarios de control (atestiguan controles, adjuntan evidencia)
- Revisores (aprueban cambios, solicitan actualizaciones)
- Auditores (acceso solo lectura, trazabilidad)
- Administradores (acceso de usuarios, configuración)
Esto evita construir para “todos” y no satisfacer a nadie.
Fija un alcance v1 realista
Un v1 práctico para seguimiento de riesgo operativo suele centrarse en: un registro de riesgos, puntuación básica de riesgos, seguimiento de acciones e informes sencillos. Deja capacidades más profundas (integraciones avanzadas, gestión compleja de taxonomías, constructores de flujo de trabajo personalizados) para fases posteriores.
Define métricas de éxito
Elige señales medibles como: porcentaje de riesgos con propietarios, completitud del registro de riesgos, tiempo para cerrar acciones, tasa de acciones atrasadas y cumplimiento de revisiones a tiempo. Estas métricas facilitan juzgar si la app funciona y qué mejorar a continuación.
Recopila requisitos de los interesados
Una app de registro de riesgos solo funciona si coincide con cómo las personas identifican, evalúan y hacen seguimiento del riesgo operativo. Antes de hablar de funciones, habla con quienes usarán (o serán evaluados por) los resultados.
A quién involucrar (y por qué)
Empieza con un grupo pequeño y representativo:
- Propietarios de unidades de negocio que generan y gestionan riesgos día a día
- Riesgo/Compliance que definen la terminología, expectativas de puntuación y necesidades de reporting
- Auditoría interna que se preocupa por la evidencia, las aprobaciones y la integridad del historial de auditoría
- TI/Seguridad que revisará control de acceso, retención de datos e integraciones
- Ejecutivos/enlaces del consejo que consumen resúmenes y reportes de tendencias
Mapea el proceso actual de extremo a extremo
En talleres, mapea el flujo real paso a paso: identificar → evaluar → mitigar → monitorizar → revisar. Captura dónde se toman decisiones (quién aprueba qué), qué significa “hecho” y qué desencadena una revisión (basada en tiempo, por incidente o por umbral).
Captura puntos de dolor que debes arreglar
Haz que los interesados muestren la hoja de cálculo o el hilo de correos actual. Documenta problemas concretos como:
- Propiedad faltante (propietario de riesgo vs. propietario de control vs. propietario de acción poco claro)
- Puntuación inconsistente (los equipos interpretan probabilidad/impacto de forma diferente)
- Pistas de auditoría débiles (sin registro de quién cambió qué y por qué)
- Confusión de versiones (múltiples copias de “la versión más reciente”)
Documenta los flujos de trabajo y eventos requeridos
Anota los flujos mínimos que la app debe soportar:
- Crear un nuevo riesgo (con campos obligatorios y reglas de aprobación)
- Actualizar un riesgo (re-puntuación, cambio de estado, añadir notas)
- Registrar incidentes y vincularlos a riesgos/controles
- Registrar resultados de pruebas de control y evidencia
- Crear y hacer seguimiento de planes de acción (fechas, recordatorios, escalado)
Acordad las salidas desde temprano para evitar retrabajo. Necesidades comunes incluyen resúmenes para el consejo, vistas por unidad de negocio, acciones atrasadas y riesgos principales por puntuación o tendencia.
Anota restricciones de cumplimiento (sin prometer certificaciones)
Lista las reglas que moldean los requisitos—por ejemplo, periodos de retención de datos, restricciones de privacidad para datos de incidentes, segregación de funciones, evidencia de aprobación y restricciones de acceso por región o entidad. Mantente en lo factual: estás recopilando restricciones, no afirmando cumplimiento por defecto.
Diseña tu marco de riesgo y la terminología
Antes de construir pantallas o flujos, alinea el vocabulario que la app de seguimiento de riesgo operativo impondrá. Una terminología clara previene problemas de “mismo riesgo, palabras diferentes” y hace los informes confiables.
Empieza con una taxonomía de riesgo práctica
Define cómo se agruparán y filtrarán los riesgos en el registro. Manténla útil tanto para la propiedad diaria como para paneles e informes.
Niveles típicos de taxonomía incluyen categoría → subcategoría, mapeada a unidades de negocio y (cuando aporte) procesos, productos o ubicaciones. Evita una taxonomía tan detallada que los usuarios no puedan escoger con consistencia; puedes refinarla más adelante conforme surjan patrones.
Estandariza la redacción del enunciado de riesgo y los campos obligatorios
Acordad un formato consistente para el enunciado de riesgo (p. ej., “Debido a causa, puede ocurrir evento, ocasionando impacto”). Luego decidid qué es obligatorio:
- Causa, evento, impacto (para análisis significativo)
- Propietario del riesgo y equipo responsable (para impulsar acciones)
- Estado (borrador, activo, en revisión, retirado)
- Fechas (identificado, última evaluación, próxima revisión)
Esta estructura liga controles e incidentes a una narrativa única en lugar de notas dispersas.
Define dimensiones de evaluación y puntuación
Elige las dimensiones de evaluación que soportará tu modelo de puntuación. Probabilidad e impacto son el mínimo; velocidad y detectabilidad pueden aportar valor si la gente los puntuará de forma consistente.
Decide cómo manejarás riesgo inherente vs. residual. Un enfoque común: riesgo inherente se puntúa antes de controles; riesgo residual es la puntuación post-control, con controles vinculados explícitamente para que la lógica sea explicable en revisiones y auditorías.
Finalmente, acordad una escala simple (a menudo 1–5) y redactad definiciones en lenguaje llano para cada nivel. Si “3 = medio” significa cosas diferentes para distintos equipos, el flujo de evaluación generará ruido en vez de insight.
Crea el modelo de datos (Registro de riesgos, controles, acciones)
Un modelo de datos claro convierte un registro en hoja de cálculo en un sistema que puedes confiar. Apunta a un conjunto pequeño de registros principales, relaciones limpias y listas de referencia consistentes para que el reporting siga siendo fiable conforme crece el uso.
Entidades principales (tu esquema mínimo viable)
Empieza con unas cuantas tablas que mapeen directamente a cómo trabajan las personas:
- Usuarios y Roles: quién está en el sistema y qué puede hacer
- Riesgos: la entrada del registro (título, descripción, propietario, área de negocio, puntuaciones inherente/residual, estado)
- Evaluaciones: valoraciones puntuales (fecha, evaluador, entradas de puntuación, notas). Mantener las evaluaciones separadas evita sobrescribir la “vista actual”.
- Controles: salvaguardias vinculadas a riesgos (efectividad de diseño/operación, cadencia de pruebas, propietario del control)
- Incidentes/Acontecimientos: lo ocurrido (fecha, impacto, causa raíz, riesgos vinculados, fallos de control vinculados)
- Acciones: tareas de remediación vinculadas a un riesgo, control o incidente
- Comentarios: discusión y decisiones, idealmente con @menciones y marcas temporales
Relaciones que importan para la trazabilidad
Modela explícitamente enlaces muchos-a-muchos clave:
- Riesgo ↔ Controles (vía tabla de unión) para mostrar qué controles mitigan qué riesgos
- Riesgo ↔ Incidentes para conectar pérdidas/near-misses reales con el registro
- Acciones → Riesgo/Control/Incidente (enlace polimórfico o tres claves foráneas anulables) para que la remediación siempre esté anclada
Esta estructura responde preguntas como “¿Qué controles reducen nuestros riesgos principales?” y “¿Qué incidentes causaron un cambio en la puntuación del riesgo?”.
Tablas de historial y “¿por qué cambió esto?”
El seguimiento del riesgo operativo a menudo necesita historial defendible. Añade tablas de historial/auditoría para Riesgos, Controles, Evaluaciones, Incidentes y Acciones con:
- quién lo cambió, cuándo y qué campos cambiaron
- motivo del cambio opcional (texto libre o códigos seleccionables)
Evita almacenar solo “última actualización” si se esperan aprobaciones y auditorías.
Tablas de referencia para consistencia
Usa tablas de referencia (no cadenas codificadas) para taxonomía, estados, escalas de severidad/probabilidad, tipos de control y estados de acción. Esto evita que el reporting falle por errores tipográficos (“Alto” vs. “ALTO”).
Adjuntos (evidencia) con retención en mente
Trata la evidencia como datos de primera clase: una tabla Adjuntos con metadatos de archivos (nombre, tipo, tamaño, subidor, registro vinculado, fecha de subida), además de campos para fecha de retención/eliminación y clasificación de acceso. Almacena los archivos en object storage, pero guarda las reglas de gobernanza en la base de datos.
Planifica flujos de trabajo, aprobaciones y responsabilidad
Una app de riesgos fracasa rápido cuando “quién hace qué” no está claro. Antes de construir pantallas, define estados de flujo, quién puede mover elementos entre estados y qué debe capturarse en cada paso.
Roles y permisos (mantenlos simples)
Empieza con un conjunto pequeño de roles y crece solo cuando sea necesario:
- Creador: puede redactar riesgos, controles, incidentes y acciones
- Propietario del riesgo: responsable de la veracidad y revisión continua
- Aprobador: valida entradas y puede marcarlas como “oficiales”
- Auditor / solo lectura: puede ver, exportar y (opcional) comentar, pero no editar
- Admin: gestiona configuración, usuarios y permisos
Haz los permisos explícitos por tipo de objeto (riesgo, control, acción) y por capacidad (crear, editar, aprobar, cerrar, reabrir).
Flujo de aprobación: borrador → revisión → aprobado → re-revisión
Usa un ciclo de vida claro con puertas predecibles:
- Borrador: editable; se permiten campos incompletos
- En revisión: cambios restringidos; exigir comentarios del revisor
- Aprobado: bloquear campos centrales; los cambios requieren una solicitud formal de actualización
- Revisión periódica: puntos de control programados (p. ej., trimestralmente) para confirmar que no ha habido cambios
SLA, recordatorios y lógica de vencimiento
Asocia SLA a ciclos de revisión, pruebas de control y fechas de vencimiento de acciones. Envía recordatorios antes de las fechas, escala después de incumplir SLA y muestra elementos vencidos de forma destacada (para propietarios y sus managers).
Delegación, reasignación y rendición de cuentas
Cada elemento debería tener un propietario responsable y colaboradores opcionales. Soporta delegación y reasignación, pero exige un motivo (y opcionalmente una fecha efectiva) para que los lectores entiendan por qué cambió la propiedad y cuándo se transfirió la responsabilidad.
Diseña la experiencia de usuario y pantallas clave
Cumple requisitos de ubicación de datos
Elige dónde se ejecuta tu app para cumplir requisitos internos de privacidad y transferencia de datos.
Una app de riesgos triunfa cuando la gente la usa. Para usuarios no técnicos, la mejor UX es predecible, de baja fricción y consistente: etiquetas claras, mínimo jerga y suficiente ayuda para evitar entradas vagas “varias cosas”.
1) Captura de riesgo: hacer que los buenos datos sean la opción por defecto
Tu formulario de ingreso debe sentirse como una conversación guiada. Añade texto de ayuda corto bajo los campos (no instrucciones largas) y marca como obligatorios solo los campos que lo sean de verdad.
Incluye esenciales como: título, categoría, proceso/área, propietario, estado actual, puntuación inicial y “por qué importa” (narrativa de impacto). Si usas puntuación, inserta tooltips junto a cada factor para que los usuarios entiendan las definiciones sin salir de la página.
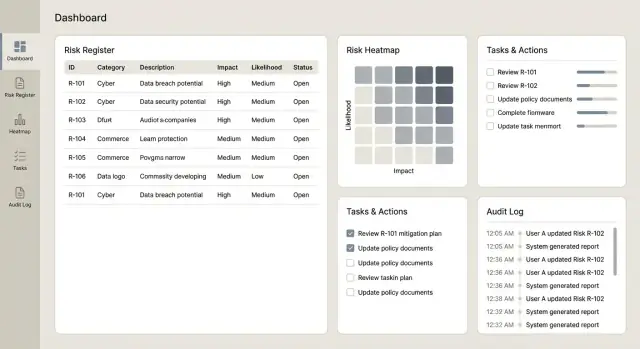
2) Vista de lista de riesgos: triaje y seguimiento en un solo lugar
La mayoría de usuarios vivirá en la vista de lista, así que hazla rápida para responder: “¿Qué necesita atención?”
Proporciona filtros y ordenación por estado, propietario, categoría, puntuación, fecha de última revisión y acciones vencidas. Resalta excepciones (revisiones vencidas, acciones pasadas de fecha) con insignias sutiles—no uses colores de alarma en todas partes—para que la atención vaya a lo relevante.
3) Página de detalle del riesgo: una historia, registros conectados
La pantalla de detalle debe leerse como un resumen primero y luego detalle de apoyo. Mantén la parte superior enfocada: descripción, puntuación actual, última revisión, próxima fecha de revisión y propietario.
Debajo, muestra controles vinculados, incidentes y acciones como secciones separadas. Añade comentarios para contexto (“por qué cambiamos la puntuación”) y adjuntos para evidencia.
4) Seguimiento de acciones: convertir decisiones en cierre
Las acciones necesitan asignación, fechas de vencimiento, progreso, subidas de evidencia y criterios claros de cierre. Haz la finalización explícita: quién aprueba el cierre y qué prueba se requiere.
Si necesitas un esquema de referencia, mantén la navegación simple y consistente entre pantallas (p. ej., /risks, /risks/new, /risks/{id}, /actions).
Implementa la puntuación y la lógica de revisión
La puntuación es donde la app de seguimiento de riesgo operativo se vuelve accionable. La meta no es “calificar” a los equipos, sino estandarizar cómo comparas riesgos, decidir qué requiere atención primero y evitar que los elementos queden obsoletos.
Elige (y documenta) un modelo de puntuación
Comienza con un modelo simple y explicable que funcione en la mayoría de equipos. Un predeterminado común es una escala 1–5 para Probabilidad y Impacto, con una puntuación calculada:
- Puntuación = Probabilidad × Impacto
Escribe definiciones claras para cada valor (qué significa un “3”, no solo el número). Pon esta documentación junto a los campos en la UI (tooltips o un cajón “Cómo funciona la puntuación”) para que los usuarios no tengan que buscarla.
Haz que los umbrales sean significativos y conéctalos a acciones
Los números por sí solos no generan comportamiento—los umbrales sí. Define límites para Bajo / Medio / Alto (y opcionalmente Crítico) y decide qué desencadena cada nivel.
Ejemplos:
- Alto: requiere propietario, fecha objetivo y aprobación de la dirección antes de cerrar
- Medio: requiere un plan de mitigación, pero puede no necesitar aprobación
- Bajo: seguimiento y revisión; no se requiere acción inmediata
Mantén los umbrales configurables, porque lo que cuenta como “Alto” difiere por unidad de negocio.
Rastrea riesgo inherente vs. residual
Las conversaciones de riesgo operativo suelen estancarse cuando la gente habla sin entenderse. Soluciona eso separando:
- Riesgo inherente: el riesgo antes de los controles
- Riesgo residual: el riesgo tras considerar los controles existentes
En la UI, muestra ambas puntuaciones lado a lado y muestra cómo los controles afectan el riesgo residual (por ejemplo, un control puede reducir Probabilidad en 1 o Impacto en 1). Evita ocultar la lógica detrás de ajustes automáticos que los usuarios no puedan explicar.
Construye reglas de revisión configurables
Añade lógica de revisión basada en tiempo para que los riesgos no queden obsoletos. Una línea base práctica:
- Riesgos altos: revisar trimestralmente
- Riesgos medios: revisar semestralmente
- Riesgos bajos: revisar anualmente
Haz la frecuencia de revisión configurable por unidad de negocio y permite excepciones por riesgo. Luego automatiza recordatorios y el estado “revisión vencida” según la fecha de última revisión.
Evita puntuaciones caja-negra
Haz visible el cálculo: muestra Probabilidad, Impacto, cualquier ajuste por controles y la puntuación residual final. Los usuarios deberían poder responder “¿Por qué esto es Alto?” de un vistazo.
Construye la pista de auditoría, versionado y manejo de evidencia
Reduce el costo de tu desarrollo
Obtén tiempo de compilación adicional creando contenido sobre Koder.ai o invitando a compañeros con referidos.
Una herramienta de riesgo operativo solo es creíble si tiene historial. Si cambia una puntuación, un control se marca como “probado” o un incidente se reclasifica, necesitas un registro que responda: quién hizo qué, cuándo y por qué.
Decide qué auditar (y sé explícito)
Empieza con una lista clara de eventos para no perder acciones importantes ni inundar el log con ruido. Eventos comunes incluyen:
- Create/update/delete en objetos principales (riesgos, controles, incidentes, acciones)
- Decisiones de aprobación (enviado, aprobado, rechazado) y reasignación de propiedad
- Exports (CSV/PDF), especialmente para equipos regulados
- Eventos de autenticación (intentos de login, reinicios de contraseña) y cambios de permisos
Captura el “quién/cuándo/qué” más contexto
Como mínimo, almacena actor, sello temporal, tipo/ID de objeto y los campos que cambiaron (valor antiguo → nuevo). Añade una nota opcional de “motivo del cambio”—evita confusiones posteriores (“cambiamos la puntuación residual tras la revisión trimestral”).
Mantén el log de auditoría append-only. Evita permitir ediciones, incluso por admins; si se necesita una corrección, crea un nuevo evento que haga referencia al anterior.
Proporciona una vista de log de auditoría de solo lectura
Auditores y administradores suelen necesitar una vista dedicada y filtrable: por rango de fechas, objeto, usuario y tipo de evento. Facilita exportar desde esta pantalla mientras sigues registrando el propio export.
Versiona evidencia y evita sobrescrituras silenciosas
Los archivos de evidencia (capturas, resultados de pruebas, políticas) deben versionarse. Trata cada subida como una nueva versión con su propia marca temporal y subidor, y preserva archivos previos. Si permites reemplazos, exige una nota de motivo y conserva ambas versiones.
Define retención y acceso para evidencia sensible
Fija reglas de retención (p. ej., conservar eventos de auditoría X años; purgar evidencia tras Y salvo retención legal). Restringe el acceso a la evidencia con permisos más estrictos que el registro cuando contenga datos personales o detalles de seguridad.
Aborda seguridad, privacidad y control de acceso
La seguridad y la privacidad no son “extras” para una app de seguimiento de riesgo operativo—configuran la comodidad de la gente para registrar incidentes, adjuntar evidencia y asignar responsabilidades. Empieza mapeando quién necesita acceso, qué deben ver y qué debe restringirse.
Autenticación: SSO vs. email/contraseña
Si tu organización ya usa un proveedor de identidad (Okta, Azure AD, Google Workspace), prioriza Single Sign-On vía SAML o OIDC. Reduce el riesgo de contraseñas, simplifica onboarding/offboarding y se alinea con políticas corporativas.
Si construyes para equipos pequeños o usuarios externos, email/contraseña puede funcionar—pero combínalo con reglas fuertes de contraseña, recuperación segura de cuenta y (cuando sea posible) MFA.
Control de acceso basado en roles (RBAC) que refleje el trabajo
Define roles que reflejen responsabilidades reales: admin, propietario de riesgo, revisor/aprobador, colaborador, solo lectura, auditor.
El riesgo operativo a menudo requiere límites más estrictos que una herramienta interna típica. Considera RBAC que restrinja acceso:
- Por unidad de negocio/departamento (p. ej., Finanzas no ve incidentes de RRHH)
- Por nivel de registro (p. ej., solo el equipo de investigación puede acceder a un incidente sensible)
Mantén los permisos comprensibles—la gente debería saber rápidamente por qué puede o no ver un registro.
Fundamentos de protección de datos que debes tratar como no negociables
Usa cifrado en tránsito (HTTPS/TLS) en todas partes y aplica el principio de mínimo privilegio para servicios de app y bases de datos. Las sesiones deben protegerse con cookies seguras, timeouts cortos por inactividad y invalidación server-side al cerrar sesión.
Sensibilidad por campo y enmascaramiento
No todos los campos tienen el mismo riesgo. Narrativas de incidentes, notas de impacto a clientes o detalles de empleados pueden necesitar controles más estrictos. Soporta visibilidad a nivel de campo (o al menos enmascaramiento) para que los usuarios colaboren sin exponer contenido sensible de forma amplia.
Salvaguardas administrativas
Añade algunos guardarraíles prácticos:
- Logs de actividad de administradores (quién cambió permisos, exports, configuraciones)
- Listas de IP permitidas opcionales para entornos de alto riesgo
- MFA para administradores (incluso si otros no lo usan)
Bien implementados, estos controles protegen datos sin entorpecer workflows de reporting y remediación.
Los paneles e informes son donde una app de seguimiento de riesgo operativo demuestra su valor: convierten un largo registro en decisiones claras para propietarios, managers y comités. La clave es que los números sean trazables hasta las reglas de puntuación y registros subyacentes.
Paneles que la gente use realmente
Empieza con un conjunto pequeño de vistas de alto valor que respondan preguntas comunes rápidamente:
- Riesgos principales por puntuación residual (con opción de cambiar a inherente)
- Tendencias en el tiempo (p. ej., tendencia de riesgo residual por mes/trimestre)
- Distribución residual vs. inherente, incluida una vista simple “antes vs. después de controles”
- Un mapa de calor (probabilidad × impacto) que enlace cada celda con los riesgos subyacentes
Haz cada mosaico clicable para que los usuarios puedan profundizar en la lista exacta de riesgos, controles, incidentes y acciones detrás del gráfico.
Vistas operativas para la gestión diaria
Los paneles de decisión son distintos de las vistas operativas. Añade pantallas enfocadas en lo que necesita atención esta semana:
- Acciones vencidas (por propietario/equipo, con días de retraso)
- Revisiones próximas (riesgos o controles que deben revisarse)
- Pruebas de control fallidas (fallos recientes, severidad y remediación abierta)
- Frecuencia de incidentes (conteos y tasas en el tiempo, con filtros por proceso/categoría)
Estas vistas encajan bien con recordatorios y propiedad de tareas para que la app parezca una herramienta de flujo, no solo una base de datos.
Exportaciones que funcionen para comités y auditorías
Planifica las exportaciones temprano, porque los comités suelen depender de paquetes offline. Soporta CSV para análisis y PDF para distribución solo lectura, con:
- Filtros (unidad de negocio, categoría, propietario, estado)
- Rangos de fechas (incidentes en periodo, acciones creadas/cerradas en periodo)
- Etiquetas claras (inherente vs. residual, fechas de versión y filtros aplicados)
Si ya tienes una plantilla de paquete de gobernanza, refléjala para facilitar la adopción.
Consistencia y rendimiento a escala
Asegúrate de que cada definición de informe coincida con tus reglas de puntuación. Por ejemplo, si el panel ordena “riesgos principales” por puntuación residual, debe coincidir con el mismo cálculo usado en el registro y en las exportaciones.
Para registros grandes, diseña para el rendimiento: paginación en listas, cache para agregados comunes y generación asíncrona de informes (generar en background y notificar cuando esté listo). Si añades informes programados más adelante, guarda enlaces internos (p. ej., guarda una configuración de informe que pueda reabrirse desde /reports).
Planifica integraciones y migración de datos
Lanza un piloto de forma segura
Lanza una beta interna con alojamiento y despliegue integrados, luego itera con retroalimentación.
Las integraciones y la migración determinan si tu app de seguimiento de riesgo se convierte en el sistema de registro—o simplemente otro lugar que la gente olvida actualizar. Planifícalas temprano, pero impleméntalas de forma incremental para mantener el producto central estable.
Empieza con los flujos que la gente ya usa
La mayoría de equipos no quieren “otra lista de tareas”. Quieren que la app se conecte con donde el trabajo sucede:
- Jira o ServiceNow para crear y seguir acciones de remediación (y sincronizar estado de vuelta)
- Slack o Microsoft Teams para alertas cuando un riesgo se escala, una revisión vence o se solicita evidencia
- Email para recordatorios de revisiones y aprobaciones (útil para usuarios ocasionales)
Un enfoque práctico es mantener la app de riesgos como el propietario de los datos de riesgo, mientras herramientas externas gestionan detalles de ejecución (tickets, asignados, fechas) y devuelven actualizaciones de progreso.
Población inicial del registro desde hojas de cálculo—con seguridad
Muchas organizaciones empiezan con Excel. Ofrece una importación que acepte formatos comunes, pero añade salvaguardas:
- Reglas de validación (campos obligatorios, formatos de fecha, rangos numéricos)
- Detección de duplicados (p. ej., mismo título del riesgo + proceso + propietario) con opción “fusionar/omitir”
- Aplicación de taxonomía (unidad de negocio, proceso, categoría de riesgo) para evitar reporting desordenado más adelante
Muestra una vista previa de lo que se creará, lo que será rechazado y por qué. Esa pantalla puede ahorrar horas de idas y venidas.
Fundamentos de API que reduzcan el dolor futuro
Aunque empieces con una integración, diseña la API como si tuvieras varias:
- Mantén endpoints consistentes y nombres claros (p. ej., /risks, /controls, /actions)
- Asegura registro de auditoría en escrituras (quién cambió qué, cuándo y desde dónde)
- Añade limitación de tasa y códigos de error claros para que las integraciones fallen de forma manejable
Maneja fallos con reintentos y estado visible
Las integraciones fallan por razones normales: cambios de permisos, timeouts de red, tickets borrados. Diseña para esto:
- Encola solicitudes salientes y reintenta con backoff
- Registra un estado de integración en cada ítem vinculado (“Synced”, “Pending”, “Failed”)
- Proporciona mensajes accionables (“Token de ServiceNow expirado—reconectar”) y un botón “Reintentar ahora”
Esto mantiene la confianza alta y evita la deriva silenciosa entre el registro y las herramientas de ejecución.
Prueba, lanza y mejora con el tiempo
Una app de seguimiento de riesgos se vuelve valiosa cuando la gente confía y la usa con consistencia. Trata las pruebas y el despliegue como parte del producto, no como una casilla final.
Construye una estrategia de pruebas práctica
Empieza con pruebas automatizadas para las partes que deben comportarse igual siempre—especialmente puntuación y permisos:
- Tests unitarios para puntuación: verifica cálculos de probabilidad/impacto, umbrales, redondeos y casos límite (p. ej., “N/A”, campos faltantes, overrides)
- Tests de flujo para aprobaciones: asegura que los cambios de estado siguen las reglas (borrador → enviado → aprobado), incluyendo reasignación y rechazo
- Tests de permisos: confirma que quienes solo leen no puedan editar, que propietarios no puedan aprobar sus propias envíos (si esa es tu política) y que admins puedan auditar sin romper segregación de funciones
Realiza pruebas de aceptación de usuarios (UAT) con escenarios reales
UAT funciona mejor cuando replica trabajo real. Pide a cada unidad de negocio un pequeño conjunto de riesgos, controles, incidentes y acciones de muestra, y luego ejecuta escenarios típicos:
- crear un riesgo, vincular controles y enviar para aprobación
- actualizar tras un incidente y adjuntar evidencia
- completar una acción y verificar cambios en reporting
Captura no solo bugs, sino etiquetas confusas, estados faltantes y campos que no coinciden con el lenguaje de los equipos.
Piloto antes del despliegue global
Lanza primero a un equipo (o región) durante 2–4 semanas. Mantén el alcance controlado: un solo flujo, pocas campos y una métrica de éxito clara (p. ej., % de riesgos revisados a tiempo). Usa el feedback para ajustar:
- nombres de campos y obligatorios
- pasos de aprobación y reglas de propiedad
- timing de recordatorios y escalados
Proporciona guías cortas y un glosario de una página: qué significa cada puntuación, cuándo usar cada estado y cómo adjuntar evidencia. Una sesión en vivo de 30 minutos más clips grabados suele ser mejor que un manual largo.
Construye más rápido con Koder.ai (opcional)
Si quieres llegar a un v1 creíble rápidamente, una plataforma vibe-coding como Koder.ai puede ayudar a prototipar e iterar flujos sin un ciclo de setup largo. Puedes describir pantallas y reglas (captura de riesgo, aprobaciones, puntuación, recordatorios, vistas de auditoría) en chat y luego refinar la app generada según la reacción de los interesados.
Koder.ai está diseñado para entrega end-to-end: soporta construir web apps (habitualmente React), servicios backend (Go + PostgreSQL) e incluye funcionalidades prácticas como exportación de código fuente, despliegue/hosting, dominios personalizados y snapshots con rollback—útiles cuando cambias taxonomías, escalas de puntuación o flujos de aprobación y necesitas iterar con seguridad. Los equipos pueden empezar en un plan gratuito y escalar a pro, business o enterprise según requisitos de gobernanza y escala.
Mantén la app saludable tras el lanzamiento
Planifica operaciones continuas desde el inicio: backups automáticos, monitorización básica de uptime/errores y un proceso ligero de cambios para taxonomía y escalas de puntuación para que las actualizaciones sean coherentes y auditable a lo largo del tiempo.