15 may 2025·8 min
Cómo crear una aplicación web para el enriquecimiento de datos de clientes
Aprende a crear una aplicación web que enriquece registros de clientes: arquitectura, integraciones, matching, validación, privacidad, monitorización y consejos de despliegue.
Definir objetivos, usuarios y alcance del enriquecimiento
Antes de elegir herramientas o dibujar diagramas de arquitectura, determina con precisión qué significa “enriquecimiento” para tu organización. Los equipos suelen mezclar distintos tipos de enriquecimiento y luego tienen dificultades para medir el progreso —o discuten sobre cómo se define el “terminado”.
¿Qué se considera enriquecimiento?
Empieza por nombrar las categorías de campos que quieres mejorar y por qué:
- Firmográficos: tamaño de la empresa, industria, sede, etapa de financiación
- Contacto: cargo, email/teléfono verificado, antigüedad, rol
- Comportamiento: señales de uso del producto, intención, puntuaciones de engagement
- Campos personalizados: territorio interno, nivel de cuenta, puntuación de ajuste al ICP
Anota qué campos son requeridos, cuáles son deseables y cuáles nunca deben enriquecerse (por ejemplo, atributos sensibles).
¿Quién usará la app —y para qué?
Identifica a tus usuarios principales y sus tareas principales:
- Sales ops: reducir duplicados, estandarizar cuentas, mejorar el enrutamiento
- Marketing ops: enriquecer leads para segmentación y mejor targeting
- Soporte: mostrar contexto de la cuenta durante los tickets
- Analistas: datasets confiables para reporting
Cada grupo de usuarios suele necesitar un flujo de trabajo diferente (procesos por lotes frente a revisión registro a registro), así que captura esas necesidades desde el principio.
Definir resultados, límites de alcance y métricas de éxito
Lista los resultados en términos medibles: mayor tasa de coincidencia, menos duplicados, enrutamiento más rápido de leads/cuentas o mejor rendimiento de la segmentación.
Establece límites claros: qué sistemas están dentro del alcance (CRM, facturación, analítica de producto, mesa de soporte) y cuáles no —al menos para la primera versión.
Por último, acuerda métricas de éxito y tasas de error aceptables (por ejemplo, cobertura de enriquecimiento, tasa de verificación, tasa de duplicados y reglas de “fallo seguro” cuando el enriquecimiento es incierto). Esto será tu estrella del norte para el resto del desarrollo.
Modela tus datos de cliente e identifica vacíos
Antes de enriquecer nada, aclara qué significa “un cliente” en tu sistema —y qué ya sabes de él. Esto evita pagar por enriquecimiento que no puedes almacenar y evita fusiones confusas después.
Haz inventario de tus campos y fuentes actuales
Empieza con un catálogo simple de campos (por ejemplo: nombre, email, empresa, dominio, teléfono, dirección, cargo, industria). Para cada campo, anota su origen: entrada de usuario, importación al CRM, sistema de facturación, herramienta de soporte, formulario de registro del producto o un proveedor de enriquecimiento.
También captura cómo se recoge (requerido vs opcional) y con qué frecuencia cambia. Por ejemplo, el cargo y el tamaño de la empresa varían con el tiempo, mientras que un ID interno de cliente nunca debería cambiar.
Define tu modelo de identidad: persona, empresa, cuenta
La mayoría de los flujos de enriquecimiento involucran al menos dos entidades:
- Persona (contacto/lead): individuo con emails, teléfonos y roles
- Empresa (organización): negocio con dominio, ubicación y firmográficos
Decide si también necesitas una Cuenta (relación comercial) que vincule varias personas a una empresa con atributos como plan, fechas de contrato y estado.
Escribe las relaciones que soportarás (por ejemplo, muchas personas → una empresa; una persona → varias empresas a lo largo del tiempo).
Documenta problemas comunes de datos
Lista los problemas que ves repetidamente: valores faltantes, formatos inconsistentes ("US" vs "United States"), duplicados creados por importaciones, registros obsoletos y fuentes en conflicto (dirección de facturación vs dirección en el CRM).
Elige claves requeridas y establece niveles de confianza
Escoge los identificadores que usarás para emparejar y actualizar —típicamente email, dominio, teléfono y un ID de cliente interno.
Asigna a cada uno un nivel de confianza: qué claves son autoritativas, cuáles son “mejor intento” y cuáles nunca deben sobrescribirse.
Aclara la propiedad y permisos de edición
Acuerda quién es dueño de qué campos (Sales ops, Support, Marketing, Customer Success) y define reglas de edición: qué puede cambiar un humano, qué puede cambiar la automatización y qué requiere aprobación.
Esta gobernanza ahorra tiempo cuando los resultados de enriquecimiento entran en conflicto con datos existentes.
Elige fuentes de enriquecimiento y contratos de datos
Antes de escribir código de integración, decide de dónde vendrán los datos de enriquecimiento y qué permiso tienes para usarlos. Esto evita un modo de fallo común: lanzar una funcionalidad que funciona técnicamente pero rompe por costes, fiabilidad o cumplimiento.
Fuentes típicas de enriquecimiento
Usualmente combinarás varias entradas:
- Sistemas internos: CRM, facturación, tickets de soporte, analítica de producto, plataforma de email, data warehouse
- APIs de terceros: firmográficos de empresas, validación de contactos, códigos de industria, tecnográficas, señales de riesgo
- Listas subidas: CSVs de ventas, eventos, partners o proveedores de datos
- Webhooks: actualizaciones en tiempo real desde herramientas que ya observan cambios (p. ej., verificación de email, proveedores de identidad)
Cómo evaluar las fuentes
Para cada fuente, puntúala según cobertura (con qué frecuencia devuelve algo útil), frescura (qué tan rápido se actualiza), coste (por llamada/por registro), límites de tasa y términos de uso (qué puedes almacenar, cuánto tiempo y con qué propósito).
Verifica también si el proveedor devuelve puntuaciones de confianza y proveniencia clara (de dónde vino un campo).
Define un contrato de datos
Trata cada fuente como un contrato que especifique nombres y formatos de campos, campos requeridos vs opcionales, frecuencia de actualización, latencia esperada, códigos de error y semántica de confianza.
Incluye un mapeo explícito (“campo proveedor → tu campo canónico”) más reglas para nulos y valores en conflicto.
Decisiones de fallback y almacenamiento
Planifica qué ocurre cuando una fuente no está disponible o devuelve resultados de baja confianza: reintentar con backoff, encolar para más tarde o usar una fuente secundaria.
Decide qué almacenas (atributos estables necesarios para búsqueda/reporting) versus qué calculás bajo demanda (búsquedas caras o consultas sensibles al tiempo).
Finalmente, documenta restricciones sobre almacenar atributos sensibles (p. ej., identificadores personales, inferencias demográficas) y establece reglas de retención.
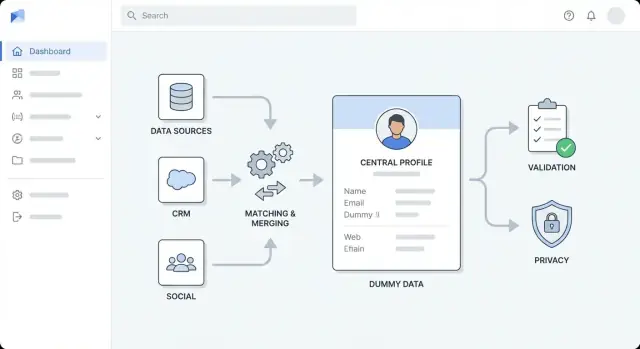
Diseña la arquitectura de alto nivel
Antes de elegir herramientas, decide la forma de la app. Una arquitectura clara mantiene el trabajo de enriquecimiento predecible, evita que los “parches rápidos” se conviertan en desorden permanente y ayuda a estimar esfuerzo.
Elige un estilo de arquitectura acorde a tu equipo
Para la mayoría de equipos, empieza con un monolito modular: una sola app desplegable, internamente dividida en módulos bien definidos (ingestión, emparejamiento, enriquecimiento, UI). Es más sencillo de construir, probar y depurar.
Pasa a servicios separados cuando tengas una razón clara —p. ej., alto throughput de enriquecimiento, necesidad de escalado independiente o equipos distintos que posean partes distintas. Una división común es:
- Servicio API (peticiones síncronas, auth, CRUD de registros)
- Servicio de workers (enriquecimiento asíncrono, reintentos)
- UI (revisión, aprobaciones, acciones por lotes)
Separa responsabilidades en capas
Mantén límites explícitos para que los cambios no se propaguen por todas partes:
- Capa de ingestión: importaciones desde CRM/archivos y normalización de entradas
- Capa de enriquecimiento: llamadas a vendors/fuentes internas y almacenamiento de resultados
- Capa de validación: aplica reglas de calidad de datos y marca excepciones
- Capa de almacenamiento: perfiles de clientes, payloads crudos, historial de auditoría
- Capa de presentación: vistas UI, colas de revisión, aprobaciones
Diseña para enriquecimiento asíncrono desde el día uno
El enriquecimiento es lento y propenso a fallos (límites de tasa, timeouts, datos parciales). Trátalo como trabajos:
- La API crea un job y responde rápido
- Los workers procesan jobs vía una cola (con reintentos y backoff)
- La UI muestra estado del job y permite re-ejecución cuando sea necesario
Planifica entornos y configuración
Configura dev/staging/prod temprano. Mantén claves de proveedores, umbrales y feature flags en configuración (no en código) y facilita cambiar proveedores por entorno.
Alinea con un diagrama de una página
Haz un diagrama simple que muestre: UI → API → base de datos, más cola → workers → proveedores de enriquecimiento. Úsalo en revisiones para que todos acuerden responsabilidades antes de implementar.
Prototipado rápido (opcional)
Si tu objetivo es validar los flujos y pantallas de revisión antes de invertir en un ciclo de ingeniería completo, una plataforma de prototipado tipo “vibe-coding” como Koder.ai puede ayudarte a prototipar la app central rápidamente: una UI en React para revisión/aprobaciones, una capa API en Go y almacenamiento con PostgreSQL.
Esto es especialmente útil para validar el modelo de jobs (enriquecimiento asíncrono con reintentos), el historial de auditoría y los patrones de acceso por roles, y luego exportar el código fuente cuando estés listo para llevarlo a producción.
Configura almacenamiento, colas y servicios de soporte
Antes de conectar proveedores de enriquecimiento, pon la “plomería” en orden. Las decisiones sobre almacenamiento y procesamiento en background son difíciles de cambiar después y afectan la fiabilidad, el coste y la auditabilidad.
Base de datos principal: perfiles + historial
Elige una base de datos principal para perfiles de clientes que soporte datos estructurados y atributos flexibles. Postgres es una elección común porque puede almacenar campos core (nombre, dominio, industria) junto con campos de enriquecimiento semiestructurados (JSON).
Igual de importante: guarda el historial de cambios. En lugar de sobrescribir valores silenciosamente, captura quién/qué cambió un campo, cuándo y por qué (p. ej., “vendor_refresh”, “manual_approval”). Esto facilita aprobaciones y te protege en rollbacks.
Cola: enriquecimiento y reintentos
El enriquecimiento es inherentemente asíncrono: las APIs aplican límites de tasa, las redes fallan y algunos vendors responden lento. Añade una cola de jobs para trabajo en background:
- Peticiones de enriquecimiento (registro único y por lotes)
- Reintentos con backoff
- Refrescos programados (p. ej., cada 30/90 días)
- Manejo de dead-letter para jobs que siguen fallando
Esto mantiene la UI responsiva y evita que problemas con proveedores tumben la app.
Caché: búsquedas rápidas y seguimiento de límites
Una caché pequeña (a menudo Redis) ayuda con búsquedas frecuentes (p. ej., “empresa por dominio”) y a trackear límites de tasa y ventanas de cooldown de proveedores. También es útil para llaves de idempotencia para que importaciones repetidas no disparen enriquecimientos duplicados.
Almacenamiento de archivos y retención
Planifica un almacenamiento de objetos para importaciones/exports CSV, reportes de errores y archivos “diff” usados en flujos de revisión.
Define reglas de retención temprano: guarda payloads crudos de proveedores solo mientras sean necesarios para debugging y auditorías, y expira logs según la política de cumplimiento.
Construye pipelines de ingestión y normalización
Compensa tus costos de desarrollo
Obtén créditos compartiendo lo que construiste con Koder.ai o invitando a colegas.
Tu app de enriquecimiento solo es tan buena como los datos que le alimentas. La ingestión es donde decides cómo entra la información al sistema y la normalización es donde la haces lo suficientemente consistente para emparejar, enriquecer y reportar.
Decide cómo entra la información
La mayoría de equipos necesita una mezcla de puntos de entrada:
- Endpoints API para que tu producto o herramientas internas envíen clientes nuevos/actualizados
- Webhooks desde CRMs o sistemas de facturación para cambios casi en tiempo real
- Pulls programados (sync nocturno) para sistemas que no soportan push
- Importaciones CSV para backfills y cargas puntuales
Sea lo que sea, mantén el paso de “ingest crudo” ligero: acepta datos, autentica, registra metadata y encola trabajo para procesamiento.
Normaliza y estandariza temprano
Crea una capa de normalización que convierta entradas desordenadas en una forma interna consistente:
- Nombres: recorta espacios, separa nombre completo cuando sea posible, maneja mayúsculas/minúsculas
- Teléfonos: convierte a formato E.164 y guarda supuestos de país explícitos
- Direcciones: estandariza campos (calle, localidad, región, código postal) y conserva el texto original
- Dominios/emails: lowercase, elimina parámetros de tracking de URLs, valida sintaxis
Valida, cuarentena y mantén idempotencia
Define campos requeridos por tipo de registro y rechaza o cuarentena registros que fallen las comprobaciones (p. ej., falta de email/dominio para emparejamiento de empresa). Los elementos en cuarentena deben ser visibles y corregibles en la UI.
Añade llaves de idempotencia para evitar procesamiento duplicado cuando ocurren reintentos (común con webhooks y redes inestables). Un enfoque simple es hashear (source_system, external_id, event_type, event_timestamp).
Rastrea linaje por campo
Almacena la proveniencia para cada registro y, idealmente, para cada campo: fuente, hora de ingestión y versión de transformación. Esto permite responder preguntas posteriores: “¿Por qué cambió este teléfono?” o “¿Qué import produjo este valor?”.
Implementa emparejamiento, deduplicación y fusión
Acertar en el enriquecimiento depende de identificar de forma fiable quién es quién. Tu app necesita reglas claras de emparejamiento, comportamiento predecible de fusión y una red de seguridad cuando el sistema no está seguro.
Define reglas de emparejamiento (y umbrales de confianza)
Empieza con identificadores deterministas:
- Claves exactas: email (normalizado a minúsculas), ID de cliente, ID fiscal, o dominio verificado
Luego añade emparejamiento probabilístico para casos sin claves exactas:
- Coincidencias difusas: nombre + dominio de empresa, nombre + ubicación, similitud de teléfono
Asigna una puntuación de match y fija umbrales, por ejemplo:
- Auto-merge solo por encima de un umbral alto
- Encolar para revisión manual en el rango “tal vez”
- Rechazar por debajo del umbral bajo
Planifica la lógica de deduplicación y fusión
Cuando dos registros representan al mismo cliente, decide cómo se eligen los campos:
- Precedencia de campos: “email verificado vence a no verificado”, “marca más reciente gana”, “CRM sobreescribe enriquecimiento para propietario de contacto”
- Puntuaciones de confianza de fuentes: ordena las fuentes (CRM, facturación, proveedores de enriquecimiento) para resolver conflictos
- Manejo de conflictos: guarda ambos valores cuando sea posible (p. ej., múltiples teléfonos) o almacena el valor perdedor en el historial
Registro de auditoría y flujo de revisión
Cada fusión debe crear un evento de auditoría: quién/qué lo desencadenó, valores antes/después, cuándo, puntuación de match e IDs de registros involucrados.
Para matches ambiguos, proporciona una pantalla de revisión con comparación lado a lado y opciones “fusionar / no fusionar / pedir más datos”.
Salvaguardas contra fusiones masivas accidentales
Requiere confirmación extra para fusiones por lotes, limita el número de fusiones por job y soporta vistas previas en “dry run”.
Añade también una ruta de deshacer (o reversión de fusión) usando el historial de auditoría para que los errores no sean permanentes.
Integra APIs de enriquecimiento y maneja la fiabilidad
El enriquecimiento es donde tu app se encuentra con el mundo exterior: múltiples proveedores, respuestas inconsistentes y disponibilidad impredecible.
Trata a cada proveedor como un “conector” enchufable para poder añadir, cambiar o desactivar fuentes sin tocar el resto del pipeline.
Crea conectores de proveedor (auth, reintentos, mapeo de errores)
Crea un conector por proveedor de enriquecimiento con una interfaz consistente (p. ej., enrichPerson(), enrichCompany()). Mantén la lógica específica del proveedor dentro del conector:
- Autenticación (API keys, tokens OAuth, refresh de tokens)
- Reintentos estandarizados para fallos transitorios
- Mapeo de errores (convertir errores del proveedor en tus propias categorías como
invalid_request,not_found,rate_limited,provider_down)
Esto simplifica los flujos downstream: estos manejan tus tipos de error, no las peculiaridades de cada proveedor.
Maneja límites de tasa con throttling y backoff
La mayoría de APIs de enriquecimiento imponen cuotas. Añade throttling por proveedor (y a veces por endpoint) para mantener las solicitudes bajo los límites.
Cuando alcanzas un límite, usa backoff exponencial con jitter y respeta cabeceras Retry-After.
Planea también el “fallo lento”: los timeouts y respuestas parciales deben registrarse como eventos reintentables, no como caídas silenciosas.
Almacena confianza y evidencia (dentro de la política)
Los resultados de enriquecimiento rara vez son absolutos. Guarda las puntuaciones de confianza del proveedor cuando estén disponibles, además de tu propia puntuación basada en calidad de match y completitud de campos.
Cuando el contrato y la política de privacidad lo permitan, guarda evidencia cruda (URLs fuente, identificadores, timestamps) para soportar auditoría y confianza de usuarios.
Estrategia multi-proveedor: selección del “mejor disponible”
Soporta múltiples proveedores definiendo reglas de selección: más barato primero, mayor confianza, o “mejor por campo”.
Registra qué proveedor suministró cada atributo para poder explicar cambios y revertir si es necesario.
Reglas de refresco programado
El enriquecimiento se queda obsoleto. Implementa políticas de refresh como “re-enriquecer cada 90 días”, “refrescar cuando cambia un campo clave” o “solo refrescar si la confianza cae”.
Haz los calendarios configurables por cliente y por tipo de dato para controlar costes y ruido.
Añade reglas de calidad de datos y validación
Prueba revisiones y aprobaciones
Crea pantallas de revisión de merge y registro de auditoría desde temprano, antes de la implementación completa.
El enriquecimiento solo ayuda si los valores nuevos son fiables. Trata la validación como una funcionalidad de primera clase: protege a tus usuarios de importaciones desordenadas, respuestas poco fiables de terceros y corrupción accidental durante fusiones.
Define reglas de validación por campo
Empieza con un “catálogo de reglas” por campo, compartido entre formularios UI, pipelines de ingestión y APIs públicas.
Reglas comunes incluyen comprobaciones de formato (email, teléfono, código postal), valores permitidos (códigos de país, listas de industria), rangos (número de empleados, bandas de ingresos) y dependencias requeridas (si country = US, entonces state es requerido).
Mantén las reglas versionadas para poder cambiarlas de forma segura con el tiempo.
Añade verificaciones de calidad que reflejen uso real
Más allá de la validación básica, ejecuta checks de calidad que respondan preguntas del negocio:
- Completitud: ¿Tenemos los campos mínimos para usar el registro?
- Unicidad: ¿Se duplican identificadores “únicos” (dominio, ID fiscal)?
- Consistencia: ¿Están de acuerdo campos relacionados (país vs prefijo telefónico)?
- Oportunidad: ¿Qué antigüedad tiene un valor y debe ser refrescado?
Puntúa registros y fuentes
Convierte las comprobaciones en una tarjeta de puntuación: por registro (salud global) y por fuente (qué tan seguido provee valores válidos y actualizados).
Usa la puntuación para guiar la automatización —por ejemplo, aplicar automáticamente enriquecimientos solo por encima de un umbral.
Enruta fallos de forma predecible
Cuando un registro falla validación, no lo descartes.
Envíalo a una cola “data-quality” para reintento (problemas transitorios) o revisión manual (entrada mala). Guarda el payload fallido, violaciones de reglas y sugerencias de corrección.
Haz los errores entendibles
Devuelve mensajes claros y accionables para importaciones y clientes de API: qué campo falló, por qué y un ejemplo de valor válido.
Esto reduce la carga de soporte y acelera la limpieza.
Crea la UI para revisión, aprobaciones y trabajo por lotes
Tu pipeline de enriquecimiento solo entrega valor cuando las personas pueden revisar qué cambió y con confianza empujar actualizaciones a sistemas downstream.
La UI debe dejar claro “qué pasó, por qué y qué hago ahora?”.
Pantallas núcleo a diseñar
La ficha de cliente es la base. Muestra identificadores clave (email, dominio, nombre de empresa), valores actuales y un distintivo de estado de enriquecimiento (p. ej., No enriquecido, En progreso, Requiere revisión, Aprobado, Rechazado).
Añade una línea de tiempo de cambios que explique actualizaciones en lenguaje claro: “Tamaño de empresa actualizado de 11–50 a 51–200.” Haz cada entrada clicable para ver detalles.
Proporciona sugerencias de fusión cuando se detecten duplicados. Muestra los dos (o más) registros candidatos lado a lado con el registro recomendado como “superviviente” y una vista previa del resultado de la fusión.
Trabajo por lotes que refleje operaciones reales
La mayoría de equipos trabaja en lotes. Incluye acciones por lotes como:
- Enriquecer registros seleccionados (o encolarlos para procesamiento nocturno)
- Aprobar/rechazar fusiones sugeridas
- Exportar resultados (CSV) para auditorías o revisión offline
Usa un paso claro de confirmación para acciones destructivas (fusionar, sobrescribir) con una ventana de “deshacer” cuando sea posible.
Búsqueda rápida, filtros y proveniencia a nivel de campo
Añade búsqueda global y filtros por email, dominio, empresa, estado y puntuación de calidad.
Permite a los usuarios guardar vistas como “Requiere revisión” o “Actualizaciones de baja confianza”.
Para cada campo enriquecido, muestra proveniencia: fuente, timestamp y confianza.
Un panel simple “¿Por qué este valor?” genera confianza y reduce idas y vueltas.
Flujos guiados para usuarios no técnicos
Mantén las decisiones binarias y guiadas: “Aceptar valor sugerido”, “Mantener existente” o “Editar manualmente”. Si necesitas control más fino, escóndelo tras un toggle “Avanzado” en lugar de hacerlo por defecto.
Seguridad, privacidad y fundamentos de cumplimiento
Ajusta el plan al alcance
Comienza en el plan gratuito y luego pasa a Pro, Business o Enterprise a medida que tu despliegue crece.
Las apps de enriquecimiento tocan identificadores sensibles (emails, teléfonos, datos de empresa) y a menudo extraen datos de terceros. Trata la seguridad y la privacidad como características centrales, no como tareas “para después”.
Control de acceso basado en roles (RBAC)
Comienza con roles claros y privilegios mínimos:
- Admin: gestionar usuarios, roles, conectores, políticas de retención
- Ops: ejecutar jobs de enriquecimiento, resolver conflictos, aprobar fusiones
- Viewer: acceso solo lectura para reporting y soporte
Mantén permisos granulados (p. ej., “exportar datos”, “ver PII”, “aprobar fusiones”) y separa entornos para que datos de producción no estén disponibles en dev.
Protege datos sensibles
Usa TLS para todo el tráfico y cifrado en reposo para bases de datos y almacenamiento de objetos.
Guarda claves de API en un gestor de secretos (no en archivos de entorno en control de código), rótalas periódicamente y limita su alcance por entorno.
Si muestras PII en la UI, aplica valores por defecto seguros como enmascaramiento (p. ej., mostrar solo los últimos 2–4 dígitos) y exige permiso explícito para revelar valores completos.
Consentimiento y restricciones de uso de datos
Si el enriquecimiento depende de consentimiento o términos contractuales, codifica esas restricciones en tu flujo:
- Rastrear fuente de datos, propósito y usos permitidos por campo
- Documentar qué almacenas y por qué (una página de política interna como /privacy o /docs/data-handling ayuda)
- Evitar recolectar campos innecesarios —menos datos reducen el riesgo
Auditoría, retención y eliminación
Crea un rastro de auditoría para accesos y cambios:
- Registra quién vio/exportó registros
- Registra quién cambió qué y cuándo (valores antes/después, ID de job, proveedor de enriquecimiento)
Finalmente, soporta solicitudes de privacidad con herramientas prácticas: políticas de retención, eliminación de registros y flujos de “olvido” que también purguen copias en logs, cachés y backups cuando sea factible (o las marquen para expiración).
Monitorización, analítica y controles operativos
La monitorización no es solo para uptime —es cómo mantienes la confianza en el enriquecimiento a medida que cambian volúmenes, proveedores y reglas.
Trata cada ejecución de enriquecimiento como un job medible con señales claras que puedas trazar en el tiempo.
Métricas que realmente ayudan
Empieza con un pequeño conjunto de métricas operativas vinculadas a resultados:
- Throughput de jobs (registros/min) y tiempo hasta completar por ejecución
- Tasa de éxito vs tasa de fallo, desglosada por tipo de fallo (validación, emparejamiento, proveedor)
- Latencia del proveedor (p50/p95) y timeouts por fuente de enriquecimiento
- Tasa de match (con qué frecuencia adjuntas enriquecimiento con confianza)
- Duplicados prevenidos (cuántos se habrían fusionado incorrectamente sin controles)
Estos números responden rápidamente: “¿Estamos mejorando datos o solo moviéndolos?”.
Alertas y salvaguardas
Añade alertas que se disparen por cambio, no por ruido:
- Picos en fallos o registros en cuarentena
- Backlogs en colas o consumidores lentos (indica pipeline atascado)
- Rafagas de errores de proveedores (429/5xx), latencia elevada o timeouts
Vincula alertas a acciones concretas, como pausar un proveedor, reducir concurrencia o cambiar a datos en caché/obsoletos.
Dashboard de administración para operadores
Proporciona una vista de admin para ejecuciones recientes: estado, contadores, reintentos y lista de registros en cuarentena con razones.
Incluye controles de “replay” y acciones masivas seguras (reintentar timeouts de proveedor, re-ejecutar solo emparejamiento).
Trazabilidad con logs
Usa logs estructurados y un correlation ID que siga un registro end-to-end (ingestión → match → enriquecimiento → fusión).
Esto acelera mucho el soporte al cliente y la depuración de incidentes.
Playbooks de incidentes y rollback
Escribe playbooks cortos: qué hacer cuando un proveedor degrada, cuando la tasa de match colapsa o cuando se infiltran duplicados.
Mantén una opción de rollback (p. ej., revertir fusiones en una ventana temporal) y documenta el proceso en /runbooks.
Pruebas, despliegue e iteración
Las pruebas y el despliegue son donde una app de enriquecimiento se vuelve segura de confiar. El objetivo no es “más tests”, sino la confianza de que el emparejamiento, la fusión y la validación se comportan de forma predecible con datos reales y desordenados.
Prueba las partes de más riesgo primero
Prioriza tests alrededor de la lógica que puede dañar registros en silencio:
- Reglas de emparejamiento: tests unitarios para matches exactos, difusos y compuestos (p. ej., email + dominio de empresa). Incluye casi-duplicados y campos intercambiados.
- Resultados de fusión: prueba precedencia de campos (prioridad de fuentes), manejo de conflictos y reglas de “no sobrescribir”.
- Casos límite de validación: emails malformados, formatos telefónicos internacionales, país faltante, identificadores duplicados y valores “desconocidos”.
Usa datasets sintéticos (nombres, dominios y direcciones generadas) para validar precisión sin exponer datos reales de clientes.
Mantén un conjunto “golden” versionado con salidas esperadas de match/fusión para detectar regresiones.
Incrementa el despliegue para reducir el radio de impacto
Empieza pequeño y luego amplia:
- Piloto: un equipo o un segmento (p. ej., solo SMB leads)
- Acciones limitadas: inicia con “actualizaciones sugeridas” que requieren aprobación antes de escribir en el CRM
- Subida gradual: aumenta el volumen de registros y luego habilita escrituras automáticas para campos de bajo riesgo
Define métricas de éxito antes de comenzar (precisión de match, tasa de aprobación, reducción de ediciones manuales y tiempo hasta enriquecer).
Documenta flujos y checklist de integración
Crea docs breves para usuarios e integradores (link desde tu área de producto o /pricing si limitas funciones). Incluye una checklist de integración:
- Método de auth de la API, límites de tasa y comportamiento de reintentos
- Campos requeridos para requests de enriquecimiento
- Webhooks/payloads de eventos (y versionado)
- Códigos de error y reglas de “enriquecimiento parcial”
- Expectativas de logs de auditoría y retención de datos
Para la mejora continua, programa una revisión ligera: analiza validaciones fallidas, anulaciones manuales frecuentes y desajustes, luego actualiza reglas y añade tests.
Una referencia práctica para endurecer reglas: /blog/data-quality-checklist.
Construir vs acelerar: nota práctica
Si ya conoces tus flujos objetivo pero quieres acortar el tiempo desde la especificación hasta una app funcional, considera usar Koder.ai para generar una implementación inicial (UI en React, servicios en Go, almacenamiento en PostgreSQL) a partir de un plan estructurado por chat.
Los equipos usan este enfoque para montar la UI de revisión, el procesamiento de jobs y el historial de auditoría rápidamente —luego iteran con modo de planificación, snapshots y rollback según evolucionan los requisitos. Cuando necesitas control total, puedes exportar el código fuente y continuar en tu pipeline existente. Koder.ai ofrece planes free, pro, business y enterprise, que ayudan a equilibrar experimentación y producción.