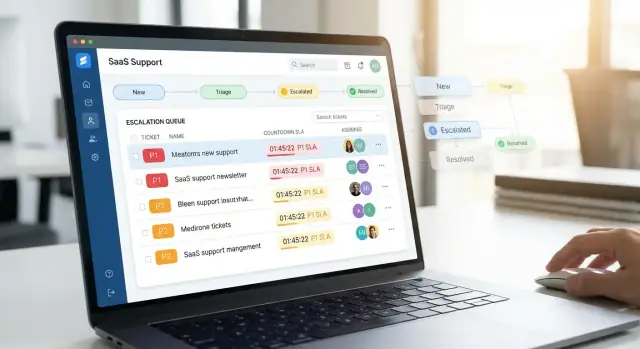
Aclara el flujo de escalación y los objetivos
Antes de crear pantallas o escribir código, decide para qué sirve tu app y qué comportamiento debe imponer. Las escalaciones no son solo “clientes enfadados”: son tickets que requieren manejo más rápido, mayor visibilidad y coordinación más estricta.
¿Qué cuenta como una escalación?
Define criterios de escalación en lenguaje claro para que agentes y clientes no tengan que adivinar. Disparadores comunes incluyen:
- Una interrupción o degradación severa
- Un cliente VIP o con contrato de “soporte prioritario”
- Un incumplimiento inminente del SLA (o incumplimientos repetidos)
- Un problema que afecta a seguridad, facturación o aspectos legales
También define qué no es una escalación (por ejemplo, preguntas de uso, solicitudes de función, bugs menores) y cómo deben enrutarse esas solicitudes.
Roles y responsabilidades
Enumera los roles que necesita tu flujo y lo que puede hacer cada uno:
- Agente: triage y resolución, actualiza el ticket, sigue playbooks
- Líder: revisa escalaciones, reasigna trabajo, aprueba cambios de prioridad
- Manager: responsable de reportes, estándares de comunicación con clientes, política de escalaciones
- On-call: recibe alertas urgentes y toma la propiedad inmediata fuera de horario
- Administrador del cliente: envía y sigue tickets, añade stakeholders internos
Anota quién es propietario del ticket en cada paso (incluyendo los traspasos) y qué significa “ser propietario” (requisito de respuesta, próxima hora de actualización y autoridad para escalar).
Canales para soportar primero
Comienza con un conjunto pequeño de entradas para poder lanzar antes y mantener el triage consistente. Muchos equipos empiezan con correo + formulario web, y luego añaden chat una vez que los SLA y el enrutamiento están estables.
Objetivos y métricas de éxito
Elige resultados medibles que la app deba mejorar:
- Tiempo de primera respuesta (global y para escalaciones)
- Tiempo de resolución o tiempo hasta mitigación para incidentes
- Tasa de re-apertura y número de “pinged for update”
- Tasa de SLA incumplidos y tiempo que el ticket pasó sin propietario
Estas decisiones se convierten en los requisitos de producto para el resto del desarrollo.
Diseña el modelo de datos para tickets, SLA y escalaciones
Una app de soporte prioritario vive o muere por su modelo de datos. Si aciertas la base, el enrutamiento, los reportes y la aplicación de SLA serán más simples — porque el sistema tendrá los hechos necesarios.
Comienza con lo “básico” del ticket (lo que los agentes siempre deben saber)
Como mínimo, cada ticket debería capturar: solicitante (un contacto), empresa (cuenta cliente), asunto, descripción y adjuntos. Trata la descripción como la declaración original del problema; las actualizaciones posteriores pertenecen a los comentarios para que puedas ver cómo evolucionó la historia.
Añade campos específicos de escalación (qué hace esto “prioritario”)
Las escalaciones necesitan más estructura que el soporte general. Campos comunes incluyen severidad (qué tan grave), impacto (cuántos usuarios/qué ingresos), y prioridad (qué tan rápido responderás). Añade un campo servicio afectado (p. ej., Facturación, API, App Móvil) para que el triage pueda enrutar rápido.
Para los plazos, almacena tiempos de vencimiento explícitos (como “primera respuesta debida” y “resolución/próxima actualización debida”), no solo un “nombre de SLA”. El sistema puede calcular estos timestamps, pero los agentes deberían ver las horas exactas.
Modela relaciones para trabajo real
Un modelo práctico suele incluir:
- Clientes → muchos Contactos
- Clientes → muchos Tickets
- Tickets → muchos Comentarios (internos + públicos)
- Tickets → muchas Tareas (checklists, seguimientos)
Esto mantiene la colaboración limpia: conversaciones en comentarios, acciones en tareas y propiedad en el ticket.
Define estados (y mantenlos consistentes)
Usa un conjunto pequeño y estable de estados como: New, Triaged, In Progress, Waiting, Resolved, Closed. Evita estados que sean “prácticamente iguales”: cada estado extra complica los reportes y la automatización.
Decide qué debe ser inmutable para auditoría
Para el seguimiento de SLA y la rendición de cuentas, algunos datos deberían ser append-only: timestamps de creación/actualización, historial de cambios de estado, eventos de inicio/parada de SLA, cambios de escalación y quién hizo cada cambio. Prefiere un registro de auditoría (o tabla de eventos) para poder reconstruir lo ocurrido sin conjeturas.
Establece niveles de prioridad y reglas de SLA
La prioridad y las reglas de SLA son el “contrato” que tu app aplica: qué se atiende primero, con qué rapidez y quién es responsable. Mantén el esquema simple, documentado claramente y difícil de anular sin una razón.
Un esquema simple de prioridad (P1–P4)
Usa cuatro niveles para que los agentes clasifiquen rápido y los managers reporten de forma consistente:
- P1 — Outage crítico / impacto severo: El producto está caído, hay pérdida de datos o se sospecha incidente de seguridad. Muchos usuarios o toda una cuenta cliente están bloqueados.
- P2 — Degradación mayor: Funciones clave parcialmente rotas, soluciones parciales limitadas y alto impacto en el negocio pero no total.
- P3 — Incidente estándar: Afecta a un único usuario o a una función no crítica. Existe una solución temporal. Muchos tickets deberían caer aquí.
- P4 — Baja urgencia / solicitudes: Preguntas de uso, bugs menores, solicitudes de funciones, consultas de facturación que no bloquean el uso.
Define “impacto” (cuántos usuarios/clientes) y “urgencia” (qué tan sensible al tiempo) en la UI para reducir errores de etiquetado.
Define SLA por plan, nivel del cliente y prioridad
Tu modelo de datos debería permitir que los SLA varíen según plan/nivel del cliente (p. ej., Free/Pro/Enterprise) y prioridad. Normalmente controlas al menos dos temporizadores:
- SLA de primera respuesta (tiempo para reconocer y comenzar a gestionar)
- SLA de resolución o SLA de próxima actualización (tiempo para resolver o dar una actualización significativa)
Ejemplo: Enterprise + P1 podría requerir primera respuesta en 15 minutos, mientras que Pro + P3 podría ser 8 horas hábiles. Mantén la tabla de reglas visible para los agentes y enlázala desde la página del ticket.
Horario laboral, 24/7 y calendarios de festivos
Los SLA de soporte a menudo dependen de si el plan incluye cobertura 24/7.
- Para SLA en horario laboral, almacena un calendario de trabajo (zona horaria, días, hora de inicio/fin).
- Para SLA 24/7, el reloj siempre corre.
- Añade un calendario de festivos (por región si hace falta) para que los temporizadores no “incumplan” en días en que nadie espera trabajar.
Muestra en el ticket tanto “SLA restante” como el calendario que se está usando (para que los agentes confíen en el temporizador).
Pausas de SLA, “esperando al cliente” y manejo de incumplimientos
Los flujos reales necesitan pausas. Una regla común: pausar el SLA cuando el ticket está Waiting on customer (o Waiting on third party), y reanudar cuando el cliente responde.
Sé explícito sobre:
- Qué estados pausan qué temporizadores de SLA
- Si las pausas aplican al SLA de respuesta, al de resolución o a ambos
- Qué sucede cuando ocurre un incumplimiento (p. ej., autoescalar prioridad, paginar on-call, notificar a un manager, etiquetar el ticket “SLA Breached”)
Evita incumplimientos silenciosos. El manejo de incumplimientos debe crear un evento visible en el historial del ticket.
Quién recibe alertas antes y después de un incumplimiento
Define al menos dos umbrales de alerta:
- Advertencia pre-incumplimiento (p. ej., 50% y 80% del SLA consumido): notificar al propietario del ticket y al canal del equipo propietario.
- Alerta de incumplimiento: notificar on-call (para P1/P2), líder de equipo y opcionalmente customer success para cuentas de alto nivel.
Enruta las alertas según prioridad y nivel para que la gente no sea paginada por ruido P4. Si quieres más detalle, conecta esta sección con tus reglas de on-call en /blog/notifications-and-on-call-alerting.
Construye lógica de triage, enrutamiento y propiedad
El triage y el enrutamiento son donde una app de soporte prioritario o ahorra tiempo o crea confusión. La meta es simple: cada nueva solicitud debe llegar al lugar correcto rápidamente, con un propietario claro y un siguiente paso obvio.
Crea una bandeja de triage en la que los agentes confíen
Empieza con una bandeja de triage dedicada para tickets no asignados o necesitan revisión. Manténla rápida y predecible:
- Orden por defecto por señales de urgencia (prioridad, tiempo hasta SLA, nivel del cliente)
- Filtros por área de producto, región/zona horaria, canal (correo/chat/web) y cuentas “VIP”
- Una vista “Sin propietario / Sin categoría” que destaque deficiencias de calidad de datos
Una buena bandeja minimiza clics: los agentes deberían poder reclamar, re-rutar o escalar desde la lista sin abrir cada ticket.
Define reglas de enrutamiento (y mantenlas explicables)
El enrutamiento debería basarse en reglas, pero legibles por no ingenieros. Entradas comunes:
- Área de producto (seleccionada por usuario, detectada desde el formulario o inferida por etiquetas)
- Palabras clave en asunto/cuerpo (p. ej., “outage”, “invoice”, “SSO”)
- Nivel del cliente (estándar vs. prioritario)
- Región (enrutar a equipos alineados por zona horaria)
Almacena el “por qué” de cada decisión de enrutamiento (p. ej., “Coincidencia palabra clave: SSO → equipo Auth”). Eso facilita resolver disputas y mejora la formación.
Anulación manual y rutas de escalación
Incluso las mejores reglas necesitan una salida. Permite a usuarios autorizados anular el enrutamiento y activar rutas de escalación como:
Agente → Líder de equipo → On-call
Las anulaciones deben requerir una razón corta y crear una entrada de auditoría. Si luego tienes paginación on-call, enlaza las acciones de escalación a ella (ver /blog/notifications-and-on-call-alerting).
Desduplicar y enlazar trabajo relacionado
Los tickets duplicados desperdician tiempo de SLA. Añade herramientas ligeras:
- Sugerir duplicados posibles basado en cliente + asunto similar + ventana temporal
- Permitir a los agentes enlazar tickets a un incidente padre (“related to INC-123”)
Los tickets enlazados deben heredar actualizaciones de estado y mensajes públicos del padre.
Reglas de propiedad: un nombre, una cola
Define estados de propiedad claros:
- Asignado único (una persona responsable)
- Cola de equipo (sin asignar dentro de un equipo; usar cuando los traspasos son frecuentes)
- Handoff (transferencia explícita con notas y un nuevo checkpoint de SLA si procede)
Haz la propiedad visible en todas partes: vista de lista, cabecera del ticket y registro de actividad. Cuando alguien pregunte “¿Quién tiene esto?”, la app debe responder al instante.
Crea un panel de soporte que los agentes usen rápido
Una app de soporte prioritario se gana o pierde en los primeros 10 segundos que un agente pasa en ella. El panel debe responder tres preguntas inmediatamente: qué necesita atención ahora, por qué y qué puedo hacer a continuación.
Vistas clave que los agentes realmente usan
Comienza con un pequeño conjunto de vistas de alto valor en vez de un laberinto de pestañas:
- Cola (worklist): la vista por defecto con filtros por prioridad, estado de SLA, canal, área de producto y asignado.
- Detalle del ticket: abrir con un clic, con contexto y acciones sobre la línea superior.
- Perfil del cliente: vista compacta de nivel, escalaciones recientes, incidentes activos y contactos clave.
- Panel de SLA: vista basada en tiempo que resalta lo que vencerá pronto, no solo lo que ya está atrasado.
Señales visuales que reducen la carga cognitiva
Usa señales claras y consistentes para que los agentes no tengan que “leer” cada fila:
- Chips de prioridad (P1–P4) con color + texto accesible (nunca solo color).
- Cuenta regresiva de SLA (p. ej., “45m para primera respuesta”) e indicador de “riesgo de incumplimiento”.
- Insignias de bloqueador (Waiting on customer, Waiting on engineering, Needs approval) para que el trabajo atascado sea visible.
Mantén la tipografía simple: un color de acento primario y una jerarquía clara (título → cliente → estado/SLA → última actualización).
Acciones rápidas y velocidad de triage
Cada fila de ticket debe soportar acciones rápidas sin abrir la página completa:
- Asignar / reasignar, escalar, cambiar prioridad, solicitar información, marcar bloqueador, añadir nota interna.
Añade acciones masivas (asignar, cerrar, aplicar etiqueta, establecer bloqueador) para limpiar backlogs rápidamente.
Teclado, accesibilidad y “sin sorpresas”
Soporta atajos de teclado para usuarios avanzados: / para buscar, j/k para moverse, e para escalar, a para asignar, g luego q para volver a la cola.
Para accesibilidad, asegura contraste suficiente, estados de foco visibles, controles con etiquetas y texto amigable para lectores de pantalla (p. ej., “SLA: 12 minutos restantes”). También haz la tabla responsiva para que el mismo flujo funcione en pantallas pequeñas sin ocultar campos críticos.
Notificaciones y paginación on-call
Planifica SLAs y responsabilidades
Usa Planning Mode para mapear roles, estados y reglas de SLA antes de generar el código.
Las notificaciones son el “sistema nervioso” de una app de soporte prioritario: convierten cambios de ticket en acción oportuna. La meta no es notificar más, sino notificar a las personas correctas, por el canal correcto y con suficiente contexto para responder.
Mapea los tipos de notificación
Comienza con un conjunto claro de eventos que disparan mensajes. Tipos comunes y de alto valor incluyen:
- Asignación: ticket asignado o reasignado a agente/equipo
- Mención: alguien @menciona a un agente en una nota interna
- Advertencia de SLA: un ticket se acerca a objetivos de primera respuesta o resolución
- Incumplimiento de SLA: se ha perdido un objetivo (con razón si se conoce)
- Escalada: aumenta la prioridad, se añade un ejecutivo/cliente o se declara un incidente
Cada mensaje debe incluir ID del ticket, nombre del cliente, prioridad, propietario actual, temporizadores SLA y un deep link al ticket.
Elige canales sin perder control
Usa notificaciones in-app para el trabajo diario y correo electrónico para actualizaciones duraderas y entregas. Para escenarios reales de on-call, añade SMS/push como canal opcional reservado para eventos urgentes (como una escalación P1 o un incumplimiento inminente).
Prevén la fatiga por alertas
La fatiga por alertas mata el tiempo de respuesta. Añade controles como agrupamiento, horas de silencio y deduplicación:
- Agrupa advertencias de SLA repetidas en un único hilo
- Deduplica ráfagas de “cambio de asignación” en una ventana corta
- Respeta horas silenciosas con una anulación para incidentes críticos
Plantillas + historial de entrega
Proporciona plantillas para actualizaciones hacia clientes y notas internas para que el tono y la completitud sean consistentes. Rastrea el estado de entrega (enviado, entregado, fallido) y mantiene una línea de tiempo de notificaciones por ticket para auditoría y seguimientos. Una pestaña simple de “Notificaciones” en el detalle del ticket facilita esta revisión.
Página de detalle del ticket: colaboración y comunicación
La página de detalle es donde el trabajo de escalación ocurre realmente. Debe ayudar a los agentes a entender el contexto en segundos, coordinar con compañeros y comunicarse con el cliente sin errores.
Separa lo que ve el cliente de lo que permanece interno
Haz que el editor elija explícitamente Respuesta al cliente o Nota interna, con estilos distintos y una vista previa clara. Las notas internas deben soportar formato rápido, enlaces a runbooks y etiquetas privadas (p. ej., “needs engineering”). Las respuestas al cliente deben venir por defecto con una plantilla amistosa y mostrar exactamente lo que se enviará.
Conversación en hilos + adjuntos seguros
Soporta un hilo cronológico que incluya correos, transcripciones de chat y eventos del sistema. Para adjuntos, prioriza la seguridad:
- Escaneo antivirus y listas blancas de tipos de archivo
- Límites de tamaño y enlaces de descarga con caducidad
- Advertencias de redacción para datos sensibles (tokens, contraseñas)
Si muestras archivos proporcionados por el cliente, deja claro quién los subió y cuándo.
Macros, respuestas rápidas y pasos guardados
Añade macros que inserten respuestas preaprobadas y checklists de diagnóstico (p. ej., “recoger logs”, “pasos de reinicio”, “texto para status page”). Permite que los equipos mantengan una librería compartida de macros con control de versiones para que las escalaciones sean consistentes y cumplidoras.
Una línea de tiempo de eventos clave
Además de los mensajes, muestra una línea de tiempo compacta de eventos: cambios de estado, actualizaciones de prioridad, pausas/resumen de SLA, transferencias de asignado y cambios de nivel de escalación. Esto evita idas y vueltas preguntando “¿qué cambió?” y ayuda en revisiones post-incidente.
Herramientas de colaboración que no generan ruido
Habilita @menciones, seguidores y tareas enlazadas (ticket de ingeniería, doc del incidente). Las menciones deben notificar solo a las personas pertinentes y los seguidores deben recibir resúmenes cuando el ticket cambie de forma material—no con cada pulsación de tecla.
Seguridad, privacidad y permisos
Inicia la pila central
Genera un panel en React con backend en Go y PostgreSQL a partir de un chat simple.
La seguridad no es una característica “para después” en una app de escalaciones: las escalaciones suelen contener correos, capturas, logs y notas internas. Construye guardarraíles temprano para que los agentes puedan moverse rápido sin sobrecompartir datos ni perder confianza.
Control de acceso por roles (RBAC) que refleje el trabajo real de soporte
Comienza con un conjunto pequeño de roles que puedas explicar en una frase (por ejemplo: Agent, Team Lead, On-Call Engineer, Admin). Luego define qué puede ver, editar, comentar, reasignar y exportar cada rol.
Un enfoque práctico es “denegar por defecto”:
- Visibilidad de escalaciones: restringe por equipo, cola y cuenta cliente (p. ej., solo agentes de la cola Enterprise abren escalaciones Enterprise).
- Derechos de edición: permite a agentes actualizar estado y añadir notas, pero limita cambios de SLA, anulaciones de prioridad y cancelaciones de escalación a líderes/admins.
- Campos sensibles: trata PII del cliente (email, teléfono), logs de seguridad y adjuntos como permisos separados.
Privacidad por diseño: mínimos privilegios por defecto
Recopila solo lo que el flujo necesita. Si no necesitas cuerpos completos de mensajes o direcciones IP completas, no las almacenes. Cuando guardes datos de clientes, deja claro qué campos son obligatorios vs. opcionales y evita copiar datos desde otros sistemas salvo que haya una razón.
Para patrones de acceso, asume “los agentes deben ver lo mínimo necesario para resolver el ticket”. Usa scope por cuenta y por cola antes de añadir reglas complejas.
Protege lo básico: autenticación, sesiones y CSRF
Usa autenticación probada (SSO/OIDC si es posible), exige contraseñas fuertes cuando se usen y soporta MFA para roles elevados.
Fortalece sesiones:
- Cookies Secure y HttpOnly; vidas de sesión cortas para acciones administrativas
- Rotación en login y cambios de privilegios
- Protección CSRF para solicitudes que cambien estado
Secretos, registros de auditoría y acceso a datos sensibles
Almacena secretos en un gestor administrado (no en control de versiones). Registra accesos a datos sensibles (quién vio una escalación, quién descargó un adjunto, quién exportó un ticket) y haz los logs de auditoría difíciles de manipular y buscables.
Retención y exportaciones (sin prometer de más)
Define reglas de retención para tickets, adjuntos y logs de auditoría (p. ej., borrar adjuntos tras N días, retener logs de auditoría por más tiempo). Ofrece exportaciones para clientes o reportes internos, pero evita afirmar certificaciones de cumplimiento específicas a menos que puedas verificarlas. Un flujo simple de “exportar datos” y un workflow admin-only de “solicitud de borrado” es un buen comienzo.
Elige un stack técnico y arquitectura
Tu app de escalaciones solo será efectiva si es fácil de cambiar. Las reglas de escalación, los SLA y las integraciones evolucionan constantemente, así que prioriza un stack que tu equipo pueda mantener y para el que puedas contratar.
Elige un stack que encaje con tu equipo
Elige herramientas familiares antes que “perfectas”. Algunas combinaciones comunes y probadas:
- React + Node.js (Express/NestJS): bueno si quieres un dashboard muy interactivo y mucha UI en tiempo real.
- Django (Python): gran tooling admin, desarrollo CRUD rápido, excelente para apps con flujos de trabajo.
- Rails (Ruby): excelentes convenciones para construir productos tipo ticketing rápidamente.
Si ya tenéis un monolito, coincidir con ese ecosistema reduce onboarding y complejidad operativa.
Si quieres moverte rápido sin un gran build, también puedes prototipar (y iterar) el flujo en una plataforma low-code como Koder.ai—especialmente para piezas estándar como un dashboard React, un backend Go/PostgreSQL y la lógica de SLA/notificaciones basada en jobs.
Almacenamiento de datos: relacional primero, búsqueda donde ayude
Para registros core—tickets, clientes, SLA, eventos de escalación, asignaciones—usa una base relacional (Postgres es una opción común). Te da transacciones, constraints y consultas amigables para reportes.
Para búsquedas rápidas sobre asuntos, texto de conversaciones y nombres de cliente, considera añadir un índice de búsqueda después (p. ej., Elasticsearch/OpenSearch). Manténlo opcional: empieza con full-text search en Postgres y escala si lo necesitas.
Trabajos en background son innegociables
Las apps de escalación dependen de trabajo basado en tiempo e integraciones que no deben ejecutarse en una petición web:
- Temporizadores de SLA y comprobaciones de incumplimiento
- Notificaciones (email/SMS/push)
- Paginación on-call
- Sincronización de mensajes desde email/chat/CRM
Usa una cola de jobs (p. ej., Celery, Sidekiq, BullMQ) y haz los jobs idempotentes para que los reintentos no creen alertas duplicadas.
Define APIs temprano y mantenlas consistentes
REST o GraphQL, define los límites de recursos desde el principio: tickets, comentarios, eventos, clientes y usuarios. Un estilo de API consistente acelera integraciones y la UI. Planifica webhooks desde el inicio (firma, reintentos y límites de tasa).
Hosting y entornos
Corre al menos dev/staging/prod. Staging debe replicar ajustes de prod (proveedores de correo, colas, webhooks) con credenciales de prueba seguras. Documenta despliegues y pasos de rollback, y guarda la configuración en variables de entorno, no en código.
Integraciones: correo, chat, CRM y webhooks
Las integraciones convierten tu app de “otro sitio más” en el sistema donde el equipo realmente trabaja. Comienza con los canales que usan los clientes y añade hooks de automatización para que otras herramientas reaccionen a eventos de escalación.
Correo: parsing entrante, envío saliente, threading
El correo suele ser la integración de mayor impacto. Soporta reenvío entrante (p. ej., support@) y parsea:
- From/To/Cc, asunto, cuerpo (prefiere texto plano como fallback) y adjuntos
- Message-ID e In-Reply-To para mantener el threading
- Dominio del cliente y pistas de firma para descubrir contactos
Para envío saliente, responde desde el ticket y preserva headers de threading para que las respuestas vuelvan al mismo ticket. Guarda una línea de tiempo limpia: muestra lo que el cliente vio, no las notas internas.
Herramientas de chat (opcionales): convertir mensajes en tickets
Para chat (Slack/Teams/widgets tipo intercom), mantenlo simple: convierte una conversación en un ticket con transcripción y participantes claros. Evita sincronizar cada mensaje por defecto: ofrece un botón “Adjuntar últimos 20 mensajes” para que los agentes controlen el ruido.
El sync con CRM hace automático el “soporte prioritario”. Trae empresa, plan/nivel, owner de cuenta y contactos clave. Mapea cuentas CRM a tus tenants para que nuevos tickets hereden reglas de prioridad inmediatamente.
Webhooks para eventos clave
Proporciona webhooks para eventos como ticket.escalated, ticket.resolved y sla.breached. Incluye un payload estable (ID del ticket, timestamps, severidad, ID del cliente) y firma las peticiones para que los receptores verifiquen autenticidad.
Documenta y simplifica la configuración
Añade un pequeño flujo admin con botones de prueba (“Enviar email de prueba”, “Verificar webhook”). Mantén la documentación en un lugar (p. ej., /docs/integrations) y muestra pasos comunes de resolución (problemas SPF/DKIM, headers de threading faltantes, mapeo de campos CRM).
Testing, monitorización y fiabilidad
Convierte los SLAs en código
Implementa prioridades P1-P4, horario comercial y estados de pausa con lógica clara y verificable.
Una app de soporte prioritario se convierte en “fuente de la verdad” en momentos tensos. Si los temporizadores SLA se desvían, el enrutamiento falla o los permisos filtran datos, la confianza se evapora. Trata la fiabilidad como una característica: prueba lo importante, mide lo que ocurre y planea fallos.
Testea las reglas que impulsan la urgencia
Enfoca tests automatizados en la lógica que cambia resultados:
- Cálculos de SLA: condiciones de inicio/parada, horario laboral, pausas, umbrales de incumplimiento y timestamps de “próximo vencimiento”.
- Enrutamiento y propiedad: reglas de triage, asignación round-robin/por habilidad y triggers de escalación.
- Permisos: control RBAC para colas, detalles de ticket, notas internas y mensajes visibles al cliente.
Añade una pequeña suite end-to-end que mime el flujo de un agente (crear ticket → triage → escalar → resolver) para atrapar suposiciones rotas entre UI y backend.
Datos semilla y escenarios realistas
Crea datos semilla útiles más allá de demos: algunos clientes, múltiples niveles (estándar vs. prioritario), prioridades variadas y tickets en distintos estados. Incluye casos difíciles como tickets reabiertos, “waiting on customer” y múltiples asignados. Esto hace que la práctica de triage sea significativa y ayuda a QA a reproducir edge cases.
Observabilidad: saber antes que los clientes te lo digan
Instrumenta la app para que puedas responder: “¿Qué falló, para quién y por qué?”
- Tracking de errores en trabajos de SLA/enrutamiento
- Logs estructurados con ID de ticket, ID de regla y correlation IDs
- Monitorización de rendimiento en páginas críticas y workers en background
Pruebas de carga y recuperación segura
Realiza pruebas de carga en vistas de alto tráfico como colas, búsqueda y paneles—especialmente en cambios de turno.
Finalmente, prepara tu propio playbook de incidentes: feature flags para reglas nuevas, pasos de rollback de migraciones y un procedimiento claro para desactivar automatizaciones mientras los agentes siguen trabajando.
Plan de lanzamiento, reportes e iteración
Una app de soporte prioritario está “lista” solo cuando los agentes confían en ella bajo presión. La mejor manera de llegar allí es lanzar pequeño, medir lo que realmente ocurre e iterar en ciclos cortos.
Empieza con un MVP que pruebe el flujo
Resiste la tentación de lanzar todas las funcionalidades. Tu primer lanzamiento debe cubrir el camino más corto desde “nueva escalación” hasta “resuelta con responsabilidad”:
- Una cola de triage con orden claro (prioridad, vencimiento de SLA, nivel del cliente)
- Página de detalle de ticket que permita actualizaciones rápidas y notas internas
- Temporizadores SLA visibles (primera respuesta y resolución/próxima actualización si aplica)
- Alertas básicas por incumplimiento inminente y cambios de estado
Si usas Koder.ai, esta forma de MVP mapea bien a sus defaults comunes (UI React, servicios Go, PostgreSQL), y la capacidad de snapshot/rollback puede ser útil mientras ajustas la matemática de SLA, reglas de enrutamiento y límites de permisos.
Piloto con un equipo pequeño y revisa semanalmente
Despliega a un grupo piloto (una región, una línea de producto o una rotación on-call) y realiza una revisión semanal de feedback. Mantén la estructura: qué ralentizó a los agentes, qué datos faltaron, qué alertas eran ruidosas y dónde falló la gestión de escalaciones (traspasos, propiedad poco clara o tickets mal enrutados).
Una táctica práctica: mantener un changelog ligero dentro de la app para que los agentes vean mejoras y sientan que se les escucha.
Añade reportes que impulsen acción, no vanidad
Cuando tengas uso consistente, introduce reportes que respondan preguntas operativas:
- Cumplimiento de SLA: tasa de incumplimiento por prioridad, nivel de cliente y canal
- Volumen de escalaciones: tendencias y picos tras releases
- Principales causas: etiquetas/razones correlacionadas con escalaciones
- Carga por agente: tickets abiertos por agente y tiempo hasta primer contacto
Estos reportes deben ser fáciles de exportar y de explicar a stakeholders no técnicos.
Itera sobre reglas y macros usando resultados reales
Las reglas de enrutamiento y triage estarán equivocadas al principio—y eso es normal. Afina reglas de triage según misrutas, tiempos de resolución y feedback de on-call. Haz lo mismo con macros y respuestas guardadas: elimina las que no reducen tiempo y mejora las que mejoran la comunicación y claridad del incidente.
Publica una hoja de ruta simple y recursos de ayuda
Mantén la hoja de ruta corta y visible dentro del producto (“Próximos 30 días”). Enlaza contenidos de ayuda y FAQs para que la formación no sea conocimiento tribal. Si mantienes info pública, hazla fácil de encontrar mediante links internos como /pricing o /blog para que los equipos se auto-servicio y consulten mejores prácticas.