Antes de bosquejar pantallas o elegir una base de datos, aclara para qué sirve la aplicación, quién dependerá de ella y cómo se ve el “éxito”. Las apps de puntuación de proveedores fallan con mayor frecuencia cuando intentan satisfacer a todos a la vez, o cuando no pueden responder preguntas básicas como “¿qué proveedor estamos evaluando realmente?”
Objetivos, usuarios y alcance
Quién la usa (y qué necesitan)
Empieza nombrando tus grupos de usuarios primarios y sus decisiones del día a día:
- Compras necesita una ficha de proveedor consistente, vistas comparativas entre proveedores y una trazabilidad defendible para decisiones de contratación.
- Finanzas le interesa la variación de costes, el cumplimiento de condiciones de pago y señales de riesgo que afecten previsiones.
- Operaciones quiere resolución rápida de incidencias: seguimiento de incidentes, documentación de acciones correctivas y ver si el desempeño está mejorando.
- Proveedores (portal opcional) quieren visibilidad de la retroalimentación, una forma de responder y claridad sobre cómo se calculan las puntuaciones.
Un truco útil: elige un “usuario core” (a menudo compras) y diseña la primera versión en torno a su flujo de trabajo. Añade al siguiente grupo solo cuando puedas explicar qué capacidad nueva desbloquea.
Resultados clave que buscas
Escribe resultados como cambios medibles, no como características. Resultados comunes incluyen:
- Mejores decisiones sobre proveedores (p. ej., listas de proveedores preferidos basadas en evidencia, no en anécdotas)
- Resolución de problemas más rápida (propiedad clara, plazos y seguimientos)
- Evaluaciones más consistentes (menos variación entre evaluadores o sitios)
Estos resultados guiarán más tarde tu seguimiento de KPI y las elecciones de reporting.
Define qué significa “proveedor” en tu sistema
“Proveedor” puede significar cosas distintas según la estructura de tu org y los contratos. Decide pronto si un proveedor es:
- una entidad legal (empresa matriz)
- un sitio/ubicación (útil cuando la calidad varía por planta o región)
- una línea de servicio (p. ej., logística vs embalaje del mismo proveedor)
Tu elección afecta todo: agregados de puntuación, permisos e incluso si una mala instalación debería afectar la relación global.
Elige el enfoque de puntuación
Hay tres patrones comunes:
- KPI ponderados: entradas numéricas (%, tasa de defectos) multiplicadas por pesos. Excelente para transparencia y automatización.
- Rúbricas: los revisores seleccionan niveles (p. ej., “Excelente/Bueno/Regular/Malo”) con textos guía. Excelente cuando los datos son cualitativos.
- Híbrido: KPI para áreas medibles + rúbrica para colaboración, capacidad de respuesta o encaje estratégico.
Haz que el método de puntuación sea lo bastante comprensible para que un proveedor (y un auditor interno) pueda seguirlo.
Define métricas de éxito para la app
Finalmente, elige algunas métricas de éxito a nivel de aplicación para validar adopción y valor:
- Adopción: % de proveedores activos con al menos una reseña en el último trimestre
- Completitud de reseñas: campos obligatorios llenos, evidencias adjuntas, KPIs proporcionados
- Tiempo de ciclo: tiempo desde que se abre la reseña → aprueba → comparte con el proveedor (si aplica)
Con objetivos, usuarios y alcance definidos tendrás una base estable para el modelo de puntuación y el diseño de flujo de trabajo que siguen.
Modelo de puntuación y diseño de KPI
Una app de puntuación de proveedores vive o muere según si la puntuación refleja la experiencia real. Antes de construir pantallas, escribe los KPI exactos, escalas y reglas para que compras, operaciones y finanzas interpreten los resultados de la misma manera.
Elige un conjunto pequeño y defendible de KPI
Empieza con un núcleo que la mayoría de los equipos reconozca:
- Entrega a tiempo (p. ej., % de envíos dentro de la ventana acordada)
- Calidad (tasa de defectos, tasa de devoluciones o % de inspecciones aprobadas)
- Cumplimiento de SLA (tickets resueltos dentro del tiempo objetivo, disponibilidad si aplica)
- Variación de coste (factura vs PO, cargos no planificados)
- Capacidad de respuesta (tiempo a primera respuesta, tiempo a resolución para escaladas)
Mantén definiciones medibles y asocia cada KPI a una fuente de datos o una pregunta de revisión.
Define escalas que la gente pueda explicar
Elige 1–5 (fácil para humanos) o 0–100 (más granular) y luego define qué significa cada nivel. Por ejemplo, “Entrega a tiempo: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%.” Umbrales claros reducen disputas y hacen las revisiones comparables entre equipos.
Pesos, datos faltantes y reglas de equidad
Asigna pesos por categoría (p. ej., Entrega 30%, Calidad 30%, SLA 20%, Coste 10%, Capacidad de respuesta 10%) y documenta cuándo cambian los pesos (diferentes tipos de contrato pueden priorizar resultados distintos).
Decide cómo manejar datos faltantes:
- Excluir el KPI del denominador para ese periodo, o
- Aplicar un valor por defecto neutral, o
- Marcar la puntuación como “datos insuficientes” y bloquear el ranking.
Sea lo que sea, aplícalo de forma consistente y muéstralo en vistas detalladas para que los equipos no interpreten “faltante” como “bueno”.
Múltiples fichas por proveedor
Soporta más de una ficha por proveedor para que los equipos puedan comparar rendimiento por contrato, región o periodo. Así evitas promediar problemas que están aislados a un sitio o proyecto.
Disputas y correcciones
Documenta cómo afectan las disputas a las puntuaciones: si una métrica puede corregirse retroactivamente, si una disputa marca temporalmente la puntuación y qué versión se considera “oficial”. Incluso una regla simple como “las puntuaciones se recalculan cuando se aprueba una corrección, con una nota que explica el cambio” evita confusiones posteriores.
Modelo de datos y esquema básico
Un modelo de datos limpio mantiene la puntuación justa, las reseñas trazables y los informes creíbles. Quieres responder preguntas sencillas con fiabilidad—“¿Por qué este proveedor obtuvo un 72 este mes?” y “¿Qué cambió desde el último trimestre?”—sin conjeturas ni hojas de cálculo manuales.
Entidades centrales (qué almacenar)
Como mínimo, define estas entidades:
- Vendor: perfil del proveedor (nombre, estado, categoría, contactos)
- Contract: detalles del acuerdo comercial y ventanas de validez
- Order/Invoice (o una Transaction unificada): hechos operativos que impulsan los KPI
- KPI Metric: definiciones como % de entrega a tiempo, tasa de defectos, tiempo de respuesta
- Score: resultado calculado para un proveedor en un periodo (global y/o por métrica)
- Review: retroalimentación cualitativa, calificaciones y evidencias narrativas
- Attachment: archivos vinculados a reseñas o disputas (emails, fotos, PDFs)
Este conjunto soporta tanto el rendimiento “duro” medido como la retroalimentación “blanda”, que normalmente requieren flujos de trabajo distintos.
Modela las relaciones explícitamente:
- Vendor → Contracts: un proveedor puede tener múltiples contratos a lo largo del tiempo.
- Vendor → Orders/Invoices: las transacciones suelen ser muchos-a-uno respecto al proveedor.
- Score → Metric: las puntuaciones deben ser trazables hasta la definición de la métrica y la versión de cálculo.
- Review → Period: las reseñas necesitan una ventana temporal clara (mes/trimestre) para que no queden sin contexto.
Un enfoque común es:
scorecard_period (p. ej., 2025-10)vendor_period_score (global)vendor_period_metric_score (por métrica, incluye numerador/denominador si aplica)
Campos que agradecerás haber añadido
Añade campos de consistencia en la mayoría de tablas:
- Timestamps:
created_at, updated_at, y para aprobaciones submitted_at, approved_at
- Autor y actor:
created_by_user_id, además de approved_by_user_id donde corresponda
- Sistema origen:
source_system e identificadores externos como erp_vendor_id, crm_account_id, erp_invoice_id
- Confianza/calidad: una puntuación
confidence o data_quality_flag para marcar feeds incompletos o estimaciones
Estos campos alimentan auditorías, manejo de disputas y analítica de compras confiable.
Retención, versionado y “¿qué cambió?”
Las puntuaciones cambian porque los datos llegan tarde, las fórmulas evolucionan o alguien corrige un mapeo. En lugar de sobrescribir la historia, almacena versiones:
- Mantén una versión de cálculo (o
calculation_run_id) en cada fila de puntuación.
- Registra códigos de razón para la recalculación (factura tardía, actualización de definición de KPI, corrección manual).
- Considera una pista de auditoría append-only para tablas importantes (scores, reviews, approvals) para mostrar quién cambió qué y cuándo.
Para retención, define cuánto tiempo guardas transacciones crudas vs. puntuaciones derivadas. A menudo se retienen más tiempo las puntuaciones derivadas (menor almacenamiento, alto valor de reporting) y se conservan los extractos ERP crudos por una ventana de política más corta.
Estrategia de identificadores para emparejar ERP/CRM
Trata los IDs externos como campos de primera clase, no como notas:
- Guarda tanto external ID como nombre del sistema (ERP_A vs ERP_B).
- Aplica unicidad por sistema origen (p. ej.,
unique(source_system, external_id)).
- Añade tablas de mapeo ligeras cuando los proveedores se fusionan/separan para que las puntuaciones históricas sigan siendo precisas.
Este trabajo preparatorio facilita la implementación y explicación de integraciones, seguimiento de KPI, moderación de reseñas y auditabilidad.
Ingesta de datos e integraciones
Una app de puntuación de proveedores vale lo que valen sus entradas. Planifica múltiples caminos de ingestión desde el día uno, aunque empieces con uno. La mayoría de los equipos acaban necesitando mezcla de entrada manual para casos extremos, subidas masivas para datos históricos y sincronización por API para actualizaciones continuas.
Fuentes de datos comunes
Entrada manual es útil para proveedores pequeños, incidentes puntuales o cuando un equipo necesita registrar una reseña de inmediato.
Subida CSV te ayuda a arrancar el sistema con rendimiento pasado, facturas, tickets o registros de entrega. Haz las subidas previsibles: publica una plantilla y versiona el formato para que cambios no rompan importaciones silenciosamente.
Sincronización por API conecta típicamente con ERP/herramientas de compras (POs, recepciones, facturas) y sistemas de servicio como mesas de ayuda (tickets, incumplimientos de SLA). Prefiere sincronización incremental (desde el último cursor) para evitar tirar todo cada vez.
Validación que prevenga basura
Establece reglas de validación claras en el momento de la importación:
- Campos obligatorios (vendor ID, fecha, nombre/valor de métrica)
- Rangos numéricos (p. ej., puntuaciones 0–100, cantidades no negativas)
- Detección de duplicados (mismo vendor + métrica + periodo + ID de registro fuente)
Almacena filas inválidas con mensajes de error para que los administradores las corrijan y vuelvan a subir sin perder contexto.
Correcciones, backfills y registros de recalculación
Las importaciones a veces estarán mal. Soporta re-ejecuciones (idempotentes por IDs de fuente), backfills (periodos históricos) y registros de recalculación que documenten qué cambió, cuándo y por qué. Esto es crítico para la confianza cuando la puntuación de un proveedor se desplaza.
Planificación y transparencia
La mayoría de equipos funciona bien con importaciones diarias/semanales para finanzas y métricas de entrega, más eventos casi en tiempo real para incidentes críticos.
Expón una página de administración amigable (p. ej., /admin/imports) que muestre estado, conteo de filas, advertencias y errores exactos—para que los problemas sean visibles y solucionables sin ayuda de desarrolladores.
Roles, permisos y flujo de aprobación
Reglas claras y un camino de aprobación predecible evitan la “anarquía de fichas”: ediciones en conflicto, cambios de calificación sorpresivos e incertidumbre sobre qué puede ver un proveedor. Define reglas de acceso temprano y luego aplícalas de forma consistente en la UI y la API.
Tipos de roles (y para qué sirven)
Un conjunto práctico de roles de inicio:
- Admin: gestiona configuraciones de la organización, asignaciones de roles, plantillas de puntuación y reglas de moderación.
- Revisor interno: envía reseñas, evidencias y borradores de actualización de puntuaciones.
- Aprobador: valida acciones sensibles (publicar reseñas, bloquear periodos, aprobar cambios de puntuación).
- Usuario proveedor: ve su propia ficha, responde a reseñas y sube aclaraciones (si se permite).
- Solo lectura: puede ver dashboards y perfiles, pero no editar.
Permisos ligados a acciones reales
Evita permisos vagos como “puede gestionar proveedores”. Controla capacidades concretas:
- Visualización: quién puede ver reseñas, nombres de revisores, adjuntos y puntuaciones históricas.
- Edición: quién puede crear/editar borradores, cambiar valores de KPI o ajustar pesos.
- Publicación: quién puede mover contenido de borrador a visible.
- Exportación: quién puede descargar informes (CSV/PDF) y con qué alcance (un proveedor vs todos).
Considera separar “exportar” en “exportar propios proveedores” vs “exportar todo”, sobre todo para analítica de compras.
Reglas de visibilidad para proveedores
Los usuarios proveedor deberían ver típicamente solo sus propios datos: sus puntuaciones, reseñas publicadas y el estado de elementos abiertos. Limita detalles de la identidad del revisor por defecto (p. ej., mostrar departamento o rol en lugar del nombre completo) para reducir fricciones interpersonales. Si permites respuestas de proveedores, mantenlas en hilo y claramente etiquetadas como aportadas por el proveedor.
Flujos de aprobación para confianza y consistencia
Trata las reseñas y cambios de puntuación como propuestas hasta que se aprueben:
- El Revisor interno envía una reseña/borrador de actualización de puntuación.
- El Aprobador revisa evidencias, comprueba políticas y aprueba, solicita cambios o rechaza.
- Solo los elementos aprobados afectan la puntuación “actual” y se hacen visibles para los usuarios proveedor.
Los flujos con límites temporales ayudan: por ejemplo, los cambios de puntuación pueden requerir aprobación solo durante el cierre mensual/trimestral.
Requisitos de trazabilidad
Para cumplimiento y responsabilidad, registra cada evento significativo: quién hizo qué, cuándo, desde dónde y qué cambió (valores antes/después). Las entradas de auditoría deben cubrir cambios de permisos, ediciones de reseñas, aprobaciones, publicaciones, exportes y eliminaciones. Haz la pista de auditoría buscable, exportable para auditorías y protegida contra manipulaciones (almacenamiento append-only o logs inmutables).
UX y pantallas principales
Reduce el coste de tu desarrollo
Obtén créditos creando contenido sobre Koder.ai o invitando a compañeros de equipo y colaboradores.
Una app de puntuación de proveedores tiene éxito o falla según si los usuarios ocupados pueden encontrar al proveedor correcto rápido, entender la puntuación de un vistazo y dejar retroalimentación fiable sin fricción. Empieza con un conjunto pequeño de pantallas “base” y haz que cada número sea explicable.
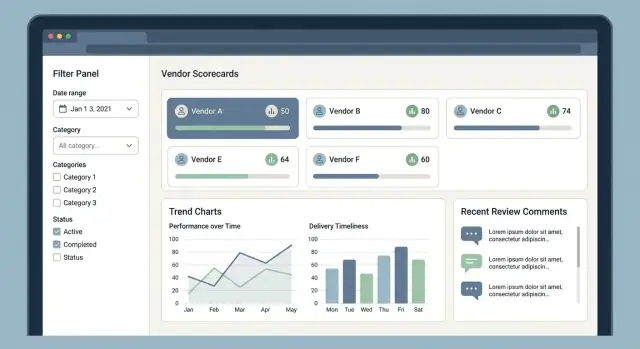
1) Lista de proveedores (el centro de comando)
Aquí comienzan la mayoría de sesiones. Mantén el diseño simple: nombre del proveedor, categoría, región, banda de puntuación actual, estado y última actividad.
El filtrado y la búsqueda deben sentirse instantáneos y previsibles:
- Categoría, región, estado (activo/en espera/bloqueado)
- Rango de fechas (p. ej., última reseña, último incidente de entrega)
- Banda de puntuación (A/B/C o rangos 0–100)
Guarda vistas comunes (p. ej., “Proveedores críticos en EMEA por debajo de 70”) para que los equipos de compras no reconstruyan filtros cada día.
2) Perfil del proveedor (una página, muchas respuestas)
El perfil debe resumir “quién es” y “cómo va”, sin forzar pestañas demasiado pronto. Pon detalles de contacto y metadatos de contrato junto a un resumen claro de la puntuación.
3) Ficha de puntuación con desglose del “por qué”
Muestra la puntuación global y el desglose por KPI (calidad, entrega, coste, cumplimiento). Cada KPI necesita una fuente visible: las reseñas, incidentes o métricas subyacentes que lo produjeron.
Un patrón útil es:
- KPI → fórmula/peso → ítems contribuyentes → evidencia (comentarios, adjuntos, timestamps)
4) Reseñas e incidencias (entrada rápida, contexto sólido)
Haz la entrada de reseñas amigable para móvil: objetivos táctiles grandes, campos cortos y comentarios rápidos. Siempre adjunta reseñas a un intervalo de tiempo y (si procede) a una orden de compra, sitio o proyecto para que la retroalimentación sea accionable.
Los informes deben responder preguntas comunes: “¿Qué proveedores están en declive?” y “¿Qué cambió este mes?” Usa gráficos legibles, etiquetas claras y navegación por teclado para accesibilidad.
Reseñas, comentarios y moderación
Las reseñas son donde la app se vuelve realmente útil: capturan contexto, evidencias y el “por qué” detrás de los números. Para mantenerlas consistentes (y defendibles), trata las reseñas como registros estructurados primero, texto libre después.
Tipos de reseñas que deberías soportar
Distintos momentos requieren plantillas distintas. Un conjunto de inicio simple:
- Reseñas periódicas (mensuales/trimestrales): cadencia para seguimiento de tendencias.
- Reseñas por incidente: vinculadas a una entrega tardía, defecto de calidad o incumplimiento.
- Reseñas de cierre de proyecto: resumen final con lecciones aprendidas.
Cada tipo puede compartir campos comunes pero permitir preguntas específicas para evitar encajar incidentes en un formulario trimestral.
Campos estructurados: haz las reseñas buscables
Junto a un comentario narrativo, incluye entradas estructuradas que impulsen filtrado e informes:
- Etiquetas y categorías (p. ej., Logística, Calidad, Comunicación)
- Fortalezas y brechas (campos separados para evitar feedback unilateral)
- Acciones con responsable, fecha de vencimiento y estado
Esta estructura convierte “feedback” en trabajo rastreable, no solo texto en un cuadro.
Manejo de evidencias (sin hacerlo doloroso)
Permite adjuntar pruebas donde se escribe la reseña:
- Archivos (fotos, PDFs)
- Enlaces a documentos compartidos
- Referencias a tickets / POs / órdenes (idealmente seleccionables de una lista)
Almacena metadatos (quién subió, cuándo, a qué se relaciona) para que las auditorías no sean una búsqueda del tesoro.
Moderación e historial de ediciones
Incluso herramientas internas necesitan moderación. Añade:
- Chequeos básicos de profanidad/spam
- Reglas de escalado para reclamaciones graves (p. ej., seguridad, fraude)
- Un historial de ediciones que registre qué cambió y quién (incluyendo redacciones)
Evita ediciones silenciosas—la transparencia protege tanto a revisores como a proveedores.
Notificaciones, recordatorios y SLAs de respuesta
Define reglas de notificación por adelantado:
- Avisar a proveedores cuando se publique una reseña (o cuando se solicite respuesta)
- Enviar recordatorios internos para acciones atrasadas
- Fijar un SLA de respuesta (p. ej., 5 días hábiles) con escalado si se incumple
Bien hecho, las reseñas se convierten en un flujo de retroalimentación cerrado en lugar de una queja puntual.
Arquitectura y elección de stack tecnológico
Asegura los permisos desde el principio
Configura RBAC y aprobaciones para que solo las puntuaciones aprobadas se vuelvan oficiales.
Tu primera decisión arquitectónica no es tanto sobre “la tecnología más nueva” como sobre cuán rápido puedes lanzar una plataforma fiable sin crear una carga de mantenimiento.
Si quieres moverte rápido, considera prototipar el flujo (proveedores → fichas → reseñas → aprobaciones → informes) en una plataforma que pueda generar una app funcional desde una especificación clara. Por ejemplo, Koder.ai es una plataforma vibe-coding donde puedes construir web, backend y apps móviles mediante una interfaz conversacional, y luego exportar el código fuente cuando estés listo para avanzar. Es una forma práctica de validar el modelo de puntuación y los roles/permisos antes de invertir mucho en UI e integraciones personalizadas.
Monolito vs servicios modulares (mantenlo simple)
Para la mayoría, un monolito modular es el punto óptimo: una app desplegable, pero organizada en módulos claros (Vendors, Scorecards, Reviews, Reporting, Admin). Obtienes desarrollo y depuración más sencillos, además de despliegues y seguridad más directos.
Pasa a servicios separados solo cuando haya una razón fuerte—p. ej., cargas pesadas de reporting, múltiples equipos de producto o requisitos estrictos de aislamiento. Un camino de evolución común es: monolito ahora, luego extraer “imports/reporting” si hace falta.
Diseño de API (REST que mapea a trabajo real)
Una API REST suele ser la más fácil de razonar e integrar con herramientas de compras. Busca recursos predecibles y algunos endpoints “task” donde el sistema haga trabajo real.
Ejemplos:
/api/vendors (crear/actualizar vendors, estado)/api/vendors/{id}/scores (puntuación actual, desglose histórico)/api/vendors/{id}/reviews (listar/crear reseñas)/api/reviews/{id} (actualizar, acciones de moderación)/api/exports (solicitar exportes; retorna job id)
Mantén operaciones pesadas (exportes, recálculos masivos) asíncronas para que la UI siga respondiendo.
Trabajos en background (imports, recálculos, notificaciones)
Usa una cola de trabajos para:
- importar datos de proveedores (CSV/SFTP/API)
- recalcular puntuaciones cuando cambian KPIs, pesos o reseñas
- enviar notificaciones (reseña solicitada, puntuación cambiada, aprobación necesaria)
Esto también te ayuda a reintentar fallos sin intervención manual.
Los dashboards pueden ser caros. Cachea métricas agregadas (por rango de fechas, categoría, unidad de negocio) e invalida en cambios significativos, o refresca en un horario. Esto mantiene el dashboard rápido sin perder datos detallados para el desglose.
Documentación (para desarrolladores y admins)
Escribe docs de API (OpenAPI/Swagger está bien) y mantiene una guía interna, amigable para administradores, en formato tipo /blog—p. ej., “Cómo funciona la puntuación”, “Cómo manejar reseñas disputadas”, “Cómo ejecutar exportes”—y enlázala desde la app en /blog para que sea fácil de encontrar y actualizar.
Seguridad, privacidad y fiabilidad
Los datos de evaluación pueden influir en contratos y reputaciones, así que necesitas controles de seguridad previsibles, auditables y fáciles de seguir para usuarios no técnicos.
Autenticación y control de acceso
Empieza con opciones de inicio de sesión apropiadas:
- Email/contraseña para equipos pequeños (usa reglas de contraseñas fuertes y MFA donde sea posible).
- SSO para empresas vía SAML u OIDC, para gestionar accesos centralmente y revocarlos rápido.
Acompaña la autenticación con RBAC: admins de compras, revisores, aprobadores y stakeholders solo lectura. Mantén permisos granulares (p. ej., “ver puntuaciones” vs “ver texto de reseñas”). Mantén una pista de auditoría para cambios de puntuación, aprobaciones y ediciones.
Protege datos sensibles
Encripta datos en tránsito (TLS) y en reposo (BD + backups). Trata secretos (contraseñas BD, claves API, certificados SSO) como primera clase:
- Guárdalos en un vault gestionado
- Rota con regularidad
- Nunca los comités en el repositorio
Prevención de abuso y endpoints seguros
Aunque tu app sea “interna”, endpoints públicos (reinicio de contraseña, links de invitación, formularios de envío de reseñas) pueden ser abusados. Añade limitación de tasa y protección contra bots (CAPTCHA o scoring de riesgo) donde proceda, y restringe APIs con tokens con alcance.
Privacidad por diseño
Las reseñas suelen contener nombres, emails o detalles de incidentes. Minimiza datos personales por defecto (campos estructurados sobre texto libre), define políticas de retención y ofrece herramientas para redactar o eliminar contenido cuando sea necesario.
Operaciones fiables sin filtrar datos
Loggea lo suficiente para depurar (request IDs, latencia, códigos de error), pero evita capturar texto confidencial de reseñas o adjuntos. Usa monitorización y alertas para imports fallidos, errores en trabajos de cálculo y patrones de acceso inusuales—sin convertir los logs en una segunda base de datos de contenido sensible.
Una app de puntuación es tan útil como las decisiones que permite. El reporting debe responder tres preguntas rápido: ¿Quién va bien, comparado con qué y por qué?
Vistas de dashboard que funcionan para stakeholders ocupados
Comienza con un dashboard ejecutivo que resuma puntuación global, cambios en la puntuación a lo largo del tiempo y un desglose por categoría (calidad, entrega, cumplimiento, coste, servicio, etc.). Las líneas de tendencia son críticas: un proveedor con puntuación algo inferior pero que mejora rápidamente puede ser mejor que un alto puntuador que está decayendo.
Haz los dashboards filtrables por periodo, unidad de negocio/sitio, categoría de proveedor y contrato. Usa valores por defecto consistentes (p. ej., “últimos 90 días”) para que dos personas viendo lo mismo obtengan respuestas comparables.
Benchmarking con controles de acceso
El benchmarking es potente—y sensible. Permite comparar proveedores dentro de la misma categoría (p. ej., “proveedores de embalaje”) mientras aplicas permisos:
- Liderazgo de compras puede ver comparaciones con nombres.
- Gerentes de sitio pueden ver solo proveedores que gestionan.
- Stakeholders generales pueden ver rankings anonimizado o cuartiles.
Así evitas divulgaciones accidentales y sigues apoyando decisiones de selección.
Los dashboards deben enlazar a informes con explicación del movimiento de la puntuación:
- Por periodo: rollups mensuales/trimestrales con deltas de KPI.
- Por sitio: resaltar problemas específicos de ubicación (entregas tardías en una planta).
- Por contrato: mostrar si el desempeño cumple SLAs y términos comerciales.
Un buen perforado termina con “qué pasó”: reseñas relacionadas, incidentes, tickets o registros de envío.
Exportes para compartir internamente
Soporta CSV para análisis y PDF para compartir. Los exportes deben reflejar filtros en pantalla, incluir un timestamp y, opcionalmente, añadir una marca de agua para uso interno (y la identidad del visor) para desincentivar el reenvío fuera de la organización.
Explicabilidad: muestra cómo se construyó la puntuación
Evita puntuaciones “caja negra”. Cada puntuación debe tener un desglose claro:
- Contribuciones de KPI (pesos, valores brutos, normalización)
- Penalizaciones/bonificaciones aplicadas (p. ej., problema crítico de cumplimiento)
- Notas de cálculo y versión (para auditar cambios en fórmulas)
Cuando los usuarios pueden ver los detalles de cálculo, las disputas se resuelven más rápido y los planes de mejora son más sencillos de acordar.
Pruebas y controles de calidad
Implementa la app principal
Genera una app web para proveedores, fichas de puntuación, revisiones e informes en un mismo lugar.
Probar una plataforma de puntuación no es solo encontrar bugs—es proteger la confianza. Los equipos de compras necesitan seguridad de que una puntuación es correcta y los proveedores necesitan garantías de que reseñas y aprobaciones se manejan consistentemente.
Crea datos de prueba que reflejen la imprevisibilidad real
Empieza creando conjuntos de datos pequeños y reutilizables que incluyan casos límite: KPIs faltantes, envíos tardíos, valores en conflicto entre importes, y disputas (p. ej., un proveedor impugna un resultado de SLA de entrega). Incluye casos donde un proveedor no tiene actividad en un periodo o donde los KPIs existen pero deben excluirse por fechas inválidas.
Verifica la lógica de puntuación con pruebas unitarias
Tus cálculos de puntuación son el corazón del producto, así que testéalos como una fórmula financiera:
- Reglas de ponderación (incluyendo pesos que no suman 100% y cómo se maneja)
- Comportamiento de redondeo y empates en ranking
- Umbrales (p. ej., cuándo un KPI pasa de “bueno” a “necesita atención”)
- Tests de regresión ante cambios en definiciones de KPI
Las pruebas unitarias deben afirmar no solo puntuaciones finales, sino componentes intermedios (por-KPI, normalización, penalizaciones/bonificaciones) para facilitar debugeo.
Cubre imports, permisos y flujo con pruebas de integración
Las pruebas de integración deben simular flujos end-to-end: importar una ficha de proveedor, aplicar permisos y asegurar que solo los roles correctos pueden ver, comentar, aprobar o escalar una disputa. Incluye tests para entradas del registro de auditoría y acciones bloqueadas (p. ej., un proveedor intentando editar una reseña aprobada).
Valida con UAT y pruebas de rendimiento
Realiza pruebas de aceptación de usuario con compras y un grupo piloto de proveedores. Registra momentos confusos y actualiza textos de UI, validaciones y ayudas.
Finalmente, ejecuta pruebas de rendimiento para periodos pico (cierre mensual/trimestral), centrándote en tiempos de carga de dashboards, exportes masivos y recalculaciones concurrentes.
Plan de lanzamiento y roadmap de iteración
Una app de puntuación tiene éxito cuando la gente la usa. Eso suele significar lanzar en fases, reemplazar hojas de cálculo con cuidado y fijar expectativas sobre qué cambiará (y cuándo).
Lanzamiento por fases que genere confianza
Empieza con la versión más pequeña que aún produzca fichas útiles.
Fase 1: fichas internas solo. Da a compras y stakeholders un lugar limpio para registrar valores de KPI, generar una ficha de proveedor y dejar notas internas. Mantén el flujo simple y céntrate en consistencia.
Fase 2: acceso a proveedores. Cuando la puntuación interna sea estable, invita a proveedores a ver sus fichas, responder y añadir contexto (p. ej., “demora por cierre de puerto”). Aquí importan permisos y pista de auditoría.
Fase 3: automatización. Añade integraciones y recalculación programada cuando confíes en el modelo. Automatizar demasiado pronto puede amplificar datos malos o definiciones poco claras.
Si quieres acortar tiempo al piloto, Koder.ai puede ayudar: puedes montar el flujo core (roles, aprobación de reseñas, fichas, exportes) rápidamente, iterar con stakeholders en “modo planificación” y luego exportar la base de código cuando estés listo para endurecer integraciones y controles de cumplimiento.
Plan de migración (adiós hojas de cálculo, con seguridad)
Si reemplazas hojas de cálculo, planifica una transición gradual en lugar de un corte brusco.
Proporciona plantillas de importación que reflejen columnas existentes (nombre proveedor, periodo, valores KPI, revisor, notas). Añade ayudas de importación como errores de validación (“vendor desconocido”), vistas previas y modo de simulación.
Decide también si migras todo el histórico o solo periodos recientes. A menudo, importar los últimos 4–8 trimestres basta para análisis de tendencias sin convertir la migración en arqueología de datos.
Mantén la formación corta y específica por rol:
- Guías de una página para revisores, aprobadores y admins
- Consejos en la app en el primer uso (cómo puntuar, dónde dejar contexto, qué significa “enviar”)
- Una checklist de admin: crear categorías, definir KPI, configurar ciclos de revisión y verificar accesos
Mantenimiento continuo e iteración
Trata definiciones de puntuación como un producto. Los KPI cambian, las categorías se expanden y los pesos evolucionan.
Establece una política de recalculación: ¿qué ocurre si cambia la definición de un KPI? ¿Recalculan resultados históricos o se preserva el cálculo original para auditoría? Muchas organizaciones mantienen resultados históricos y recalculan solo desde una fecha efectiva.
Próximos pasos: precios y empaquetado
Al pasar del piloto, decide qué incluir en cada nivel (número de proveedores, ciclos de revisión, integraciones, reporting avanzado, acceso al portal de proveedores). Si formalizas un plan comercial, bosqueja paquetes y enlázalos a /pricing para detalles.
Si evalúas construir vs comprar vs acelerar, también puedes tratar “¿qué tan rápido podemos lanzar un MVP confiable?” como un insumo de empaquetado. Plataformas como Koder.ai (con planes desde free hasta enterprise) pueden servir de puente práctico: construir e iterar rápido, desplegar y alojar, y mantener la opción de exportar y poseer el código fuente cuando tu programa de evaluación madure.