Aclarar el caso de uso y las métricas de éxito
Antes de diseñar pantallas o elegir stack tecnológico, define con precisión el problema que vas a resolver. Una app de dependencias falla cuando se convierte en “otro lugar para actualizar”, mientras el dolor real —sorpresas y entregas tardías entre equipos— continúa.
Definir el problema central
Comienza con una frase simple que puedas repetir en cada reunión:
Las dependencias interfuncionales están provocando retrasos y sorpresas de último minuto porque la propiedad, los tiempos y el estado no están claros.
Hazlo específico para tu organización: qué equipos se ven más afectados, qué tipos de trabajo se bloquean y dónde se pierde tiempo hoy (entregas, aprobaciones, acceso a datos, etc.).
Identificar usuarios objetivo (y lo que necesitan)
Enumera los usuarios principales y cómo usarán la app:
- Project managers: necesitan una vista fiable de bloqueos próximos y qué escalar.
- Team leads: necesitan claridad sobre qué debe entregar su equipo, para cuándo y los tradeoffs.
- Sponsors ejecutivos: necesitan una vista de riesgo de alto nivel y responsabilidad.
- Contribuyentes individuales (IC): necesitan solicitudes accionables, contexto y fechas de entrega.
Capturar los principales jobs-to-be-done
Mantén los “jobs” acotados y comprobables:
- Descubrir dependencias temprano (durante la planificación, no en la ejecución).
- Crear solicitudes de dependencia con alcance y fechas claras.
- Validar (aceptar/rechazar) con plazos negociados.
- Rastrear el progreso y los cambios a lo largo del tiempo.
- Escalar cuando el riesgo aumenta o los compromisos fallan.
Decidir qué significa “dependencia” aquí
Escribe una definición de un párrafo. Ejemplos: un handoff (Equipo A suministra datos), una aprobación (firma Legal), o un entregable (spec de diseño). Esta definición será tu modelo de datos y la columna vertebral del flujo de trabajo.
Establecer métricas de éxito
Elige un pequeño conjunto de resultados medibles:
- Menos bloqueos activos por proyecto (o menos dependencias “descubiertas tarde”).
- Menor tiempo medio desde solicitud → aceptación → entrega.
- Mejor predictibilidad (menos desvíos de fechas, mayor tasa de entrega a tiempo).
Si no puedes medirlo, no podrás probar que la app mejora la ejecución.
Mapear stakeholders y flujo de trabajo actual
Antes de diseñar pantallas o bases de datos, aclara quién participa en las dependencias y cómo fluye el trabajo entre ellos. La gestión de dependencias interfuncionales falla menos por mala herramienta y más por expectativas desajustadas: “¿Quién lo posee?”, “¿Qué significa hecho?”, “¿Dónde vemos el estado?”.
La información suele estar dispersa. Haz un inventario rápido y captura ejemplos (pantallazos reales o enlaces) de:
- Hojas de cálculo que rastrean solicitudes y fechas
- Tickets y épicos en Jira/Asana/Trello
- Docs y notas de reuniones (Google Docs/Notion/Confluence)
- Hilos en Slack/Teams donde se toman decisiones y se hacen promesas
Esto te dice qué campos ya usan las personas (fechas, enlaces, prioridad) y qué falta (propietario claro, criterios de aceptación, estado).
Mapear el flujo de trabajo de extremo a extremo
Escribe el flujo actual en lenguaje llano, típicamente:
request → accept → deliver → verify
Para cada paso, anota:
- Quién lo desencadena (rol/equipo, no una persona)
- Qué información se necesita para avanzar
- Dónde se registra hoy
- Qué significa “completo” (y quién lo firma)
Detectar puntos de fallo y priorizar el dolor
Busca patrones como propietarios poco claros, fechas faltantes, estado “silencioso” o dependencias descubiertas tarde. Pide a los stakeholders que ordenen los escenarios más dolorosos (p. ej., “aceptado pero nunca entregado” vs. “entregado pero no verificado”). Optimiza primero para los 1–2 más importantes.
Anclar la construcción con user stories
Escribe 5–8 user stories que reflejen la realidad, por ejemplo:
- “Como PM solicitante, puedo enviar una dependencia con fecha requerida y contexto para que el equipo responsable la evalúe.”
- “Como lead responsable, puedo aceptar/rechazar con una fecha de compromiso para que las expectativas sean explícitas.”
- “Como stakeholder, puedo ver el estado de un vistazo para no perseguir actualizaciones en reuniones.”
Estas historias serán tu guía de alcance cuando empiecen a acumularse solicitudes de funcionalidades.
Diseñar el modelo de datos de la dependencia
Una app de dependencias triunfa o fracasa según si todos confían en los datos. El objetivo del modelo es capturar quién necesita qué, de quién, para cuándo y mantener un registro limpio de cómo cambian los compromisos con el tiempo.
Registro núcleo de dependencia
Empieza con una única entidad “Dependency” que se lea por sí misma:
- Título: corto y específico (p. ej., “Revisión legal de la copia de checkout actualizada”)
- Descripción: contexto, criterios de aceptación, enlaces
- Tipo: lista controlada (p. ej., revisión, entrega, aprobación, acceso a datos)
- Equipo responsable: equipo que debe entregar
- Solicitante: persona o equipo que lo pide
Haz estos campos obligatorios donde sea posible; los campos opcionales tienden a quedarse vacíos.
Fechas y compromisos
Las dependencias van sobre tiempo, así que almacena las fechas de forma explícita y separada:
- Fecha solicitada (la fecha que necesita el solicitante)
- Fecha comprometida (la promesa del equipo responsable)
- Fecha de entrega (fecha real de finalización)
- Ventana de revisión (rango inicio/fin para verificación o sign-off)
Esta separación evita discusiones posteriores (“solicitado” no es lo mismo que “comprometido”).
Estado y relaciones
Usa un modelo de estado simple y compartido: propuesto → pendiente → aceptado → entregado, con excepciones como en riesgo y rechazado.
Modela relaciones como enlaces uno-a-muchos para que cada dependencia pueda conectar con:
- Proyectos (una dependencia puede impactar varias iniciativas)
- Hitos (vincúlala a un checkpoint de entrega específico)
- Tickets (p. ej., issues en Jira para la ejecución)
Auditabilidad y confianza
Haz los cambios trazables con:
- Creado/actualizado por
- Historial de cambios (actualizaciones a nivel de campo en el tiempo)
- Comentarios (notas de decisión, aclaraciones, aprobaciones)
Si haces bien el trail de auditoría desde el inicio, evitarás debates y facilitarás los handoffs.
Modelar proyectos, hitos y propiedad de equipos
Una app de dependencias solo funciona si todos se ponen de acuerdo en qué es un “proyecto”, qué es un “hito” y quién responde cuando algo falla. Mantén el modelo lo bastante simple para que los equipos realmente lo mantengan.
Proyectos y hitos: elegir la granularidad adecuada
Rastrea proyectos al nivel en que la gente planifica y reporta: normalmente una iniciativa de semanas a meses con un resultado claro. Evita crear un proyecto para cada ticket; eso pertenece a las herramientas de entrega.
Los hitos deben ser pocos y significativos, checkpoints que puedan desbloquear a otros (p. ej., “Contrato API aprobado”, “Lanzamiento beta”, “Revisión de seguridad completa”). Si los hitos son demasiado detallados, las actualizaciones se convierten en una tarea y la calidad de datos cae.
Una regla práctica: los proyectos deberían tener 3–8 hitos, cada uno con propietario, fecha objetivo y estado. Si necesitas más, considera hacer el proyecto más pequeño.
Directorio de equipos: hacer la propiedad fácilmente localizable
Las dependencias fallan cuando nadie sabe con quién hablar. Añade un directorio ligero de equipos que incluya:
- Nombre del equipo y función (p. ej., Pagos, Plataforma de Datos, Legal)
- Contacto principal (persona) y backup/on-call
- Canal preferido (email, handle de Slack, cola de tickets)
Este directorio debe ser usable por partners no técnicos; mantén los campos legibles y buscables.
Reglas de propiedad: responsabilidad sin confusión
Decide desde el inicio si permites propiedad compartida. La regla más limpia para dependencias es:
- Un propietario accountable por hito/dependencia (una persona)
- Colaboradores opcionales (varias personas)
Si dos equipos comparten responsabilidad real, móstralo como dos hitos (o dos dependencias) con un handoff claro, en lugar de ítems “co-propiedad” que nadie lidera.
Dependencias cross-project y rollups de programa
Representa las dependencias como enlaces entre proyecto/hito solicitante y proyecto/hito proveedor, con una dirección (“A necesita a B”). Esto permite vistas de programa: podrás agregar por iniciativa, trimestre o portfolio sin cambiar cómo trabajan los equipos diariamente.
Estrategia de etiquetas que sea útil a largo plazo
Las tags ayudan a segmentar reportes sin forzar una nueva jerarquía. Empieza con un conjunto pequeño y controlado:
- Área de producto
- Trimestre (o ventana de lanzamiento)
- Nombre de iniciativa/programa
- Prioridad (p. ej., P0–P3)
Prefiere menús desplegables en vez de texto libre para tags clave y evita variaciones como “Pagos”, “pagos” y “Paymnts”.
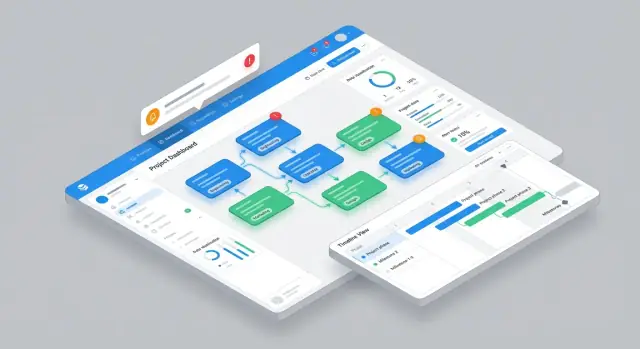
Planear la UI central y la navegación
Una app de gestión de dependencias funciona cuando la gente puede responder en segundos: ¿Qué debo entregar? y ¿Qué me está bloqueando? Diseña la navegación alrededor de esos jobs-to-be-done, no de objetos de la base de datos.
Vistas primarias que coincidan con el trabajo real
Comienza con cuatro vistas centrales, cada una optimizada para un momento distinto de la semana:
- Lista de dependencias para triage y ordenamiento (ideal para check-ins diarios)
- Gráfico de dependencias para entender impacto upstream/downstream de un vistazo
- Línea de tiempo para detectar colisiones de fechas y handoffs que se retrasan
- Bandeja del equipo como landing por defecto para contribuyentes ("solicitudes pendientes para mí")
Mantén la navegación global mínima (p. ej., Bandeja, Dependencias, Línea de tiempo, Informes) y permite saltar entre vistas sin perder filtros.
Creación rápida sin perder claridad
Haz que crear una dependencia se sienta tan rápido como enviar un mensaje. Proporciona plantillas (p. ej., “Contrato API”, “Revisión de diseño”, “Exportación de datos”) y un panel de Añadir rápido.
Requiere sólo lo necesario para enrutar el trabajo: equipo solicitante, equipo responsable, fecha límite, descripción corta y estado. Todo lo demás puede ser opcional o mostrado progresivamente.
Filtrado, búsqueda y vistas guardadas
La gente vivirá en filtros. Soporta búsqueda y filtros por equipo, rango de fechas, riesgo, estado, proyecto, además de “asignado a mí”. Permite guardar combinaciones comunes (“Mis lanzamientos Q1”, “Alto riesgo este mes”).
Accesibilidad y orientación en estados vacíos
Usa indicadores de riesgo seguros para color (icono + etiqueta, no sólo color) y asegúrate de navegación completa por teclado para crear, filtrar y actualizar estados.
Los estados vacíos deben enseñar. Cuando una lista esté vacía, muestra un ejemplo breve de una dependencia bien formulada:
“Equipo de Pagos: proporcionar keys sandbox para Checkout v2 antes del 14 de mar; necesario para empezar QA móvil.”
Ese tipo de guía mejora la calidad de datos sin añadir proceso.
Construir flujos de trabajo: Solicitar, Aceptar, Entregar, Cerrar
Itera sin miedo
Usa instantáneas y reversión al probar nuevas reglas de estado o campos de datos.
Una herramienta de dependencias funciona cuando refleja cómo colaboran los equipos—sin obligarlos a largas reuniones de estado. Diseña el flujo alrededor de un conjunto pequeño de estados que todos reconozcan, y haz que cada cambio responda a una pregunta: ¿Qué sucede después y quién lo posee?
Flujo de solicitud: crear → enrutar → aceptación
Empieza con un formulario guiado que capture lo mínimo requerido para actuar: proyecto solicitante, resultado necesario, fecha objetivo e impacto si se falla. Luego enrúta automáticamente al equipo responsable según una regla simple (propietario de servicio/componente, directorio de equipos o selección manual).
La aceptación debe ser explícita: el equipo responsable acepta, rechaza o pide aclaraciones. Evita las “aceptaciones blandas”—haz un botón que cree responsabilidad y selle la decisión con timestamp.
Criterios de aceptación: definición de hecho y sign-off
Al aceptar, pide una definición de hecho ligera: entregables (p. ej., endpoint API, revisión de spec, exportación de datos), prueba/validación y el responsable de sign-off en el lado solicitante.
Esto evita el fallo común donde algo está “entregado” pero no es utilizable.
Gestión de cambios: fechas, alcance, reasignaciones
Los cambios son normales; las sorpresas no. Cada cambio debe:
- registrar qué cambió (fecha, alcance, propietario)
- requerir una breve razón
- notificar a ambos equipos
- mantener un historial visible para que nadie discuta “quién dijo qué”
Ruta de escalado: flags de riesgo y SLAs
Da a los usuarios un flag claro de en riesgo con niveles de escalado (p. ej., Team Lead → Program Lead → Sponsor Ejecutivo) y SLAs opcionales (respuesta en X días, actualización cada Y días). El escalado debe ser una acción del flujo, no un hilo de mensajes airado.
Flujo de cierre: evidencia, verificación y notas retrospectivas
Cierra una dependencia sólo después de dos pasos: evidencia de entrega (enlace, adjunto o nota) y verificación por parte del solicitante (o cierre automático tras una ventana definida). Captura un campo retrospectivo corto (“qué nos bloqueó?”) para mejorar la planificación futura sin hacer un postmortem completo.
Añadir roles, permisos y auditabilidad
La gestión de dependencias se rompe rápido cuando no está claro quién puede comprometer, editar o qué cambió. Un modelo de permisos claro evita cambios accidentales, protege trabajo sensible y construye confianza entre equipos.
Definir tipos de roles que coincidan con el trabajo real
Empieza con un conjunto pequeño y amplía sólo si surge una necesidad real:
- Admin: gestiona settings del workspace, integraciones y permisos globales
- Program manager: supervisa portfolios, define reglas de gobernanza y resuelve disputas
- Team lead: posee compromisos del equipo y aprueba solicitudes entrantes
- Contributor: crea y actualiza dependencias en las que participa, añade notas y propone cambios
- Viewer: acceso solo lectura para stakeholders que necesitan visibilidad sin editar
Permisos por objeto (y por acción)
Implementa permisos a nivel de objeto—dependencias, proyectos, hitos, comentarios/notas—y luego por acción:
- Crear/editar dependencias
- Cambiar estado de una dependencia (p. ej., Propuesto → Aceptado → Entregado → Cerrado)
- Editar fechas comprometidas vs. sugeridas
- Borrar (normalmente restringido a Admin/Program manager)
Un buen defecto es mínimos privilegios: usuarios nuevos no deberían poder borrar registros ni sobrescribir compromisos.
Visibilidad de datos y trabajo sensible
No todos los proyectos deben ser igualmente visibles. Añade ámbitos de visibilidad como:
- Interno (por defecto): visible para usuarios autenticados del workspace
- Sensible: limitado a equipos específicos o a un grupo de seguridad
- Notas privadas de equipo: mantener notas de entrega candidas visibles solo para el equipo responsable, mientras el estado sigue siendo visible para stakeholders
Controles de aprobación y auditoría
Define quién puede aceptar/rechazar solicitudes y quién puede cambiar fechas comprometidas—típicamente el team lead receptor (o delegado). Haz la regla explícita en la UI: “Solo el equipo responsable puede comprometer fechas.”
Finalmente, añade un log de auditoría para eventos clave: cambios de estado, edición de fechas, cambios de propietario, actualizaciones de permisos y borrados (incluyendo quién, cuándo y qué cambió). Si soportas SSO, empareja con el log para dejar claro acceso y responsabilidad.
Implementar alertas y notificaciones
Mantén el código portátil
Genera la app rápidamente y exporta el código fuente cuando estés listo para llevarla a producción.
Las alertas son donde una herramienta de dependencias o bien resulta verdaderamente útil o bien se convierte en ruido que la gente ignora. El objetivo es simple: mantener el trabajo en movimiento entre equipos notificando a las personas correctas en el momento correcto, con el nivel de urgencia adecuado.
Empezar con disparadores de notificación claros
Define los eventos que más importan para dependencias interfuncionales:
- Nueva solicitud creada (el equipo receptor debe reconocerla)
- Solicitud aceptada / rechazada (el solicitante necesita certeza)
- Fecha próxima (prevenir sorpresas de último minuto)
- Estado cambia a “en riesgo” o “bloqueado” (provocar acción y apoyo)
Asocia cada disparador a un propietario y al “siguiente paso”, para que la notificación no sea solo informativa sino accionable.
Ofrecer canales sin forzarlos
Soporta múltiples canales:
- Notificaciones in-app para un rastro limpio y triage fácil
- Email para personas que viven en su bandeja de entrada
- Slack/Teams para visibilidad rápida del equipo
Hazlo configurable por usuario y equipo. Un lead de dependencia puede querer pings en Slack; un sponsor ejecutivo puede preferir un resumen diario por email.
Balancear alertas en tiempo real con resúmenes
Los mensajes en tiempo real son mejores para decisiones (aceptar/rechazar) y escalados. Los resúmenes son mejores para conciencia (fechas próximas, items “esperando”).
Incluye opciones como: “inmediato para asignaciones”, “digest diario para fechas próximas” y “resumen semanal de salud”. Esto reduce la fatiga de notificaciones sin perder visibilidad.
Hacer bien recordatorios y lógica de escalado
Los recordatorios deben respetar días hábiles, zonas horarias y horas de silencio. Por ejemplo: enviar un recordatorio 3 días hábiles antes de una fecha límite y nunca notificar fuera de 9am–6pm hora local.
Los escalados deben activarse cuando:
- Una solicitud queda sin responder tras una SLA definida (p. ej., 48 horas)
- Una fecha se desliza o una dependencia se marca en riesgo
Escala al siguiente nivel responsable (team lead, program manager) e incluye contexto: qué está bloqueado, por quién y qué decisión se necesita.
Planear integraciones y sincronización de datos
Las integraciones hacen útil una app de dependencias desde el día uno porque la mayoría de equipos ya rastrea trabajo en otras herramientas. El objetivo no es “reemplazar Jira” (o Linear, GitHub, Slack): es conectar decisiones de dependencia con los sistemas donde ocurre la ejecución.
Integraciones que vale la pena priorizar
Empieza con herramientas que representen trabajo, tiempo y comunicación:
- Jira / Linear para issues, estado, asignados y contexto de sprints/iteraciones
- GitHub para pull requests, releases y señales de despliegue
- Google Calendar para fechas de hitos, ventanas de cambio y reuniones clave
- Slack para notificaciones y aprobaciones ligeras
Elige 1–2 para piloto primero. Demasiadas integraciones temprano convierten el debug en la tarea principal.
Estrategia de importación: CSV primero, luego sync
Usa una importación CSV única para bootstrapping de dependencias, proyectos y propietarios. Mantén el formato opinado (p. ej., título de dependencia, equipo solicitante, equipo proveedor, fecha, estado).
Luego añade sincronización continua sólo para los campos que deben mantenerse consistentes (como el estado del issue o la fecha). Esto reduce cambios sorpresa y facilita la resolución de problemas.
Enlazar vs sincronizar (y cuándo)
No todos los campos externos deben copiarse en tu base:
- Enlazar: almacena el ID del sistema externo (p. ej., clave de issue de Jira) y deep-link a él. Ideal cuando la herramienta externa es la fuente de la verdad.
- Sincronizar: guarda una copia local de campos selectos (estado, fecha, asignado) para soportar reportes, alertas y auditoría—especialmente si necesitas saber “qué cambió cuándo”.
Un patrón práctico: siempre guarda IDs externos, sincroniza un conjunto pequeño de campos y permite overrides manuales sólo donde tu app es la fuente de la verdad.
Webhooks + APIs: sincronización basada en eventos
El polling es simple pero ruidoso. Prefiere webhooks cuando sea posible:
- Escucha cambios de estado (p. ej., “In Progress” → “Done”)
- Escucha cambios de fecha (a menudo el disparador más importante de riesgo)
Cuando llegue un evento, encola un job en background para obtener el registro más reciente vía API y actualizar tu objeto de dependencia.
Definir límites de propiedad de datos
Documento qué sistema es dueño de cada campo:
- Jira/Linear posee estado del issue y asignado
- Tu app posee relación de dependencia, fecha de compromiso y decisiones de aceptar/rechazar
- Slack posee canal de entrega e historial de mensajes (no intentes replicarlo)
Reglas claras de fuente de la verdad previenen “guerras de sincronización” y simplifican gobernanza y auditoría.
Crear reportes y dashboards de salud
Los dashboards son donde tu app gana confianza: los líderes dejan de pedir “una slide más” y los equipos dejan de perseguir actualizaciones en hilos. El objetivo no es una pared de gráficos, sino una forma rápida de responder: ¿Qué está en riesgo, por qué y quién hace el siguiente movimiento?
Definir señales claras de salud
Empieza con un conjunto pequeño de flags de riesgo que se puedan calcular de forma consistente:
- Atrasado: fecha prometida pasada y no entregado
- Bloqueado: marcado como bloqueado o falta un insumo requerido
- Sin propietario: no hay equipo/persona accountable asignado
- Fechas en conflicto: el solicitante la necesita después de la entrega planificada del proveedor (o viceversa)
Estas señales deben ser visibles a nivel de dependencia y agregadas a nivel de proyecto/programa.
Construir vistas listas para reuniones
Crea vistas que casen con cómo se hacen las reuniones de dirección:
- Dependencias críticas próximas: próximas 2–4 semanas, ordenadas por riesgo y fecha
- Impacto en la capacidad del equipo: mostrar donde las solicitudes entrantes exceden la capacidad disponible (incluso un indicador simple bajo/medio/alto ayuda)
- Rollups de programa: agrupar dependencias por iniciativa, trimestre o release train para que líderes comparen flujos sin agregación manual
Un buen por defecto es una página que responda: “¿Qué cambió desde la semana pasada?” (nuevos riesgos, bloqueos resueltos, cambios de fecha).
Hacer que compartir sea sencillo
Los dashboards suelen salir de la app. Añade exportaciones que preserven contexto:
- CSV para análisis y filtrado
- PDF para reuniones de dirección y aprobaciones
Al exportar, incluye propietario, fechas, estado y el último comentario para que el archivo sea autosuficiente. Así los dashboards reemplazan slides manuales en lugar de crear otra tarea de reporte.
Seleccionar un stack técnico práctico y arquitectura
Establece roles y reglas
Determina quién puede fijar fechas y registra las ediciones clave con un historial apto para auditorías.
El objetivo no es escoger la tecnología “perfecta”, sino una que tu equipo pueda construir y operar con confianza manteniendo vistas rápidas y datos fiables.
Una base práctica es:
- Una web app (server-rendered o SPA) para uso diario
- Una API única (REST o GraphQL) que impulse la UI e integraciones
- Una base de datos relacional
- Jobs en background para notificaciones, sincronizaciones programadas y generación de reportes
Esto mantiene el sistema sencillo: acciones de usuario síncronas y trabajo pesado (alertas, métricas) asíncrono.
Base de datos: modela los enlaces como realmente importan
La gestión de dependencias exige consultas del tipo “encuentra todos los items bloqueados por X”. Un modelo relacional funciona bien con los índices adecuados.
Al menos, planifica tablas como Projects, Milestones/Deliverables y Dependencies (from_id, to_id, type, status, fechas, propietarios). Añade índices para filtros comunes (equipo, estado, fecha, proyecto) y para travesías (from_id, to_id).
Gráficos y líneas de tiempo: elige librerías con rendimiento en mente
Los gráficos de dependencias y las timelines tipo Gantt pueden ser costosos. Elige librerías que soporten virtualización (renderizar solo lo visible) y actualizaciones incrementales. Trata las vistas “mostrar todo” como modos avanzados y por defecto usa vistas acotadas (por proyecto, equipo, rango de fechas).
Mantener vistas rápidas: caching y paginación
Pagina las listas por defecto y cachea resultados calculados comunes (p. ej., “cuenta bloqueados por proyecto”). Para gráficos, precarga solo el vecindario alrededor del nodo seleccionado y expande bajo demanda.
Buenas prácticas de despliegue que agradecerás
Usa entornos separados (dev/staging/prod), añade monitorización y tracking de errores, y registra eventos relevantes para auditoría. Una app de dependencias pronto se convierte en fuente de la verdad: downtime y fallos silenciosos cuestan coordinación real.
Ruta rápida si prototipas
Si tu objetivo principal es validar flujos y UI rápido (bandeja, aceptación, escalado, dashboards) antes de dedicar ingeniería, puedes prototipar en una plataforma de vibe-coding como Koder.ai. Permite iterar modelo de datos, roles/permisos y pantallas clave vía chat y exportar código cuando estés listo para producción (comúnmente React en frontend, Go + PostgreSQL en backend). Esto es útil para un piloto con 2–3 equipos donde la velocidad de iteración importa más que la arquitectura perfecta desde el día uno.
Probar, pilotar y desplegar con seguridad
Una app de dependencias solo ayuda si la gente confía en ella. Esa confianza se gana con pruebas cuidadosas, un piloto contenido y un despliegue que no interrumpa equipos en mitad de entregas.
Probar el flujo de extremo a extremo
Valida la ruta feliz: un equipo solicita una dependencia, el responsable acepta, se entrega el trabajo y la dependencia se cierra con un resultado claro.
Luego prueba casos límite que rompen el uso real:
- Reasignaciones: mover propiedad a otro equipo y confirmar que el historial se mantiene
- Rechazos: rechazar con motivo y asegurar que el solicitante puede revisar/reenviar
- Cambios de fecha: actualizar fechas de hitos y verificar que las timelines, SLAs y reportes se ajustan correctamente
Chequeos de permisos y auditoría
Las apps de dependencias fallan cuando los permisos son demasiado estrictos (la gente no puede hacer su trabajo) o demasiado laxos (los equipos pierden control). Prueba escenarios como:
- Un solicitante puede editar su solicitud, pero no editar los campos de entrega del equipo responsable
- Solo los owners designados pueden aceptar/comprometer fechas
- Los admins pueden intervenir y cada cambio crítico se captura en un log de auditoría (quién/qué/cuándo)
Notificaciones sin ruido
Las alertas deben provocar acción, no ignorarse:
Verifica:
- No haya notificaciones duplicadas cuando cambian múltiples campos a la vez
- El throttle funciona (p. ej., un resumen de actualización en vez de 10 pings separados)
- Los resúmenes incluyen contexto suficiente (proyecto, dependencia, fecha, propietario) para actuar sin buscar más
Sembrar datos demo para validación
Antes de involucrar equipos, precarga proyectos, hitos y dependencias cross-team realistas. Buenos datos de ejemplo exponen etiquetas confusas, estados faltantes y huecos de reporte más rápido que registros sintéticos.
Ejecutar un piloto pequeño y luego ampliar
Pilota con 2–3 equipos que dependen entre sí. Fija una ventana corta (2–4 semanas), recopila feedback semanal y itera sobre:
- Nombres de estado y campos obligatorios
- Reglas de notificación
- Vistas de reporte (qué es “accionable” vs “interesante”)
Cuando los equipos piloto digan que la herramienta ahorra tiempo, despliega por oleadas y publica un doc claro de “cómo trabajamos ahora” enlazado desde la cabecera de la app.