Definir objetivos y señales de adopción
Antes de construir una puntuación de salud de adopción, decide qué quieres que la puntuación haga por el negocio. Una puntuación diseñada para disparar alertas de riesgo de churn será distinta a la que guía el onboarding, la educación del cliente o las mejoras de producto.
Define qué significa “adopción” para tu producto
Adopción no es solo “se conectó recientemente”. Anota los pocos comportamientos que realmente indican que los clientes están alcanzando valor:
- Activación: el primer momento en que un usuario llega a un resultado significativo (p. ej., “invitó a un compañero”, “conectó una fuente de datos”, “publicó un informe”).
- Acciones centrales: comportamientos repetibles y de alta señal que se correlacionan con cuentas exitosas (p. ej., exportaciones semanales, ejecuciones de automatizaciones, dashboards vistos por varios usuarios).
- Retención: uso continuado en la cadencia adecuada para tu producto (diario, semanal, mensual), idealmente por más de un usuario en la cuenta.
Estos serán tus señales iniciales de adopción para analítica de uso de funciones y análisis por cohortes.
Lista las decisiones que debe permitir tu app
Sé explícito sobre qué ocurre cuando cambia la puntuación:
- ¿Quién es notificado cuando una cuenta baja de un umbral?
- ¿Qué playbooks deben lanzarse (outreach, formación, revisión de soporte)?
- ¿Qué insights deben informar la monitorización de adopción (puntos de fricción, funciones poco usadas, time-to-value)?
Si no puedes nombrar una decisión, no rastrees esa métrica todavía.
Identifica usuarios, roles y ventanas temporales
Aclara quién usará el panel de Customer Success:
- Gerentes de Customer Success (CS) necesitan priorización y contexto de cuenta.
- Producto necesita patrones, cohortes y movimientos a nivel de función.
- Soporte necesita actividad reciente relacionada con tickets e incidentes.
- Liderazgo necesita un resumen entendible y tendencias.
Elige ventanas estándar—últimos 7/30/90 días—y considera etapas del ciclo de vida (trial, onboarding, steady-state, renovación). Esto evita comparar una cuenta nueva con una madura.
Establece criterios de éxito
Define “hecho” para tu modelo de puntuación:
- Precisión: ¿predice riesgo y señales de expansión mejor que el enfoque actual?
- Explicabilidad: ¿puede un CSM explicar por qué la puntuación es alta/baja en un minuto?
- Facilidad de uso: ¿ahorra tiempo y genera acciones consistentes?
Estos objetivos moldean todo lo posterior: tracking de eventos, lógica de scoring y los flujos de trabajo alrededor de la puntuación.
Seleccionar métricas para tu puntuación de salud
La elección de métricas es donde tu puntuación será una señal útil o un número ruidoso. Apunta a un conjunto pequeño de indicadores que reflejen adopción real—no solo actividad.
Empieza con señales de adopción del producto
Elige métricas que muestren si los usuarios obtienen valor repetidamente:
- Logins / usuarios activos: p. ej., weekly active users (WAU) y la tendencia en las últimas 4–8 semanas.
- Días activos: cuántos días distintos la cuenta estuvo activa en una semana/mes (evita falsos positivos por “una sesión grande”).
- Profundidad de funciones: uso de tus “funciones de valor” (las acciones que se correlacionan con el éxito), no cada clic en la interfaz.
- Integraciones conectadas: especialmente si las integraciones aumentan el coste de cambio o desbloquean flujos clave.
- Utilización de asientos: porcentaje de asientos comprados que están invitados, activados y efectivamente activos.
Mantén la lista enfocada. Si no puedes explicar por qué importa una métrica en una frase, probablemente no sea una entrada principal.
Añade contexto del negocio (para que las puntuaciones no sean injustas)
La adopción debe interpretarse en contexto. Un equipo de 3 asientos se comportará distinto a un despliegue de 500 asientos.
Señales contextuales comunes:
- Nivel de plan y derechos de características
- Tamaño del contrato / banda de ARR
- Etapa del ciclo de vida: trial vs recién pagado vs ventana de renovación
No necesitan “sumar puntos”, pero ayudan a fijar expectativas y umbrales realistas por segmento.
Decide indicadores líderes vs rezagados
Una puntuación útil mezcla:
- Indicadores líderes (predicen éxito futuro): aumento de días activos, finalización del onboarding, primera integración conectada.
- Indicadores rezagados (confirman resultados): renovación, expansión, retención a largo plazo.
Evita sobreponderar los indicadores rezagados; cuentan lo que ya pasó.
Opcional: insumos cualitativos (usar con cuidado)
Si los tienes, NPS/CSAT, volumen de tickets de soporte y notas de CSM pueden añadir matiz. Úsalos como modificadores o flags—no como base—porque los datos cualitativos pueden ser escasos y subjetivos.
Crea un diccionario de datos simple
Antes de crear gráficos, alinea nombres y definiciones. Un diccionario ligero debe incluir:
- Nombre de métrica (p. ej.,
active_days_28d)
- Definición clara (qué cuenta y qué no)
- Ventana temporal y frecuencia de actualización
- Sistema fuente (eventos del producto, CRM, soporte)
Esto evita la confusión de “misma métrica, distinto significado” cuando implementes paneles y alertas.
Diseñar un modelo de puntuación explicable
Una puntuación de adopción solo funciona si tu equipo confía en ella. Apunta a un modelo que puedas explicar en un minuto a un CSM y en cinco minutos a un cliente.
Empieza simple: puntos ponderados (antes de ML)
Comienza con una puntuación basada en reglas transparente. Elige un conjunto pequeño de señales de adopción (p. ej., usuarios activos, uso de funciones clave, integraciones habilitadas) y asigna pesos que reflejen los momentos “aha” de tu producto.
Ejemplo de ponderación:
- Weekly active users por asiento: 0–40 puntos
- Frecuencia de uso de función clave: 0–35 puntos
- Amplitud de funciones usadas: 0–15 puntos
- Tiempo desde la última actividad significativa: 0–10 puntos
Mantén los pesos fáciles de defender. Puedes revisarlos después—no esperes al modelo perfecto.
Normaliza para reducir sesgos
Los recuentos brutos castigan a las cuentas pequeñas y aplanan a las grandes. Normaliza métricas donde importe:
- Por asiento (uso / asientos licenciados)
- Por edad de la cuenta (nueva vs madura)
- Por nivel de plan (disponibilidad de funciones)
Esto ayuda a que la puntuación refleje comportamiento, no solo tamaño.
Define verde/amarillo/rojo con razonamiento claro
Fija umbrales (p. ej., Verde ≥ 75, Amarillo 50–74, Rojo < 50) y documenta por qué existe cada corte. Vincula los umbrales a resultados esperados (riesgo de renovación, finalización de onboarding, readiness para expansión) y guarda las notas en tus docs internos o en /blog/health-score-playbook.
Hazlo explicable: contribuyentes y tendencia
Cada puntuación debe mostrar:
- Los 3 principales contribuyentes (qué ayudó/perjudicó)
- El cambio a lo largo del tiempo (últimos 7/30 días)
- Un resumen en lenguaje llano (“El uso de la función X bajó 35% semana a semana”)
Plan para iteración: versiona el modelo
Trata el scoring como un producto. Versiona (v1, v2) y mide impacto: ¿fueron más precisas las alertas de churn? ¿Actuaron antes los CSMs? Guarda la versión del modelo con cada cálculo para comparar resultados en el tiempo.
Instrumentar eventos del producto y fuentes de datos
Una puntuación de salud solo es tan confiable como los datos de actividad detrás. Antes de construir la lógica de scoring, confirma que las señales correctas se capturan de forma consistente entre sistemas.
Elige tus fuentes de eventos
La mayoría de los programas de adopción extraen de una mezcla de:
- Eventos frontend (vistas de página, clicks, interacciones de funciones)
- Acciones backend (llamadas API, jobs completados, registros creados)
- Facturación (plan, renovaciones, estado de pagos, conteo de asientos)
- Herramientas de soporte y éxito (tickets, CSAT, hitos de onboarding)
Una regla práctica: rastrea acciones críticas server-side (difícil de falsificar, menos afectado por ad blockers) y usa eventos frontend para engagement de UI y descubrimiento.
Define un esquema de eventos claro
Mantén un contrato consistente para que los eventos sean fáciles de unir, consultar y explicar a stakeholders. Una línea base común:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id, etc.)
Usa un vocabulario controlado para event_name (por ejemplo, project_created, report_exported) y documenta en un tracking plan sencillo.
Decide SDK vs server-side (o ambos)
- Tracking con SDK es rápido de lanzar y excelente para eventos de UI.
- Tracking server-side es mejor para acciones que son sistema de registro.
Muchos equipos hacen ambos, pero asegúrate de no doble-contar la misma acción del mundo real.
Maneja identidad correctamente
Las puntuaciones suelen agregarse a nivel de cuenta, por lo que necesitas un mapeo fiable usuario→cuenta. Planea para:
- Usuarios pertenecientes a múltiples cuentas
- Fusión de cuentas (adquisiciones, consolidación de workspaces)
- IDs anonimizados para comportamiento pre-login (con una fusión segura tras el signup)
Incorpora checks de calidad de datos
Como mínimo, monitoriza eventos faltantes, ráfagas duplicadas y consistencia de zona horaria (almacena en UTC; convierte para display). Marca anomalías temprano para que tus alertas de riesgo no se activen porque el tracking falló.
Modela tus datos y almacenamiento
Una app de puntuación de salud vive o muere por lo bien que modelas “quién hizo qué y cuándo”. El objetivo es responder rápido: ¿Cómo está esta cuenta esta semana? ¿Qué funciones suben o bajan? Un buen modelado mantiene simples el scoring, los paneles y las alertas.
Entidades principales a modelar
Empieza con un pequeño conjunto de tablas “fuente de la verdad”:
- Accounts: account_id, plan, segmento, etapa del ciclo de vida, owner CSM
- Users: user_id, account_id, rol/persona, created_at, status
- Subscriptions (o contratos): account_id, start/end, seats, MRR, fecha de renovación
- Features: feature_id, name, category (activación, colaboración, admin, etc.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (o computed_at), overall_score, component_scores, campos de explicación
Mantén estas entidades consistentes usando IDs estables (account_id, user_id) en todas partes.
Almacenamiento dividido: relacional + analítica
Usa una BD relacional (p. ej., Postgres) para accounts/users/subscriptions/scores—cosas que actualizas y unes frecuentemente.
Almacena eventos de alto volumen en un warehouse/analytics (p. ej., BigQuery/Snowflake/ClickHouse). Esto mantiene dashboards y análisis de cohortes responsivos sin sobrecargar tu BD transaccional.
Guarda agregados para velocidad
En lugar de recalcular todo desde eventos raw, mantiene:
- Resúmenes diarios por cuenta (una fila por cuenta por día): usuarios activos, conteos de eventos clave, última actividad, hitos de adopción
- Contadores por función: uso por cuenta/día/función, usuarios únicos, tiempo empleado (si está disponible)
Estas tablas impulsan gráficos de tendencia, insights de “qué cambió” y componentes del score.
Retención, particionado y rendimiento de consultas
Para tablas de eventos grandes, planifica retención (p. ej., 13 meses raw, más tiempo para agregados) y particiona por fecha. Cluster/index por account_id y timestamp/date para acelerar consultas “cuenta a través del tiempo”.
En tablas relacionales, indexa filtros y joins comunes: account_id, (account_id, date) en resúmenes, y claves foráneas para mantener la limpieza de datos.
Planificar la arquitectura de la app web
Construye la canalización de puntuación
Prototipa cuentas, eventos, agregados y procesos de scoring rápidamente para que tu equipo pueda iterar desde el inicio.
Tu arquitectura debe facilitar lanzar un v1 confiable y luego crecer sin reescrituras. Empieza decidiendo cuántas piezas realmente necesitas.
Monolito vs servicios (mantén simple el v1)
Para la mayoría, un monolito modular es el camino más rápido: una base de código con límites claros (ingestión, scoring, API, UI), un único deploy y menos sorpresas operativas.
Pasa a servicios solo cuando haya una razón clara—necesidad de escalado independiente, aislamiento estricto de datos, o equipos separados. Si no, los servicios prematuros aumentan puntos de fallo y ralentizan la iteración.
Define los componentes centrales
Como mínimo, planifica estas responsabilidades (aunque vivan en una sola app inicialmente):
- Ingestión: recibe eventos del producto (SDK, Segment, webhook, importaciones por lotes).
- Agregación: convierte eventos raw en hechos de uso diarios/semanales por cuenta/usuario.
- Scoring: calcula la puntuación de salud de adopción y las explicaciones asociadas.
- API: sirve scores, tendencias y el “por qué” al UI e integraciones.
- UI: panel de Customer Success con vistas de cuenta, cohortes y drill-down.
Si quieres prototipar rápido, un enfoque de desarrollo rápido puede ayudarte a tener un dashboard funcional sin sobreinvertir en infraestructura. Por ejemplo, Koder.ai puede generar una UI en React y backend en Go + PostgreSQL a partir de una descripción sencilla de tus entidades (accounts, events, scores), endpoints y pantallas—útil para levantar un v1 que el equipo de CS pueda validar temprano.
Jobs programados vs streaming
El scoring por lotes (p. ej., horario o nocturno) suele ser suficiente y mucho más sencillo de operar. El streaming tiene sentido si necesitas alertas casi en tiempo real (p. ej., caída súbita de uso) o volúmenes de eventos muy altos.
Un híbrido práctico: ingiere eventos continuamente, agrega/scoring en un horario, y reserva streaming para señales urgentes puntuales.
Entornos, secretos y requisitos no funcionales
Configura dev/stage/prod desde temprano, con cuentas de muestra en stage para validar dashboards. Usa un store gestionado de secretos y rota credenciales.
Documenta requisitos: volumen esperado de eventos, frescura del score (SLA), objetivos de latencia de la API, disponibilidad, retención de datos y restricciones de privacidad (manejo de PII y controles de acceso). Esto evita decisiones de arquitectura tardías y bajo presión.
Construir la canalización de datos y jobs de scoring
Tu puntuación es tan confiable como la canalización que la produce. Trata el scoring como un sistema de producción: reproducible, observable y fácil de explicar cuando alguien pregunta “¿por qué esta cuenta bajó hoy?”.
Una canalización simple: raw → validado → agregados
Empieza con un flujo en etapas que depure los datos antes de puntuar:
- Eventos raw: ingestión append-only desde app, mobile, integraciones y exportes de billing/CRM.
- Eventos validados: eventos que pasan cheques de esquema (campos requeridos, tipos correctos), chequeos de identidad (mapeo user→account) y desduplicación.
- Agregados diarios: rollups por cuenta (y opcionalmente por workspace/equipo) como usuarios activos, conteos de eventos clave, hitos y deltas de tendencia.
Esta estructura mantiene los jobs de scoring rápidos y estables al operar sobre tablas limpias y compactas en vez de miles de millones de filas raw.
Programación de recalculaciones y backfills
Decide cuán “fresca” debe ser la puntuación:
- Cada hora para movimientos de alto contacto donde los CSMs actúan rápido.
- Diaria para SMB/self-serve y para controlar costos.
Construye el scheduler para soportar backfills (p. ej., reprocesar los últimos 30/90 días) cuando ajustes tracking, pesos o añadas señales. Los backfills deben ser una función de primera clase, no un script de emergencia.
Idempotencia: evita doble-contar
Los jobs de scoring se reintentarán. Las importaciones se volverán a ejecutar. Los webhooks pueden entregarse doble. Diseña para ello.
Usa una clave de idempotencia para eventos (event_id o un hash estable de timestamp + user_id + event_name + properties) y aplica unicidad en la capa validada. Para agregados, haz upsert por (account_id, date) para que la recomputación reemplace resultados previos en vez de sumarlos.
Monitorización y cheques de anomalías
Añade monitorización operativa para:
- Éxito/fallo de jobs y conteos de reintentos
- Retraso de datos (qué tan atrasados están tus últimos agregados respecto a “ahora”)
- Anomalías de volumen (caídas/subidas repentinas en eventos, usuarios activos, acciones clave)
Incluso umbrales ligeros (p. ej., “eventos 40% abajo vs promedio de 7 días”) evitan fallos silenciosos que engañarían el panel de Customer Success.
Pistas de auditoría para cada puntuación
Guarda un registro de auditoría por cuenta y por ejecución de scoring: métricas de entrada, features derivadas (p. ej., cambio semana a semana), versión del modelo y puntuación final. Cuando un CSM haga clic en “¿Por qué?”, podrás mostrar exactamente qué cambió y cuándo—sin reconstruirlo desde logs.
Crear una API segura para salud e insights
Reduce los costos de desarrollo
Obtén créditos compartiendo tu proceso de construcción o refiriendo colegas a Koder.ai.
Tu app depende de su API. Es el contrato entre tus jobs de scoring, la UI y herramientas downstream (plataformas CS, BI, exports). Apunta a una API rápida, predecible y segura por defecto.
Endpoints clave para soportar workflows reales
Diseña endpoints según cómo el Customer Success realmente explora adopción:
- Health de cuenta:
GET /api/accounts/{id}/health devuelve la puntuación más reciente, banda de estado (p. ej., Verde/Amarillo/Rojo) y timestamp de cálculo.
- Tendencias:
GET /api/accounts/{id}/health/trends?from=&to= para score a lo largo del tiempo y deltas de métricas clave.
- **Drivers ("por qué")
: GET /api/accounts/{id}/health/drivers` para mostrar factores positivos/negativos (p. ej., “asientos activos semanales abajo 35%”).
- Cohortes:
GET /api/cohorts/health?definition= para análisis de cohortes y benchmarks de pares.
- Exports:
POST /api/exports/health para generar CSV/Parquet con esquemas consistentes.
Filtrado, paginación y caching
Haz que los endpoints de lista sean fáciles de segmentar:
- Filtros:
plan, segment, csm_owner, lifecycle_stage y date_range son esenciales.
- Paginación: usa paginación basada en cursor (
cursor, limit) para estabilidad mientras los datos cambian.
- Caching: cachea consultas pesadas (rollups de cohortes, series de tendencia) y devuelve
ETag/If-None-Match para reducir cargas repetidas. Ten en cuenta permisos y filtros en las claves de cache.
Seguridad con control de acceso por roles
Protege datos a nivel de cuenta. Implementa RBAC (p. ej., Admin, CSM, Solo-lectura) y haz cumplir permisos en cada endpoint. Un CSM solo debe ver las cuentas que gestiona; roles como finanzas pueden ver agregados a nivel de plan pero no detalles de usuarios.
Devuelve siempre explicaciones
Junto al número customer adoption health score, devuelve campos de “por qué”: principales drivers, métricas afectadas y baseline de comparación (periodo previo, mediana de cohortes). Esto convierte la monitorización de adopción en acción, no solo en reporte, y hace tu panel de Customer Success confiable.
Diseñar paneles y vistas de cuenta
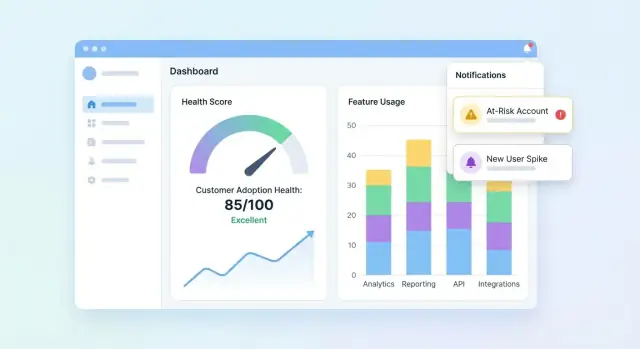
Tu UI debe responder tres preguntas rápido: ¿Quién está sano? ¿Quién está decayendo? ¿Por qué? Empieza con un dashboard que resuma la cartera y permite que los usuarios hagan drill-down en una cuenta para entender la historia detrás de la puntuación.
Esenciales del panel de cartera
Incluye un conjunto compacto de tiles y gráficos que un equipo de CS pueda escanear en segundos:
- Distribución de puntuaciones (histograma o buckets como Saludable / Vigilar / En riesgo)
- Lista de en riesgo con los campos necesarios para actuar (cuenta, owner, puntuación, última actividad, driver principal)
- Tendencia de puntuación (gráfico de líneas) con opción de filtrar por segmento
Haz la lista de en riesgo clicable para abrir la cuenta y ver inmediatamente qué cambió.
Vista de cuenta: explica la puntuación
La página de cuenta debe leerse como una línea de tiempo de adopción:
- Línea de tiempo de eventos clave (pasos de onboarding completados, integraciones conectadas, cambios administrativos, primer uso de funciones importantes)
- Métricas clave (usuarios activos, acciones de funciones clave, tiempo desde la última actividad significativa)
- Desglose de adopción por función mostrando qué funciones están adoptadas, ignoradas o en regresión
Añade un panel “¿Por qué esta puntuación?”: al hacer clic en la puntuación se revelan las señales contribuyentes (positivas y negativas) con explicaciones en lenguaje claro.
Vistas de cohortes y segmentos
Proporciona filtros de cohortes que coincidan con cómo los equipos gestionan cuentas: cohortes de onboarding, niveles de plan e industrias. Acompaña cada cohorte con líneas de tendencia y una pequeña tabla de principales movimientos para comparar resultados y detectar patrones.
Visuales accesibles y confiables
Usa etiquetas y unidades claras, evita iconos ambiguos y ofrece indicadores de estado seguros para el color (p. ej., etiquetas de texto + formas). Trata los gráficos como herramientas de decisión: anota picos, muestra rangos de fechas y haz el comportamiento de drill-down consistente en todas las páginas.
Añadir alertas, tareas y flujos de trabajo
Una puntuación de salud solo es útil si genera acción. Las alertas y flujos convierten “datos interesantes” en outreach oportuno, correcciones de onboarding o nudges de producto—sin forzar al equipo a vigilar dashboards todo el día.
Define reglas de alerta que mapeen a riesgo real
Empieza con un conjunto pequeño de triggers de alta señal:
- Caídas de puntuación (p. ej., baja 15 puntos semana a semana)
- Estado Rojo (cruza un umbral crítico)
- Declive súbito de uso (uso de función clave cae por debajo de un baseline)
- Fallo en paso de onboarding (item de checklist estancado, integración no completada)
Haz cada regla explícita y explicable. En lugar de “Mala salud”, alerta sobre “Sin actividad en la Función X por 7 días + onboarding incompleto.”
Elige canales y hazlos configurables
Los equipos trabajan diferente, así que ofrece soporte de canales y preferencias:
- Email para owners y managers
- Slack para visibilidad de equipo y respuesta rápida
- Tareas in-app dentro del dashboard de CS para que el trabajo no se pierda
Permite que cada equipo configure: quién recibe notificaciones, qué reglas están activas y qué umbrales son “urgentes”.
Reduce el ruido con guardrails
La fatiga de alertas mata la monitorización. Añade controles como:
- Ventanas de cooldown (no volver a alertar por la misma cuenta durante N horas/días)
- Umbrales mínimos de datos (saltar alertas si la cuenta tiene pocos datos recientes)
- Batching/digestos para señales no urgentes (resúmenes diarios/semanales)
Añade contexto y pasos a seguir
Cada alerta debe responder: qué cambió, por qué importa y qué hacer ahora. Incluye drivers recientes de la puntuación, una línea de tiempo corta (p. ej., últimos 14 días) y tareas sugeridas como “Programar llamada de onboarding” o “Enviar guía de integración”. Enlaza a la vista de cuenta (p. ej., /accounts/{id}).
Haz seguimiento de resultados para cerrar el ciclo
Trata las alertas como items de trabajo con estados: reconocida, contactada, recuperada, churned. Reportar resultados ayuda a afinar reglas, mejorar playbooks y demostrar que la puntuación de salud está generando retención medible.
Asegurar calidad de datos, privacidad y gobernanza
Construye en equipo
Colabora con producto y CS en la misma app mientras afinan drivers y umbrales.
Si tu puntuación se basa en datos poco fiables, los equipos dejarán de confiar y de actuar. Trata la calidad, privacidad y gobernanza como características de producto, no como un añadido.
Implementa cheques automáticos de datos
Empieza con validaciones ligeras en cada handoff (ingest → warehouse → salida de scoring). Unos cuantos tests de alta señal detectan la mayoría de problemas temprano:
- Cheques de esquema: columnas esperadas existen, tipos no cambiaron, enums válidos.
- Cheques de rango: valores imposibles (sesiones negativas, timestamps futuros) fallan rápido.
- Cheques de nulos: campos requeridos (
account_id, event_name, occurred_at) no pueden estar vacíos.
Cuando los tests fallen, bloquea el job de scoring (o marca resultados como “stale”) para que una canalización rota no genere alertas de churn engañosas.
Maneja casos límite comunes explícitamente
El scoring falla en escenarios “extraños pero normales”. Define reglas para:
- Cuentas nuevas con pocos datos: mostrar “datos insuficientes” o usar una baseline de ramp-up en lugar de una puntuación baja.
- Uso estacional: comparar con el periodo previo de la cuenta o con benchmark de cohortes en vez de un umbral universal.
- Outages y gaps de tracking: marcar ventanas afectadas y evitar penalizar clientes por tu downtime.
Añade permisos y controles de privacidad
Limita PII por defecto: guarda solo lo necesario para la monitorización de adopción. Aplica RBAC en la app web, registra quién vio/exportó datos y redacta exports cuando campos no sean necesarios (p. ej., ocultar emails en descargas CSV).
Crea runbooks y hábitos de gobernanza
Escribe runbooks cortos para respuesta a incidentes: cómo pausar scoring, backfill de datos y re-ejecutar jobs históricos. Revisa métricas de éxito del cliente y pesos de la puntuación regularmente—mensual o trimestralmente—para evitar deriva conforme evoluciona el producto. Para alineamiento de procesos, enlaza tu checklist interno desde /blog/health-score-governance.
Validar, iterar y escalar la puntuación de salud
La validación es donde una puntuación deja de ser “un bonito gráfico” y empieza a ser fiable para generar acción. Trata la primera versión como una hipótesis, no como la respuesta final.
Ejecuta un piloto y calibra contra juicio humano
Empieza con un grupo piloto de cuentas (por ejemplo, 20–50 por segmento). Para cada cuenta, compara la puntuación y las razones de riesgo con la evaluación del CSM.
Busca patrones:
- Puntuaciones consistentemente más altas/bajas que el juicio del CSM (calibración)
- “Falsas alarmas” (alto riesgo pero la cuenta está bien) vs “misses” (puntuación sana pero la cuenta churnea)
- Razones que no coinciden con la realidad (brechas de explicabilidad)
Mide si realmente es útil
La precisión ayuda, pero la utilidad paga. Rastrea resultados operacionales como:
- Tiempo para detectar riesgo (qué tan temprano marcas un problema)
- Tasa de éxito del outreach (porcentaje de cuentas en riesgo que mejoran tras intervención)
- Proxies de reducción de churn (movimientos en probabilidad de renovación, señales de expansión, cambio en carga de soporte)
Cuando ajustes umbrales, pesos o añadas señales, trátalo como una nueva versión del modelo. Haz A/B test de versiones en cohortes comparables y guarda versiones históricas para poder explicar por qué cambiaron las puntuaciones con el tiempo.
Recoge feedback dentro de la UI
Añade un control ligero como “La puntuación parece incorrecta” con una razón (p. ej., “finalización de onboarding reciente no reflejada”, “uso estacional”, “mapeo de cuenta incorrecto”). Rutea este feedback al backlog y etiqueta por cuenta y versión del modelo para depuración más rápida.
Escala con una hoja de ruta
Una vez el piloto esté estable, planifica el trabajo de escalado: integraciones más profundas (CRM, billing, soporte), segmentación (por plan, industria, ciclo de vida), automatización (tareas y playbooks) y configuración self-serve para que los equipos personalicen vistas sin ingeniería.
Al escalar, mantiene el bucle construir/iterar cerrado. Los equipos suelen usar Koder.ai para generar nuevas páginas de dashboard, refinar shapes de la API o añadir features de workflow (tareas, exports, releases con rollback) directamente desde chat—muy útil cuando versionas el modelo de puntuación y necesitas lanzar cambios de UI + backend rápido sin frenar el ciclo de feedback de CS.