26 nov 2025·8 min
Cómo construir una aplicación web para rastrear cuellos de botella operativos
Guía paso a paso para planificar, diseñar y lanzar una aplicación web que capture datos de flujo de trabajo, detecte cuellos de botella y ayude a los equipos a corregir retrasos.
Empieza con el problema y las decisiones
Una aplicación de seguimiento de procesos solo ayuda si responde a una pregunta específica: “¿Dónde nos estamos atascando y qué debemos hacer al respecto?” Antes de diseñar pantallas o elegir una arquitectura de aplicación web, define qué significa “cuello de botella” en tu operación.
Define qué cuenta como cuello de botella
Un cuello de botella puede ser un paso (p. ej., “revisión de QA”), un equipo (p. ej., “fulfillment”), un sistema (p. ej., “pasarela de pago”) o incluso un proveedor (p. ej., “recogida por transportista”). Elige las definiciones que realmente vas a gestionar. Por ejemplo:
- Un paso es un cuello de botella cuando su tiempo medio en cola supera las 24 horas.
- Un equipo es un cuello de botella cuando el trabajo en curso se mantiene por encima de un umbral establecido durante 3 días.
- Un sistema es un cuello de botella cuando los incidentes hacen que el tiempo de ciclo se dispare por encima del rango acordado.
Enumera las decisiones que la app debe permitir
Tu panel de operaciones debe impulsar acciones, no solo informes. Apunta las decisiones que quieres tomar más rápido y con más confianza, como:
- Staffing: “¿Movemos a una persona del Equipo A al Equipo B esta semana?”
- Priorización: “¿Qué pedidos/tickets deberían pasar delante para proteger los SLA?”
- Automatización: “¿Qué paso es lo suficientemente estable (y costoso) como para automatizar primero?”
Identifica los usuarios principales y lo que necesitan
Diferentes usuarios necesitan vistas distintas:
- Managers de operaciones necesitan una vista clara de “dónde intervenir hoy”.
- Líderes de equipo necesitan desgloses hasta colas individuales, bloqueos y traspasos.
- Analistas necesitan definiciones consistentes y exportaciones para analítica de flujo.
Define métricas de éxito para la propia app
Decide cómo sabrás que la app está funcionando. Buenas medidas incluyen adopción (usuarios activos semanales), tiempo ahorrado en reporting y resolución más rápida (reducción del tiempo para detectar y arreglar cuellos de botella). Estas métricas te mantienen enfocado en resultados, no en características.
Elige el flujo de trabajo y escribe un mapa de proceso simple
Antes de diseñar tablas, paneles o alertas, elige un flujo de trabajo que puedas describir en una frase. El objetivo es rastrear dónde espera el trabajo—así que comienza pequeño y escoge uno o dos procesos que importen y generen volumen constante, como cumplimiento de pedidos, tickets de soporte o incorporación de empleados.
Un alcance ajustado mantiene clara la definición de terminado y evita que el proyecto se atasque porque los equipos no se ponen de acuerdo sobre cómo debería funcionar el proceso.
Comienza con 1–2 procesos con alta señal
Elige flujos que:
- Ocurran con frecuencia (suficientes datos para detectar patrones)
- Crucen al menos un traspaso (donde se forman colas)
- Tengan un impacto claro en el cliente (tiempo, coste, satisfacción)
Por ejemplo, “tickets de soporte” suele ser mejor que “customer success” porque tiene una unidad de trabajo obvia y acciones con marcas de tiempo.
Mapea pasos y traspasos en lenguaje llano
Escribe el flujo como una lista simple de pasos usando palabras que el equipo ya usa. No estás documentando la política: estás identificando estados por los que se mueve el ítem de trabajo.
Un mapa de proceso ligero podría verse así:
- Ticket creado → triado → asignado → agente trabajando → esperando al cliente → resuelto
En esta etapa, señala los traspasos explícitamente (triage → assigned, agente → especialista, etc.). Los traspasos son donde suele esconderse el tiempo en cola, y son los momentos que querrás medir más tarde.
Define eventos de inicio/fin y qué significa “hecho” para cada paso
Para cada paso, escribe dos cosas:
- Evento de inicio (¿qué prueba que el paso comenzó?)
- Evento de fin (¿qué prueba que el paso terminó?)
Manténlo observable. “El agente empieza a investigar” es subjetivo; “estado cambiado a En Progreso” o “primera nota interna añadida” es rastreable.
También define qué significa “hecho” para que la app no confunda una finalización parcial con la finalización. Por ejemplo, “resuelto” puede significar “mensaje de resolución enviado y ticket marcado como Resuelto”, no solo “trabajo completado internamente”.
Anota excepciones comunes que rastrearás más tarde
Las operaciones reales incluyen caminos desordenados: retrabajos, escalados, información faltante y elementos reabiertos. No intentes modelarlo todo el primer día—simplemente anota las excepciones para poder agregarlas intencionalmente después.
Una nota simple como “10–15% de los tickets se escalan a Tier 2” es suficiente. Usarás estas notas para decidir si las excepciones se convierten en pasos propios, etiquetas o flujos separados cuando amplíes el sistema.
Define métricas que realmente revelen cuellos de botella
Un cuello de botella no es una sensación: es una ralentización medible en un paso específico. Antes de construir gráficas, decide qué números probarán dónde se acumula trabajo y por qué.
Elige un conjunto pequeño de medidas centrales
Comienza con cuatro métricas que funcionan en la mayoría de los flujos:
- Tiempo de ciclo: cuánto tarda un ítem desde inicio hasta hecho.
- Tiempo de espera/cola: cuánto tiempo permanece un ítem inactivo entre pasos.
- Rendimiento (throughput): cuántos ítems se completan por período de tiempo.
- WIP (trabajo en curso): cuántos ítems están actualmente “en el sistema”.
Estas cubren velocidad (ciclo), inactividad (cola), salida (rendimiento) y carga (WIP). La mayoría de las “demoras misteriosas” aparecen como aumento del tiempo en cola y del WIP en un paso particular.
Define los cálculos (incluyendo casos límite)
Escribe definiciones con las que todo tu equipo pueda estar de acuerdo, y luego implementa exactamente eso.
- Cycle time =
done_timestamp − start_timestamp.- Casos límite: ítems reabiertos (tratar como un ciclo nuevo vs. extender el original), ítems nunca iniciados (excluir del tiempo de ciclo pero contarlos en WIP), timestamps faltantes (marcar como calidad de datos).
- Queue time = suma de los gaps entre pasos donde el estado es “waiting”.
- Casos límite: noches/fines de semana (tiempo calendario vs. horas laborables), estados bloqueados (contarlos por separado del waiting normal si quieres causas más claras).
- Throughput = conteo de ítems con
done_timestampen la ventana.- Casos límite: cancelaciones (excluir o rastrear por separado), completaciones parciales.
- WIP = conteo de ítems que no están en un estado terminal en un punto en el tiempo.
- Casos límite: ítems en espera (siguen siendo WIP, pero quizás quieras un “WIP bloqueado” separado).
Elige los desgloses que impulsan decisiones
Selecciona cortes que tus managers realmente usen: equipo, canal, línea de producto, región y prioridad. La meta es responder: “¿Dónde está lento, para quién y en qué condiciones?”
Define ventanas temporales y objetivos
Decide tu ritmo de reporting (diario y semanal son comunes) y define objetivos como umbrales de SLA/SLO (por ejemplo, “80% de los ítems de alta prioridad completados dentro de 2 días”). Los objetivos hacen que el dashboard sea accionable en lugar de solo decorativo.
Planifica tus fuentes de datos y el método de captura
La forma más rápida de que una app de seguimiento de cuellos de botella se estanque es asumir que los datos “simplemente estarán ahí”. Antes de diseñar tablas o gráficas, escribe de dónde vendrá cada evento y timestamp—y cómo mantendrás la consistencia a lo largo del tiempo.
Haz inventario de las fuentes que ya tienes
La mayoría de los equipos de operaciones ya registran trabajo en algunos sitios. Puntos de partida comunes incluyen:
- Hojas de cálculo usadas para traspasos, registros diarios o conteos de producción
- Sistemas ERP/CRM (pedidos, clientes, pasos de fulfillment)
- Herramientas de tickets (colas de soporte, solicitudes de cambio, tareas de mantenimiento)
- Bases de datos internas (escaneos de almacén, tablas de programación de trabajos, datos de ejecución de manufactura)
Para cada fuente, anota lo que puede proporcionar: un ID de registro estable, un historial de estados (no solo el estado actual) y al menos dos timestamps (entrada al paso, salida del paso). Sin eso, el monitoreo del tiempo en cola y el seguimiento del tiempo de ciclo serán conjeturas.
Elige un método de captura que se ajuste a la fuente
Generalmente tienes tres opciones, y muchas apps usan una mezcla:
- API pull: sincronización programada desde ERP/CRM/herramientas de tickets. Fácil de razonar, pero necesitarás manejar paginación, límites de tasa y actualizaciones incrementales.
- Webhooks: envíos cuando cambia el trabajo. Genial para alertas casi en tiempo real, pero debes diseñar reintentos y eventos fuera de orden.
- Entrada manual / carga CSV: útil para equipos que parten de hojas de cálculo o casos marginales. Hazlo seguro con plantillas, validación y mensajes de error claros.
Planifica la calidad de datos (porque sucederá)
Espera timestamps faltantes, duplicados y estados inconsistentes (“En Progreso” vs “Trabajando”). Construye reglas desde temprano:
- Prefiere un log de eventos inmutable en lugar de sobrescribir registros
- Desduplicar por source ID + event time + status
- Normalizar estados en los pasos canónicos de tu app
- Marcar registros que no pueden producir seguimiento de tiempo de ciclo fiable
Decide la cadencia de actualización
No todos los procesos requieren actualizaciones en tiempo real. Elige según las decisiones:
- Tiempo real: despacho, triage de soporte, riesgo de SLA
- Cada hora: throughput de almacén, monitoreo del tiempo en cola
- Diario: reporting semanal, revisiones de mejora continua
Escribe esto ahora; dirige tu estrategia de sincronización, costes y expectativas para el panel de operaciones.
Diseña un modelo de datos pensado para análisis basados en tiempo
Una app de seguimiento de cuellos de botella vive o muere por cuán bien puede responder preguntas temporales: “¿Cuánto tardó esto?”, “¿Dónde esperó?” y “¿Qué cambió justo antes de que las cosas se ralentizaran?” La manera más fácil de soportar esas preguntas es modelar tus datos alrededor de eventos y timestamps desde el día uno.
Comienza con las entidades centrales
Mantén el modelo pequeño y obvio:
- Proceso: el flujo de trabajo general (p. ej., “Fulfillment de pedidos”).
- Paso: una etapa dentro del proceso (p. ej., “Pick”, “Pack”, “Ship”).
- Ítem de trabajo: la unidad que se mueve por los pasos (ticket, pedido, reclamación).
- Evento: un cambio registrado de estado (entró a un paso, asignado, bloqueado, completado).
- Usuario/Equipo y Asignación: quién poseía el trabajo en un momento dado.
Esta estructura te permite medir tiempo de ciclo por paso, tiempo en cola entre pasos y throughput en todo el proceso sin inventar casos especiales.
Prefiere un log de eventos sobre campos de “estado actual”
Trata cada cambio de estado como un registro de evento inmutable. En lugar de sobrescribir current_step y perder el historial, añade un evento como:
- work_item_id
- from_step → to_step (o “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Aún puedes almacenar una instantánea de “estado actual” para velocidad, pero tu analítica debería basarse en el log de eventos.
Haz que el tiempo y la trazabilidad sean innegociables
Almacena timestamps en UTC de forma consistente. También conserva identificadores originales de la fuente (p. ej., clave de issue de Jira, ID de pedido del ERP) en ítems de trabajo y eventos, para que cada gráfico pueda rastrearse hasta un registro real.
Captura excepciones sin crear trabajo administrativo
Planifica campos ligeros para los momentos que explican retrasos:
- reason_code (opciones estándar como “Esperando al cliente”)
- comment (texto opcional)
- blocked_flag o severity
Mantenlos opcionales y fáciles de completar, para que aprendas de las excepciones sin convertir la app en un ejercicio de llenar formularios.
Elige una arquitectura que encaje con tu equipo
Estira tu presupuesto de desarrollo
Obtén créditos por compartir lo que construyes o invitar a compañeros a Koder.ai.
La “mejor” arquitectura es la que tu equipo puede construir, entender y operar durante años. Empieza eligiendo una pila que coincida con tu pool de contratación y habilidades existentes—opciones comunes y bien soportadas incluyen React + Node.js, Django o Rails. La consistencia vence a la novedad cuando tu dashboard de operaciones es algo de lo que dependen las personas a diario.
Separa responsabilidades para que el sistema siga siendo editable
Una app de seguimiento de cuellos de botella suele funcionar mejor cuando la divides en capas claras:
- Ingestión: recepción de eventos (cambios de estado, timestamps, traspasos) desde formularios, integraciones o importaciones.
- Almacenamiento: una base de datos transaccional para escrituras fiables e historial de auditoría.
- Consultas analíticas: vistas o consultas optimizadas para lectura que calculen tiempo de ciclo, tiempo en cola y throughput.
- UI/API: endpoints y pantallas que mantengan dashboards rápidos y previsibles.
Esta separación te permite cambiar una parte (por ejemplo, añadir una nueva fuente de datos) sin reescribirlo todo.
Decide dónde deben vivir los cálculos
Algunas métricas son lo bastante simples para calcularse en consultas de base de datos (p. ej., “tiempo medio en cola por paso últimos 7 días”). Otras son costosas o necesitan preprocesado (p. ej., percentiles, detección de anomalías, cohortes semanales). Una regla práctica:
- Haz filtros y desgloses en tiempo real en la base de datos.
- Usa jobs en segundo plano para precomputar agregados pesados y almacenarlos para una carga rápida del dashboard.
- Añade una capa analítica solo si tu equipo la mantendrá con confianza.
Planifica el rendimiento desde temprano
Los dashboards operativos fallan cuando se sienten lentos. Usa índices en timestamps, IDs de paso del flujo y tenant/team IDs. Añade paginación para logs de eventos. Cachea vistas de dashboard comunes (como “hoy” y “últimos 7 días”) e invalida la caché cuando lleguen nuevos eventos.
Si quieres una discusión más profunda de compensaciones, guarda un breve registro de decisiones en tu repo para que cambios futuros no se desvíen.
Una ruta más rápida para equipos que quieren lanzar pronto
Si tu objetivo es validar analítica de flujo y alertas antes de comprometerte con una construcción completa, una plataforma de creación rápida tipo “vibe-coding” como Koder.ai puede ayudarte a levantar una primera versión más rápido: describes el flujo, las entidades y los paneles en chat, y luego iteras sobre la UI generada en React y el backend en Go + PostgreSQL a medida que afinas la instrumentación de KPI.
La ventaja práctica para una app de seguimiento de cuellos de botella es la rapidez para obtener feedback: puedes pilotar la ingestión (API pulls, webhooks o importación CSV), añadir pantallas de desglose y ajustar definiciones de métricas sin semanas de andamiaje. Cuando estés listo, Koder.ai también permite exportar el código fuente y el despliegue/hosting, lo que facilita pasar de prototipo a herramienta interna mantenida.
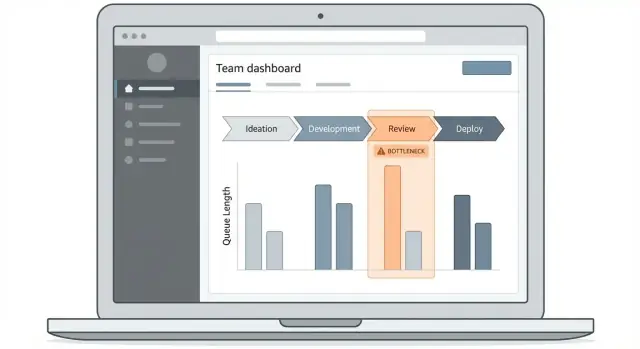
Diseña la experiencia del dashboard y el drill-down
Una app de seguimiento de cuellos de botella tiene éxito o fracasa en si las personas pueden responder una pregunta rápidamente: “¿Dónde se está atascando el trabajo ahora y qué ítems lo están causando?” Tu dashboard debe hacer ese camino obvio, incluso para alguien que solo lo visita una vez a la semana.
Comienza con 2–3 pantallas centrales
Mantén el primer lanzamiento ajustado:
- Panel de resumen: el “tablero de estado” para tiempo de ciclo, tiempo en cola y pasos más bloqueados.
- Lista de ítems de trabajo: una tabla buscable y filtrable de ítems afectados por demoras.
- Detalle del flujo: una vista paso a paso que muestra el tiempo en cada etapa y los puntos de traspaso.
Estas pantallas crean un flujo natural de drill-down sin forzar a los usuarios a aprender una UI compleja.
Usa visuales que expliquen tiempo y flujo
Elige tipos de gráficos que respondan a preguntas operativas:
- Embudo por etapa: muestra dónde se acumula volumen (útil para detectar colas).
- Barras de tiempo en etapa: compara pasos por mediana y percentiles, no solo por promedios.
- Líneas de tendencia: responden “¿esto mejora o empeora?” a lo largo de semanas.
- Mapas de calor: revelan patrones como “los lunes en revisión” o “traspasos del turno nocturno”.
Mantén las etiquetas claras: “Tiempo esperando” vs. “Latencia en cola”.
Haz los filtros consistentes y difíciles de pasar por alto
Usa una barra de filtros compartida en todas las pantallas (misma ubicación, mismos valores por defecto): rango de fechas, equipo, prioridad y paso. Muestra los filtros activos como chips para que la gente no malinterprete los números.
Diseña rutas de drill-down claras
Cada tarjeta de KPI debe ser clicable y llevar a algo útil:
KPI → paso → lista de ítems impactados
Ejemplo: hacer clic en “Mayor tiempo en cola” abre el detalle del paso, y un solo clic muestra los ítems exactos que están esperando allí—ordenados por antigüedad, prioridad y responsable. Esto convierte la curiosidad en una lista de tareas concreta, que es lo que hace que el dashboard se use en lugar de ignorarse.
Añade alertas y señales de aviso temprano
Diseña permisos desde el inicio
Incluye acceso de visor, gestor y administrador, además de seguimiento de cambios apto para auditorías.
Los dashboards son geniales para revisiones, pero los cuellos de botella suelen dañar más entre reuniones. Las alertas convierten tu app en un sistema de aviso temprano: encuentras problemas mientras se están formando, no después de que se haya perdido la semana.
Comienza con reglas claras y aburridas
Empieza con un pequeño conjunto de tipos de alerta que tu equipo ya considera “malos”:
- Superación de umbrales: tiempo de ciclo o tiempo en cola por encima de un límite conocido (p. ej., “Paso de revisión > 24 horas”).
- Aumentos anormales: la mediana de tiempo de ciclo de hoy ha subido 30% vs la semana pasada.
- Ítems atascados: sin cambio de estado durante N horas/días, o ítems que exceden una edad máxima.
Mantén la primera versión simple. Unas pocas reglas determinísticas atrapan la mayoría de los problemas y son más fáciles de confiar que modelos complejos.
Añade comprobaciones de anomalías ligeras
Una vez que los umbrales estén estables, añade señales básicas de “¿esto es raro?”:
- Cambio porcentual vs la semana pasada (comparar el mismo día reduce falsas alarmas).
- Deriva de media móvil (p. ej., la media de 7 días subiendo de forma sostenida).
- Desajustes de volumen (entrada creciendo más rápido que la salida en un paso).
Haz que las anomalías sean sugerencias, no emergencias: etiquétalas como “Aviso” hasta que los usuarios confirmen que son útiles.
Entrega alertas donde la gente trabaja
Soporta múltiples canales para que los equipos elijan lo que encaja:
- Correo para managers y resúmenes diarios
- Slack/Microsoft Teams para triage en tiempo real
- Notificaciones en la app para responsables dentro de la herramienta
Haz que cada alerta sea accionable
Una alerta debe responder “qué, dónde y qué sigue”:
- Qué paso está afectado y la ventana temporal
- Los principales impulsores (p. ej., equipo, categoría, prioridad)
- Un enlace directo para investigar, por ejemplo:
/dashboard?step=review&range=7d&filter=stuck
Si las alertas no conducen a una acción concreta, la gente las silenciará—trata la calidad de las alertas como una característica de producto, no como un añadido.
Maneja permisos, seguridad y auditabilidad
Una app de seguimiento de cuellos de botella rápidamente se convierte en una “fuente de verdad”. Eso es genial—hasta que la persona equivocada edita una definición, exporta datos sensibles o comparte un dashboard fuera de su equipo. Permisos y registros de auditoría no son burocracia; protegen la confianza en los números.
Define roles y reglas de acceso
Comienza con un modelo de roles pequeño y claro y crece solo cuando sea necesario:
- Viewer: acceso de solo lectura a dashboards e informes.
- Manager: puede filtrar por equipo, crear vistas guardadas, reconocer alertas y añadir notas (pero no puede cambiar configuraciones globales).
- Admin: gestiona definiciones de procesos, fórmulas de KPI, integraciones y acceso de usuarios.
Sé explícito sobre lo que cada rol puede hacer: ver eventos crudos vs. métricas agregadas, exportar datos, editar umbrales y gestionar integraciones.
Separa datos por equipo o unidad de negocio
Si varias unidades usan la app, aplica separación en la capa de datos—no solo en la UI. Opciones comunes:
- Multi-tenant: cada registro tiene un
tenant_id, y cada consulta se scopea a él. - Particiones/proyectos: “workspaces” separados por unidad de negocio, con configuraciones y dashboards independientes.
Decide pronto si los managers pueden ver los datos de otros equipos. Haz que la visibilidad entre equipos sea un permiso deliberado, no un valor por defecto.
Autenticación segura (SSO o compatible con MFA)
Si tu organización tiene SSO (SAML/OIDC), úsalo para centralizar offboarding y control de acceso. Si no, implementa un inicio de sesión que sea compatible con MFA (TOTP o passkeys), permita restablecimiento de contraseña seguro y aplique timeouts de sesión.
Haz los cambios auditables
Registra las acciones que pueden cambiar resultados o exponer datos: exportaciones, cambios de umbral, ediciones de flujo de trabajo, actualizaciones de permisos y configuraciones de integración. Captura quién lo hizo, cuándo, qué cambió (antes/después) y dónde (workspace/tenant). Proporciona una vista de “Registro de auditoría” para investigar problemas rápidamente.
Convierte insights en acciones y mejoras de proceso
Un dashboard de cuellos de botella solo importa si cambia lo que la gente hace después. El objetivo de esta sección es convertir “gráficos interesantes” en un ritmo operativo repetible: decidir, actuar, medir y mantener lo que funciona.
Crea una revisión ligera de cuellos de botella
Establece una cadencia semanal simple (30–45 minutos) con propietarios claros. Comienza con los 1–3 cuellos de botella principales por impacto (p. ej., mayor tiempo en cola o la mayor caída de throughput), y luego acuerda una acción por cuello de botella.
Mantén el flujo de trabajo pequeño:
- Propietario: una persona responsable por acción
- Fecha de vencimiento: siguiente revisión por defecto
- Definición de hecho: un cambio medible (no “investigar más”)
Captura decisiones directamente en la app para que el dashboard y el registro de acciones permanezcan conectados.
Rastrea mejoras como experimentos
Trata las soluciones como experimentos para aprender rápido y evitar “actos aleatorios de optimización”. Para cada cambio, registra:
- Hipótesis (qué está ralentizando y por qué)
- Cambio (qué harás)
- Impacto esperado (qué métrica debería moverse y cuánto)
- Resultado (qué pasó en realidad)
Con el tiempo, esto se convierte en un playbook de lo que reduce tiempo de ciclo, reduce retrabajo y lo que no funciona.
Añade contexto con anotaciones
Los gráficos pueden engañar sin contexto. Añade anotaciones simples en las líneas de tiempo (p. ej., incorporación de nuevo personal, caída del sistema, actualización de políticas) para que los espectadores interpreten correctamente los cambios en tiempo en cola o throughput.
Facilita el intercambio
Proporciona opciones de exportación para análisis e informes—descargas CSV y reportes programados—para que los equipos incluyan resultados en actualizaciones operativas y revisiones de liderazgo. Si ya tienes una página de reportes, enlázala desde tu dashboard (por ejemplo, /reports).
Despliega, monitoriza y mantén los datos frescos
Construye a partir de un mapa de procesos sencillo
Convierte tu mapa de procesos en pasos, eventos y paneles sin semanas de configuración.
Una app de seguimiento de cuellos de botella solo es útil si está disponible consistentemente y los números siguen siendo confiables. Trata el despliegue y la frescura de los datos como parte del producto, no como algo secundario.
Usa entornos separados y despliegues repetibles
Configura dev / staging / prod desde temprano. Staging debe reflejar producción (mismo motor de base de datos, volumen de datos similar, mismos jobs en segundo plano) para atrapar consultas lentas y migraciones rotas antes de que los usuarios las sufran.
Automatiza despliegues con una pipeline única: ejecuta tests, aplica migraciones, despliega y luego corre una comprobación rápida (loguearse, cargar el dashboard, verificar que la ingestión está en marcha). Mantén despliegues pequeños y frecuentes; reducen el riesgo y hacen realista el rollback.
Monitoriza la app y la pipeline
Quieres monitorización en dos frentes:
- Salud de la app: tasas de error, latencia, endpoints lentos y consultas pesadas.
- Salud de datos: fallos de ingestión, tamaño del backlog y “tiempo desde el último evento recibido”.
Alerta sobre síntomas que los usuarios sienten (dashboards que caducan) y sobre señales tempranas (una cola que crece durante 30 minutos). También rastrea fallos en el cálculo de métricas—los tiempos de ciclo faltantes pueden parecer “mejora”.
Mantén los datos frescos: eventos tardíos, correcciones y backfills
Los datos operativos llegan tarde, fuera de orden o se corrigen. Planea para:
- Ingestión idempotente (reprocesar el mismo evento no cuenta doble).
- Backfills para rangos de fechas cuando una fuente estuvo caída.
- Recomputos cuando cambian datos de referencia (p. ej., calendarios de turnos actualizados).
Define qué significa “fresco” (por ejemplo, 95% de eventos dentro de 5 minutos) y muestra la frescura en la UI.
Escribe runbooks para que las correcciones no sean conjeturas
Documenta runbooks paso a paso: cómo reiniciar una sincronización rota, validar los KPIs de ayer y confirmar que un backfill no cambió números históricos inesperadamente. Almacénalos con el proyecto y enlázalos desde /docs para que el equipo responda rápido.
Itera con usuarios y amplía la cobertura
Una app de seguimiento de cuellos de botella tiene éxito cuando la gente confía en ella y realmente la usa. Eso ocurre después de observar a usuarios reales intentando responder preguntas reales (“¿Por qué las aprobaciones están lentas esta semana?”) y luego ajustar el producto alrededor de esos flujos.
Comienza con un piloto y aprende qué se rompe
Empieza con un equipo piloto y un número reducido de flujos. Mantén el alcance lo bastante estrecho para observar uso y responder rápido.
En la primera semana o dos, céntrate en lo que confunde o falta:
- ¿Qué gráficos malinterpretan los usuarios?
- ¿Dónde se atascan al hacer drill-down?
- ¿Qué datos esperan ver y no encuentran?
- ¿Qué cuellos de botella les parecen “obvios” pero no aparecen en la app?
Captura feedback en la herramienta misma (un simple “¿Fue útil esto?” en pantallas clave funciona bien) para no depender de la memoria de las reuniones.
Valida métricas para evitar “peleas por el dashboard”
Antes de expandirte a más equipos, cierra las definiciones con las personas que rendirán cuentas. Muchos lanzamientos fallan porque los equipos no se ponen de acuerdo sobre lo que significa una métrica.
Para cada KPI (tiempo de ciclo, tiempo en cola, tasa de retrabajo, incumplimientos de SLA) documenta:
- Eventos exactos de inicio y fin
- Manejo de pausas, fines de semana y timestamps faltantes
- Cómo se cuentan las excepciones (cancelaciones, escalados, reabrimientos)
Luego revisa esas definiciones con los usuarios y añade tooltips cortos en la UI. Si ajustas una definición, muestra un changelog claro para que la gente entienda por qué se movieron los números.
Expande la cobertura sin convertir la app en un desastre
Añade funcionalidades con cuidado y solo cuando la analítica del equipo piloto esté estable. Expansiones comunes incluyen pasos personalizados (distintos equipos etiquetan etapas diferente), fuentes adicionales (tickets + CRM + hojas de cálculo) y segmentación avanzada (por línea de producto, región, prioridad, tier de cliente).
Una regla útil: añade una nueva dimensión a la vez y verifica que mejore las decisiones, no solo el reporting.
Facilita la incorporación de nuevos equipos
A medida que despliegas a más equipos necesitarás consistencia. Crea una guía corta de onboarding: cómo conectar datos, cómo interpretar el dashboard de operaciones y cómo actuar sobre alertas de cuellos de botella.
Enlaza a las personas con páginas relevantes dentro de tu producto y contenido, como /pricing y /blog, para que los nuevos usuarios puedan auto-servirse respuestas en lugar de esperar sesiones de entrenamiento.